6.7% 到 68.3%:Harness Engineering 六大支柱如何重塑 AI Agent 开发
原创
6.7% 到 68.3%:Harness Engineering 六大支柱如何重塑 AI Agent 开发
原创
运维有术
发布于 2026-04-27 00:14:12
发布于 2026-04-27 00:14:12
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 85 篇,AI 星探「2026」系列第 9 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
封面图 - Harness Engineering 核心架构全景
图 1:Harness Engineering 核心架构全景
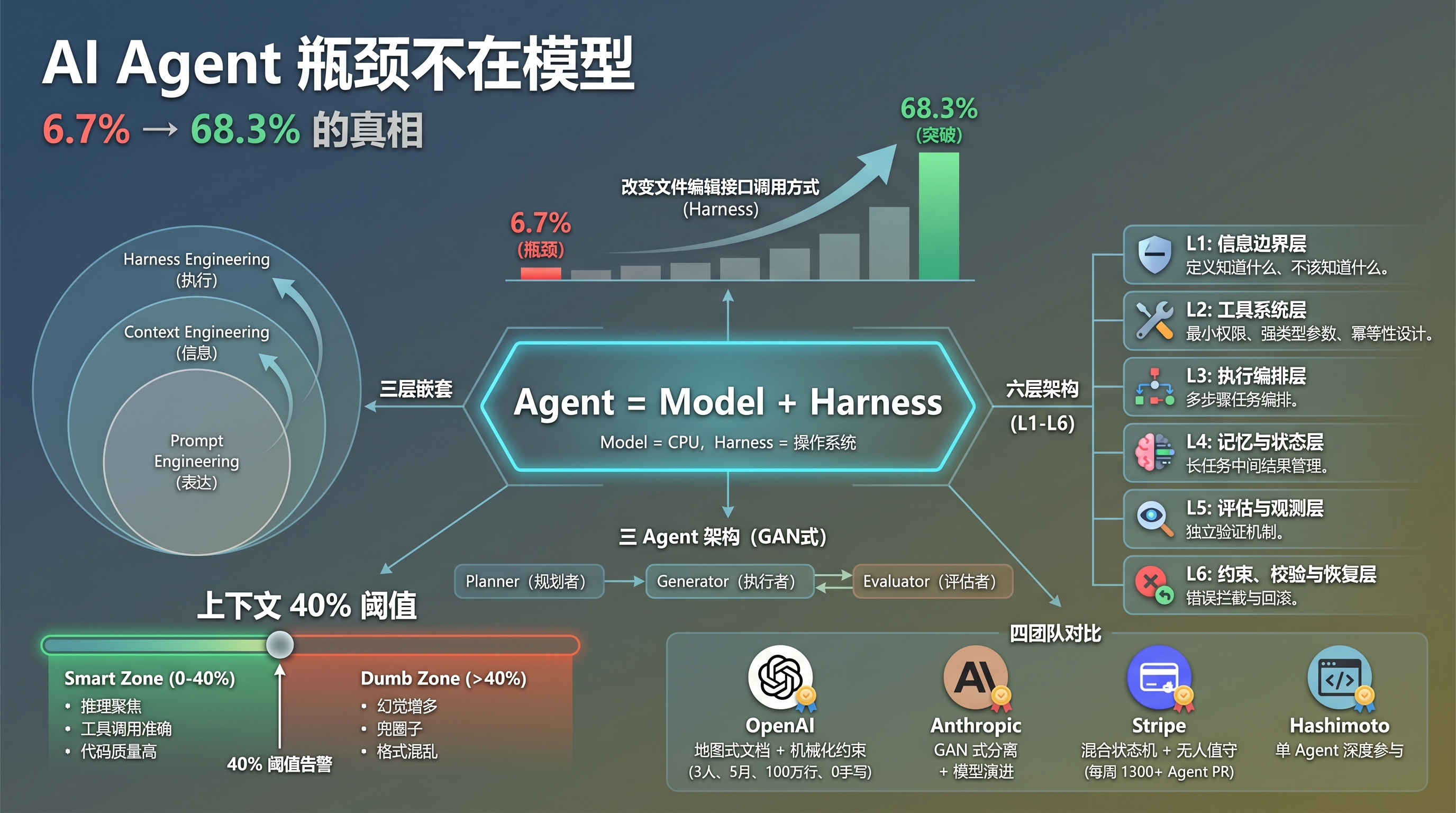
Can.ac 做了一个实验,结果让很多人坐不住了。
同一个模型,只是换了文件编辑接口的调用方式,编码基准分数从 6.7% 直接跳到 68.3%。模型没变,上下文没变,连 prompt 都没变——变的只是模型外围那套让它和世界交互的系统。
这不是个例。LangChain 在 Terminal Bench 2.0 上只改了 Agent 运行环境,模型固定不动,排名从全球第 30 升到第 5,得分从 52.8% 提升到 66.5%。OpenAI 用 3 个人、5 个月、100 万行代码、零手写,靠的全部是 Harness 的工程体系。
这些数据指向同一个结论:当模型能力达到一定水平后,系统设计才是效果的主要瓶颈。
1. Agent = Model + Harness:一个把系统切开的公式
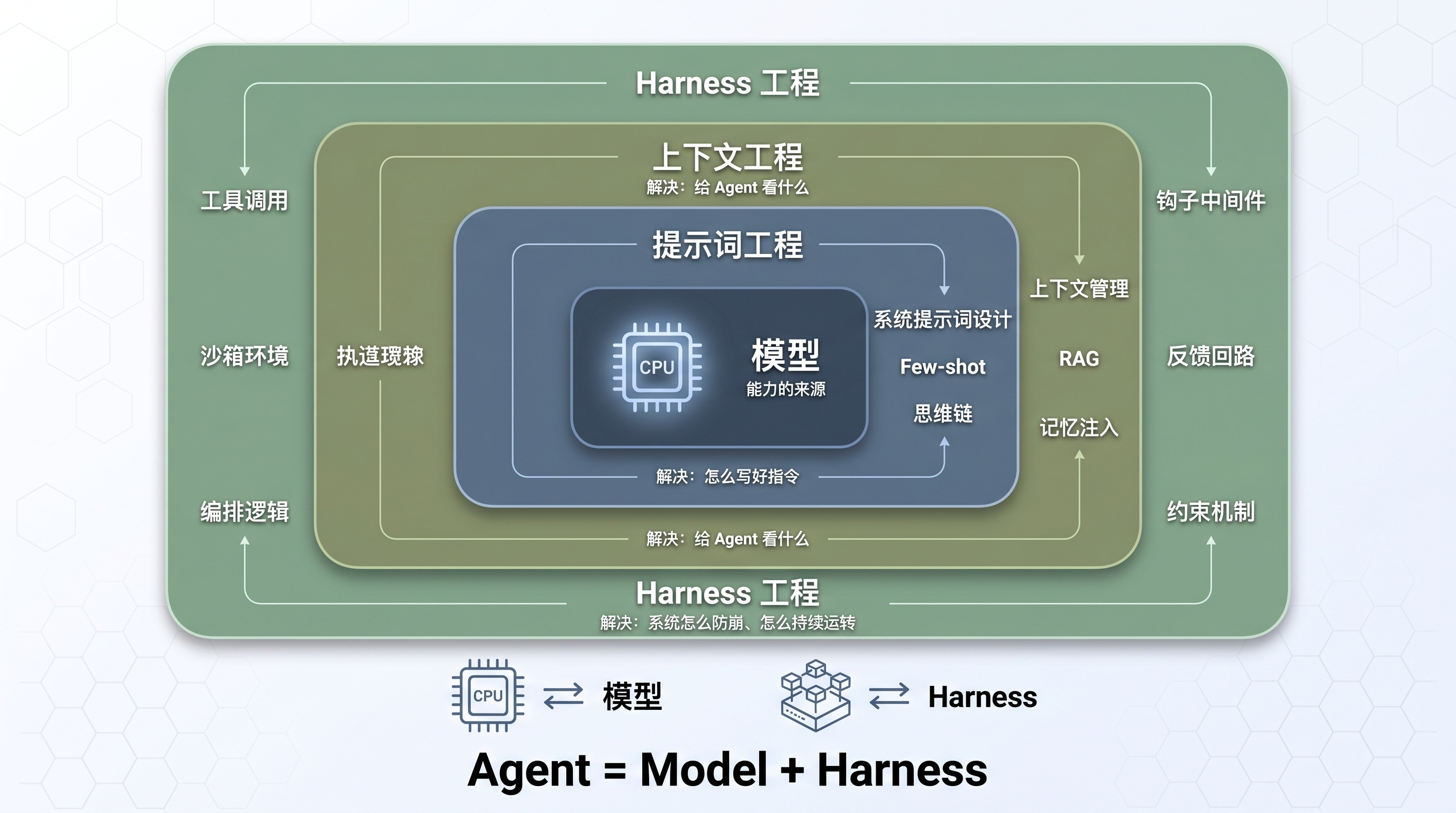
Agent = Model + Harness 三层嵌套架构
图 2:Agent = Model + Harness 三层嵌套架构
LangChain 把这件事用一句话说透了:Agent = Model + Harness。
模型是 CPU,Harness 是操作系统。CPU 再强,OS 拉胯也白搭。你装了最新款芯片,跑一个崩溃不断的系统,体验还不如老芯片配稳定的 OS。
Harness 就是模型之外的一切:系统提示词、工具调用、文件系统、沙箱环境、编排逻辑、钩子中间件、反馈回路、约束机制。模型本身只是能力的来源,只有通过 Harness 把状态、工具、反馈和约束串起来,它才真正变成一个 Agent。
三层嵌套关系
翻了一圈文档,发现很多人把 Prompt Engineering、Context Engineering 和 Harness Engineering 当成三件并列的事。实际上它们是嵌套关系,每一层解决的是完全不同的问题:
层级 | 解决什么 | 典型工作 |
|---|---|---|
Prompt Engineering | 表达 - 怎么写好指令 | 系统提示词设计、Few-shot、CoT |
Context Engineering | 信息 - 给 Agent 看什么 | 上下文管理、RAG、记忆注入 |
Harness Engineering | 执行 - 系统怎么防崩、怎么持续运转 | 约束执行、熵管理、反馈回路 |
