同花顺实现行业资金流向热力图


前几天群里有同学反馈,之前写的akshare 频繁获取东方财富数据 ip被封了,写的功能没法用了。既然没法用了,有什么好的办法, 这里说一下, 要么用ip代理,要么换个数据源呗。
既然提出了问题, 那这里用前几天写的同花顺主力资金流向为例写一个UI界面,来演示下 行业资金流向去哪了。 技术选型 还是老朋友streamlit 和plotly 。
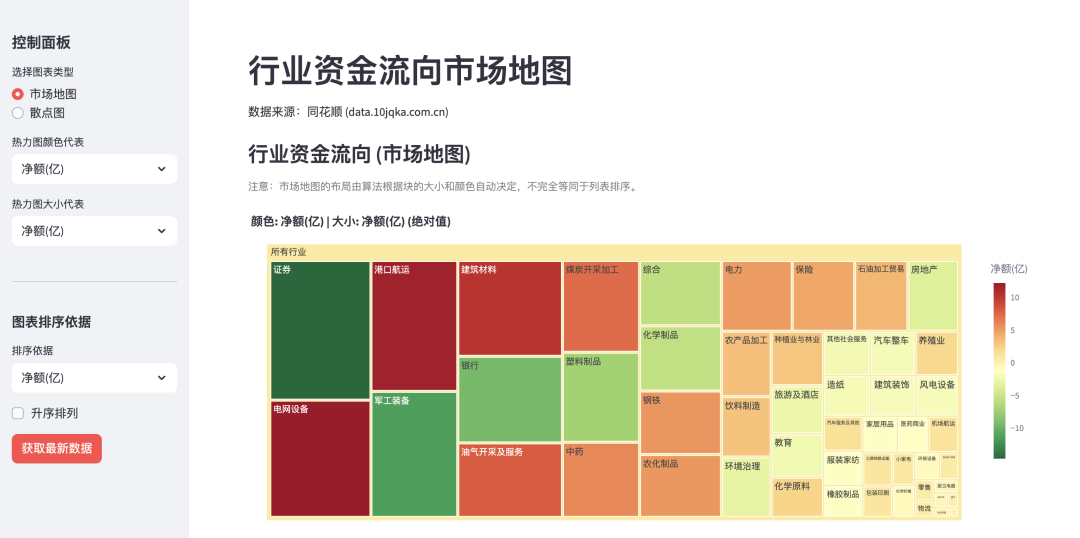
看上面的图可以看出,周五的资金去了 电网、港口、建筑材料这些 散户很少光顾的行业。 至于科创、创业板大跌,就不用多想了,如果之前一直持有,前面赚得也不少了。
回到正题,为什么我们要紧盯“行业资金流向”?
在探讨技术之前,我们必须先明白其价值所在。单一个股的涨跌可能受消息、情绪等偶然因素影响,但整个行业的资金异动,往往代表着机构等大资金对某一板块未来趋势的集体判断。
- 发现市场热点:持续净流入的行业,是市场资金的“宠儿”,往往是当下最强的主线。跟随热点,意味着更高的胜率和更快的盈利速度。
- 规避潜在风险:持续净流出的行业,说明资金正在“用脚投票”,可能预示着板块景气度下降或估值过高。及时规避,可以有效保护你的本金。
- 洞察板块轮动:市场并非一成不变。通过观察资金从高位板块流出,并流入低位板块的现象,我们可以精准捕捉“板块轮动”的节奏,实现高低切换,获得超额收益。
因此,一个能够清晰、直观、实时展示行业资金流向的工具,是每一位严肃投资者的“军火库”里不可或缺的武器。
题外话:
和朋友闲聊,说你的公众号数据看着不错的,每篇至少有十分之一的分享率, 为啥阅读量那么低呢? 其实吧, 没有平台推荐,就靠一些老读者阅读,当然不高了。 在这个年代, 让别人知道你在炒股是 很羞耻的事情。也不知道怎么能增加阅读量,就凑合着写,凑合着看吧。
这里贴一下完整代码,参考下思路, 具体根据自己的实际情况改造。 备注:如果发现格式有多余的特殊字符,用普通浏览器打开复制应该没问题。 希望我的分享对大家有所帮助
import streamlit as st
import plotly.express as px
import pandas as pd
import io
import requests
from bs4 import BeautifulSoup
import py_mini_racer
# --- 数据抓取函数 ---
@st.cache_data(ttl=600)
def get_zijindongxiang_data():
try:
from akshare.datasets import get_ths_js
js_file_path = get_ths_js("ths.js")
except ImportError:
st.error("请安装 akshare 库: pip install akshare")
return pd.DataFrame()
except Exception as e:
st.error(f"无法获取 ths.js 文件: {e}")
return pd.DataFrame()
def _get_file_content_ths(file_path: str) -> str:
with open(file_path, encoding="utf-8") as f:
return f.read()
js_code = py_mini_racer.MiniRacer()
js_content = _get_file_content_ths(js_file_path)
js_code.eval(js_content)
v_code = js_code.call("v")
headers = {
"Accept": "text/html, */*; q=0.01", "Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8", "Cache-Control": "no-cache",
"Connection": "keep-alive", "hexin-v": v_code, "Host": "data.10jqka.com.cn",
"Pragma": "no-cache", "Referer": "http://data.10jqka.com.cn/funds/hyzjl/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36",
"X-Requested-With": "XMLHttpRequest",
}
initial_url = "http://data.10jqka.com.cn/funds/hyzjl/field/tradezdf/order/desc/ajax/1/free/1/"
try:
r = requests.get(initial_url, headers=headers)
r.raise_for_status()
soup = BeautifulSoup(r.text, features="lxml")
raw_page = soup.find(name="span", attrs={"class": "page_info"}).text
