MySQL数据库进化论-从增删改查到 AI 向量
原创

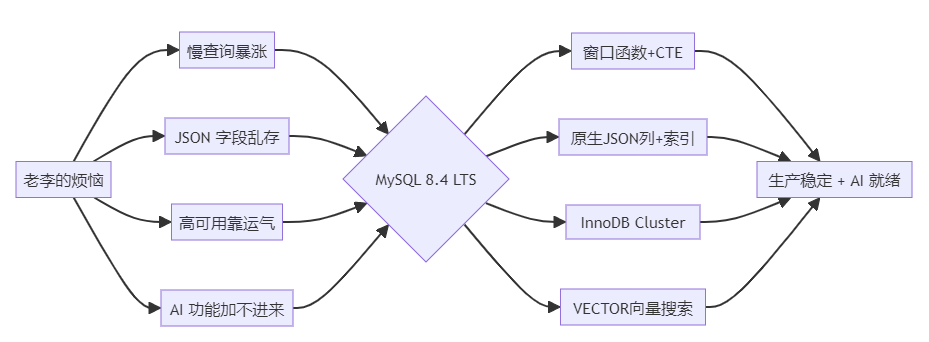
一、痛点引入:老李的数据库困境
"千里之行,始于足下。"——《道德经》
老李的团队用了三年 MySQL 5.7,最近遇到三道坎:
第一道坎:活动大促期间,促销规则里塞了一堆 JSON 字符串,用 LIKE '%color=red%' 全表扫。DBA 深夜打电话说慢查询报表刷屏了。
第二道坎:老板要求接入 AI 推荐,供应商说向量数据库要单独采购,一年几十万。老李皱眉:MySQL 就不能存向量?
第三道坎:主库宕机演练,切换耗时 8 分钟,订单丢了几百条,SLA 直接崩。
MySQL 8.4 LTS 是答案的起点,但不是终点。这篇文章,老李来带你把每个特性跑通。
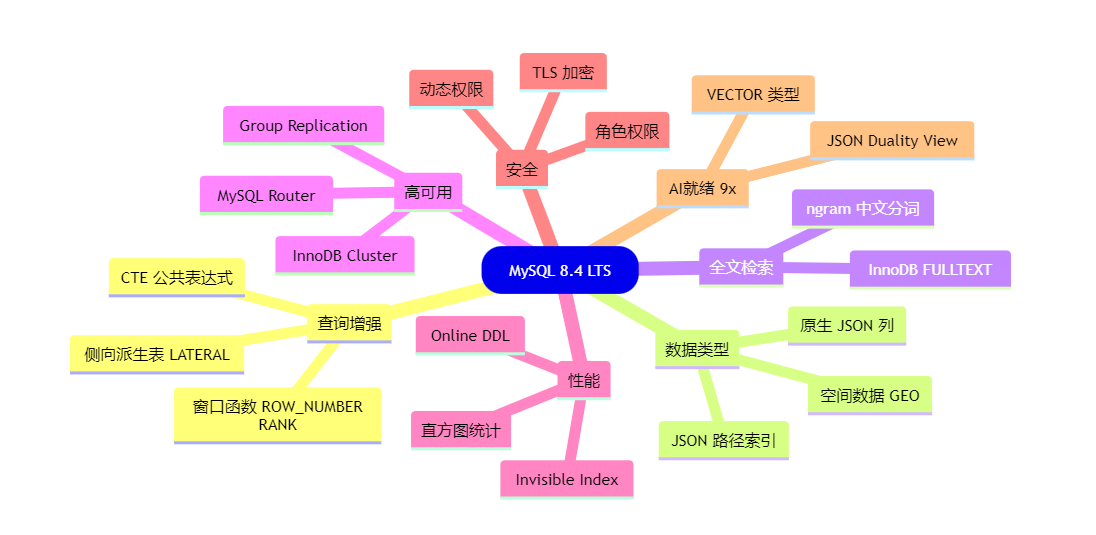
二、是什么:MySQL 8.4 LTS 特性全景
"工欲善其事,必先利其器。"——《论语》
MySQL 目前双轨并行:
版本 | 类型 | 适用场景 |
|---|---|---|
8.4.x | LTS 长期支持,支持至 2032 | 生产首选 |
9.4.x | Innovation 创新版 | 尝鲜/技术储备 |
8.4 LTS 核心特性矩阵:
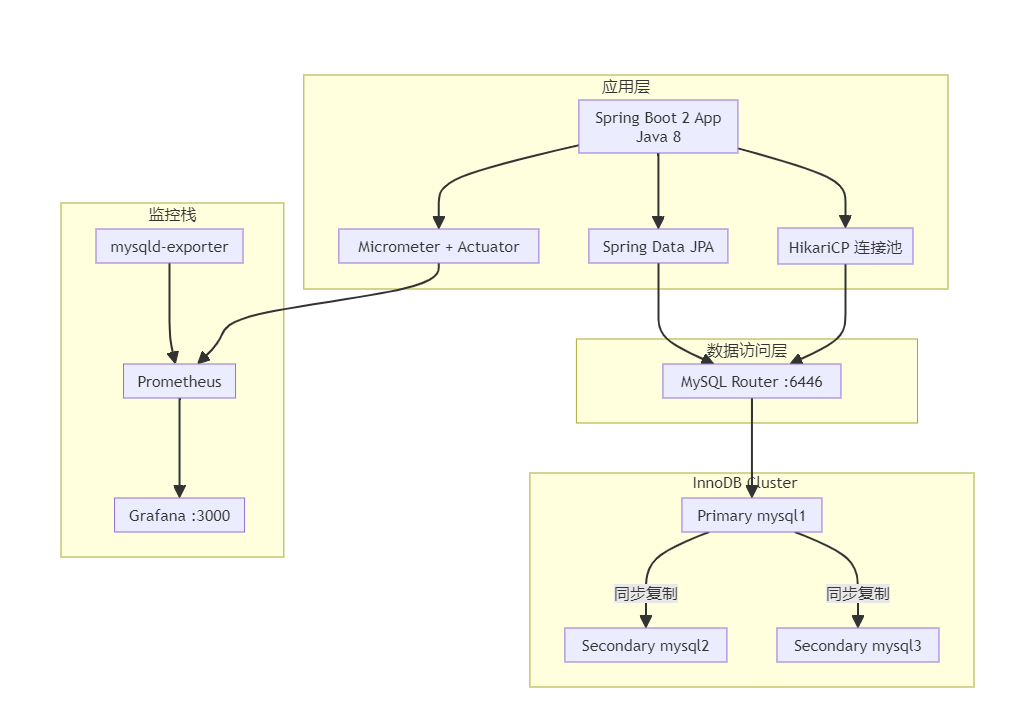
三、架构图:Spring Boot 2 + MySQL 8.4 技术全栈
"凡事预则立,不预则废。"——《礼记》
四、Docker Compose 一键启动
"纸上得来终觉浅,绝知此事要躬行。"——陆游
4.1 docker-compose.yml(完整监控栈)
version: "3.9"
services:
mysql:
image: mysql:8.4.4
container_name: mysql84
environment:
MYSQL_ROOT_PASSWORD: rootpass
MYSQL_DATABASE: shopdb
MYSQL_USER: appuser
MYSQL_PASSWORD: apppass
volumes:
- mysql_data:/var/lib/mysql
- ./conf/my.cnf:/etc/mysql/conf.d/my.cnf:ro
- ./init:/docker-entrypoint-initdb.d:ro
ports:
- "3306:3306"
healthcheck:
test: ["CMD", "mysqladmin", "ping", "-h", "localhost", "-uappuser", "-papppass"]
interval: 10s
timeout: 5s
retries: 5
restart: unless-stopped
networks: [backend]
mysqld-exporter:
image: prom/mysqld-exporter:latest
container_name: mysqld_exporter
environment:
DATA_SOURCE_NAME: "exporter:exporterpass@(mysql:3306)/"
ports:
- "9104:9104"
depends_on:
mysql:
condition: service_healthy
networks: [backend]
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml:ro
ports:
- "9090:9090"
command:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--web.enable-lifecycle"
networks: [backend]
grafana:
image: grafana/grafana:latest
container_name: grafana
environment:
GF_SECURITY_ADMIN_USER: admin
GF_SECURITY_ADMIN_PASSWORD: admin123
volumes:
- grafana_data:/var/lib/grafana
- ./grafana/provisioning:/etc/grafana/provisioning:ro
ports:
- "3000:3000"
depends_on: [prometheus]
networks: [backend]
app:
build: .
