我把 4 年踩坑经验「蒸馏」成 Claude Code Skill 开源了

我把 4 年踩坑经验「蒸馏」成 Claude Code Skill 开源了

码哥字节
发布于 2026-05-08 18:34:35
发布于 2026-05-08 18:34:35
github 开源地址:https://github.com/MageByte-Zero/magebyte-power
最近,我们有一个涉及退款金额计算的核心接口,上线前做了 Code Review,测试也通过了,自测没发现问题。结果上线两小时后,运维来消息说有用户重复收到退款。
排查了四个小时,找到了原因:在某个特定的并发窗口下,幂等键虽然写进去了,但写入和读取之间有一个竞态——两个请求几乎同时抢到了同一把锁的空档期,各自独立走完了退款流程。
这段代码在 Code Review 时被两个同事审过了,包括我自己。没人发现这个问题。
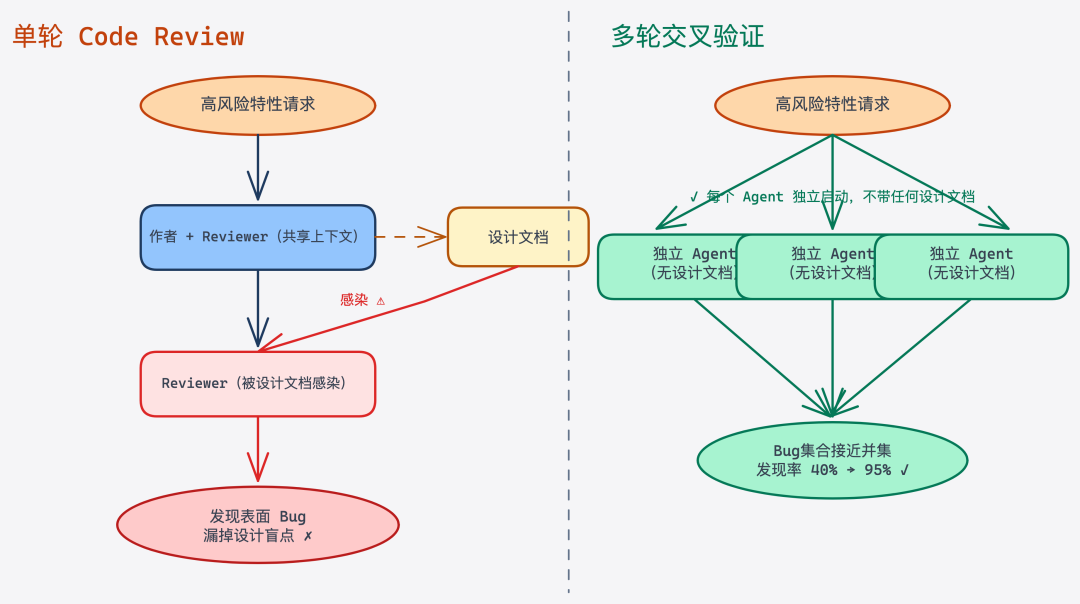
不是因为大家不认真,而是因为 Code Review 本身有一个结构性盲点。
单一视角的 Review,到底漏掉了什么
Code Review 最大的问题不是审查不仔细,而是所有 reviewer 共享同一套上下文和设计假设。
设计文档是作者写的,reviewer 也读过。文档里说"这里保证了幂等性",reviewer 就会在看到对应代码时默认"嗯,这里处理过了"——然后真正的漏洞就在这个默认里溜走了。
我把这个现象叫做「上下文污染」。你给 reviewer 的信息越多,它就越难发现你信念系统里的漏洞。
解决这个问题的方式,理论上很简单:让一个完全不知道你设计思路的 reviewer 只看代码本身,看代码实际做了什么,而不是看它应该做什么。
实际操作上,这很难——你不可能每次都拉一个对项目完全陌生的同事来 review,更难的是要在 reviewer 面前绝口不提设计文档。
但 Claude Code 的 Superpowers 生态可以做到这件事。
我开源了一个 Claude Code Skill:cross-verified-feature-development
这个 Skill 的核心逻辑是:在实施和合并之间,强制插入 4 轮独立视角的验证。
