代码实战 | ERA5数据下载、K指数计算与ERA5原生K指数对比分析

代码实战 | ERA5数据下载、K指数计算与ERA5原生K指数对比分析

用户11172986
发布于 2026-04-24 19:36:32
发布于 2026-04-24 19:36:32
在本项目你将学会:
- 使用
cdsapi下载 ERA5 的 pressure levels 与 single levels 数据; - 由 500 / 700 / 850 hPa 的温度与湿度信息手工计算 K 指数;
- 分别采用
wrf.td与MetPy两种方式计算露点温度; - 与 ERA5 原生提供的
k_index(变量名kx)进行绘图对比; - 对两者差异的来源进行简要分析。
本 Notebook 同时保留了可复现实验代码,既可作为文章阅读,也可直接运行。
1. 背景与问题
前些日子吉林通化局的崔老师发了个问题,说是自己算的K指数跟era5的K指数对不上。我试了试,还真是这样,到底为什么呢
K 指数(K-index)是一个经典的对流不稳定度指标,常用于雷暴潜势的初步诊断。其常见定义为:
其中:
- 分别为 850、700、500 hPa 的气温;
- 分别为 850、700 hPa 的露点温度。
在 ERA5 中,可以直接下载原生的 k_index,也可以下载温度和湿度场后自行计算。
本文以 2026-03-01 00UTC 东亚大范围的单时次案例为例,对这一问题做一个可复现的示范。
2. 数据与实验设置
- 时间:2026-03-01 00:00 UTC
- 区域:东亚大范围,
[60, 70, 10, 145],顺序为north west south east - pressure levels 变量:
temperature、specific_humidity - single levels 变量:
k_index - 网格分辨率:0.25° × 0.25°
需要注意:
- ERA5 pressure levels 是规则等压面产品;
- ERA5 single levels 中的
k_index是 ECMWF 预先诊断好的单层产品; wrf.td需要的是 mixing ratio,而 ERA5 下载的q是 specific humidity,两者不能直接混用。
from pathlib import Path
import numpy as np
import pandas as pd
import xarray as xr
import matplotlib.pyplot as plt
import cdsapi
import metpy.calc as mpcalc
from metpy.units import units
from wrf import td as wrf_td
plt.rcParams['figure.dpi'] = 120
plt.rcParams['axes.unicode_minus'] = False
try:
import cartopy.crs as ccrs
import cartopy.feature as cfeature
HAS_CARTOPY = True
except ImportError:
HAS_CARTOPY = False
print('Cartopy 未安装,涉及地图底图的单元将退化为普通经纬度图。')
3. 参数设置
本项目已经下载并生成了对应案例数据,下面的参数既可以复用已有结果,也可以在删除输出文件后重新下载。
PRESSURE_DATASET = 'reanalysis-era5-pressure-levels'
SINGLE_LEVEL_DATASET = 'reanalysis-era5-single-levels'
PRESSURE_LEVELS = [500, 700, 850]
EPSILON = 0.622
year, month, day, hour = 2026, 3, 1, 0
area = [60, 70, 10, 145] # north, west, south, east
grid = [0.25, 0.25]
stamp = f'{year:04d}{month:02d}{day:02d}{hour:02d}'
output_dir = Path('./')
output_dir.mkdir(parents=True, exist_ok=True)
pressure_path = output_dir / f'era5_pressure_levels_{stamp}.nc'
single_path = output_dir / f'era5_single_levels_{stamp}.nc'
figure_path = output_dir / f'kindex_compare_{stamp}.png'
pressure_path, single_path, figure_path
(PosixPath('era5_pressure_levels_2026030100.nc'),
PosixPath('era5_single_levels_2026030100.nc'),
PosixPath('kindex_compare_2026030100.png'))
4. 下载 ERA5 数据
若本地已有对应文件,本单元会自动跳过下载。若需要重新获取,请先删除输出文件,或者自行加入强制下载逻辑。
运行本单元前需确保用户主目录下已经正确配置 ~/.cdsapirc。
client = cdsapi.Client()
common_request = {
'product_type': ['reanalysis'],
'year': [f'{year:04d}'],
'month': [f'{month:02d}'],
'day': [f'{day:02d}'],
'time': [f'{hour:02d}:00'],
'data_format': 'netcdf',
'download_format': 'unarchived',
'area': area,
'grid': grid,
}
ifnot pressure_path.exists():
request_pl = {
**common_request,
'variable': ['temperature', 'specific_humidity'],
'pressure_level': [str(level) for level in PRESSURE_LEVELS],
}
client.retrieve(PRESSURE_DATASET, request_pl, str(pressure_path))
ifnot single_path.exists():
request_sl = {
**common_request,
'variable': ['k_index'],
}
client.retrieve(SINGLE_LEVEL_DATASET, request_sl, str(single_path))
print('pressure file:', pressure_path, pressure_path.exists())
print('single file :', single_path, single_path.exists())
5. 读取数据并准备计算
这里采用与项目脚本一致的处理方式:
- 读取 pressure levels 上的
t与q; - 将
specific humidity转为mixing ratio; - 构造与数据维度一致的 pressure 场,供
wrf.td使用; - 读取 single levels 上的原生
kx。
ds_pl = xr.open_dataset(pressure_path)
ds_sl = xr.open_dataset(single_path)
temperature = ds_pl['t'] - 273.15
temperature.attrs['units'] = 'degC'
specific_humidity = ds_pl['q']
native_k = ds_sl['kx'].squeeze(drop=True)
level_name = 'pressure_level'
mixing_ratio = specific_humidity / (1.0 - specific_humidity)
pressure_hpa = xr.zeros_like(specific_humidity) + specific_humidity[level_name]
print(ds_pl)
print('-' * 80)
print(ds_sl)
<xarray.Dataset> Size: 1MB
Dimensions: (valid_time: 1, pressure_level: 3, latitude: 201,
longitude: 301)
Coordinates:
number int64 8B ...