page_num = int(raw_page.split("/")[1])
except Exception as e:
st.error(f"获取页码信息失败: {e}")
return pd.DataFrame()
url_template = "http://data.10jqka.com.cn/funds/hyzjl/field/tradezdf/order/desc/ajax/1/free/{}/"
big_df = pd.DataFrame()
progress_bar = st.progress(0, text="正在抓取数据...")
for i, page in enumerate(range(1, page_num + 1)):
current_url = url_template.format(page)
try:
r = requests.get(current_url, headers=headers)
r.raise_for_status()
temp_df = pd.read_html(io.StringIO(r.text))[0]
big_df = pd.concat(objs=[big_df, temp_df], ignore_index=True)
except Exception as e:
st.warning(f"第 {page} 页抓取失败,已跳过。错误: {e}")
continue
finally:
progress_bar.progress((i + 1) / page_num, text=f"正在抓取第 {i + 1}/{page_num} 页...")
progress_bar.empty()
# --- 关键修复:在返回数据前进行去重 ---
# 这将移除所有完全重复的行,确保数据唯一性。
if not big_df.empty:
big_df.drop_duplicates(inplace=True)
return big_df
# --- Streamlit 应用主体 ---
st.set_page_config(layout="wide", page_title="行业资金流向热力图")
st.title("行业资金流向市场地图")
st.markdown("数据来源:同花顺 (data.10jqka.com.cn)")
# --- 侧边栏控件 ---
st.sidebar.header("控制面板")
chart_type = st.sidebar.radio("选择图表类型", ("市场地图", "散点图"), index=0)
color_by_option = st.sidebar.selectbox("热力图颜色代表", ("净额(亿)", "流入资金(亿)"), index=0)
size_by_option = st.sidebar.selectbox("热力图大小代表", ("净额(亿)", "流入资金(亿)"), index=0)
st.sidebar.markdown("---")
st.sidebar.subheader("图表排序依据")
sort_options = {
"行业名称": "行业名称", "行业涨跌幅(%)": "行业涨跌幅", "净额(亿)": "净额(亿)",
"流入资金(亿)": "流入资金(亿)", "公司家数": "公司家数", "领涨股涨跌幅(%)": "领涨股涨跌幅",
}
sort_by_col = st.sidebar.selectbox("排序依据", options=list(sort_options.keys()), index=2)
sort_ascending = st.sidebar.checkbox("升序排列", value=False)
# --- 数据加载与处理 ---
if st.sidebar.button("获取最新数据", type="primary"):
st.cache_data.clear()
with st.spinner("正在加载数据,请稍候..."):
df = get_zijindongxiang_data()
if df.empty:
st.error("未能获取到数据,请检查网络连接或稍后重试。")
st.stop()
# --- 数据清洗和准备 ---
column_map = {
'行业': '行业名称', '涨跌幅': '行业涨跌幅', '流入资金(亿)': '流入资金(亿)',
'流出资金(亿)': '流出资金(亿)', '净额(亿)': '净额(亿)', '公司家数': '公司家数',
'领涨股': '领涨股', '涨跌幅.1': '领涨股涨跌幅', '当前价(元)': '当前价(元)',
}
df.rename(columns=column_map, inplace=True)
def clean_numeric_series(series):
if series.dtype == 'object':
series = series.astype(str).str.replace('%', '', regex=False)
series = series.str.replace('--', '0', regex=False)
series = series.str.replace(',', '', regex=False)