每一轮验证用的是不同的视角、不同的信息范围、不同的 agent 上下文——4 种视角发现的 bug 集合接近并集而不是重复集合。这就是为什么它能把 Critical Bug 发现率从 ~40% 提升到 ~95%。
整个工作流分 7 个阶段:
① 需求/设计 → 把模糊诉求结构化为完整 spec
①.5 架构决策评审 → 在动代码之前把关键技术决策显式验证一遍
② 实施计划 → 把 spec 拆成可独立执行、可独立验证的 task 清单
③ 实施 → 每个 task 独立的 fresh subagent 执行,消除累积偏差
④ 多轮交叉验证 ← 这是整个工作流的核心创新
⑤ 迭代修复 → 把发现的问题修干净,再跑一次验证
⑥ 谨慎简化 → 带怀疑的优化,避免"我最了解这段代码"的自信陷阱
⑦ 文档同步 → 把最终代码状态回填到设计文档,避免给下一个维护者埋雷

前三个阶段做的是普通工作流都应该做的事,这个 Skill 用 Superpowers 把它们做得更结构化。真正让它和普通工作流产生差距的是第四阶段。
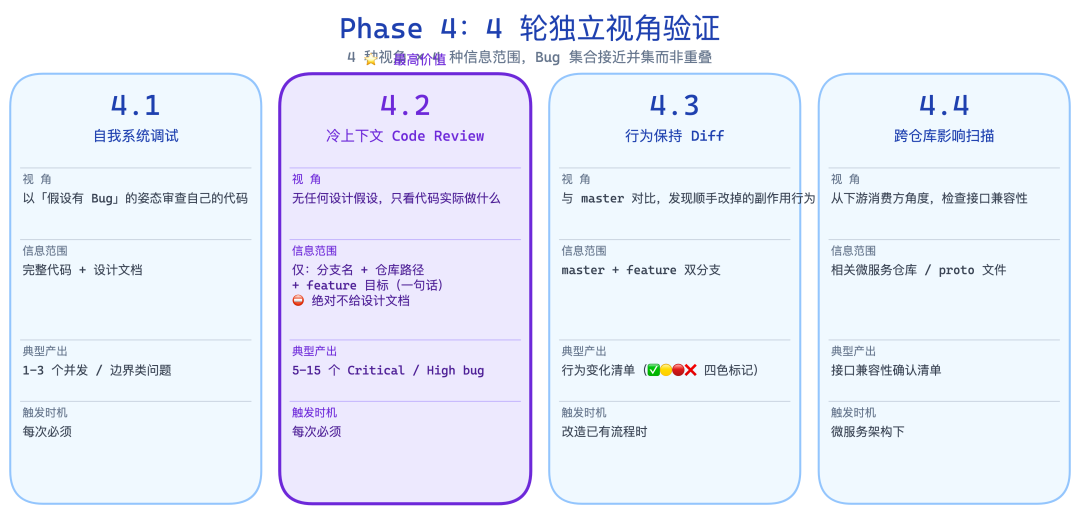
Phase 4:4 轮独立验证,每一轮发现的 Bug 都不一样
Round 4.1:自我系统调试
这一轮用 superpowers:systematic-debugging 框架,以**"假如此刻存在 Bug,会是什么 Bug"** 的角度扫描自己的代码。
重点检查:并发点、失败模式、幂等性、状态机边界、nil 值。成本极低,通常能找到 1-3 个"顺路发现"的问题。
但这一轮的价值是热身,不是主菜。
Round 4.2:冷上下文 Code Review ⭐ 这才是主菜
这是整个工作流里价值最高的一步,也是让它和普通工作流真正产生差距的地方。
做法是:用 Claude Code 的 Agent 工具 dispatch 一个全新的 reviewer agent,给它的信息极其有限:
- ✅ 只告诉它:分支名、仓库路径、feature 目标一句话
- ❌ 绝对不给:设计文档、实施计划、你的任何理解和总结
prompt 里必须明确写:DO NOT read the design document. Your value comes from NOT knowing what the author intended.
