用 HyperFrames 和 Rust 搭建一套“视频全自动生产线”

用 HyperFrames 和 Rust 搭建一套“视频全自动生产线”

程序那些事儿
发布于 2026-05-08 12:13:14
发布于 2026-05-08 12:13:14
当大多数人还在研究哪个剪辑软件的转场更酷炫时,真正的生产力玩家已经开始把视频拆解成 “协议” 与 “数据”。视频制作的下半场,不再是剪辑师的竞争,而是系统架构师的对决。
从“手动剪辑”到“代码声明”
传统的视频剪辑(GUI 模式)本质上是像素级的体力活。哪怕是目前流行的 Remotion 或 Motion Canvas,虽然实现了“代码化”,但由于其对 React 生态的深度绑定,对于 AI Agent 来说依然存在较高的逻辑门槛和“幻觉”风险。

Video as Code: A Deep Dive into HeyGen's Hyperframes
HyperFrames 的出现,标志着一种更纯粹的“视频即协议(Video as Protocol)”时代的到来。
它与 Remotion 的最大区别在于:
- Remotion 是给人类程序员准备的“摄像机”,功能强大但逻辑复杂。
- HyperFrames 是给 AI 准备的“标准接口”,它通过轻量级的声明式语法,消除了 AI 生成复杂代码时的不确定性。
HyperFrames 是如何工作的?
很多人好奇,不用鼠标拖拽,代码是怎么控制画面的?其实 HyperFrames 的核心只有三步,这种声明式语法简直是为程序员量身定制的:
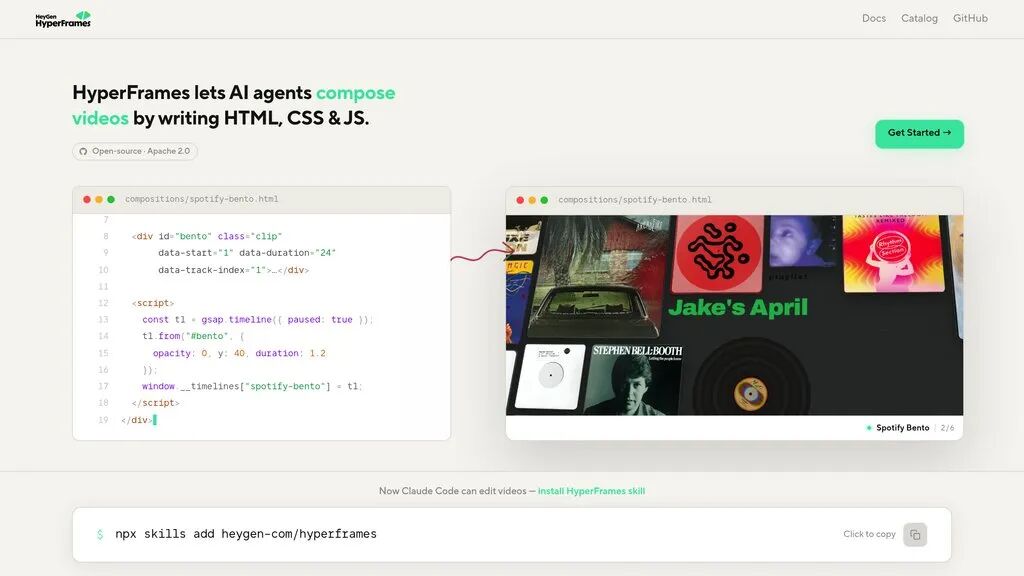
HyperFrames:開発者とAIエージェントがHTML、CSS、JavaScriptを記述してビデオを構成できるHeyGenのオープンソースビデオレンダリングフレームワーク。 - MOGE
1. 定义视觉容器(The Frame)
不同于传统的视频层,HyperFrames 允许你使用标准的 HTML/CSS 结构来定义布局。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
<div class="video-layout">
<!-- 数字人位置 -->
<hf-avatar id="host" src="my_avatar.mp4" />
<!-- 代码演示区 -->
<div class="code-overlay">
<pre><code id="step-1">println!("Hello HyperFrames");</code></pre>
</div>
</div>2. 注入动态数据(The Payload)
这是实现全自动出片的关键。你可以预留“槽位(Slots)”,通过一个简单的 JSON 文件,把你的 Obsidian 笔记内容 批量注入进去:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
{
"title": "Rust 与 HyperFrames 的碰撞",
"content": "今天我们要聊聊如何用代码驱动视频...",
"code_block": "struct AutomatedSystem { ... }",
"duration_hint": "auto"
}3. 驱动动画逻辑(The Sequencer)
借助内置对 GSAP 的支持,你可以用极其简洁的逻辑描述物体的运动。
- 无需计算帧数: 你只需说“文字在数字人说话时浮现”。
- 自动对齐: 框架会自动监听语音流(Audio Stream)的长度,并调整动画的结束点。
为什么 HyperFrames 是 AI Agent 的“梦中情框”?
如果你想搭一个全自动出片系统,HyperFrames 有三个无法替代的优势:
1. 极低的“幻觉”率
AI 写复杂的 React 组件经常会掉进闭包或状态同步的坑。而 HyperFrames 采用的是数据驱动的声明式逻辑。AI 只需要生成结构化的 JSON,告诉系统“这里放数字人,那里放代码块”,剩下的布局对齐交给框架。这种“约束性生产”保证了系统的极高稳定性。
2. 完美的“解耦”设计
它将“视觉模版”与“内容数据”完全分离。
你可以用 Rust 编写高性能的后端逻辑,负责处理数据抓取、语义提取和资源调度;而 HyperFrames 只负责最后的视觉呈现。这种架构对于追求 Local-first 和数据主权的开发者来说,具有天然的吸引力。
3. 动态时间轴适配
不再需要手动计算每一帧的毫秒数。HyperFrames 能够根据配音长度自动拉伸画面。这意味着你的 AI Agent 不再需要精通数学计算,只需专注于内容创作。

HyperFrames Explained: Build AI Videos with HTML (Full Guide) - YouTube
全自动视频工厂流程
想象一下这样一个闭环工作流:
- 输入层: 你在 Obsidian 里写下一篇深度技术笔记。
- 调度层: 本地 AI Agent 监控到特定标签,自动调用 LLM 提取金句,并匹配对应的代码高亮组件。
- 生成层: 系统调用 Rust 编写的生成器,快速产出符合 HyperFrames 协议的 JSON 配置文件。
- 渲染层: 结合 HeyGen 的数字人分身,系统在后台静默完成渲染合成。
全程 0 人工干预。当你合上电脑休息时,你的数字分身正在全网为你播报最新的技术见解。
总结
在这个 AI 浓度爆表的时代,原创性不再仅仅来自于文字,更来自于生产方式的革新。
利用 HyperFrames 搭建的系统,其核心壁垒不在于视频本身,而在于你背后那套 “代码即资产”的自动化逻辑。当别人还在为导出一段视频等待半小时的时候,你已经通过 Rust 驱动的流水线产出了一个系列的矩阵内容。
未来的内容之争,本质上是自动化程度的竞争。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号