英伟达加速版 Qwen3.6-35B,双4090本地部署,性能实测

英伟达加速版 Qwen3.6-35B,双4090本地部署,性能实测

Ai学习的老章
发布于 2026-04-24 21:07:40
发布于 2026-04-24 21:07:40
我用 vLLM 部署的这个版本
本文测下 Red Hat 量化团队 Qwen3.6-35B-A3B-NVFP4(4-bit 浮点)的性能
NVFP4 量化版:Red Hat 出品
模型地址:huggingface.co/RedHatAI/Qwen3.6-35B-A3B-NVFP4
模型地址:huggingface.co/RedHatAI/Qwen3.6-35B-A3B-NVFP4
这个 NVFP4 版本由 Red Hat AI 团队使用 llm-compressor 完成量化
❝llm-compressor 是 vLLM 项目下的量化工具库,专门为 vLLM 推理做优化,支持 GPTQ、AWQ、SmoothQuant、FP8、NVFP4 等多种方案
NVFP4 的核心:权重和激活都量化到 FP4(W4A4),使用 E2M1 格式 + 16 元素微块缩放
Red Hat 跑了 GSM8K Platinum 评测,初步结果相当惊艳:
版本 | GSM8K Platinum 准确率 |
|---|---|
原版 BF16 | 95.62 |
NVFP4 量化版 | 96.28 |
恢复率 | 100.69% |
量化后精度居然比原版高了一丢丢
当然这有统计波动因素,但至少说明 NVFP4 量化对精度的损失可以忽略不计
实测部署:vLLM + Docker
我在双 4090 GPU 服务器上用 Docker + vLLM 部署了这个模型
Docker 启动命令:
docker run -d --name qwen36-35b-a3b-int4 \
--gpus all \
-v /data/llm-models/Qwen3.6-35B-A3B-NVFP4:/model \
-p 8000:8000 \
vllm/vllm-openai:v0.19.1 \
--model /model \
--served-model-name qwen3.6-35-int4 \
--tensor-parallel-size 2 \
--max-model-len 102400 \
--kv-cache-dtype fp8 \
--enable-prefix-caching \
--language-model-only \
--max-num-batched-tokens 8192 \
--max-num-seqs 24 \
--default-chat-template-kwargs '{"enable_thinking": false}'
几个关键参数说明:
--tensor-parallel-size 2:双卡张量并行--kv-cache-dtype fp8:KV Cache 用 FP8 存储,进一步节省显存--language-model-only:跳过视觉编码器,把显存省给 KV Cache--enable-prefix-caching:开启前缀缓存加速--default-chat-template-kwargs '{"enable_thinking": false}':默认关闭思考模式,需要的时候再开
部署数据一览
从启动日志里扒出来的关键数据:
指标 | 数值 |
|---|---|
vLLM 版本 | 0.19.1 |
模型加载耗时 | 24 秒 |
模型显存占用 | 10.61 GiB(每卡) |
torch.compile 编译耗时 | 39.49 秒 |
初始化总耗时 | 136.49 秒 |
GPU KV Cache 容量 | 494,656 tokens |
最大并发(102K 上下文) | 17.18x |