简单任务里提示词就够了。依赖外部知识的任务需要上下文管理。但在长链路、可执行、低容错的真实场景里,Harness 才是决定成败的东西。一线团队的重心都放在了 Harness 上,原因就在这里。
有一个容易踩的坑:LangChain 发现当前的 Agent 产品(如 Claude Code、Codex)是模型和 Harness 一起训练的,这导致一种过拟合——换了工具逻辑后模型表现会变差。Opus 在 Claude Code 的 Harness 下得分,远低于它在其他 Harness 中的得分。所以为你的任务选择 Harness 时,不要被模型的默认 Harness 束缚。
2. 六层架构:从定义边界到兜底恢复

六层架构图
图 3:Harness Engineering 六层架构
理解 Harness 有两种思路。一种是"缺什么补什么"——模型做不到的,一个个补上。另一种是从系统设计角度看,一个成熟的 Harness 有清晰的层次结构。
业界把 Harness Engineering 细化为六层架构。可以类比成给一个新手员工搭建的完整工作环境:
L1:信息边界层
解决什么:Agent 该知道什么、不该知道什么。
核心工作是定义角色与目标,裁剪无关信息,结构化组织任务状态。这一层决定了 Agent 的注意力集中在哪里。
OpenAI 的做法是让 AGENTS.md 只当目录用(约 100 行),详细规则放在子文档中按需加载。这和很多人的直觉相反——不少人把 AGENTS.md 当成"超级 System Prompt",恨不得把所有规则塞进一个文件,结果上下文窗口被撑爆,Agent 反而更蠢了。
Anthropic 的 Claude Code 在这方面设计比较完善:CLAUDE.md 作为项目级上下文的核心载体,每次会话启动时自动加载。/memories/ 目录按三个作用域分层管理:用户记忆(跨工作区全局生效)、会话记忆(当次会话)、仓库记忆(当前项目)。前 200 行核心文件在会话开始时自动加载,其余按需读取,天然实现了延迟加载。
L2:工具系统层
解决什么:Agent 怎么跟外部世界交互。
工具设计有几个核心原则:
- 最小权限暴露:Agent 在任何时刻只应获得当前任务所需的最小工具集合,而非全量工具列表
- 强类型参数定义:用 JSON Schema 或 OpenAPI 规范严格定义参数类型和取值范围,在架构层防止参数注入
- 幂等性设计:相同参数的重复调用不产生副作用,Agent 可安全重试
Anthropic 的实践表明:在 SWE-bench 测试中,工程师在工具设计上花费的时间远远超过在 prompt 调优上的时间,最终带来了更好的 Agent 可靠性。与其提供 20 个功能模糊的工具,不如提供 5 个边界清晰、文档完善的工具。
L3:执行编排层
解决什么:多步骤任务怎么串起来。
让模型像人一样走完"理解目标 → 判断信息 → 分析 → 生成 → 检查"的完整轨道。Anthropic 在其三 Agent 架构中把任务拆解为 Sprint:Generator 按 Sprint 逐个实现功能,每个 Sprint 有明确的完成标准。Generator 和 Evaluator 在 Sprint 开始前先协商一个"合同",约定做什么、怎么验证,然后才开始写代码。
L4:记忆与状态层
解决什么:长任务中间结果怎么管。