container_name: spring-app
ports:
- "8080:8080"
environment:
SPRING_DATASOURCE_URL: >
jdbc:mysql://mysql:3306/shopdb?useSSL=false
&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
&allowPublicKeyRetrieval=true
SPRING_DATASOURCE_USERNAME: appuser
SPRING_DATASOURCE_PASSWORD: apppass
depends_on:
mysql:
condition: service_healthy
networks: [backend]
volumes:
mysql_data:
grafana_data:
networks:
backend:
driver: bridge4.2 conf/my.cnf(生产调优)
[mysqld]
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
default-time-zone = +08:00
# InnoDB 核心调优
innodb_buffer_pool_size = 1G
innodb_buffer_pool_instances = 4
innodb_log_file_size = 256M
innodb_flush_log_at_trx_commit = 1
innodb_flush_method = O_DIRECT
# 连接管理
max_connections = 500
wait_timeout = 28800
max_allowed_packet = 64M
# 慢查询日志(运维必开)
slow_query_log = ON
slow_query_log_file = /var/lib/mysql/slow.log
long_query_time = 1
log_queries_not_using_indexes = ON
# 二进制日志(主从/备份必需)
log_bin = mysql-bin
binlog_format = ROW
expire_logs_days = 74.3 启动与验证
docker compose up -d
# 验证 MySQL 版本
docker exec mysql84 mysql -uappuser -papppass shopdb \
-e "SELECT VERSION(), @@character_set_server, @@innodb_buffer_pool_size\G"
# 应用入口:http://localhost:8080
# Grafana: http://localhost:3000 (admin/admin123,导入 Dashboard ID: 14057)
# Prometheus:http://localhost:9090五、Spring Boot 2 项目基础配置
"根深则叶茂,源浚则流长。"——《贞观政要》
5.1 pom.xml
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.18</version><!-- Java 8 LTS 最后稳定版 -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<!-- MySQL 8.4 官方驱动 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.4.0</version>
</dependency>
<!-- Flyway 数据库版本管理 -->
<dependency>
<groupId>org.flywaydb</groupId>
<artifactId>flyway-mysql</artifactId>
</dependency>
<!-- Prometheus 监控暴露 -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
</dependencies>5.2 application.yml
spring:
datasource:
url: jdbc:mysql://mysql:3306/shopdb?useSSL=false&characterEncoding=UTF-8
&serverTimezone=Asia/Shanghai&useUnicode=true&allowPublicKeyRetrieval=true
username: appuser
password: apppass
driver-class-name: com.mysql.cj.jdbc.Driver
hikari:
maximum-pool-size: 20
minimum-idle: 5
connection-timeout: 30000
idle-timeout: 600000
max-lifetime: 1800000
connection-test-query: SELECT 1
jpa:
hibernate:
ddl-auto: validate # 生产:validate;Flyway 负责 DDL
show-sql: false
open-in-view: false # 关闭 OSIV,避免连接泄漏
properties:
hibernate.dialect: org.hibernate.dialect.MySQL8Dialect
hibernate.jdbc.batch_size: 50
flyway:
enabled: true
locations: classpath:db/migration
management:
endpoints:
web:
exposure:
include: "*"
metrics:
export:
prometheus:
enabled: true六、特性一:ACID 事务 + InnoDB 悲观锁(防超卖场景)
"不患寡而患不均,不患贫而患不安。"——《论语》
场景:大促秒杀,1000 个请求同时下单抢最后 10 件商品,必须保证库存不为负。
DDL(Flyway V1__init_schema.sql)
CREATE TABLE product (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(200) NOT NULL,
price DECIMAL(10,2) NOT NULL,
stock INT NOT NULL DEFAULT 0,
version INT NOT NULL DEFAULT 0 COMMENT '乐观锁版本号',
attrs JSON COMMENT '扩展属性',
FULLTEXT KEY idx_ft_name (name) WITH PARSER ngram
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
CREATE TABLE `order` (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
order_no VARCHAR(32) NOT NULL UNIQUE COMMENT '幂等号',
user_id BIGINT NOT NULL,
product_id BIGINT NOT NULL,
qty INT NOT NULL,
amount DECIMAL(10,2) NOT NULL,
status ENUM('PENDING','PAID','CANCELLED') DEFAULT 'PENDING',
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
updated_at DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
INDEX idx_user_status (user_id, status),
INDEX idx_product (product_id),
FOREIGN KEY (product_id) REFERENCES product(id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;Entity
// Product.java
@Entity
@Table(name = "product")
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private BigDecimal price;
private Integer stock;
@Version // 乐观锁(与悲观锁二选一)
private Integer version;
@Column(columnDefinition = "JSON")
@Convert(converter = JsonAttributeConverter.class)
private Map<String, Object> attrs;
// getters / setters 略(建议用 Lombok @Data)
}
// Order.java
@Entity
@Table(name = "`order`")
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String orderNo;
private Long userId;
private Long productId;
private Integer qty;
private BigDecimal amount;