CUDA Graph 显存 | 0.81 GiB |
非 Blackwell GPU 跑 NVFP4
WARNING: Your GPU does not have native support for FP4 computation
but FP4 quantization is being used. Weight-only FP4 compression
will be used leveraging the Marlin kernel. This may degrade
performance for compute-heavy workloads.
我的 GPU 设备能力是 8.9(Ada Lovelace 架构),不支持原生 FP4 计算
vLLM 自动退回到 Marlin 内核做 weight-only FP4 解压——推理时权重从 FP4 解压到高精度再参与计算,激活量化的加速效果就没了
GPU 架构 | FP4 原生支持 | NVFP4 实际行为 |
|---|---|---|
Blackwell (B100/B200) | 支持 | W4A4 全量化加速 |
Hopper (H100/H200) | 不支持 | Weight-only + Marlin 解压 |
Ada (L40S/4090) | 不支持 | Weight-only + Marlin 解压 |
所以如果你和我一样用 Ada 架构的 GPU,NVFP4 的核心收益是省显存
推理速度的提升主要来自模型变小后降低的内存带宽需求,要拿到 NVFP4 真正的 W4A4 全量化加速,需要 Blackwell GPU
还有两个值得留意的细节:
- Mamba Cache 实验性支持:日志里提示 prefix caching 对 Mamba 层的支持还在实验阶段。Qwen3.6 用了 Gated DeltaNet(一种线性注意力变体),vLLM 对这类层的缓存机制还在打磨中
- Custom AllReduce 被禁用:因为 GPU 之间不支持 P2P 直连,退回到 NCCL 通信。多卡并行的效率会有一点点损失
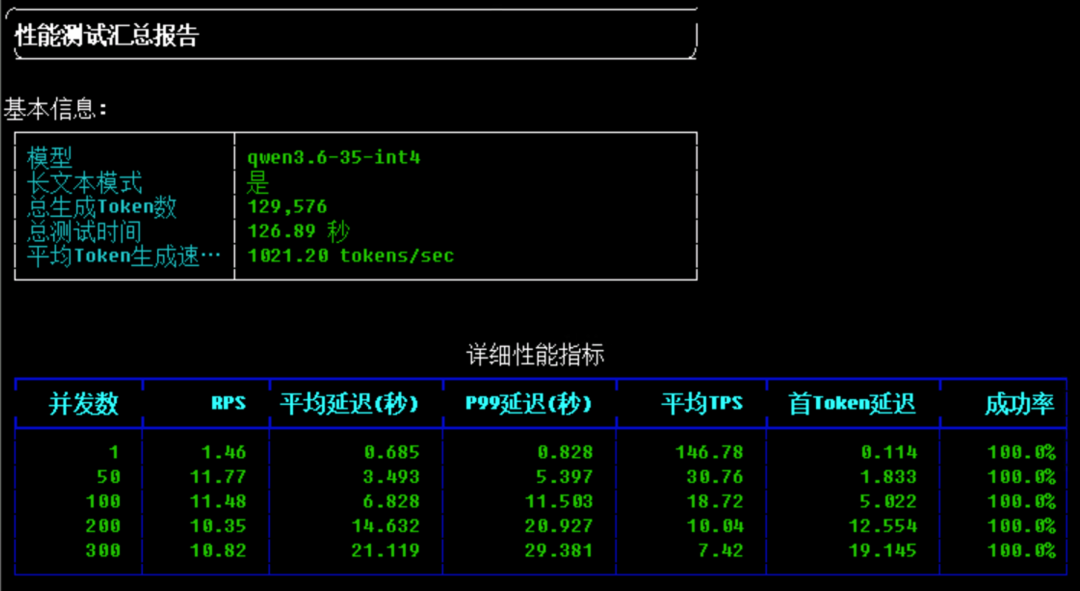
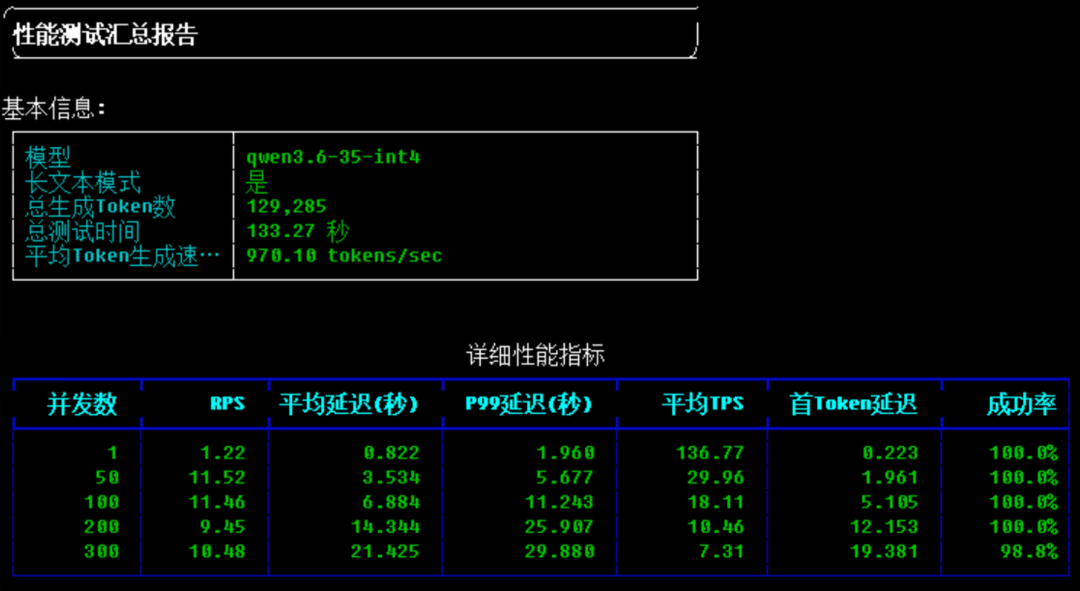
对比前文同为 vLLM 0.19.1 拉起的 Qwen3.6-35B-A3B-AWQ-4bit
各方面都有提升
部署建议
硬件选择:
- 最低 2x RTX 4090(24GB),可以跑 100K 上下文,或许可以更高,我没再加
- 有 Blackwell GPU 的话能获得最完整的 NVFP4 加速
推理框架:
- vLLM 版本 0.19.0 以上,推荐 0.19.1,前文我也测了 v0.17 也可以
- 官方同时支持 SGLang 和 KTransformers
采样参数建议:
- Thinking 模式:
temperature=1.0, top_p=0.95, top_k=20, presence_penalty=1.5 - 精确编程任务:
temperature=0.6, top_p=0.95, top_k=20, presence_penalty=0.0 - 非思考模式:
temperature=0.7, top_p=0.8, top_k=20, presence_penalty=1.5
Agent 场景推荐开启 preserve_thinking,能在多轮对话中保留思维链上下文,减少重复推理的 token 消耗
#Qwen3.6 #NVFP4 #量化 #vLLM #本地部署
制作不易,如果这篇文章对你有帮助,可否帮我个忙。给我个三连击:点赞、转发和在看。若可以再给我加个星标,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号