独立管理当前任务状态、中间产物和长期记忆,防止系统混乱。核心思路是把"记忆"从 Agent 的内部状态外化为可读取的文件系统——类似于操作系统让无状态的 CPU 运行有状态的程序。
Nicholas Carlini 在编译器项目里的做法很极端:跑了 2000 个 Claude Code 会话,每个会话都是独立的、从干净状态开始。日志全部写进文件,用 grep 友好的单行格式(ERROR: [reason]),主动控制上下文污染。
L5:评估与观测层
解决什么:Agent 怎么知道自己做对了没有。
建立独立于生成过程的验证机制。Anthropic 的 Evaluator Agent 用 Playwright MCP 实际点击运行中的应用,按产品设计深度、功能性、视觉设计、代码质量等维度打分。OpenAI 把 Chrome DevTools Protocol 接入了 Agent 运行时,Agent 能自己抓 DOM 快照、截图。
关键点:可观测性不只是给人看的,也是给 Agent 看的。当"把启动时间降到 800ms 以下"能被 Agent 自己测量和验证时,优化就从玄学变成了工程。
L6:约束、校验与恢复层
解决什么:出错了怎么办。
预设规则拦截错误,失败时提供重试或回滚机制。OpenAI 的原话很直接:"If it cannot be enforced mechanically, agents will deviate."——如果不能机械化地强制执行,Agent 就会偏离。
LangChain 的三个 Middleware 直接体现了这一层:PreCompletionChecklistMiddleware 在 Agent 准备退出时拦截,检查是否运行了测试;LoopDetectionMiddleware 跟踪文件编辑次数,编辑 N 次后提示"考虑重新考虑方法"。把"软约束"(Prompt)变成"硬约束"(代码逻辑)。
⚠️ 不要试图一开始就搭齐六层。 从 L1(信息边界)和 L6(约束与恢复)入手,投入产出比最高。L1 决定了 Agent 知道该干什么,L6 决定了它搞砸了能不能拉回来。
3. 上下文架构:40% 阈值与渐进式披露
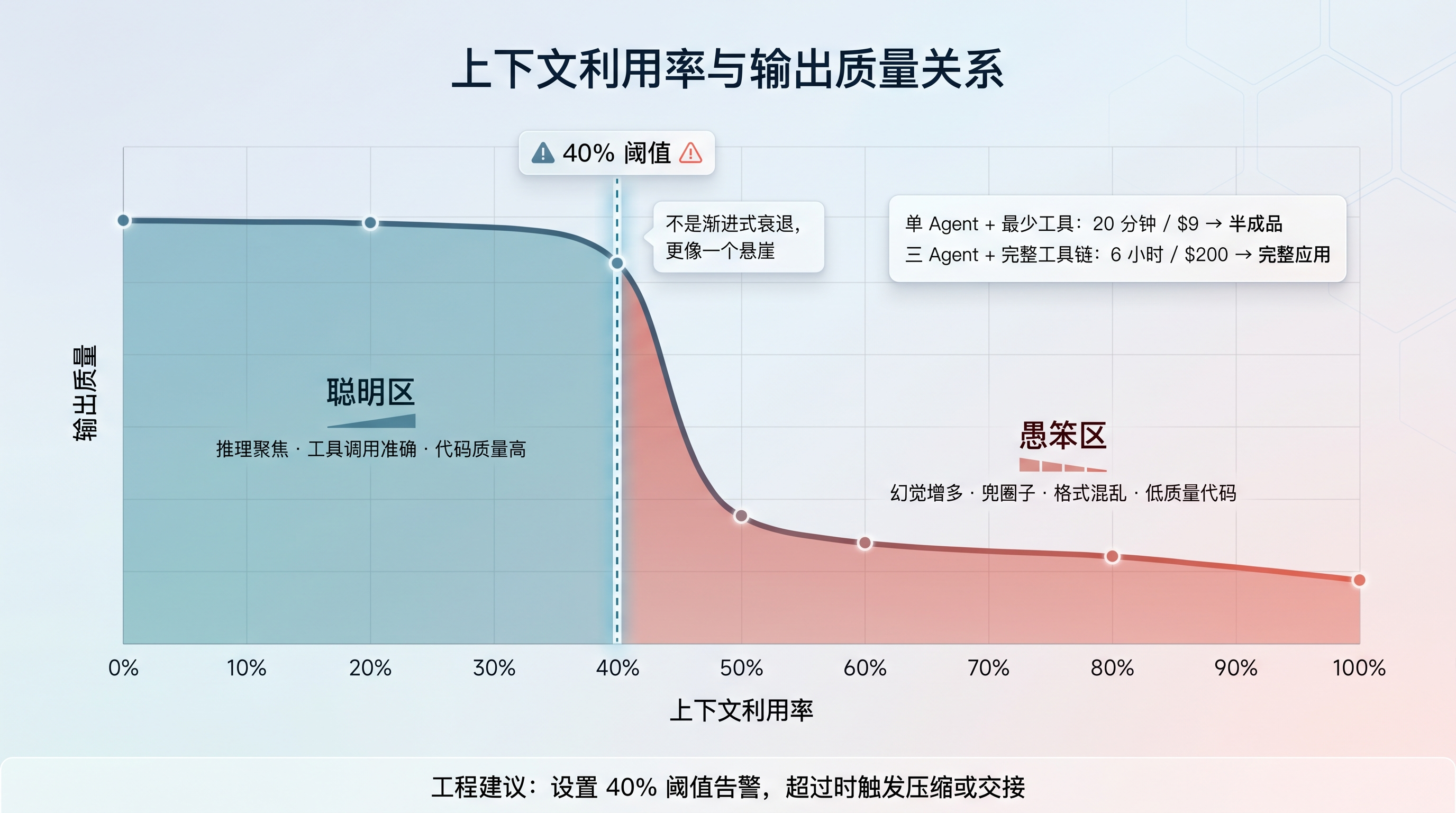
上下文利用率曲线图
图 4:上下文利用率 40% 阈值——聪明区与愚笨区
Dex Horthy 观察到一个现象:168K token 的上下文窗口,用到大约 40% 的时候,Agent 的输出质量就开始明显下降。
区间 | 表现 |
|---|---|
0 - ~40%(Smart Zone) | 推理聚焦、工具调用准确、代码质量高 |
超过 ~40%(Dumb Zone) | 幻觉增多、兜圈子、格式混乱、低质量代码 |
这不是渐进式衰退,更像一个悬崖。Anthropic 在官方实验中也碰到了类似的问题,而且比"变蠢"更隐蔽——上下文焦虑(Context Anxiety)。
Sonnet 4.5 在上下文快填满时,会变得犹豫,倾向于提前收工,哪怕任务还没做完。光靠压缩不够。Anthropic 最终的做法是直接清空上下文窗口,但通过结构化的交接文档把关键状态留下来。他们的对比数据很有说服力:
配置 | 耗时 | 花费 | 效果 |
|---|---|---|---|