* valid_time (valid_time) datetime64[ns] 8B 2026-03-01
* pressure_level (pressure_level) float64 24B 850.0 700.0 500.0
* latitude (latitude) float64 2kB 60.0 59.75 59.5 ... 10.5 10.25 10.0
* longitude (longitude) float64 2kB 70.0 70.25 70.5 ... 144.8 145.0
expver <U4 16B ...
Data variables:
t (valid_time, pressure_level, latitude, longitude) float32 726kB ...
q (valid_time, pressure_level, latitude, longitude) float32 726kB ...
Attributes:
GRIB_centre: ecmf
GRIB_centreDescription: European Centre for Medium-Range Weather Forecasts
GRIB_subCentre: 0
Conventions: CF-1.7
institution: European Centre for Medium-Range Weather Forecasts
history: 2026-03-08T09:38 GRIB to CDM+CF via cfgrib-0.9.1...
--------------------------------------------------------------------------------
<xarray.Dataset> Size: 246kB
Dimensions: (valid_time: 1, latitude: 201, longitude: 301)
Coordinates:
* valid_time (valid_time) datetime64[ns] 8B 2026-03-01
* latitude (latitude) float64 2kB 60.0 59.75 59.5 59.25 ... 10.5 10.25 10.0
* longitude (longitude) float64 2kB 70.0 70.25 70.5 ... 144.5 144.8 145.0
expver <U4 16B ...
Data variables:
kx (valid_time, latitude, longitude) float32 242kB ...
Attributes:
GRIB_centre: ecmf
GRIB_centreDescription: European Centre for Medium-Range Weather Forecasts
GRIB_subCentre: 0
Conventions: CF-1.7
institution: European Centre for Medium-Range Weather Forecasts
history: 2026-03-08T10:05 GRIB to CDM+CF via cfgrib-0.9.1...
6. 露点温度计算
本文分别采用两种思路计算露点:
- 方法一:
wrf.td - 方法二:
MetPy dewpoint
其中 wrf.td 的一个工程细节需要特别注意:其返回结果可能丢失原来的 pressure-level 坐标,因此这里显式用原 pressure 场的 coords/dims 重新封装,避免后续 .sel(pressure_level=700) 时把 700 误当成位置索引。
td_wrf_raw = wrf_td(pressure_hpa, mixing_ratio, meta=True, units='degC')
td_wrf = xr.DataArray(
np.asarray(td_wrf_raw),
coords=pressure_hpa.coords,
dims=pressure_hpa.dims,
name='td_wrf',
)
vapor_pressure_hpa = (mixing_ratio * pressure_hpa) / (EPSILON + mixing_ratio)
td_metpy = xr.DataArray(
mpcalc.dewpoint(vapor_pressure_hpa.values * units.hectopascal).m,
coords=pressure_hpa.coords,
dims=pressure_hpa.dims,
name='td_metpy',
)
td_wrf, td_metpy
(<xarray.DataArray 'td_wrf' (valid_time: 1, pressure_level: 3, latitude: 201,
longitude: 301)> Size: 1MB
array([[[[-30.84901697, -30.519368 , -30.1987568 , ..., -14.82100213,
-14.81287255, -14.82506776],
[-30.64725578, -30.39286462, -30.11654163, ..., -14.95583744,
-14.86987846, -14.78040596],
[-30.43488054, -30.1987568 , -29.98078195, ..., -15.04234567,
-15.00108241, -15.01757259],
...,
[ -1.89562018, -2.24014847, -1.84444305, ..., 15.78203906,
15.51720418, 15.06335683],
[ -1.14073139, -1.78358623, -1.71806735, ..., 15.74116777,
15.42783366, 15.03944511],
[ -1.12028534, -1.96689396, -1.930387 , ..., 15.6512511 ,
15.43353984, 15.16736505]],
[[-29.58757972, -29.46991854, -29.34815038, ..., -25.39540336,
-25.18842873, -24.98487484],
[-29.93669456, -29.7772191 , -29.64145189, ..., -24.86433535,
-24.5804582 , -24.30641506],
[-30.18286571, -30.0033225 , -29.84294738, ..., -24.3481834 ,
-24.02129597, -23.62356865],
...
[-30.27367757, -22.3009684 , -14.68946715, ..., 7.1534271 ,
6.53410916, 6.02173885],
[-31.68305055, -24.57335548, -16.21047809, ..., 6.54802595,
6.09383223, 5.71547102],
[-32.11550236, -26.71656052, -17.86558505, ..., 6.25487783,
5.99379762, 5.7618458 ]],
[[-47.47090074, -48.65065815, -49.69725319, ..., -36.37861482,
-36.34733182, -36.3161382 ],
[-46.83513172, -48.02157288, -49.04627551, ..., -36.368177 ,
-36.2919369 , -36.2162202 ],
[-46.37246881, -47.55206443, -48.59381798, ..., -36.48704938,
-36.41696908, -36.35774991],
...,
[-48.06441841, -48.07515908, -48.03226714, ..., -18.93701094,
-18.39117354, -18.17136987],
[-47.65447236, -47.72679983, -47.74756335, ..., -19.20916649,
-18.87936501, -18.81713428],
[-46.11367748, -46.15781953, -46.14013923, ..., -19.3940961 ,
-19.30255789, -19.41180605]]]])
Coordinates:
number int64 8B 0
* valid_time (valid_time) datetime64[ns] 8B 2026-03-01
* pressure_level (pressure_level) float64 24B 850.0 700.0 500.0
* latitude (latitude) float64 2kB 60.0 59.75 59.5 ... 10.5 10.25 10.0
* longitude (longitude) float64 2kB 70.0 70.25 70.5 ... 144.8 145.0
expver <U4 16B '0005',
<xarray.DataArray 'td_metpy' (valid_time: 1, pressure_level: 3, latitude: 201,
longitude: 301)> Size: 1MB
array([[[[-30.84847444, -30.51882865, -30.19822054, ..., -14.82063502,
-14.81250549, -14.82470063],
[-30.6467152 , -30.39232648, -30.11600616, ..., -14.95546844,
-14.86951109, -14.78003907],
[-30.43434201, -30.19822054, -29.98024779, ..., -15.04197619,
-15.00071316, -15.01720325],
...,
[ -1.89541609, -2.23994077, -1.8442397 , ..., 15.78198672,
15.51715662, 15.06331658],
[ -1.14053845, -1.78338457, -1.71786587, ..., 15.74111645,
15.42778721, 15.0394046 ],
[ -1.12009155, -1.96668981, -1.93018286, ..., 15.65120069,
15.43349347, 15.16732313]],
[[-29.58704956, -29.46938949, -29.34762247, ..., -25.39491641,
-25.18794471, -24.98439266],
[-29.93616111, -29.77668715, -29.64092122, ..., -24.86385426,
-24.57998072, -24.30594003],
[-30.18232993, -30.00278841, -29.8424148 , ..., -24.347708 ,
-24.02082453, -23.6231007 ],
...
