TencentDB Agent Memory 正式开源:让 Agent 沉淀经验,让人专注创造
原创
TencentDB Agent Memory 正式开源:让 Agent 沉淀经验,让人专注创造
原创
腾讯云NoSQL技术
发布于 2026-05-13 22:02:40
发布于 2026-05-13 22:02:40
TencentDB Agent Memory 正式开源:让 Agent 沉淀经验,让人专注创造。
今天,腾讯云数据库团队正式开源 TencentDB Agent Memory 。
一套面向 AI Agent 的分层记忆引擎,项目采用 MIT 协议开源,开箱即用。


✨项目主页:https://github.com/Tencent/TencentDB-Agent-Memory
在当前主流的 Agent 架构中,Memory 已经从"加分项"变成了"标配组件"。
无论是面向 C 端的对话助手,还是面向开发者的长周期 Agent,底层都依赖类似的"记忆层"承载跨会话偏好与历史经验,并逐渐收敛出一套通用的接口范式。
TencentDB Agent Memory 正是在这一背景下诞生的:让 Agent 学会你的工作流程、保留任务上下文、复用历史经验——以符号化记忆化解单次长任务的信息过载,以分层记忆沉淀跨会话的经验资产。
在超长session评测中发现,agent memory作为 OpenClaw 插件接入后:最高节省 61.38% Token,通过率相对提升 51.52%;PersonaMem 准确率从 48% 提升到 76%。
记忆能力 | Benchmark | Openclaw 成功率 | 加插件后成功率 | 相对变化 | Openclaw Token 消耗 | 加插件后 Token 消耗 | 相对变化 |
|---|---|---|---|---|---|---|---|
短期记忆 | WideSearch | 33% | 50% | +51.52% | 221.31M | 85.64M | −61.38% |
短期记忆 | SWE-bench | 58.4% | 64.2% | +9.93% | 3474.1M | 2375.4M | −33.09% |
短期记忆 | AA-LCR | 44.0% | 47.5% | +7.95% | 112.0M | 77.3M | −30.98% |
长期记忆 | PersonaMem | 48% | 76% | +59% | — | — | — |
目前,TencentDB Agent Memory已作为 OpenClaw 记忆增强插件,在生产环境中验证工作效果。
准确
当下主流 AI Agent 的记忆方案,大多做的是同一件事:把对话历史压缩成一段摘要,然后在下次会话时注入上下文。这在短对话里够用,但在真实的长周期任务中会暴露三个问题:
● 跨会话断裂:昨天反复确认的代码规范,今天新开会话又全忘了
● 事实与偏好混淆:用户说过"我用 TypeScript"和"帮我查一下天气",这两条信息的价值完全不同,但被同等对待
● 上下文膨胀:任务越长,堆进上下文的历史信息越多,Token 消耗持续攀升,模型注意力也在衰减
TencentDB Agent Memory通过把不同粒度的信息放在不同的"楼层",构建分层式长期记忆能力来解决以上长周期任务问题:
- L0 原始对话层全量保留每一轮交互;
- L1 原子记忆层自动提取事实、偏好、约束、阶段结论;
- L2 场景归纳层按任务自动聚合;
- L3 用户画像层持续蒸馏出稳定的长期画像
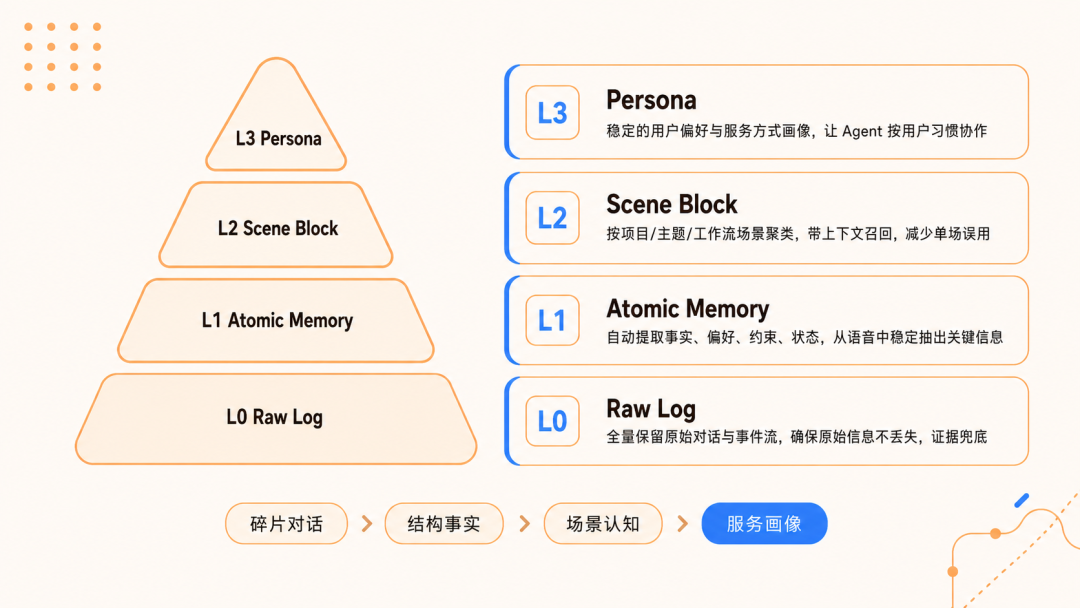
每一层只做一件事,层与层之间通过提取-聚合-蒸馏的管道连接,任何一层都可以独立升级或替换,让Agent 不再因为换了一次会话就忘掉你是谁。
效率
过去,"更聪明的 Agent"往往意味着"更贵的 Agent",但 Agent 是按 Token 计费、按响应速度评价的,每多塞一段对话,就是成本和体验的双重损失。
TencentDB Agent Memory 通过上下文卸载 + Mermaid 无限画布两项关键技术,把原始工具结果搬到外部文件,把任务结构折叠成可导航的画布,上下文里只保留摘要和索引。
对于连续任务和大规模并发,每一个 Token 都影响着成本和体验,这套功能,使得原文不丢、结构可查、Token 不再线性增长。

