Open LLM Leaderboard:AI模型的“奥运会”,如何看懂这场技术盛宴?

Open LLM Leaderboard:AI模型的“奥运会”,如何看懂这场技术盛宴?

沈宥
发布于 2026-04-28 19:21:41
发布于 2026-04-28 19:21:41
在AI模型发布如“下饺子”般密集的今天,一个客观、透明、可复现的排行榜,是区分“真金”与“镀金”的唯一标准。
每周,都有数十个新的开源大语言模型(LLM)高调亮相,伴随着“超越GPT-4”、“行业领先”等宣传语。面对如此信息洪流,开发者、研究者和企业决策者该如何判断一个模型的真实水平?
答案就是——Open LLM Leaderboard。由全球最大AI社区 Hugging Face 推出的这个榜单,被誉为 AI模型界的“奥运会” 和 **“照妖镜”**,它用一套标准化的评测体系,为所有开源模型提供了一个公平竞技的舞台。
今天,我们就来深度解析 Open LLM Leaderboard 的前世今生、核心价值以及如何利用它做出明智的技术选型。
🔍 一、什么是 Open LLM Leaderboard?
简单来说,它是一个动态更新的在线排行榜,专门用于评估和比较公开可用的大型语言模型的综合能力。
它的诞生背景
早期的模型评测多依赖于厂商自报的分数,缺乏统一标准,导致“刷榜”和“数据污染”问题严重。许多模型在公开数据集上表现优异,但在真实场景中却大打折扣。
为了解决这一痛点,Hugging Face 基于 Eleuther AI Language Model Evaluation Harness(一个强大的开源评估框架),构建了 Open LLM Leaderboard。其核心目标是:
- 标准化:为所有模型提供一个“统一考场”。
- 透明化:所有评测代码、数据和结果都公开可查。
- 去营销化:用客观数据说话,过滤掉浮夸的宣传。
🚀 二、重磅升级:Leaderboard v2 的“更难、更好、更快、更强”
随着模型能力的飞速提升,初代 Leaderboard 所使用的评测基准(如 MMLU, HellaSwag)逐渐“饱和”,无法有效区分顶尖模型的细微差距。
为此,Hugging Face 于2024年推出了 Open LLM Leaderboard v2,这是一次彻底的革新!
v2 的核心变化:评测基准全面换血
新版本摒弃了旧的、可能被“污染”的数据集,转而采用一系列未受污染、难度更高、更能反映模型真实能力的新基准:
表格
评测基准 | 核心能力 | 特点 |
|---|---|---|
MMLU-Redux | 专业知识 & 理解 | 对经典 MMLU 数据集进行清洗和重构,移除易被记忆的题目,考验真正的知识掌握。 |
MMLU-Pro | 复杂推理 & 专家级知识 | 题目由领域专家设计,难度远超原版 MMLU,堪称“博士级”考试。 |
BBH (Big-Bench Hard) | 复杂推理 | 从 Big-Bench 中筛选出最难的23项任务,专注于需要多步推理的问题。 |
AGIEval | 人类认知 & 考试能力 | 模拟人类参加的高难度考试,如高考、公务员考试、法学院入学考试(LSAT)等。 |
IFEval | 指令遵循 | 评估模型精确遵循复杂、细粒度指令的能力,这是构建可靠AI代理的关键。 |
GPQA | 专家级科学知识 | 问题由物理、生物、化学领域的博士设计,旨在测试模型是否具备真正的科学素养。 |
一句话总结 v2:**从“考记忆力”转向“考真本事”**,让排行榜的结果更具参考价值。
