最强大模型GPT-5.5来了,实测:不止是会说人话了

最强大模型GPT-5.5来了,实测:不止是会说人话了

Ai学习的老章
发布于 2026-04-24 21:09:01
发布于 2026-04-24 21:09:01
Introducing the world's most powerful model
今天继续聊新模型
刚刚,OpenAI 放出了 GPT-5.5
我第一反应是:这节奏有点凶
昨天还在看各家模型打架,今天 OpenAI 又把桌子往前推了一截。官方说它是“最聪明、最直觉化”的模型,重点能力放在 Agentic Coding、电脑操作、知识工作、科研分析这些硬活上
说人话:更适合让它接一整段活,而非只回答一个问题
升级 Codex 之后,已经能直接用了
先说结论
我简单测试了一圈,感觉很明确:
GPT-5.5 最大的变化,是它更懂“我要干什么”
很多模型很强,但用起来像在带实习生。你得把边界、格式、语气、步骤、例外都交代清楚,少说一句就开始自由发挥
GPT-5.5 给我的感觉是,它会更快抓住任务形状。尤其是写代码、改稿子、做前端、整理信息这些场景,它少绕路,少废话,少自我感动
当然,也没成神
我拿经典数手指挑战试了一下,失败
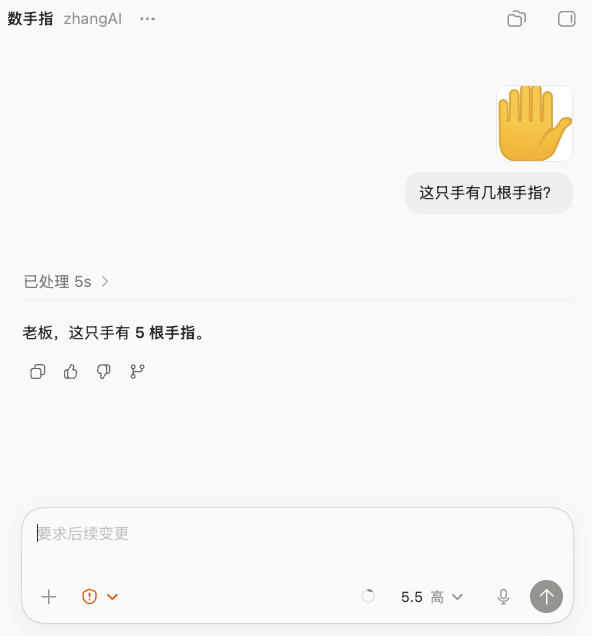
这个测试很适合泼冷水
别看到新模型就以为天下无敌,视觉细节、复杂空间关系、奇怪的人类刁钻题,模型依然会翻车
但另一个测试,我让它做阅读理解 + SVG 代码生成 + 审美表达
确实是一流水平

这个地方我挺有感触
过去很多模型做 SVG,会把“能画出来”当目标。GPT-5.5 更像是在理解内容之后,顺手把视觉层级、构图、文字密度一起处理了。最终效果谈不上设计师毕业作品,但已经明显脱离“AI 生成味儿太冲”的阶段
还有一个测试,作为彩蛋,文末公布
官方到底说了什么
OpenAI 官方文章标题很直接:
这张图里最关键的词,其实是:real work
OpenAI 这次想讲的,不只是“模型分数更高了”,它更想强调 GPT-5.5 是一个能干活的模型
我把官方信息拆成一张表,读起来更清楚:
方向 | 官方强调 | 老章翻译 |
|---|---|---|
Agentic Coding | 写代码、调试、跨文件改动、长期任务 | 更适合丢给它一整个工程问题 |
Computer Use | 操作软件、跨工具移动、看屏幕、点击、输入 | 更像能一起用电脑干活的搭子 |
Knowledge Work | 调研、分析数据、生成文档、表格、PPT | 办公室里那些杂活,它能接更多 |
Scientific Research | 多阶段科研分析、代码、数据、论文上下文 | 能陪研究人员从问题走到实验结果 |
Inference Efficiency | 速度接近 GPT-5.4,但能力更强,token 更省 | 贵归贵,但复杂任务上少返工 |
Safety | 网络安全、生物能力做了更强评估和限制 | 能力越强,护栏也越厚 |
官方原文里有一句话很重要:你可以给 GPT-5.5 一个混乱的、多步骤任务,让它自己规划、用工具、检查结果、穿过模糊地带继续推进
这句话我觉得比 benchmark 更关键
因为过去我们用模型,很多时候像在写“超详细说明书”;现在 OpenAI 想把它推进到“你说目标,它自己拆活”的阶段
从官方给出的能力图谱看,GPT-5.5 主要有四条主线:
第一,代码能力继续增强
官方给出的 Terminal-Bench 2.0 是 82.7%,GPT-5.4 是 75.1%