[-30.27314093, -22.30051498, -14.68910171, ..., 7.15350388,
6.53419502, 6.02183283],
[-31.6824996 , -24.57287807, -16.21009404, ..., 6.54811225,
6.09392511, 5.71556866],
[-32.11494734, -26.71606038, -17.86518254, ..., 6.25496855,
5.99389116, 5.7619433 ]],
[[-47.470208 , -48.64995605, -49.69654291, ..., -36.37801874,
-36.34673603, -36.31554269],
[-46.83444409, -48.02087575, -49.0455703 , ..., -36.36758102,
-36.29134159, -36.21562558],
[-46.37178493, -47.55137104, -48.59311633, ..., -36.48645233,
-36.41637265, -36.35715402],
...,
[-48.06372095, -48.07446153, -48.03156992, ..., -18.93659537,
-18.39076441, -18.1709632 ],
[-47.65377816, -47.72610504, -47.7468684 , ..., -19.2087481 ,
-18.87895067, -18.81672005],
[-46.11299571, -46.15713739, -46.13945724, ..., -19.39367614,
-19.30213816, -19.41138493]]]])
Coordinates:
number int64 8B 0
* valid_time (valid_time) datetime64[ns] 8B 2026-03-01
* pressure_level (pressure_level) float64 24B 850.0 700.0 500.0
* latitude (latitude) float64 2kB 60.0 59.75 59.5 ... 10.5 10.25 10.0
* longitude (longitude) float64 2kB 70.0 70.25 70.5 ... 144.8 145.0
expver <U4 16B '0005')
7. 计算 K 指数
按照标准公式分别计算:
- 基于
wrf.td的 K 指数 - 基于
MetPy的 K 指数 - ERA5 原生
kx
为了便于后续比较,同时计算与原生 K 指数的差值场。
def sel_level(da, level):
return da.sel(pressure_level=level).squeeze(drop=True)
k_wrf = (sel_level(temperature, 850) - sel_level(temperature, 500)) \
+ sel_level(td_wrf, 850) - (sel_level(temperature, 700) - sel_level(td_wrf, 700))
k_metpy = (sel_level(temperature, 850) - sel_level(temperature, 500)) \
+ sel_level(td_metpy, 850) - (sel_level(temperature, 700) - sel_level(td_metpy, 700))
k_native = native_k
diff_wrf_native = k_wrf - k_native
diff_metpy_native = k_metpy - k_native
k_wrf.name = 'kindex_wrf_td'
k_metpy.name = 'kindex_metpy_td'
k_native.name = 'kindex_era5_native'
diff_wrf_native.name = 'diff_wrf_minus_native'
diff_metpy_native.name = 'diff_metpy_minus_native'
8. 统计对比
下面给出三套 K 指数及其差值场的基本统计量。对于本案例,项目实测结果显示:
wrf.td与 ERA5 原生 K 指数的平均绝对差约为 5.035 ℃;MetPy与 ERA5 原生 K 指数的平均绝对差约为 5.036 ℃。
这说明:wrf.td 与 MetPy 两种露点算法的结果彼此非常接近,手工结果与原生结果的主要差异并不来自这两个露点库之间的区别。
def summary(da):
arr = da.values
return {
'mean': float(np.nanmean(arr)),
'min': float(np.nanmin(arr)),
'max': float(np.nanmax(arr)),
'std': float(np.nanstd(arr)),
}
stats = {
'k_wrf': summary(k_wrf),
'k_metpy': summary(k_metpy),
'k_native': summary(k_native),
'diff_wrf_native': summary(diff_wrf_native),
'diff_metpy_native': summary(diff_metpy_native),
}
mae_wrf = float(np.nanmean(np.abs(diff_wrf_native.values)))
mae_metpy = float(np.nanmean(np.abs(diff_metpy_native.values)))
for key, value in stats.items():
print(key, value)
print('MAE(wrf-native) =', mae_wrf)
print('MAE(metpy-native)=', mae_metpy)
k_wrf {'mean': -1.26227110083919, 'min': -68.38541954948838, 'max': 38.80141098377376, 'std': 19.856520471415795}
k_metpy {'mean': -1.2620456891259546, 'min': -71.90160807609587, 'max': 38.80142433316411, 'std': 19.857778480883887}
k_native {'mean': -3.7674310207366943, 'min': -68.73628234863281, 'max': 36.49809265136719, 'std': 20.46647834777832}
diff_wrf_native {'mean': 2.5051601389276534, 'min': -50.51135049294727, 'max': 62.62849966099513, 'std': 8.224212875382365}