📊 三、排行榜怎么看?关键指标解读
访问 Open LLM Leaderboard 官网,你会看到一个清晰的表格。
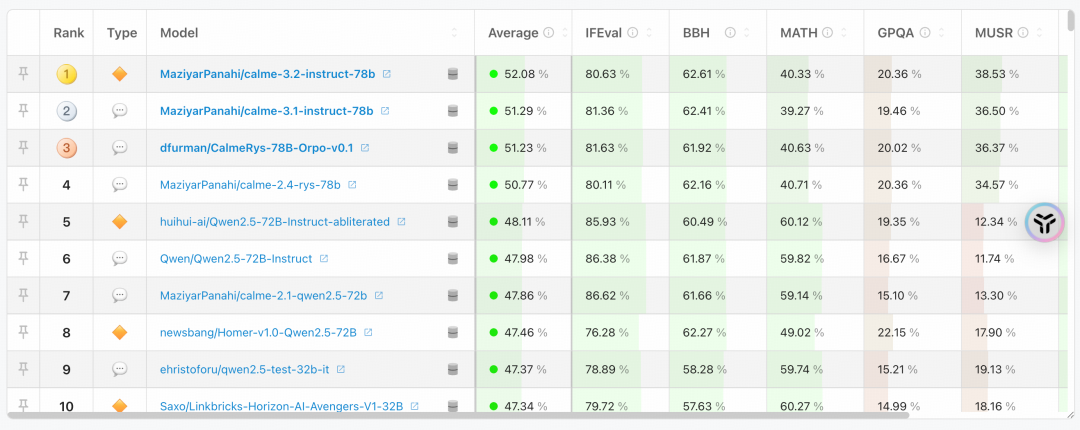
核心关注点
- Overall Score 综合得分: 各个基准测试分数的加权平均,是模型综合实力的快速参考。
- 各单项得分: 点击模型名称,可以查看其在 MMLU-Pro、BBH、IFEval 等每个具体基准上的详细表现。这对于按需选型至关重要。
- 如果你的应用需要强大的数学和代码能力,就重点看 MATH 和 HumanEval(如果包含)的分数。
- 如果你的应用是客服或指令执行机器人,就重点关注 IFEval 的分数。
- 模型类型: 区分是基础预训练模型(Base)还是经过指令微调的聊天模型(Instruct)。通常 Instruct 模型在对话和指令遵循任务上表现更好。
💼 四、如何用它指导实践?三大落地场景
场景1:技术选型,告别“盲人摸象”
- 痛点: 面对 Qwen、Llama、Mixtral 等众多优秀开源模型,不知如何选择。
- 方案: 直接上 Leaderboard,根据你的业务需求(如侧重中文、代码、推理),筛选并比较相关模型的单项得分。
- 案例: 一家金融科技公司需要一个能精准理解金融法规的模型。他们通过 Leaderboard 发现,某模型在 AGIEval 的法律子项上得分遥遥领先,从而快速锁定了候选模型。
场景2:模型研发,找到优化方向
- 痛点: 自己微调的模型效果不理想,不知道短板在哪。
- 方案: 将自己的模型提交到 Leaderboard 进行评测。通过详细的分项报告,可以清晰地看到模型在复杂推理上弱,还是在指令遵循上差,从而有针对性地改进数据或训练策略。
- 价值: 获得来自全球社区的客观反馈和认可,提升团队信心。
场景3:投资尽调,识别技术泡沫
- 痛点: 初创公司宣称其自研模型“性能卓越”,但缺乏第三方验证。
- 方案: 要求对方将模型提交至 Open LLM Leaderboard。一个敢于公开评测并在榜上有名的团队,其技术实力往往更值得信赖。
- 意义: 为投资人提供了一个去伪存真的“硬指标”。
⚠️ 五、重要提醒:排行榜的局限性
尽管 Open LLM Leaderboard 是目前最权威的开源模型评测平台,但我们也要理性看待其结果:
- 并非万能: 它主要衡量的是通用能力,对于特定垂直领域(如医疗、法律)的深度知识,可能需要结合专业领域的评测集(如 Open Medical LLM Leaderboard)。
- 不代表用户体验: 一个在 Leaderboard 上得分很高的模型,在实际对话中的流畅度、安全性、偏见控制等方面,仍需人工评估(如 LMSys Chatbot Arena 的众包投票)。
- 动态变化: 榜单会随着新模型的加入和评测基准的更新而不断变化,今天的冠军,明天可能就被超越。
💡 写在最后
Open LLM Leaderboard 的存在,极大地推动了AI领域的开放、透明和良性竞争。它不仅是研究人员的“成绩单”,更是开发者和企业的“导航仪”。
在这个技术日新月异的时代,学会看懂并善用这样的工具,能让你在AI浪潮中始终立于不败之地。
一句话总结: 不要只听厂商怎么说,要看 Leaderboard 上怎么排。 下次当你需要选择一个大模型时,不妨先打开这个链接,让数据为你指明方向。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号