SWE-Bench Pro 是 58.6%,GPT-5.4 是 57.7%
Expert-SWE 内部评测是 73.1%,GPT-5.4 是 68.5%
这个提升看起来有的很大,有的没那么夸张。但我更在意 Terminal-Bench 这种命令行长期任务,因为它真正测的是规划、执行、出错后修正、继续往前走
编码评测 | GPT-5.5 | GPT-5.4 | 我的理解 |
|---|---|---|---|
Terminal-Bench 2.0 | 82.7% | 75.1% | 长程命令行任务更稳 |
SWE-Bench Pro | 58.6% | 57.7% | 真实 GitHub issue 略有提升 |
Expert-SWE | 73.1% | 68.5% | 长周期工程任务更强 |
第二,知识工作更像真人工作流
官方提到,GPT-5.5 在 Codex 里生成文档、表格、幻灯片更强,也更适合做运营调研、财务建模、把混乱业务输入整理成计划
OpenAI 自己也给了几个内部例子:
- 通讯团队用它分析 6 个月演讲请求数据,做评分和风险框架
- 财务团队用它审查 24,771 份 K-1 税表,总计 71,637 页
- Go-to-Market 团队有人用它自动生成周报,每周节省 5 到 10 小时
这几个例子很有代表性
AI 真正进入工作流,核心价值常常在处理这些又碎、又长、又不能随便错的东西
第三,长上下文终于更有意义了
Codex 里 GPT-5.5 是 400K context window,API 计划给到 1M context window
但长上下文不能只看长度,还要看能不能在长上下文里找对东西
官方长上下文评测里,Graphwalks BFS 1mil f1,GPT-5.5 是 45.4%,GPT-5.4 是 9.4%;OpenAI MRCR v2 8-needle 512K-1M,GPT-5.5 是 74.0%,GPT-5.4 是 36.6%
这两个数字的意思很朴素:上下文拉长以后,GPT-5.5 更不容易迷路
长上下文评测 | GPT-5.5 | GPT-5.4 |
|---|---|---|
Graphwalks BFS 1mil f1 | 45.4% | 9.4% |
Graphwalks parents 1mil f1 | 58.5% | 44.4% |
MRCR 512K-1M | 74.0% | 36.6% |
这对读 PDF、审代码库、看会议记录、整理大项目文档都很关键
以前模型上下文很长,但你总担心它“看是看了,脑子没带上”
这次至少从官方数据看,长上下文检索和推理能力往前走了一步
第四,科研和安全能力都被单独拎出来了
官方页里这张图挺有代表性,是 GPT-5.5 在 Codex 里从一句 prompt 做出来的代数几何可视化应用:
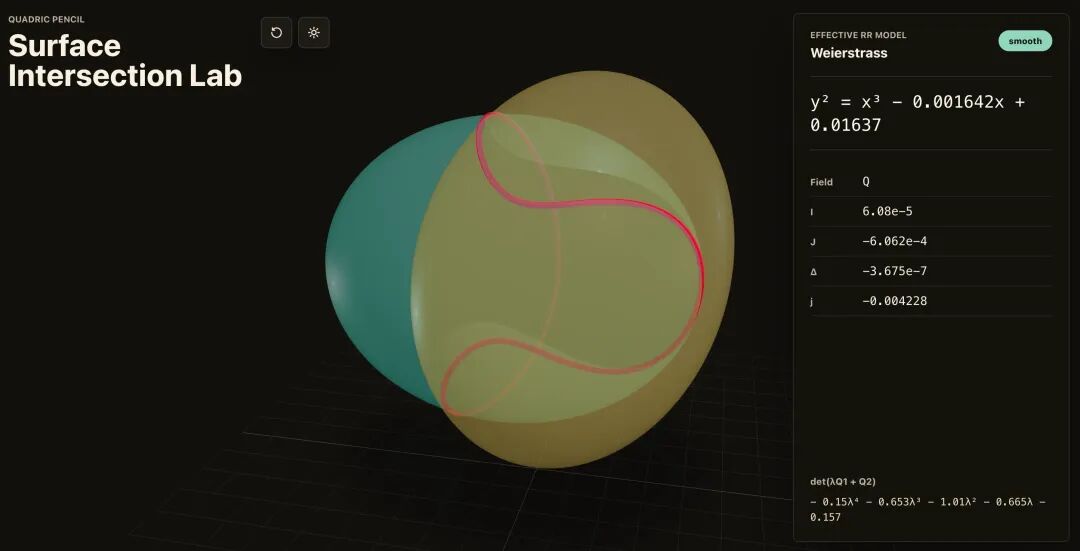
GPT-5.5 生成的代数几何可视化应用
GPT-5.5 生成的代数几何可视化应用
科研这块,官方重点提到 GeneBench、BixBench、FrontierMath、GPQA Diamond 等评测
比如 GeneBench,GPT-5.5 是 25.0%,GPT-5.4 是 19.0%;BixBench 是 80.5%,GPT-5.4 是 74.0%;FrontierMath Tier 4 是 35.4%,GPT-5.4 是 27.1%