diff_metpy_native {'mean': 2.505385550640889, 'min': -54.0275553747401, 'max': 62.629228615577745, 'std': 8.227135435749295}
MAE(wrf-native) = 5.035084348419672
MAE(metpy-native)= 5.035668970241846
8.1 区域差异统计表
为了更具体地回答“哪里差异最大”,这里把当前案例中的几个重点区域单独量化:
- 青藏高原:
27–38°N, 78–103°E - 日本附近:
30–46°N, 128–146°E - 东海附近:
24–34°N, 118–130°E
同时给出全区域最大差值点,用于定位极端差异中心。
analysis_regions = {
'Tibetan Plateau': {'lat': (27, 38), 'lon': (78, 103)},
'Japan Nearby': {'lat': (30, 46), 'lon': (128, 146)},
'East China Sea': {'lat': (24, 34), 'lon': (118, 130)},
}
absdiff = np.abs(diff_wrf_native)
global_idx = np.unravel_index(np.nanargmax(absdiff.values), absdiff.shape)
global_max_summary = {
'region': 'Global max point',
'mean_diff': float(diff_wrf_native.values[global_idx]),
'mae': float(absdiff.values[global_idx]),
'max_abs_diff': float(absdiff.values[global_idx]),
'signed_at_max': float(diff_wrf_native.values[global_idx]),
'lat_at_max': float(diff_wrf_native['latitude'].values[global_idx[0]]),
'lon_at_max': float(diff_wrf_native['longitude'].values[global_idx[1]]),
'p95_abs_diff': float(absdiff.values[global_idx]),
}
rows = [global_max_summary]
for name, box in analysis_regions.items():
sub = diff_wrf_native.sel(
latitude=slice(box['lat'][1], box['lat'][0]),
longitude=slice(box['lon'][0], box['lon'][1])
)
vals = sub.values
absvals = np.abs(vals)
idx = np.unravel_index(np.nanargmax(absvals), absvals.shape)
rows.append({
'region': name,
'mean_diff': float(np.nanmean(vals)),
'mae': float(np.nanmean(absvals)),
'max_abs_diff': float(absvals[idx]),
'signed_at_max': float(vals[idx]),
'lat_at_max': float(sub['latitude'].values[idx[0]]),
'lon_at_max': float(sub['longitude'].values[idx[1]]),
'p95_abs_diff': float(np.nanpercentile(absvals, 95)),
})
region_table = pd.DataFrame(rows)
region_table
region mean_diff mae max_abs_diff signed_at_max \
0 Global max point 62.628500 62.628500 62.628500 62.628500
1 Tibetan Plateau 12.711600 14.223625 62.628500 62.628500
2 Japan Nearby -0.796317 4.764117 42.094915 -42.094915
3 East China Sea -1.061989 2.887524 28.309171 -28.309171
lat_at_max lon_at_max p95_abs_diff
0 28.00 86.75 62.628500
1 28.00 86.75 33.414993
2 38.25 138.25 13.830919
3 27.25 129.50 12.034350
从当前案例的实际统计结果看,结论非常清楚:
- 全区域最大差异点位于青藏高原南侧附近,大致在 28.0°N, 86.75°E;
- 该点
K(wrf) - K(native)的绝对差达到 62.63 ℃; - 青藏高原区域 的平均偏差约为 +12.71 ℃,区域平均绝对差约为 14.22 ℃,显著高于海上和东部平原;
- 日本附近 的区域平均绝对差约为 4.76 ℃,虽然小于青藏高原,但仍不低,而且局地最大绝对差可达 42.09 ℃;
- 东海附近 的平均绝对差约为 2.89 ℃,整体弱于前两者。
因此,青藏高原确实是最显著的差异中心之一,地形很可能是重要影响因素;同时日本附近也存在较明显差异,只是总体上弱于青藏高原。
9. 绘图对比(带 Cartopy 底图)
from meteva.base.tool.plot_tools import add_china_map_2basemap
def add_map_features(ax):
if HAS_CARTOPY:
# ax.coastlines(resolution='50m', linewidth=0.8)
# ax.add_feature(cfeature.BORDERS.with_scale('50m'), linewidth=0.5)
add_china_map_2basemap(ax, name="province", edgecolor='k', lw=0.5, encoding='gbk', grid0=None)
ax.add_feature(cfeature.LAND.with_scale('50m'), facecolor='0.95')
ax.add_feature(cfeature.OCEAN.with_scale('50m'), facecolor='white')
lon_name, lat_name = 'longitude', 'latitude'
arrays = [k_wrf.values, k_metpy.values, k_native.values]