@Enumerated(EnumType.STRING)
private OrderStatus status = OrderStatus.PENDING;
// getters / setters 略
}Repository
// ProductRepository.java
public interface ProductRepository extends JpaRepository<Product, Long> {
// 悲观写锁:SELECT ... FOR UPDATE
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT p FROM Product p WHERE p.id = :id")
Optional<Product> findByIdForUpdate(@Param("id") Long id);
}
// OrderRepository.java
public interface OrderRepository extends JpaRepository<Order, Long> {
boolean existsByOrderNo(String orderNo);
}Service(核心事务逻辑)
@Service
@Slf4j
public class OrderService {
@Autowired private ProductRepository productRepo;
@Autowired private OrderRepository orderRepo;
/**
* 场景:电商下单 — 悲观锁防超卖 + 幂等控制
* MySQL 特性:InnoDB 行级锁 (SELECT FOR UPDATE), ACID 事务
*/
@Transactional(rollbackFor = Exception.class)
public Order placeOrder(String orderNo, Long userId, Long productId, int qty) {
// 幂等校验:同一 orderNo 只处理一次
if (orderRepo.existsByOrderNo(orderNo)) {
throw new DuplicateOrderException("重复下单: " + orderNo);
}
// 悲观锁:同一商品的并发下单串行化
Product product = productRepo.findByIdForUpdate(productId)
.orElseThrow(() -> new ProductNotFoundException("商品不存在: " + productId));
if (product.getStock() < qty) {
throw new InsufficientStockException(
"库存不足,当前库存: " + product.getStock() + ",需要: " + qty);
}
// 扣减库存
product.setStock(product.getStock() - qty);
productRepo.save(product);
// 创建订单
Order order = new Order();
order.setOrderNo(orderNo);
order.setUserId(userId);
order.setProductId(productId);
order.setQty(qty);
order.setAmount(product.getPrice().multiply(BigDecimal.valueOf(qty)));
Order saved = orderRepo.save(order);
log.info("下单成功 orderNo={} userId={} productId={} qty={}", orderNo, userId, productId, qty);
return saved;
}
/**
* 场景:批量取消超时未付款订单
* MySQL 特性:ENUM 状态机 + 批量更新
*/
@Transactional
public int cancelTimeoutOrders(int timeoutMinutes) {
// 原生 SQL 批量更新,避免 N+1
return orderRepo.cancelTimeoutPendingOrders(timeoutMinutes);
}
}验证 REST 接口
@RestController
@RequestMapping("/api/orders")
public class OrderController {
@Autowired private OrderService orderService;
@PostMapping
public ResponseEntity<Order> placeOrder(@RequestBody PlaceOrderRequest req) {
// 生成幂等号:客户端传入或服务端生成
String orderNo = req.getOrderNo() != null ? req.getOrderNo()
: "ORD-" + System.currentTimeMillis() + "-" + req.getUserId();
Order order = orderService.placeOrder(
orderNo, req.getUserId(), req.getProductId(), req.getQty());
return ResponseEntity.ok(order);
}
}# 验证:并发 100 个请求抢最后 10 件
for i in $(seq 1 100); do
curl -s -X POST http://localhost:8080/api/orders \
-H "Content-Type: application/json" \
-d "{\"userId\":$i,\"productId\":1,\"qty\":1}" &
done
wait
# 验证库存不为负
docker exec mysql84 mysql -uappuser -papppass shopdb \
-e "SELECT stock FROM product WHERE id=1;"七、特性二:原生 JSON 列 + 路径索引(SKU 扩展属性场景)
"橘生淮南则为橘,生于淮北则为枳。"——《晏子春秋》
场景:电商 SKU 每个品类属性不同(手机有 RAM/存储,服装有尺码/颜色),用 JSON 列灵活扩展,无需频繁加字段。
DDL
-- 为 JSON 字段的常用路径创建虚拟列索引(MySQL 8.x 特性)
ALTER TABLE product
ADD COLUMN brand_v VARCHAR(50)
GENERATED ALWAYS AS (attrs->>'$.brand') VIRTUAL,
ADD INDEX idx_brand (brand_v);
-- 也可以用函数索引(MySQL 8.0.13+)
ALTER TABLE product
ADD INDEX idx_color ((CAST(attrs->>'$.color' AS CHAR(50))));JsonAttributeConverter
// 通用 JSON <-> Map 转换器,所有 JSON 列复用
@Converter
@Component
public class JsonAttributeConverter implements AttributeConverter<Map<String, Object>, String> {
private static final ObjectMapper MAPPER = new ObjectMapper()
.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
@Override
public String convertToDatabaseColumn(Map<String, Object> attribute) {
if (attribute == null) return "{}";
try {
return MAPPER.writeValueAsString(attribute);
} catch (JsonProcessingException e) {
throw new IllegalArgumentException("JSON 序列化失败", e);
}
}
@Override
public Map<String, Object> convertToEntityAttribute(String dbData) {
if (dbData == null || dbData.isBlank()) return new HashMap<>();
try {
return MAPPER.readValue(dbData, new TypeReference<Map<String, Object>>() {});
} catch (JsonProcessingException e) {
throw new IllegalArgumentException("JSON 反序列化失败", e);
}
}
}Repository(JSON 路径查询)
public interface ProductRepository extends JpaRepository<Product, Long> {
// 利用虚拟列索引查询品牌(走索引,高性能)
@Query("SELECT p FROM Product p WHERE p.brandV = :brand")