Solo Harness(单 Agent + 最少工具) | 20 分钟 | $9 | 跑不起来的半成品 |
Full Harness(三 Agent + 完整工具链) | 6 小时 | $200 | 完整可用的应用 |
上下文的生命周期管理
上下文架构的核心是为上下文建立完整的生命周期管理,而非被动等待模型性能劣化:
- 注入阶段:按优先级选取必要信息注入上下文
- 监控阶段:实时统计 token 用量,计算利用率
- 压缩阶段:利用率超过 40% 时,将历史轮次摘要化
- 归档阶段:将有价值的中间结论迁移至持久存储
渐进式披露 vs 百科全书式
你的目标不是给 Agent 塞更多信息,而是让它在任何时候都运行在干净、相关的上下文里。
OpenAI 的做法是地图式文档:AGENTS.md 只有 100 行,指向 docs/ 目录下更深层的设计文档、架构图、执行计划。Agent 按需检索,每次检索的内容都在高注意力区域(前 20% 和后 20%),而不是被埋在"注意力黑洞"里。
Harrison Chase 说得好:"Context engineering is not about compression, it's about architecture."——不要压缩信息,要搭建信息的建筑。
工程建议:在生产环境中监控上下文利用率是第一优先级。设置 40% 阈值告警——当 Agent 的上下文占用超过这个比例时,触发上下文压缩或任务交接。等到 Agent 已经变蠢了再处理就晚了。
4. 架构约束:用代码替代 Prompt 劝说
这是 Harness Engineering 里反直觉的一个原则。
当你在 prompt 里写下"请不要删除用户数据"时,你是在用语言劝说一个随机采样系统。模型在复杂场景中天然不稳定——同样的规则描述,在不同的上下文状态下可能产生截然不同的执行效果。
架构约束的做法是:代码层面根本不提供删除功能,或在工具定义时强制要求二次确认。
Claude Code 的分级权限模式
Claude Code 把架构约束设计成了核心的权限模型,内置四种模式:
模式 | 行为 | 场景 |
|---|---|---|
| 文件编辑和 Shell 命令均需逐一确认 | 日常开发 |
| 文件编辑自动执行,命令仍需确认 | 写操作安全后加速 |
| 只读操作,生成计划等待批准 | 复杂任务前的方案审查 |
| 跳过所有权限检查 | 受信任的自动化脚本 |
通过 allowedTools 和 deniedTools 配置,可以精确控制可用工具范围。MCP 接入的外部工具,参数校验由 MCP 服务器侧负责,天然将约束逻辑与 Agent 主体解耦。
OpenAI 的机械化约束
OpenAI 给每个业务领域定义了固定的分层结构:
Types → Config → Repo → Service → Runtime → UI依赖方向不能反过来。怎么保证?自定义 Linter 加结构测试。违反了就报错,报错消息里不光告诉你哪里错了,还直接告诉你怎么改。Agent 在被纠错的同时就被"教会"了正确的做法。
这个设计思路的核心洞察是:传统的错误消息是给人看的,Harness 时代的 Linter 消息直接包含修复建议,便于 Agent 实现自主闭环。
你在项目中用过类似的约束方案吗?欢迎在评论区聊聊具体做法。