vmin = float(np.nanmin([np.nanmin(a) for a in arrays]))
vmax = float(np.nanmax([np.nanmax(a) for a in arrays]))
if HAS_CARTOPY:
proj = ccrs.PlateCarree()
fig, axes = plt.subplots(1, 3, figsize=(18, 5.5), subplot_kw={'projection': proj}, constrained_layout=True)
else:
fig, axes = plt.subplots(1, 3, figsize=(18, 5.5), constrained_layout=True)
titles = ['K index (wrf.td dewpoint)', 'K index (MetPy dewpoint)', 'ERA5 native K index']
mappable = None
for ax, da, title in zip(axes, [k_wrf, k_metpy, k_native], titles):
if HAS_CARTOPY:
mappable = da.plot(ax=ax, x=lon_name, y=lat_name, transform=ccrs.PlateCarree(), cmap='turbo', vmin=vmin, vmax=vmax, add_colorbar=False)
ax.set_extent([70, 145, 10, 60], crs=ccrs.PlateCarree())
add_map_features(ax)
gl = ax.gridlines(draw_labels=True, linewidth=0.3, color='gray', alpha=0.5, linestyle='--')
gl.top_labels = False
gl.right_labels = False
else:
mappable = da.plot(ax=ax, x=lon_name, y=lat_name, cmap='turbo', vmin=vmin, vmax=vmax, add_colorbar=False)
ax.set_title(title)
fig.colorbar(mappable, ax=axes, shrink=0.86, label='K Index (degC)')
plt.show()
fig.savefig(figure_path, dpi=150, bbox_inches='tight')
print('saved to', figure_path)
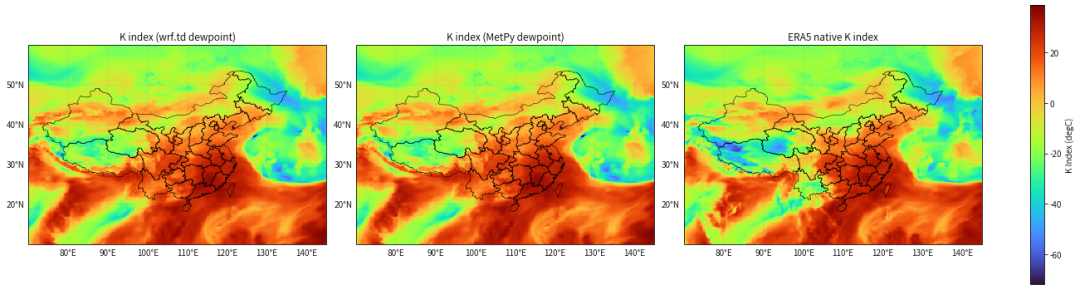
输出图片
输出图片
saved to kindex_compare_2026030100.png
10. 差值场补充分析(带区域框)
除了差值图本身,这里还在图上标出青藏高原与日本附近两个重点区域,便于直接观察其空间对应关系。
def draw_box(ax, lon0, lon1, lat0, lat1, label, color='k'):
xs = [lon0, lon1, lon1, lon0, lon0]
ys = [lat0, lat0, lat1, lat1, lat0]
if HAS_CARTOPY:
ax.plot(xs, ys, color=color, linewidth=1.2, transform=ccrs.PlateCarree())
ax.text(lon0 + 0.5, lat1 - 0.8, label, color=color, fontsize=9, transform=ccrs.PlateCarree())
else:
ax.plot(xs, ys, color=color, linewidth=1.2)
ax.text(lon0 + 0.5, lat1 - 0.8, label, color=color, fontsize=9)
if HAS_CARTOPY:
proj = ccrs.PlateCarree()
fig, axes = plt.subplots(1, 2, figsize=(12.5, 5.2), subplot_kw={'projection': proj}, constrained_layout=True)
else:
fig, axes = plt.subplots(1, 2, figsize=(12.5, 5.2), constrained_layout=True)
diffs = [diff_wrf_native, diff_metpy_native]
titles = ['K(wrf.td) - K(native)', 'K(MetPy) - K(native)']
absmax = float(np.nanmax(np.abs([np.nanmin(d.values) for d in diffs] + [np.nanmax(d.values) for d in diffs])))
mappable = None
for ax, da, title in zip(axes, diffs, titles):
if HAS_CARTOPY:
mappable = da.plot(ax=ax, x='longitude', y='latitude', transform=ccrs.PlateCarree(), cmap='RdBu_r', vmin=-absmax, vmax=absmax, add_colorbar=False)
ax.set_extent([70, 145, 10, 60], crs=ccrs.PlateCarree())
add_map_features(ax)
gl = ax.gridlines(draw_labels=True, linewidth=0.3, color='gray', alpha=0.5, linestyle='--')
gl.top_labels = False
gl.right_labels = False
else:
mappable = da.plot(ax=ax, x='longitude', y='latitude', cmap='RdBu_r', vmin=-absmax, vmax=absmax, add_colorbar=False)
draw_box(ax, 78, 103, 27, 38, 'Tibetan Plateau', color='black')
draw_box(ax, 128, 146, 30, 46, 'Japan Nearby', color='darkgreen')
ax.set_title(title)
fig.colorbar(mappable, ax=axes, shrink=0.9, label='Difference (degC)')
plt.show()
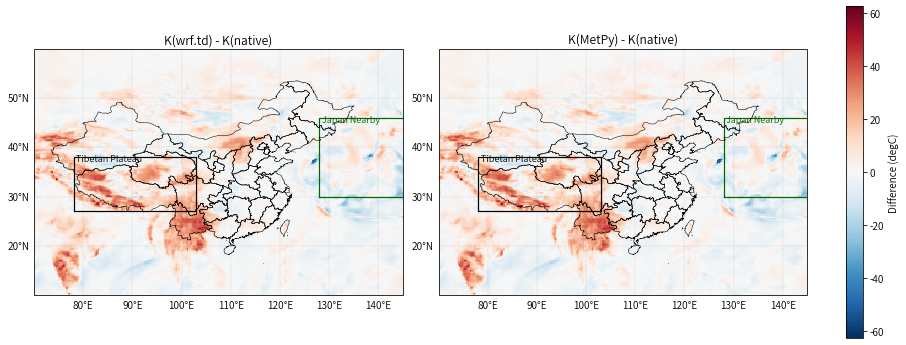
输出图片
输出图片
11. 为什么手工 K 指数与 ERA5 原生 K 指数会有差异?