稳定
省 Token 之外,任务完成率也是检验记忆方案的重要指标。
很多压缩方案能把 Token 砍下来,但任务跑偏、遗忘、重复分析的问题随之而来。
TencentDB Agent Memory 在四个公开评测集上同时跑通了两条曲线:Token 下降,完成率上升。
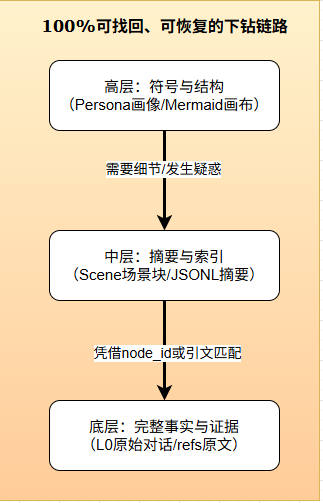
不过,「跑得稳」不只看评测分数,还得经得起底层架构的拷问——我们用 异构存储 + 全链路可溯源,确保了稳定与全量检索。
这套能力已在生产环境经历真实验证——在编程、调研、文档分析、工作流编排四类长链路任务上稳定收敛。
快速开始
GitHub 仓库中提供了 OpenClaw 、Hermes Gateway 接入方案,开箱即跑。
1. Openclaw一行安装
openclaw plugins install @tencentdb-agent-memory/memory-tencentdb
openclaw gateway restart2. Hermes Gateway(Docker,需版本号 ≥ 0.3.4)
除 OpenClaw 外,本插件也支持 Hermes Agent。
一行命令即可启动带记忆能力的 Hermes:
docker run -d \
--name hermes-memory \
--restart unless-stopped \
-p 8420:8420 \
-e MODEL_API_KEY="$MODEL_API_KEY" \
-e MODEL_BASE_URL="$MODEL_BASE_URL" \
-e MODEL_NAME="$MODEL_NAME" \
-e MODEL_PROVIDER="$MODEL_PROVIDER" \
-v hermes_data:/opt/data \
agentmemory/hermes-memory:latest镜像支持 linux/amd64 和 linux/arm64。内置腾讯云 DeepSeek-V3.2 默认配置,如需自定义模型可额外传入 MODEL_BASE_URL、MODEL_NAME、MODEL_PROVIDER。
验证:
curl http://localhost:8420/health # 检查 Gateway 状态
docker exec -it hermes-memory hermes # 进入 Hermes 对话记忆不是让 AI 记住所有事,而是让人不必重复所有事。
我们把 TencentDB Agent Memory 放到开源社区,是因为相信记忆这个产品远没有标准答案,比起做一个完美的方案,我们更想和开发者一起,把产品做得更丰富、更扎实、更可用,从而帮助更多 Agent 沉淀经验,让人更专注于创造。
欢迎所有形式的共建——提一个 issue,发起一次discussion,对一个早期项目而言,每一种反馈,都是贡献。
相关链接
资源 | 链接 |
|---|---|
GitHub | https://github.com/Tencent/TencentDB-Agent-Memory |
npm | https://www.npmjs.com/package/@tencentdb-agent-memory/memory-tencentdb |
官网介绍 | Agent Memory 智能体记忆服务|AI 长期记忆与精准召回平台 |
PersonaMem 评测集 | https://github.com/bowen-upenn/PersonaMem |
OpenClaw | https://github.com/openclaw/openclaw |
Hermes | GitHub - NousResearch/hermes-agent: The agent that grows with you · GitHub |
TencentDB Agent Memory 由腾讯云数据库团队开发和维护。如果这个项目对你有帮助,欢迎在 GitHub 上给一个 ⭐:https://github.com/Tencent/TencentDB-Agent-Memory
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号