DeepSeek-V4,终于发布,很强!


之前说过很多次的狼来了,这次狼是真的来了,推迟了 N 多次的 DeepSeek-V4 在经历过过程芯片适配,上线又回滚等多次事件后,终于如约而至。
刚刚,DeepSeek 官方公众号发文:DeepSeek-V4 预览版:迈入百万上下文普惠时代。
全新 DeepSeek-V4 的预览版本正式上线。
V4 拥有百万字超长上下文,在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。
模型按大小分为两个版本:

图片
DeepSeek-V4-Flash,更快更便宜一点,在处理简单的任务上面和 Pro 的版本没太大差距,但如果在难度系数更大的任务上,推荐使用 Pro 的版本。
DeepSeek-V4-Flash,极致性价比,适合高频、简单任务,提供快速响应。简单推理和Agent能力媲美Pro版
DeepSeek-V4-Pro,极致性能,面向复杂逻辑、深度思考和高性能场景。采用新的 Megamerge MoE架构。
现在登录官网什么,就已经是 V4了。

根据官方的报道,DeepSeek-V4-Pro:性能比肩顶级闭源模型,什么叫做比肩顶级闭源模型。
大家看看下面的对比图。
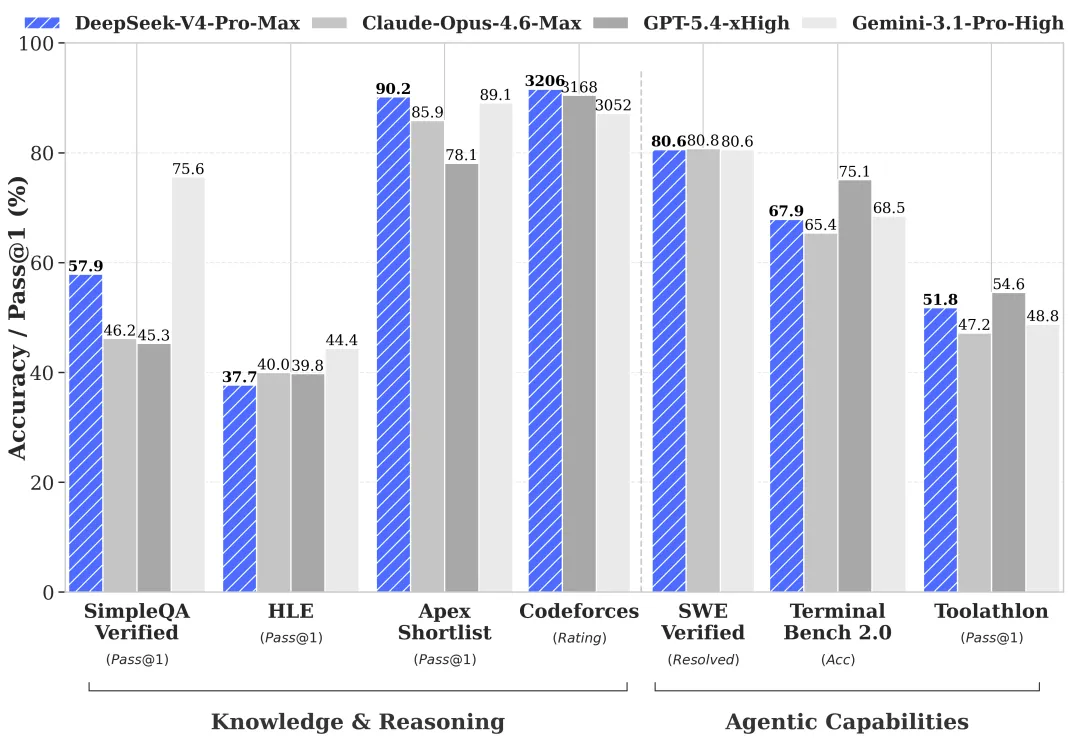
图片
就是在多项测试中,已经显著拉齐甚至超过了 Claude Opus-4.6 和 Gpt-54,还有 Gemini-3.1。
这里面很有意思的一点是, DeepSeek 只对比了 Cluade、ChatGPT 和 Gemini。
也就是说,在 DeepSeek 的心中,只有这 3 家才是它的竞争对手,大家要知道这3家已经是美国最顶尖的 AI 大模型公司。
这 3 家,每年在 AI 大模型上面投入的资金、人才密度,比 DeepSeek 要多多少倍,而 DeepSeek 只是一家小公司,还是开源的。
这些更新有哪些亮点,稍微总结一下:
1、支持接近百万级 token 上下文(1M+)。
开创了一种全新的注意力机制,在 token 维度进行压缩,相比于传统方法大幅降低了对计算和显存的需求。
从现在开始,1M(一百万)上下文将是 DeepSeek 所有官方服务的标配。
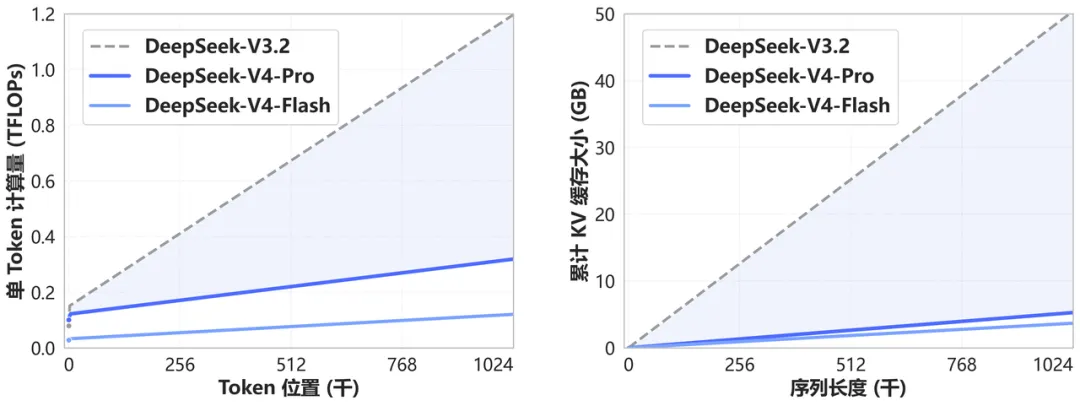
图片
DeepSeek-V4 和 DeepSeek-V3.2 的
2、Agent 能力专项优化
针对Claude Code、OpenCode、CodeBuddy等主流Agent产品进行了深度优化,在代码任务、文档生成任务等方面表现均有提升。
Agentic Coding能力已达到开源模型最佳水平。内部评测显示,其使用体验优于Sonnet 4.5,交付质量接近Opus 4.6
3、在数学、STEM(科学、技术、工程、数学)及竞赛级代码等推理测评中,均超越所有已公开评测的开源模型,达到世界顶级水平。
4、V4-Pro版本的世界知识储备,已大幅领先其他开源模型,仅次于顶尖闭源模型Gemini-Pro-3.1
5、深度适配华为昇腾算力:V4将运行在华为最新的昇腾(Ascend)芯片上。
为此,工程师团队重写了核心代码,完成了从CUDA到CANN的生态迁移,并与华为昇腾实现了 FP4量化精度的深度优化。
6、使用了 Mega MoE 和 Hyper-Connection 等新技术。
并引入了 DSA 与 NSA 相结合的稀疏注意力架构。DSA专注于让模型生成更优质的答案,而NSA则确保处理超长文本时速度更快、成本更低。
只能说,DeepSeek 那个曾经的王者,又回来了!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号