这个约束不是形式主义。你给 reviewer 看设计文档,等于让它被你的盲点感染。冷上下文的 reviewer 只看代码实际做什么,反而能发现设计本身的漏洞。
典型产出:5-15 个 Critical / High 级别的 bug,全部是标准 Code Review 会放过的问题。
我在自己的工作里每次用这一轮,找出来的问题都让我后背发凉——都是自己写完代码之后完全没意识到的漏洞。
Round 4.3:行为保持 Diff
这一轮处理一类特殊情况:当你的 feature 不是新增,而是对已有流程的改造。
dispatch 一个 agent 同时读 master 和 feature 分支,逐条列出所有副作用(DB 写、MQ 发布、RPC 调用、缓存写),用颜色标记每条变化:
- ✅ 完全不变
- 🟡 顺序变了
- 🔴 语义变了(高风险)
- ❌ 原来有,现在没了
这一轮专门找你"顺手"改掉的行为——那些你觉得是"无关紧要的调整",但对下游来说可能是 breaking change 的改动。
Round 4.4:跨仓库影响扫描
微服务架构下,你改了一个服务,另一个服务可能也需要跟着改。这一轮扫描的是:
- MQ 消费者是否需要更新去重逻辑
- RPC 调用方是否要处理新错误码
- 共享 DB 表的其他读写方是否受影响
- proto / model 变更是否向后兼容
大多数情况结论是"不需要改",但需要明确确认——而不是"应该没问题"。
Superpowers 是怎么增强这个工作流的
这个 Skill 本身不重复造轮子,它做的是编排——在正确的阶段调用正确的 Superpowers sub-skill。
阶段 | 调用的 Superpowers Skill | 增强了什么 |
|---|---|---|
Phase 1 需求分析 | superpowers:brainstorming | 把模糊需求变成有不变式清单、失败模式分析、风险表格的完整 spec |
Phase 2 实施计划 | superpowers:writing-plans | 每个 task 有文件+行号+验证命令,TDD 结构,上线策略,回滚标准 |
Phase 3 实施 | superpowers:subagent-driven-development | 每个 task 在独立的 fresh context subagent 里执行,消除累积偏差 |
Phase 4.1 自查 | superpowers:systematic-debugging | 结构化"假设有 bug,会是什么 bug"的思维框架 |
Phase 4.2 冷评审 | superpowers:code-reviewer | 不给设计文档的独立 reviewer agent |
Phase 5 修复 | superpowers:writing-plans + subagent-driven-development | 修复阶段和实施阶段同等严谨度 |
如果你没有安装 Superpowers,这个 Skill 也提供了每个阶段的 fallback 模式,用 Claude Code 内置工具完成对应工作。
两个真实踩坑案例
这两个案例来自 case-studies.md,就是工作流设计过程中真实踩过的坑。
Case 1:多义字段引发的退款数据错乱
有一张表,字段 reference_id 在主路径下存退款单号。开发者看了主路径觉得"这个缓存是冗余的,直接从 reference_id 拿就行了"。
但在部分支付(补差价)场景下,另一条完全不同的业务流会把支付单号写进同一个 reference_id。简化后的代码在这个场景下把 PaymentID 作为 RefundID 返回给了调用方。
下游用这个"退款单号"去查退款详情:查不到,报"退款单不存在"。
这个 bug 只有在 Phase 4 的冷上下文评审里才能发现——因为 reviewer 没有读设计文档,它不会默认 reference_id 只存一种语义,它会把所有写这个字段的地方都找出来。
Case 2:锁粒度不足导致并发全量副作用重复
有一个 ProcessTransaction 方法,设计时只在"retry 入口(status=PROCESSING)"加了分布式锁,认为"首次处理(status=PENDING)不会并发"。
但生产环境在高峰期,同一个 PENDING 状态的 transaction 偶尔会被两个进程几乎同时捞到——在首次处理阶段就发生了并发,绕过了锁。
Phase 4.2 的冷评审发现了这个问题,因为 reviewer 看代码时会问:"所有并发点是否都加了锁?"而不是"设计文档说这个地方不会并发"。