结合当前项目的实现、区域统计结果与已有文献信息,可以做一个浅析。
11.1 公式相同,不代表生成链路相同
ECMWF 参数库对 kx 的描述与标准 K-index 公式一致,都是基于 500/700/850 hPa 温度与 850/700 hPa 露点来构建。但 ECMWF 文档摘要显示,K 指数的评估涉及 由 model levels 向目标等压面插值 的过程。
这意味着 ERA5 原生 kx 很可能并不是简单地对 CDS 中已经插值好的 pressure-level 产品再套一次公式,而是走了 ECMWF 自身的诊断流程。
11.2 地形对差异的影响很可能非常重要
本案例中,全区域最大差异点出现在 28.0°N, 86.75°E,位于青藏高原南侧附近;青藏高原区域平均偏差约 +12.71 ℃,平均绝对差约 14.22 ℃,明显高于日本附近与东海海域。
这说明在高海拔、强地形起伏地区,ERA5 原生 kx 与基于 pressure-level 产品手算的 K 指数差异会被明显放大。一个合理解释是:
- 高原地区地表气压低,850 hPa 甚至 700 hPa 等压面可能贴近地面或位于地下;
- 不同产品对地下层、近地层以及垂直插值的处理方式并不完全一致;
- 在复杂地形区,微小的垂直插值差异会通过 K 指数的组合公式被进一步放大。
因此,青藏高原差异大,确实可以作为“地形是重要影响因素”的一个很强信号。
11.3 日本附近也存在较明显差异,但性质可能不同
日本附近区域平均绝对差约 4.76 ℃,局地最大绝对差约 42.09 ℃,说明这里同样存在不可忽略的偏差。
不过与青藏高原不同,日本附近的差异更可能与以下因素共同作用有关:
- 海陆交界附近的强水平梯度;
- 锋区、气旋活动或海上冷暖空气交汇带来的层结敏感性;
- 海陆混合区域中插值和平滑处理的差异。
换句话说:日本附近确实也差异较大,但它更可能体现海陆过渡区和天气系统敏感区的影响,而不是单纯的高地形效应。
11.4 specific humidity 与 mixing ratio 不是同一个量
这是最容易出错的一点。wrf.td 需要的输入是 water vapor mixing ratio,而 ERA5 常下载的是 specific humidity。若直接把 q 当作 qv 使用,会引入系统性偏差。正确做法是:
本项目脚本已显式做了这一步转换。
11.5 露点诊断实现不同,但不是本案例主因
露点温度并不是 pressure-level 数据文件中直接给出的本例核心变量,而是通过温湿关系诊断得到的。不同库在常数、近似形式和单位转换上可能略有不同。
不过从本案例来看,wrf.td 与 MetPy 算出的 K 指数平均绝对差几乎一致,因此这一步 不是主导差异来源。
11.6 pressure-level 产品与原生 single-level 指数可能来自不同后处理链路
手工方案使用的是 pressure-level temperature 与 specific_humidity,而对比对象是 single-level 的 k_index。即便两者都来自 ERA5,它们仍可能经历了不同的插值、重网格和后处理步骤,因此不应期待两者逐点完全相同。
11. 地形影响验证:引入 DEM 后再看差值分布
为了进一步验证“青藏高原差异大是否与地形有关”,这里引入地形文件:cldasgrid_dem (1).nc。
本节的思路是:
- 读取 DEM 中的
elevation; - 将地形数据插值到 ERA5 的 K 指数网格;
- 比较高程与
|K_manual - K_native|的关系; - 按不同高程分层,统计差值幅度。
如果高程越高、差值越大,则可以较有力地支持“地形是重要影响因素”的判断。
dem_path = Path('cldasgrid_dem (1).nc')
dem_ds = xr.open_dataset(dem_path)
print(dem_ds)
raw_lon = dem_ds['lon'].values
raw_lat = dem_ds['lat'].values
valid_lon = np.isfinite(raw_lon)
valid_lat = np.isfinite(raw_lat)
terrain = dem_ds['elevation'].isel(LON=valid_lon, LAT=valid_lat).rename({'LAT': 'latitude', 'LON': 'longitude'})
terrain = terrain.assign_coords(latitude=raw_lat[valid_lat], longitude=raw_lon[valid_lon])
terrain = terrain.sortby('latitude').sortby('longitude')
terrain = terrain.sel(
latitude=slice(float(k_native.latitude.min()), float(k_native.latitude.max())),
longitude=slice(float(k_native.longitude.min()), float(k_native.longitude.max())),
)
terrain_on_era5 = terrain.interp(latitude=k_native.latitude, longitude=k_native.longitude)
terrain_on_era5
<xarray.Dataset> Size: 126MB
Dimensions: (LON: 7000, LAT: 4500)
Coordinates:
lon (LON) float32 28kB ...
lat (LAT) float32 18kB ...
* LON (LON) float32 28kB 70.03 70.04 70.05 70.06 ... 140.0 140.0 140.0
* LAT (LAT) float32 18kB 15.03 15.04 15.05 15.06 ... 60.0 60.01 60.02
Data variables:
elevation (LAT, LON) float32 126MB ...