List<Product> findByBrand(@Param("brand") String brand);
// JSON 路径查询(复杂条件,原生 SQL)
@Query(value = """
SELECT * FROM product
WHERE attrs->>'$.brand' = :brand
AND CAST(attrs->>'$.ram_gb' AS UNSIGNED) >= :minRam
AND JSON_CONTAINS(attrs->'$.tags', :tag)
ORDER BY price ASC
""", nativeQuery = true)
List<Product> findByBrandAndRamAndTag(
@Param("brand") String brand,
@Param("minRam") int minRam,
@Param("tag") String tag
);
// JSON 数组包含查询
@Query(value = "SELECT * FROM product WHERE JSON_CONTAINS(attrs->'$.tags', ?1)",
nativeQuery = true)
List<Product> findByTag(String tagJson); // tagJson = "\"pro\""
}Service(JSON 原子操作)
@Service
public class ProductService {
@Autowired private ProductRepository productRepo;
@Autowired private EntityManager entityManager;
/**
* 场景:更新商品颜色和促销标签(JSON 原子更新)
* MySQL 特性:JSON_SET, JSON_ARRAY_APPEND,原子操作不影响其他字段
*/
@Transactional
public void updateProductAttr(Long productId, String color, String newTag) {
entityManager.createNativeQuery("""
UPDATE product
SET attrs = JSON_SET(
attrs,
'$.color', :color,
'$.updated_at', NOW()
),
attrs = JSON_ARRAY_APPEND(attrs, '$.tags', :newTag)
WHERE id = :id
""")
.setParameter("color", color)
.setParameter("newTag", newTag)
.setParameter("id", productId)
.executeUpdate();
}
/**
* 场景:查询品牌为 Apple、内存 >= 16G 的商品
*/
public List<Product> searchBySpec(String brand, int minRam) {
return productRepo.findByBrandAndRamAndTag(brand, minRam, "\"pro\"");
}
}验证
# 插入含 JSON 的商品
curl -X POST http://localhost:8080/api/products \
-H "Content-Type: application/json" \
-d '{
"name": "MacBook Pro M3",
"price": 15999.00,
"stock": 50,
"attrs": {
"brand": "Apple",
"cpu": "M3",
"ram_gb": 16,
"color": "Space Gray",
"tags": ["laptop", "pro"]
}
}'
# 验证虚拟列索引生效
docker exec mysql84 mysql -uappuser -papppass shopdb \
-e "EXPLAIN SELECT * FROM product WHERE brand_v = 'Apple'\G"
# 预期:type=ref,key=idx_brand八、特性三:窗口函数 + CTE(销售排行榜场景)
"海纳百川,有容乃大。"——林则徐
场景:运营每天要看「各品类 TOP5 销售商品」「累计销售额趋势」,之前要写三层嵌套子查询,现在用 CTE + 窗口函数一气呵成。
Repository(原生 SQL 窗口函数)
public interface OrderRepository extends JpaRepository<Order, Long> {
/**
* MySQL 8.x 窗口函数:每个品类销售额 Top5
* RANK() OVER (PARTITION BY ...)
*/
@Query(value = """
WITH daily_sales AS (
SELECT
p.id AS product_id,
p.name AS product_name,
p.attrs->>'$.brand' AS brand,
DATE(o.created_at) AS sale_date,
SUM(o.qty) AS units,
SUM(o.amount) AS revenue
FROM `order` o
JOIN product p ON o.product_id = p.id
WHERE o.status = 'PAID'
AND o.created_at >= DATE_SUB(NOW(), INTERVAL :days DAY)
GROUP BY p.id, p.name, p.attrs->>'$.brand', DATE(o.created_at)
),
ranked AS (
SELECT *,
RANK() OVER (PARTITION BY brand, sale_date ORDER BY revenue DESC) AS daily_rank,
SUM(revenue) OVER (PARTITION BY product_id ORDER BY sale_date
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_rev,
LAG(revenue, 1, 0) OVER (PARTITION BY product_id ORDER BY sale_date) AS prev_day_rev
FROM daily_sales
)
SELECT
product_id, product_name, brand, sale_date,
units, revenue, daily_rank, cumulative_rev,
ROUND((revenue - prev_day_rev) / NULLIF(prev_day_rev, 0) * 100, 2) AS day_over_day_pct
FROM ranked
WHERE daily_rank <= :topN
ORDER BY sale_date DESC, brand, daily_rank
""", nativeQuery = true)
List<Object[]> getSalesRankReport(@Param("days") int days, @Param("topN") int topN);
/**
* 累计 GMV + 7 日移动平均(时序分析)
*/
@Query(value = """
WITH daily_gmv AS (
SELECT DATE(created_at) AS dt, SUM(amount) AS gmv
FROM `order` WHERE status = 'PAID'
GROUP BY DATE(created_at)
)
SELECT dt, gmv,
SUM(gmv) OVER (ORDER BY dt) AS total_gmv,
AVG(gmv) OVER (ORDER BY dt ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) AS ma7
FROM daily_gmv
ORDER BY dt DESC
LIMIT 30
""", nativeQuery = true)
List<Object[]> getGmvTrend();
}Service + DTO 封装
@Service
public class ReportService {
@Autowired private OrderRepository orderRepo;
public List<SalesRankDTO> getSalesRank(int days, int topN) {
List<Object[]> rows = orderRepo.getSalesRankReport(days, topN);
return rows.stream().map(row -> SalesRankDTO.builder()
.productId(((Number) row[0]).longValue())
.productName((String) row[1])
.brand((String) row[2])
.saleDate(((java.sql.Date) row[3]).toLocalDate())
.units(((Number) row[4]).intValue())
.revenue((BigDecimal) row[5])
.dailyRank(((Number) row[6]).intValue())
.cumulativeRev((BigDecimal) row[7])