5. 熵治理与 GAN 式分离架构
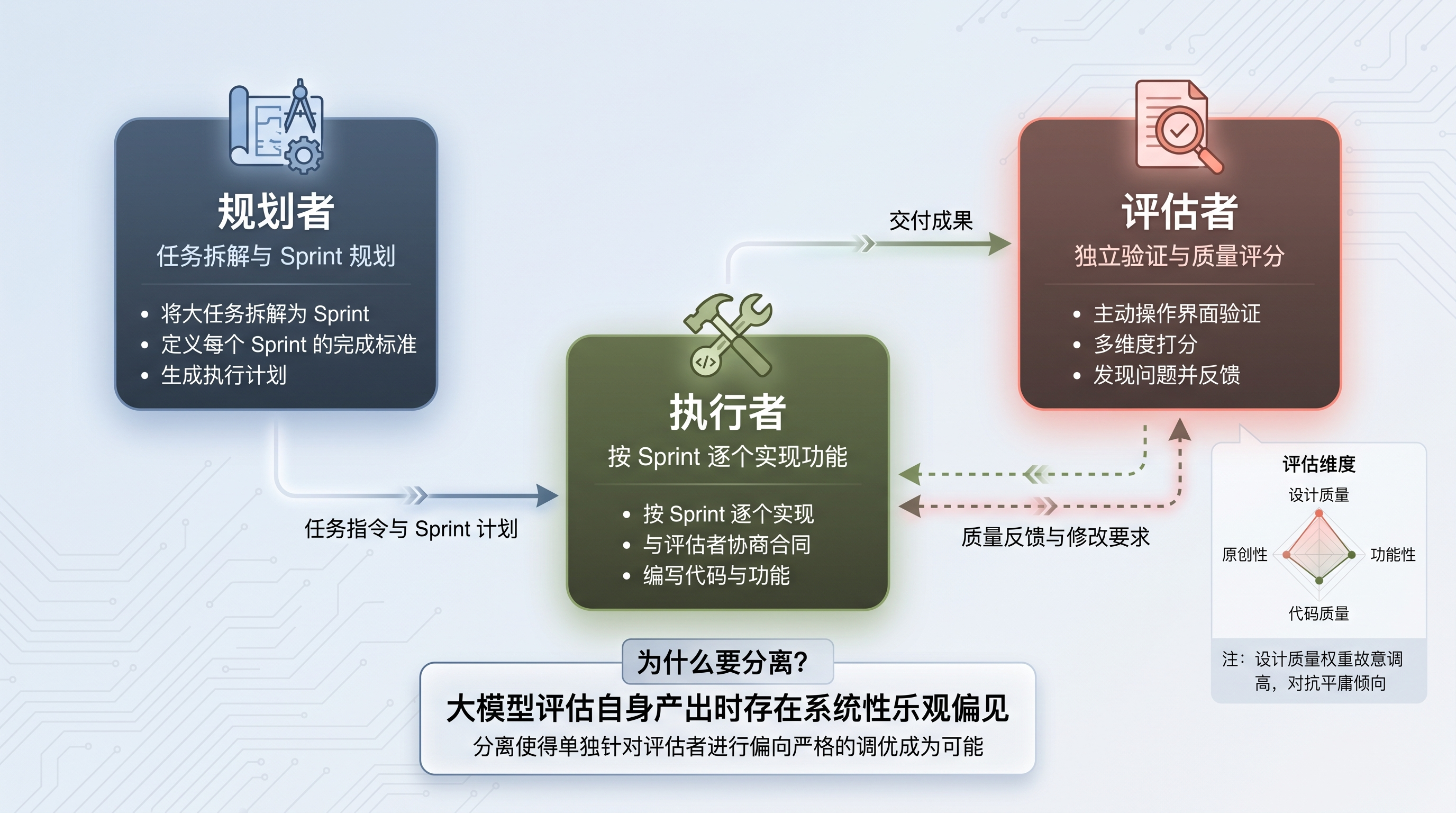
GAN 式三 Agent 架构
图 5:GAN 式三 Agent 协作架构——规划者 → 执行者 ⇄ 评估者
热力学第二定律告诉我们,孤立系统的熵只会增加。Agent 系统也不例外——随着任务执行,上下文不断积累,规则不断叠加,系统状态越来越复杂,最终变得难以预测。
上下文熵增的来源
上下文熵增来源:
- 持续累积的对话历史
- 工具调用轨迹与中间结果
- 随时间叠加的矛盾指令
- 死亡状态引用(已不存在的任务)
- 大量重复信息挤占上下文空间熵治理的核心理念:保留决策结论,丢弃推理过程。 蒸馏时区分需要保留和可以丢弃的信息:
应保留 | 可丢弃 |
|---|---|
已做出的决策及理由 | 冗长的中间推理链 |
已发现的关键事实 | 失败的探索路径 |
当前任务状态快照 | 重复出现的相同内容 |
已遭遇的错误及规避方案 | 已过期的临时状态 |
OpenAI 一开始每周五花 20% 的时间手动清理 AI 生成物中的低质量代码。后来这事被自动化了——后台 Agent 定期扫描,找文档不一致、架构违规和冗余代码,自动提交清理 PR。清理的速度跟上了生成的速度,才能可持续地跑下去。
Context Reset:不是压缩,是重启
Anthropic 在官方博客中明确区分了两种上下文管理策略:
压缩(Compaction):将对话早期内容就地摘要化,使同一个 Agent 在缩短后的历史上继续执行。可以释放空间,但因为未提供干净的起点,无法消除上下文焦虑。
上下文重置(Context Reset):彻底清空当前窗口,启动一个全新 Agent 会话,通过精心设计的交接文件(Handoff Artifact)传递上一个 Agent 的任务状态与下一步骤。
用程序员的直觉来理解:这就像程序碰到内存泄漏时的解法——你不去手动释放每一个内存块(对应压缩),而是直接重启进程,从检查点恢复状态。虽然粗暴,但在长任务场景里,一个干净重启的 Agent 比一个塞满了历史信息的 Agent 表现好得多。
GAN 式生成/评估分离
Anthropic Labs 的 Prithvi Rajasekaran 借鉴了 GAN(生成对抗网络)的思路,设计了一个三 Agent 架构:
Planner(规划者)→ Generator(执行者)⇄ Evaluator(评估者)为什么要分离?Anthropic 的实验揭示了一个关键问题:大模型在评估自身产出时存在系统性乐观偏见。即便产出质量明显欠佳,模型也倾向于给出积极评价。更棘手的是,即使模型识别出了真实存在的问题,它也容易"自我说服"这些问题不算严重。
分离本身不能立即消除评估者的乐观倾向,但它使得单独针对评估者进行"偏向严格"的调优成为可能。Rajasekaran 在官方博客中描述了这个调优过程:"Getting the evaluator to perform at this level took work. Out of the box, Claude is a poor QA agent. In early runs, I watched it identify legitimate issues, then talk itself into deciding they weren't a big deal and approve the work anyway."