<xarray.DataArray 'elevation' (latitude: 201, longitude: 301)> Size: 484kB
array([[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]])
Coordinates:
lon (longitude) float64 2kB nan 70.25 70.5 70.75 ... nan nan nan nan
lat (latitude) float64 2kB nan 59.75 59.5 59.25 ... nan nan nan nan
* latitude (latitude) float64 2kB 60.0 59.75 59.5 59.25 ... 10.5 10.25 10.0
* longitude (longitude) float64 2kB 70.0 70.25 70.5 ... 144.5 144.8 145.0
expver <U4 16B '0005'
Attributes:
long_name: GDAL Band Number 1
grid_mapping: crs
11.1 地形图与差值场并列查看
下面把地形高度与差值场并列画出。若青藏高原等高地带与高差值区空间上明显重合,就能直观支持地形影响。
if HAS_CARTOPY:
proj = ccrs.PlateCarree()
fig, axes = plt.subplots(1, 2, figsize=(13, 5.2), subplot_kw={'projection': proj}, constrained_layout=True)
else:
fig, axes = plt.subplots(1, 2, figsize=(13, 5.2), constrained_layout=True)
# terrain panel
if HAS_CARTOPY:
m0 = terrain_on_era5.plot(ax=axes[0], x='longitude', y='latitude', transform=ccrs.PlateCarree(), cmap='terrain', add_colorbar=False)
axes[0].set_extent([70, 145, 10, 60], crs=ccrs.PlateCarree())
add_map_features(axes[0])
gl = axes[0].gridlines(draw_labels=True, linewidth=0.3, color='gray', alpha=0.5, linestyle='--')
gl.top_labels = False
gl.right_labels = False
else:
m0 = terrain_on_era5.plot(ax=axes[0], x='longitude', y='latitude', cmap='terrain', add_colorbar=False)
axes[0].set_title('Terrain elevation (m)')
a = np.abs(diff_wrf_native.values)
absmax = float(np.nanmax(a))
if HAS_CARTOPY:
m1 = diff_wrf_native.plot(ax=axes[1], x='longitude', y='latitude', transform=ccrs.PlateCarree(), cmap='RdBu_r', vmin=-absmax, vmax=absmax, add_colorbar=False)
axes[1].set_extent([70, 145, 10, 60], crs=ccrs.PlateCarree())
add_map_features(axes[1])
gl = axes[1].gridlines(draw_labels=True, linewidth=0.3, color='gray', alpha=0.5, linestyle='--')
gl.top_labels = False
gl.right_labels = False
else:
m1 = diff_wrf_native.plot(ax=axes[1], x='longitude', y='latitude', cmap='RdBu_r', vmin=-absmax, vmax=absmax, add_colorbar=False)
axes[1].set_title('K(wrf.td) - K(native)')
fig.colorbar(m0, ax=axes[0], shrink=0.88, label='Elevation (m)')
fig.colorbar(m1, ax=axes[1], shrink=0.88, label='Difference (degC)')
plt.show()
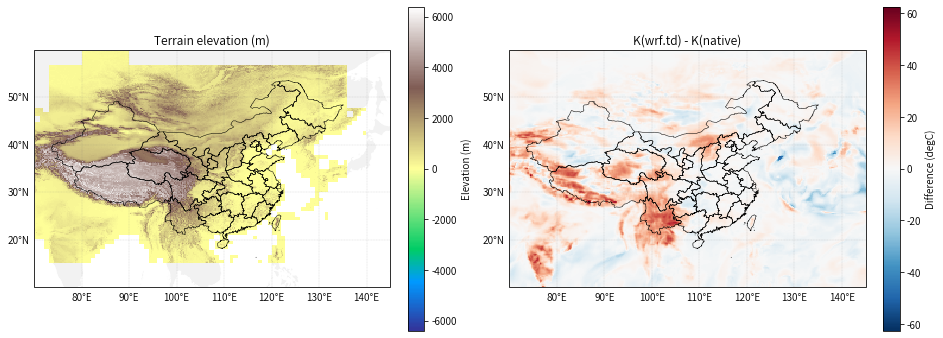
输出图片
输出图片
11.2 高程与差值的统计关系
利用 DEM 插值到 ERA5 网格后,可以直接比较:
- 高程
elevation - K 指数绝对差
|K(wrf) - K(native)|
当前案例得到的关键结果如下:
- 有效重叠格点数:37372
- 高程与绝对差的相关系数约为:0.499
这个相关系数已经不低,说明在本次个例中,地形越高,K 指数差异整体越大 的趋势相当明显。
terrain_mask = np.isfinite(terrain_on_era5.values) & np.isfinite(diff_wrf_native.values)
terrain_height = terrain_on_era5.values[terrain_mask]
terrain_absdiff = np.abs(diff_wrf_native.values[terrain_mask])
terrain_signeddiff = diff_wrf_native.values[terrain_mask]
terrain_corr = float(np.corrcoef(terrain_height, terrain_absdiff)[0, 1])
print('overlap_points =', int(terrain_mask.sum()))
print('corr(elevation, |diff|) =', terrain_corr)
overlap_points = 37372
corr(elevation, |diff|) = 0.49924111041851976
11.3 按高程分层统计
为了把“高原更大、低地更小”写得更明确,这里把地形分成多个高度层,分别计算平均绝对差与 95 分位绝对差。
bins = [0, 500, 1500, 3000, 5000, 9000]
labels = ['0-500 m', '500-1500 m', '1500-3000 m', '3000-5000 m', '>5000 m']
rows = []
for i, label in enumerate(labels):
lo, hi = bins[i], bins[i + 1]
mask = (terrain_height >= lo) & (terrain_height < hi)
if mask.sum() == 0:
continue
rows.append({
'elevation_bin': label,
'count': int(mask.sum()),
'mean_abs_diff': float(terrain_absdiff[mask].mean()),
'p95_abs_diff': float(np.percentile(terrain_absdiff[mask], 95)),
'mean_signed_diff': float(terrain_signeddiff[mask].mean()),