这些题已经超出普通聊天,更接近“读数据、理解实验、写代码、找问题、解释结果”的组合题
安全这块也很明显
Capture-the-Flags 内部任务,GPT-5.5 是 88.1%,GPT-5.4 是 83.7%;CyberGym 是 81.8%,GPT-5.4 是 79.0%
这说明它在安全攻防理解上也更强了,所以官方同时强调了更严格的防护策略
这地方我挺支持
模型越来越能写代码、找漏洞、操作工具,如果护栏跟不上,麻烦会很大
第五,推理效率这次也值得看
OpenAI 说 GPT-5.5 在真实服务里的 per-token latency 能接近 GPT-5.4,同时能力更强
更有意思的是,他们还说 Codex 和 GPT-5.5 参与了服务它自己的基础设施优化
其中一个例子是负载均衡和分区启发式算法,分析了数周生产流量模式后,token 生成速度提升超过 20%
这段很科幻
模型帮助优化运行模型的系统,听起来像套娃,但这大概率就是未来 AI 基建的常态
最后说可用性和价格:
使用入口 | 可用范围 | 关键信息 |
|---|---|---|
ChatGPT | Plus、Pro、Business、Enterprise | 可用 GPT-5.5 Thinking |
ChatGPT Pro | Pro、Business、Enterprise | 可用 GPT-5.5 Pro |
Codex | Plus、Pro、Business、Enterprise、Edu、Go | 400K context window |
Codex Fast mode | Codex 中可选 | token 生成速度 1.5 倍,费用 2.5 倍 |
API | 即将上线 | gpt-5.5 是 1M context window |
API 价格也公布了:
API 模型 | 输入价格 | 输出价格 |
|---|---|---|
gpt-5.5 | 5 美元 / 100 万 token | 30 美元 / 100 万 token |
gpt-5.5-pro | 30 美元 / 100 万 token | 180 美元 / 100 万 token |
Batch 和 Flex 是标准 API 价格的一半,Priority 是标准价格的 2.5 倍
这个价格不便宜
所以我的建议很简单:日常碎活用普通模型,复杂工程、长文档、多步骤任务,再把 GPT-5.5 请出来
编程:少一点折腾
我最关心的还是 Codex
因为现在 AI 编程模型的问题,很多时候已经从“会不会写代码”,变成了“会不会添乱”
你让它修一个小 bug,它顺手重构半个项目;
你让它补一个测试,它开始发明一套新架构;
你让它按现有风格改,它偏要展示一下自己的抽象能力
这些事,大家应该都遇到过
GPT-5.5 给我的第一印象是:它更收得住
它更愿意先读上下文,再判断改哪里;更愿意沿着原项目风格走;也更能理解“这只是一个小改动”
这点对工程师很重要
模型智商高当然好,但真正让人愿意长期使用的,是它能不能降低心智负担。你交代一句,它往正确方向走三步,这才叫生产力
官方也提到,GPT-5.5 在 Codex 里更擅长长程任务,能做实现、重构、调试、测试、验证这些连续动作
说白了,就是更像一个能扛事的 Agent
前端:审美终于往前走了
前端这个方向,我之前对很多模型都很苛刻
原因很简单:前端差一点就很丑
按钮间距差一点,信息层级差一点,颜色克制差一点,整个页面立刻变成“后台管理系统 2016 怀旧版”
GPT-5.5 这次在前端上确实有进步