评估者还需要主动探测能力——不能仅凭静态截图打分,而应像真实用户一样主动操作界面、调用 API、验证边界条件,才能发现被动查看无法暴露的深层缺陷。
打分标准本身也有讲究:前端设计方面,设计质量和原创性的权重被故意调得比功能性和代码质量更高。因为模型倾向于做出"功能齐全但长相平庸"的东西,权重调整是在引导它往更难的方向使劲。
6. 一线团队实战:四种架构决策对比
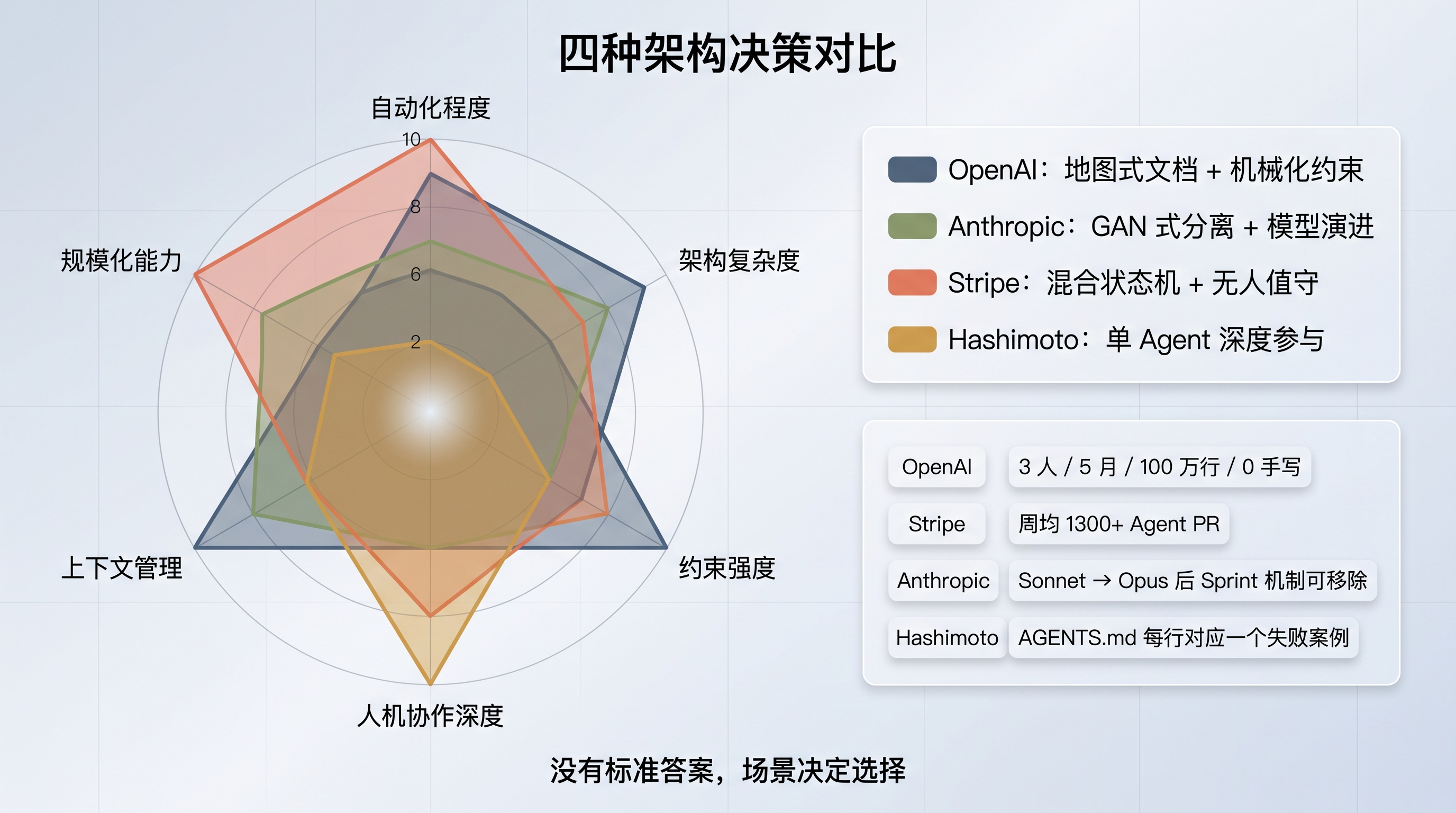
四团队架构决策对比
图 6:OpenAI、Anthropic、Stripe、Hashimoto 四团队六维度架构决策对比
OpenAI、Anthropic、Stripe、Mitchell Hashimoto,这四个团队的实践从不同角度揭示了 Harness 设计的核心问题。放在一起看会更有感觉——大家遇到的坑和总结出的经验,惊人地一致。
OpenAI:地图式文档 + 机械化约束
指标 | 数值 |
|---|---|
团队规模 | 3 名工程师(后扩至 7 人) |
持续时间 | 5 个月(2025 年 8 月起) |
代码规模 | 约 100 万行 |
手写代码 | 0 行 |
合并 PR 数 | 约 1500 个 |
日均 PR/人 | 3.5 个 |
五大方法论:
- 地图式文档:
AGENTS.md约 100 行当目录用,渐进式披露 - 机械化约束:自定义 Linter + 结构测试,报错自带修复方法
- 可观测性接入:Chrome DevTools Protocol 接入 Agent 运行时
- 熵管理:后台 Agent 定期扫描,清理速度跟上生成速度
- 仓库即事实源:写在 Slack 里的知识对 Agent 等于不存在
OpenAI 自己也说了,这个结果"不应该被假设为在缺少类似投入的情况下可以复现"。但其中的思维方式可以在任何规模上立即采用。
Anthropic:从 GAN 式架构到模型演进
Anthropic 的实验最有意思的不是三 Agent 架构本身,而是一个发现:当他们把模型从 Sonnet 4.5 换成 Opus 4.6 后,Sprint 机制可以完全移除,Evaluator 从每个 Sprint 检查变成了最后只做一次检查。
这说明 Harness 中的每个组件都编码了一个关于"模型靠自己做不到什么"的假设,而这些假设值得定期压力测试。随着模型能力提升,之前必要的保护机制可能已经冗余。
Anthropic 对此总结得很精辟:"The space of interesting harness combinations doesn't shrink as models improve. Instead, it moves."——模型越强,不是不需要 Harness 了,而是 Harness 的设计空间转移到了新的位置。
Stripe:混合状态机 + 无人值守
Stripe 的 Minions 系统代表了另一个极端:每周超过 1300 个完全由 Agent 生产的、不含任何人写代码的 PR 被合并。开发者发一条 Slack 消息,Agent 就从写代码到跑 CI 到提 PR 全部搞定。