什么时候应该用这个工作流
判断很简单,问自己一句话:**"这个 feature 最坏的 bug 会造成什么?"**
如果答案包含:资金损失 / 数据错乱 / 订单卡死 / 用户权限越权 / 生产事故——用这个工作流。
具体来说,命中以下任一项就值得走:
- 💰 资金流、支付、退款、结算
- 🔄 订单/库存状态机,有明确的状态转换
- 🔒 分布式锁、并发控制、幂等重试
- 🔗 跨服务 MQ/RPC 协议或共享 proto 变更
- 🗄️ 在线 schema 迁移或双写切换
- ⏱️ 工作量 ≥ 3 人日且失败代价高
不适合的场景:纯 UI 调整、无状态机语义的简单 CRUD、一次性脚本、小 bug 修复。
这个工作流会让你多花 40-50% 的时间。但对于命中以上场景的 feature,这个时间成本换来的是:别人在 Code Review 里找不到的 bug,你在合并前自己找到了。
怎么用
安装 Superpowers(一次性):
claude mcp add --transport http superpowers https://superpowers.anthropic.com/mcp
安装这个 Skill:
git clone https://github.com/MageByte-Zero/magebyte-power.git
ln -sf "$PWD/magebyte-power/skills/cross-verified-feature-development" \
~/.claude/skills/cross-verified-feature-development
触发方式:
/cross-verified-workflow <feature 需求描述>
或者直接描述高风险特性,Skill 检测到相关关键词会主动建议你走这个流程。
最后说一句
说实话,这套工作流是被生产 bug 逼出来的,不是设计出来的。每加一个阶段、每写一条检查清单,背后都有一次"这个我当时没想到"的经历。
开源的目的是让这些踩过的坑别再被其他人踩一遍。
如果你在做高风险的后端改动,或者你也有"Code Review 通过了还是上线翻车"的经历,可以去看看这个 Skill 的 references/case-studies.md——那里有 6 个真实案例,不是泛泛的"最佳实践",是真实的翻车现场。
GitHub 地址:https://github.com/MageByte-Zero/magebyte-power
FAQ
Q:这个工作流是不是只适合大团队?
不是。我自己用这个工作流的时候团队只有 3 个人。它的价值不依赖团队规模,依赖的是"高风险特性 + 独立视角验证"这个组合——哪怕你是一个人开发,dispatch 一个不带设计文档的 reviewer agent 都比你自己再看一遍有效。
Q:Phase 4 的 4 轮验证都必须做吗?
Phase 4.1(自查)和 4.2(冷评审)是强制的。4.3(行为 diff)只在改造已有流程时必做,纯新增可跳过。4.4(跨仓库扫描)只在微服务架构下必做,单体项目可跳过。每个阶段的触发条件在 Skill 里写清楚了。
Q:用这个工作流大概要多花多少时间?
一个 5 人日的 feature,用这个工作流大概需要 7-10 人日。多出的时间基本都花在 Phase 4 的验证和 Phase 5 的修复上。但 Phase 4.2 平均找到 5-15 个 bug——如果这些 bug 上了生产,排查和修复的时间远不止这几天。
Q:没有 Superpowers 能用吗?
能。每个阶段都有 fallback 说明,写清楚了怎么不依赖 Superpowers 完成对应阶段的工作。Superpowers 提供的是更结构化的子 skill,让每个阶段更稳定,但不是必须的。
Q:为什么叫「冷上下文 review」而不是普通的 code review?
"冷"指的是 reviewer 不带任何预设上下文进来——没读设计文档,没听过你的方案,完全从代码本身出发。这和给熟悉项目的同事做 review 有本质区别。后者的 reviewer 会用"作者应该想到了这个"的心理来填补代码里的空白,而冷上下文 reviewer 不会。
下一篇打算写如何用 Superpowers 的 subagent-driven-development 做真正的并行开发——每个 task 跑在独立的 agent 上下文里,效果比想象中好很多。感兴趣的关注一下,发布了第一时间推送。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号