网友实测也提到,同样提示下,它生成的 dashboard 比 GPT-5.4 更自然;如果先用 GPT Image 2 做设计方向,再让 GPT-5.5 实现,组合效果会更稳
这个思路很值得借鉴
以后做前端原型,可以这样玩:
先让图像模型给视觉方向
再让 GPT-5.5 还原交互和代码
最后人工收口细节
我试下来也有类似感觉
GPT-5.5 对“看起来像一个真实产品”这件事更敏感了。它会注意留白、卡片密度、图标按钮、状态提示这些小东西
当然,如果你完全不给设计约束,它也会偶尔走回老路。所以前端提示词里,还是建议明确说清楚:目标用户、产品类型、信息密度、交互状态、移动端适配
写作:它真的更会说人话
这次最让我意外的,其实是写作
很多模型写中文,有一种很微妙的“正确废话感”
每句话都没错,每段都很完整,读完什么也没留下
GPT-5.5 这个问题好了一些
它更愿意直接进入重点,句子也没那么端着。写消息、邮件、帖子、小段文案时,它更容易贴近人的表达习惯
我看到一段网友日常使用后的评价,说得挺准:
❝GPT-5.5 感觉更直接、更专注,也更能理解我真正想问什么
这句话我认可
尤其是“更直接”
AI 时代,模型越来越聪明之后,真正稀缺的反倒是克制。别动不动就写小论文,别每次都强行平衡观点,别把一句人话翻译成三段企业公文
这也是为什么我把标题写成:会说人话了
Claude 这边也很热闹

先生,你刚刚被 GPT 5.5 击败了
先生,你刚刚被 GPT 5.5 击败了
这两天还有一个很有意思的小插曲
Anthropic 官方发了一篇复盘,解释最近 Claude Code 质量波动的问题
重点有三个:
- 3 月 4 日,Claude Code 的默认 reasoning effort 从 high 调成了 medium,目的是降低延迟,但用户明显感到变笨;4 月 7 日撤回
- 3 月 26 日,一个缓存优化 bug 导致旧 thinking 在部分会话里持续丢失,模型会显得健忘、重复、工具选择奇怪;4 月 10 日修复
- 4 月 16 日,一个减少 verbosity 的系统提示影响了编码质量;4 月 20 日撤回
这个复盘很真诚,也很有参考价值
大模型产品现在已经复杂到一个程度:能力不只来自模型本体,还来自默认参数、系统提示、上下文管理、工具调用、缓存策略、产品 UI
所以你感觉一个模型“突然变笨”,有时候真未必是幻觉
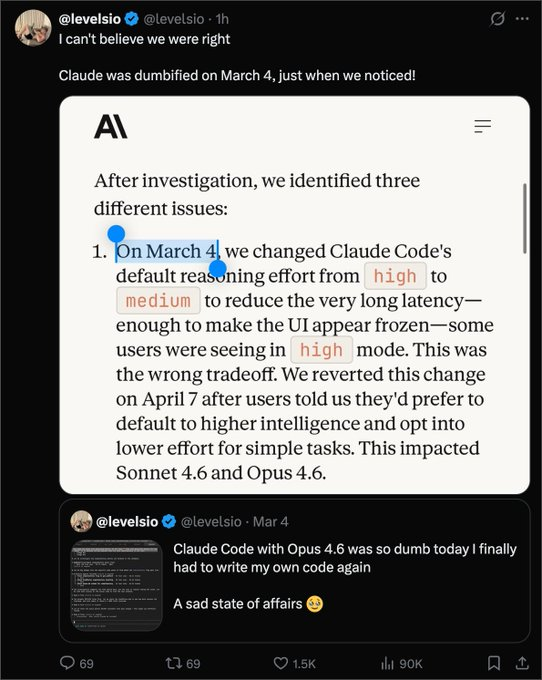
更有意思的是,这个复盘刚好在 GPT-5.5 发布当天出来
时间点过于微妙
商战,精彩
我的使用建议
如果你问 GPT-5.5 值不值得用,我的建议是:
值得,但别把它当万能药
适合用 GPT-5.5 的场景:
- 大型项目里的复杂代码修改
- 多文件重构、调试、补测试
- 需要跨工具完成的资料整理
- 长文档阅读、归纳、改写
- 前端原型实现
- 有明确目标的科研/数据分析辅助
暂时没必要用 GPT-5.5 的场景:
- 简单问答
- 日常翻译
- 普通摘要
- 几十行以内的小脚本
- 低价值批量生成内容
原因也很现实:它贵
贵模型要干贵活
One More Thing
文末放个彩蛋
菜单公布:本文由 GPT-5.5 辅助撰写,我做了些许修改
你看出来了吗?
#GPT55 #OpenAI #Codex #AI编程 #ClaudeCode
如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号