.dayOverDayPct(row[8] != null ? (BigDecimal) row[8] : BigDecimal.ZERO)
.build()
).collect(Collectors.toList());
}
}
@Data
@Builder
public class SalesRankDTO {
private Long productId;
private String productName;
private String brand;
private LocalDate saleDate;
private Integer units;
private BigDecimal revenue;
private Integer dailyRank;
private BigDecimal cumulativeRev;
private BigDecimal dayOverDayPct;
}验证
curl http://localhost:8080/api/reports/sales-rank?days=30&topN=5
# 返回:各品牌最近30天日销售额 Top5,带环比增长率九、特性四:全文检索 ngram(商品搜索场景)
"千淘万漉虽辛苦,吹尽狂沙始到金。"——刘禹锡
场景:用户输入「苹果电脑 16G」,需要对商品名称和描述进行中文全文检索,比 LIKE %keyword% 快几十倍。
DDL
-- 已在 product 表建立 ngram FULLTEXT 索引
-- FULLTEXT KEY idx_ft_name (name) WITH PARSER ngram
-- 系统变量设置(my.cnf 中配置)
-- ngram_token_size = 2 (最小分词单元,默认2)
-- 如果需要对描述字段也加全文索引
ALTER TABLE product
ADD COLUMN description TEXT COMMENT '商品描述',
ADD FULLTEXT KEY idx_ft_desc (name, description) WITH PARSER ngram;Repository
public interface ProductRepository extends JpaRepository<Product, Long> {
/**
* FULLTEXT 布尔模式:支持 + - * 等操作符
* "苹果 +电脑" = 必须含电脑,可以含苹果
* "-二手" = 排除二手
*/
@Query(value = """
SELECT *, MATCH(name, description) AGAINST(:keyword IN BOOLEAN MODE) AS score
FROM product
WHERE MATCH(name, description) AGAINST(:keyword IN BOOLEAN MODE)
ORDER BY score DESC
LIMIT :limit
""", nativeQuery = true)
List<Object[]> fullTextSearchWithScore(
@Param("keyword") String keyword,
@Param("limit") int limit
);
/**
* 自然语言模式:更自然,适合 C 端搜索框
*/
@Query(value = """
SELECT * FROM product
WHERE MATCH(name) AGAINST(:keyword IN NATURAL LANGUAGE MODE)
ORDER BY MATCH(name) AGAINST(:keyword IN NATURAL LANGUAGE MODE) DESC
""", nativeQuery = true)
List<Product> naturalLanguageSearch(@Param("keyword") String keyword);
}Service
@Service
public class SearchService {
@Autowired private ProductRepository productRepo;
/**
* 场景:商品搜索页
* MySQL 特性:FULLTEXT BOOLEAN MODE,ngram 中文分词
* 注意:搜索词需转义特殊字符,防止注入
*/
public List<SearchResultDTO> search(String rawKeyword, int limit) {
// 清洗搜索词:移除 FULLTEXT 操作符特殊字符
String keyword = rawKeyword.replaceAll("[+\\-><()~*\"@]", " ").trim();
if (keyword.isEmpty()) return Collections.emptyList();
List<Object[]> rows = productRepo.fullTextSearchWithScore(keyword, limit);
return rows.stream().map(row -> {
Product p = (Product) row[0]; // 这里需要用 DTO 映射方式
double score = ((Number) row[1]).doubleValue();
return new SearchResultDTO(p.getId(), p.getName(), p.getPrice(), score);
}).collect(Collectors.toList());
}
}验证
# 初始化数据
docker exec mysql84 mysql -uappuser -papppass shopdb << 'EOF'
INSERT INTO product (name, description, price, stock, attrs) VALUES
('苹果 MacBook Pro M3 笔记本电脑', 'Apple 最新 M3 芯片,16GB 内存,专业创作利器', 15999, 50, '{"brand":"Apple"}'),
('联想 ThinkPad X1 Carbon 商务本', '轻薄商务笔记本,英特尔酷睿 i7', 9888, 30, '{"brand":"Lenovo"}'),
('华为 MateBook 16s 苹果平板竞品', '16寸大屏笔记本,护眼屏幕', 7999, 20, '{"brand":"Huawei"}');
EOF
# 搜索验证
curl "http://localhost:8080/api/search?q=苹果电脑&limit=10"
# 预期:相关度排序,MacBook 排在最前
# 查看 EXPLAIN 确认走 FULLTEXT 索引
docker exec mysql84 mysql -uappuser -papppass shopdb \
-e "EXPLAIN SELECT * FROM product WHERE MATCH(name) AGAINST('苹果电脑' IN NATURAL LANGUAGE MODE)\G"十、特性五:分区表(日志/时序数据场景)
"不积跬步,无以至千里;不积小流,无以成江海。"——荀子
场景:操作日志每天百万条,一年后几十亿条,查询巨慢。按月分区后,清理历史数据 O(1),查询只扫当月分区。
DDL
-- 按月分区的操作日志表
CREATE TABLE operation_log (
id BIGINT AUTO_INCREMENT,
user_id BIGINT NOT NULL,
action VARCHAR(100) NOT NULL,
target_id BIGINT,
detail TEXT,
ip VARCHAR(45),
created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id, created_at) -- 分区键必须在主键中
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
PARTITION BY RANGE (YEAR(created_at) * 100 + MONTH(created_at)) (
PARTITION p202401 VALUES LESS THAN (202402),
PARTITION p202402 VALUES LESS THAN (202403),
PARTITION p202403 VALUES LESS THAN (202404),
PARTITION p202404 VALUES LESS THAN (202405),
PARTITION p_future VALUES LESS THAN MAXVALUE
);Entity + Repository
@Entity
@Table(name = "operation_log")
public class OperationLog {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long userId;
private String action;
private Long targetId;
private String detail;
private String ip;
private LocalDateTime createdAt;
}
public interface OperationLogRepository extends JpaRepository<OperationLog, Long> {
// 分区裁剪:只扫 created_at 范围内的分区(关键!)