编排设计思路不是把所有事情都交给 Agent 判断,也不是全部走确定性流程,而是一个混合状态机:该确定的地方确定(跑 lint、推送代码),该灵活的地方灵活(实现功能、修 CI 错误)。
Stripe 的核心理念是:"What's good for humans is good for agents."——为人类工程师投资的开发工具和开发者体验,在 Agent 上也直接产生了回报。
Mitchell Hashimoto:不跑多 Agent,一个人搞定
Hashimoto 的路线和 Stripe 完全相反——他坚持一次只跑一个 Agent,保持深度参与。他的六步进阶路线:
步骤 | 核心做法 |
|---|---|
| 让 Agent 在能读文件、跑程序的环境里直接干活 |
| 每件事做两次——一次自己做,一次让 Agent 做 |
| 每天最后 30 分钟给 Agent 布置任务 |
| 挑出 Agent 几乎一定能做好的任务后台跑 |
| 每当 Agent 犯错,就工程化一个解决方案让它永远不再犯 |
| 目标是 10-20% 的工作时间有后台 Agent 运行 |
Ghostty 项目里的 AGENTS.md,每一行都对应着一个过去的 Agent 失败案例。这不是写完就扔的静态文档,而是一个持续积累的防错系统。
四种模式放在一起看:OpenAI 和 Stripe 追求规模化和自动化,Anthropic 追求质量和自纠错,Hashimoto 追求深度参与和渐进积累。没有标准答案,场景决定选择。
7. 工程实践路线图:P0 到 P2
综合一线团队的实践经验,梳理了一个按优先级的行动路线。
P0:不用犹豫,立即可以做
行动 | 为什么 |
|---|---|
创建 | Agent 每次启动自动加载,犯错就更新,形成反馈循环 |
构建自定义 Linter + 修复指令 | 错误消息里直接告诉 Agent 怎么改,纠错的同时在"教" |
把团队知识放进仓库 | 写在 Slack/Wiki 里的知识对 Agent 等于不存在 |
P1:P0 做完之后,可以考虑这些
行动 | 为什么 |
|---|---|
分层管理上下文 | 不要把所有东西塞进一个文件,渐进式披露 |
建立进度文件和功能列表 | JSON 格式追踪功能状态,Agent 不太会乱改结构化数据 |
给 Agent 端到端验证能力 | 浏览器自动化让 Agent 能像用户一样验证功能 |
控制上下文利用率 | 尽量不超过 40%,增量执行 |
P2:有余力再考虑
行动 | 为什么 |
|---|---|
Agent 专业化分工 | 每个 Agent 携带更少无关信息,留在 Smart Zone |
定期垃圾回收 | 确保清理速度跟得上生成速度 |
可观测性集成 | 把"性能优化"从玄学变成可度量 |
8. 还没有答案的问题
说实话,翻完所有公开资料后,发现 Harness Engineering 还有几个大的空白。
棕地项目怎么改造? 所有公开案例全是绿地项目(从零开始的新项目)。现实中绝大多数团队面对的是已经跑了多年的代码库——怎么把 Harness 引入一个十年历史、没有架构约束、到处是技术债的项目?Thoughtworks 的 Birgitta Böckeler 把它比作"在从未用过静态分析工具的代码库上运行静态分析——你会被警报淹没"。她还提出了一个关键概念"Ambient Affordances":环境本身的结构特性(类型系统、模块边界、框架抽象)决定了 Harness 能做多好。