})
terrain_table = pd.DataFrame(rows)
terrain_table
elevation_bin count mean_abs_diff p95_abs_diff mean_signed_diff
0 0-500 m 15348 2.583629 9.467178 1.090153
1 500-1500 m 13104 6.075955 23.088992 4.239066
2 1500-3000 m 4289 10.418161 31.955339 9.448298
3 3000-5000 m 3548 14.044127 31.367969 12.759994
4 >5000 m 1077 16.996716 38.449148 15.410282
从这张表可以直接看出一个非常强的高度依赖关系:
- 0–500 m:平均绝对差约 2.58 ℃
- 500–1500 m:约 6.08 ℃
- 1500–3000 m:约 10.42 ℃
- 3000–5000 m:约 14.04 ℃
- >5000 m:约 17.00 ℃
也就是说,随着地形高度抬升,手工 K 指数与 ERA5 原生 K 指数的差异几乎是单调增大的。这比单纯看青藏高原区域平均值更能说明问题。
summary_rows = []
for name, mask in {
'lowland < 1000 m': terrain_height < 1000,
'mid terrain 1000-3000 m': (terrain_height >= 1000) & (terrain_height < 3000),
'high terrain >= 3000 m': terrain_height >= 3000,
}.items():
summary_rows.append({
'group': name,
'count': int(mask.sum()),
'mean_abs_diff': float(terrain_absdiff[mask].mean()),
'mean_signed_diff': float(terrain_signeddiff[mask].mean()),
})
terrain_summary = pd.DataFrame(summary_rows)
terrain_summary
group count mean_abs_diff mean_signed_diff
0 lowland < 1000 m 22675 3.478025 2.001108
1 mid terrain 1000-3000 m 10072 8.449822 6.693264
2 high terrain >= 3000 m 4625 14.731681 13.377153
进一步压缩为三类地形后,也能看到同样的结论:
- 低地(<1000 m):平均绝对差约 3.48 ℃
- 中地形(1000–3000 m):平均绝对差约 8.45 ℃
- 高地形(≥3000 m):平均绝对差约 14.73 ℃
因此,从当前个例来看,“地形是重要影响因素”不仅是合理猜测,而且有了比较明确的定量证据支持。
11.4 高程—差值散点图
为了更直观地展示“高程越高,差值越大”的趋势,这里绘制高程与绝对差值的散点图,并叠加分箱均值曲线。
考虑到格点很多,散点图采用随机抽样显示,以保证图像清晰。分箱均值曲线则使用全部样本来计算。
rng = np.random.default_rng(42)
plot_n = min(6000, terrain_height.size)
sample_idx = rng.choice(terrain_height.size, size=plot_n, replace=False)
sample_height = terrain_height[sample_idx]
sample_absdiff = terrain_absdiff[sample_idx]
bin_edges = np.array([0, 500, 1000, 1500, 2000, 3000, 4000, 5000, 6500])
bin_centers = 0.5 * (bin_edges[:-1] + bin_edges[1:])
bin_means = []
for lo, hi in zip(bin_edges[:-1], bin_edges[1:]):
m = (terrain_height >= lo) & (terrain_height < hi)
if m.sum() > 0:
bin_means.append(float(terrain_absdiff[m].mean()))
else:
bin_means.append(np.nan)
fig, ax = plt.subplots(figsize=(8, 5.2))
ax.scatter(sample_height, sample_absdiff, s=8, alpha=0.22, color='tab:blue', label='Random sample of grid points')
ax.plot(bin_centers, bin_means, color='crimson', linewidth=2.5, marker='o', label='Binned mean |diff|')
ax.set_xlabel('Terrain elevation (m)')
ax.set_ylabel('|K(wrf.td) - K(native)| (degC)')
ax.set_title('Elevation vs absolute K-index difference')
ax.grid(True, linestyle='--', alpha=0.4)
ax.legend()
plt.show()
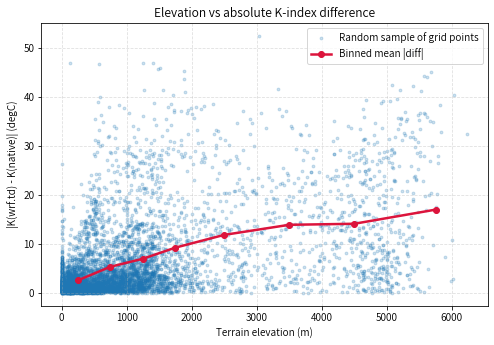
输出图片
输出图片
从这张图中通常可以直接看到两层信息:
- 散点云整体向右上方扩展,说明高海拔区域更容易出现大差值;
- 分箱均值曲线随高程总体上升,说明这不是少数离群点造成的,而是一个具有整体性的高度依赖关系。
这张图是当前 Notebook 中支持“地形是重要影响因素”最直观的一张证据图。
11.4 对青藏高原和日本附近的重新理解
有了 DEM 之后,可以更清楚地区分两类差异来源:
- 青藏高原:差异强、范围广,并且与高海拔区高度重合,说明复杂地形、地下等压面处理和垂直插值很可能是主因;
- 日本附近:虽然也有明显差异,但其高程并不高,说明那里更可能反映海陆过渡区、锋区或天气系统敏感区的影响,而不是单纯的高地形效应。
12. 结论
基于本项目的实验可以得到以下几点认识:
- 手工计算 ERA5 K 指数是可行的,前提是正确处理湿度变量,并严格统一单位;
wrf.td与MetPy给出的手工结果非常接近,说明露点库选择并不是本案例中最主要的不确定来源;- 与 ERA5 原生
kx的差异更可能来自 ECMWF 内部插值/诊断链路 与 pressure-level 手工重建链路 之间的差别; - 青藏高原是本案例中最突出的差异核心区,最大绝对差出现在 28.0°N, 86.75°E;
- 引入 DEM 后发现,高程与绝对差的相关系数约为 0.499,且从低地到高地平均绝对差呈明显递增,说明 地形确实是重要影响因素;
- 日本附近也存在显著差异,但结合地形场看,更可能体现海陆过渡区和天气系统敏感区的影响,而不是单纯的高地形效应;
- 若研究目标是与 ERA5 原生 K 指数保持严格一致,则更推荐直接使用
kx;若研究目标是透明、可控地理解 K 指数构成,则手工重建方法更便于分析每一项贡献。
从当前案例结果看,手工 K 指数相对 ERA5 原生 K 指数存在约 5 ℃量级的全域平均绝对差,但这一差异在空间上并不均匀,而是明显集中在高原及部分海陆过渡区。加入 DEM 后,这一空间特征得到了进一步定量验证。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号