@Query("SELECT l FROM OperationLog l WHERE l.userId = :userId " +
"AND l.createdAt BETWEEN :start AND :end ORDER BY l.createdAt DESC")
Page<OperationLog> findByUserAndDateRange(
@Param("userId") Long userId,
@Param("start") LocalDateTime start,
@Param("end") LocalDateTime end,
Pageable pageable
);
}Service(含分区维护)
@Service
@Slf4j
public class OperationLogService {
@Autowired private OperationLogRepository logRepo;
@Autowired private EntityManager entityManager;
/**
* 场景:记录用户操作,异步写入(不影响主业务)
*/
@Async
@Transactional
public void logAsync(Long userId, String action, Long targetId, String ip) {
OperationLog log = new OperationLog();
log.setUserId(userId);
log.setAction(action);
log.setTargetId(targetId);
log.setIp(ip);
log.setCreatedAt(LocalDateTime.now());
logRepo.save(log);
}
/**
* 场景:每月定时添加新分区(Scheduled Task)
* MySQL 特性:ALTER TABLE ADD PARTITION,不锁表
*/
@Scheduled(cron = "0 0 1 1 * ?") // 每月1日凌晨1点
@Transactional
public void addNextMonthPartition() {
YearMonth next = YearMonth.now().plusMonths(1);
YearMonth afterNext = next.plusMonths(1);
String partitionName = "p" + next.format(DateTimeFormatter.ofPattern("yyyyMM"));
int lessThanVal = afterNext.getYear() * 100 + afterNext.getMonthValue();
String sql = String.format("""
ALTER TABLE operation_log
REORGANIZE PARTITION p_future INTO (
PARTITION %s VALUES LESS THAN (%d),
PARTITION p_future VALUES LESS THAN MAXVALUE
)
""", partitionName, lessThanVal);
entityManager.createNativeQuery(sql).executeUpdate();
log.info("成功添加分区 {} (< {})", partitionName, lessThanVal);
}
/**
* 场景:删除半年前分区(秒级完成,不影响线上)
*/
@Scheduled(cron = "0 0 2 1 * ?") // 每月1日凌晨2点
@Transactional
public void dropOldPartitions() {
YearMonth cutoff = YearMonth.now().minusMonths(6);
String partitionName = "p" + cutoff.format(DateTimeFormatter.ofPattern("yyyyMM"));
try {
entityManager.createNativeQuery(
"ALTER TABLE operation_log DROP PARTITION " + partitionName
).executeUpdate();
log.info("成功删除分区 {}", partitionName);
} catch (Exception e) {
log.warn("分区不存在或删除失败: {}", partitionName);
}
}
}验证
# 查看分区信息
docker exec mysql84 mysql -uappuser -papppass shopdb \
-e "SELECT PARTITION_NAME, TABLE_ROWS, DATA_LENGTH
FROM information_schema.PARTITIONS
WHERE TABLE_NAME = 'operation_log';"
# 验证分区裁剪(查看 partitions 列只含当月分区)
docker exec mysql84 mysql -uappuser -papppass shopdb \
-e "EXPLAIN PARTITIONS SELECT * FROM operation_log
WHERE created_at BETWEEN '2024-03-01' AND '2024-03-31'\G"十一、特性六:Online DDL(零停机变更场景)
"变则通,通则久。"——《周易》
场景:线上数据库 2 亿条记录,业务方要加字段,DBA 不敢操作,怕锁表。MySQL 8.x Online DDL 让大表加字段也能丝滑进行。