return pd.to_numeric(series, errors='coerce')
numeric_cols_to_clean = [
'行业涨跌幅', '流入资金(亿)', '流出资金(亿)', '净额(亿)',
'公司家数', '领涨股涨跌幅', '当前价(元)'
]
for col in numeric_cols_to_clean:
if col in df.columns:
df[col] = clean_numeric_series(df[col])
# 根据用户选择对数据进行排序,用于图表
df_plot = df.sort_values(by=sort_options[sort_by_col], ascending=sort_ascending)
# 用于数据表的排序后的DataFrame
df_table = df_plot.copy()
# --- 绘制图表 ---
st.subheader(f"行业资金流向 ({chart_type})")
color_col = '行业涨跌幅' if color_by_option == "行业涨跌幅(%)" else '净额(亿)'
size_col = '净额(亿)' if size_by_option == "净额(亿)" else '公司家数'
# 添加绝对值列用于大小
df_plot['净额(亿)_abs'] = df_plot['净额(亿)'].abs()
df_plot[size_col + '_abs'] = df_plot[size_col].abs()
df_plot.dropna(subset=[color_col, size_col + '_abs'], inplace=True)
if df_plot.empty:
st.error("绘图数据为空,可能是因为关键列(如净额或涨跌幅)包含无效数据。")
st.stop()
if chart_type == "市场地图":
st.caption("注意:市场地图的布局由算法根据块的大小和颜色自动决定,不完全等同于列表排序。")
fig = px.treemap(
df_plot,
path=[px.Constant("所有行业"), '行业名称'],
values=size_col + '_abs',
color=color_col,
color_continuous_scale='RdYlGn_r', # 红色代表热门
hover_data={
'行业涨跌幅': ':.2f%', '净额(亿)': ':.2f', '领涨股': True, '领涨股涨跌幅': ':.2f%'
},
title=f"颜色: {color_by_option} | 大小: {size_by_option} (绝对值)"
)
fig.update_traces(
hovertemplate='<b>%{label}</b><br>行业涨跌幅: %{customdata[0]}<br>净额: %{customdata[1]} 亿<br>领涨股: %{customdata[2]} (%{customdata[3]})<extra></extra>'
)
fig.update_layout(margin=dict(t=50, l=25, r=25, b=25))
st.plotly_chart(fig, use_container_width=True)
# --- 方案2: 散点图 ---
elif chart_type == "散点图":
fig = px.scatter(
df_plot,
x='公司家数',
y='行业名称',
size=size_col + '_abs',
color=color_col,
color_continuous_scale='RdYlGn_r',
hover_data={
'行业涨跌幅': ':.2f%', '净额(亿)': ':.2f', '领涨股': True, '领涨股涨跌幅': ':.2f%'
},
title=f"颜色: {color_by_option} | 大小: {size_by_option} (绝对值) | X轴: 公司家数"
)
fig.update_traces(
hovertemplate='<b>%{y}</b><br>公司家数: %{x}<br>行业涨跌幅: %{customdata[0]}<br>净额: %{customdata[1]} 亿<br>领涨股: %{customdata[2]} (%{customdata[3]})<extra></extra>'
)
fig.update_layout(
yaxis={'categoryorder': 'array', 'categoryarray': df_plot['行业名称'].tolist()},
height=800
)
st.plotly_chart(fig, use_container_width=True)
# --- 显示原始数据表格 ---
st.subheader("详细数据表")
st.dataframe(df_table, use_container_width=True)如果我的分享对你投资有所帮助,不吝啬给个点赞关注呗。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号