怎么验证 Agent 做对了事? 大家擅长"约束不做错事",但"验证做对了事"远未解决。Böckeler 的批评很尖锐:很多团队只是让 AI 生成测试套件然后看它是否绿色通过,但用 AI 生成的测试来验证 AI 生成的代码,本质上是在用同一双眼睛检查自己的作业。
Harness 该做厚还是做薄? Manus 五次重写越做越简单,OpenAI 五个月越做越复杂。场景决定:通用产品追求最小化,特定产品可以高度定制。而且随着模型变强,已有 Harness 应该定期简化——Anthropic 的实测已经验证了这一点。
总结
一句话概括 Harness Engineering 做的事情:承认模型有边界,然后把边界之外的需求一个个工程化地补上。
有一句话整理资料的时候反复在各家的文档里出现:模型决定了系统的上限,Harness 决定了系统的底线。
六层架构从定义边界到兜底恢复,三大支柱从上下文架构到熵治理到架构约束,一线团队从 OpenAI 的地图式文档到 Anthropic 的 GAN 式分离到 Stripe 的混合状态机——做法各不相同,但核心理念一致:不要指望模型自己变好,要把"模型做不到"的假设编码成可执行、可验证、可演进的工程系统。
而且这套系统需要跟着模型一起演化。Anthropic 的实验已经证明:更强的模型不是不需要 Harness,而是需要不同设计的 Harness。每隔一段时间,逐一移除组件、观察影响、裁撤冗余——这本身就是 Harness Engineering 的一部分。
相关资源
Anthropic 官方博客(Harness Design for Long-Running Applications):https://www.anthropic.com/engineering/harness-design-long-running-apps
OpenAI 官方博客(Harness Engineering):https://openai.com/index/harness-engineering/
Mitchell Hashimoto(My AI Adoption Journey):https://mitchellh.com/writing/my-ai-adoption-journey
Birgitta Böckeler(Martin Fowler 网站):https://martinfowler.com/articles/exploring-gen-ai/harness-engineering.html
Stripe Minions 系统:https://stripe.dev/blog/minions-stripes-one-shot-end-to-end-coding-agents
LangChain(The Anatomy of an Agent Harness):https://blog.langchain.com/the-anatomy-of-an-agent-harness/
如果你的团队也在做 AI Agent 开发,转发给同事看看——说不定你们踩的坑,Harness 工程学里早有答案。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号