Service(DDL 变更最佳实践)
@Service
@Slf4j
public class SchemaService {
@Autowired private EntityManager entityManager;
/**
* 场景:在线加列,不阻塞读写
* MySQL 8.x 特性:ALGORITHM=INPLACE, LOCK=NONE
*/
public void addColumnOnline(String tableName, String columnDef) {
// ALGORITHM=INPLACE + LOCK=NONE 是最高级别在线 DDL
// 并非所有 DDL 都支持 INPLACE,加前缀 INSTANT 更快(8.0.12+)
String sql = String.format(
"ALTER TABLE %s ADD COLUMN %s, ALGORITHM=INPLACE, LOCK=NONE",
tableName, columnDef
);
log.info("执行 Online DDL: {}", sql);
entityManager.createNativeQuery(sql).executeUpdate();
}
/**
* INSTANT 算法(最快,只改元数据,秒级)
* 适用:加列(尾部)、修改默认值等
*/
public void addColumnInstant(String tableName, String columnDef) {
String sql = String.format(
"ALTER TABLE %s ADD COLUMN %s, ALGORITHM=INSTANT",
tableName, columnDef
);
entityManager.createNativeQuery(sql).executeUpdate();
}
/**
* Invisible Index:先隐藏索引验证影响,再决定是否删除
* 解决:"加了索引变慢怎么办" 的恐惧
*/
public void makeIndexInvisible(String tableName, String indexName) {
entityManager.createNativeQuery(String.format(
"ALTER TABLE %s ALTER INDEX %s INVISIBLE", tableName, indexName
)).executeUpdate();
log.info("索引 {}.{} 已隐藏,观察性能后决定是否删除", tableName, indexName);
}
public void makeIndexVisible(String tableName, String indexName) {
entityManager.createNativeQuery(String.format(
"ALTER TABLE %s ALTER INDEX %s VISIBLE", tableName, indexName
)).executeUpdate();
}
}使用直方图优化查询
-- 为低基数列创建直方图(不创建索引,让优化器更聪明)
ANALYZE TABLE `order` UPDATE HISTOGRAM ON status WITH 10 BUCKETS;
-- 查看直方图统计
SELECT HISTOGRAM->>'$."data-type"' AS type,
HISTOGRAM->>'$."number-of-buckets-specified"' AS buckets
FROM information_schema.COLUMN_STATISTICS
WHERE TABLE_NAME = 'order' AND COLUMN_NAME = 'status';十二、特性七:InnoDB Cluster 高可用(最简三节点)
"居安思危,思则有备,有备无患。"——《左传》
场景:主库宕机,8 分钟人工切换不可接受,要求 RTO < 30s,自动切换,应用无感知。
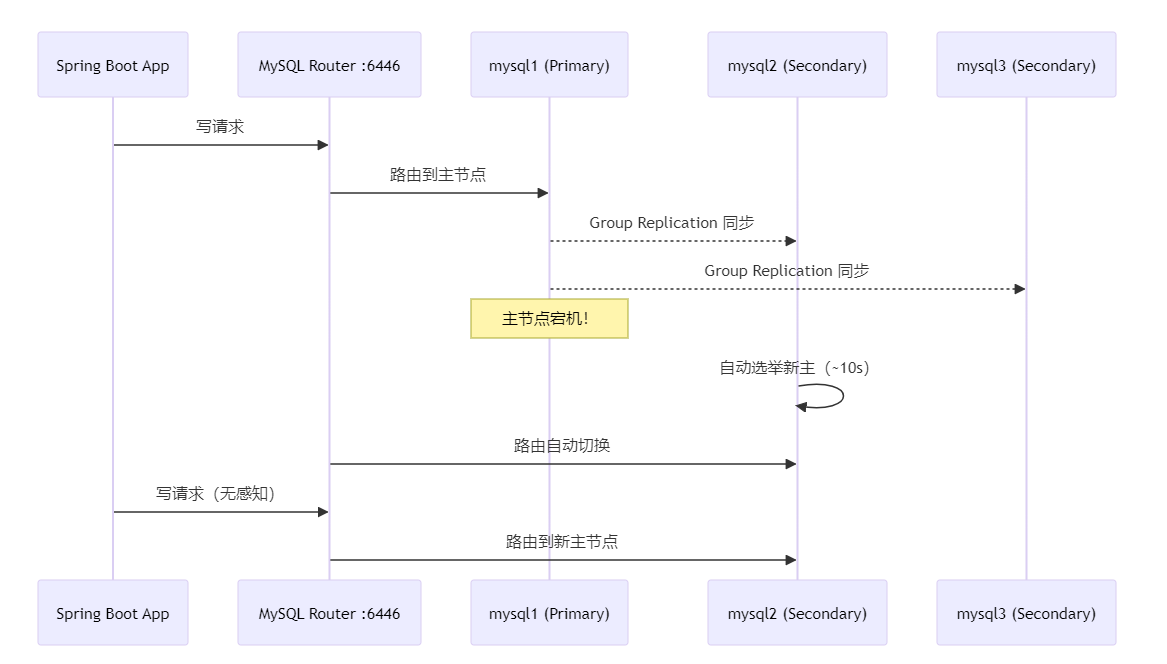
三节点集群配置
# mysql1 的 my.cnf(mysql2/mysql3 改 server_id 和 local_address)
[mysqld]
server_id = 1
gtid_mode = ON
enforce_gtid_consistency = ON
binlog_format = ROW
log_bin = mysql-bin
plugin_load_add = group_replication.so
group_replication_single_primary_mode = ON
group_replication_group_name = "aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee"
group_replication_local_address = "mysql1:33061"
group_replication_group_seeds = "mysql1:33061,mysql2:33061,mysql3:33061"集群初始化(MySQL Shell)
# 在 mysql1 上执行
mysqlsh --uri root@mysql1:3306 -- <<'EOF'
// 检查每个节点配置
dba.configureInstance('root@mysql1:3306', {restart: true})
dba.configureInstance('root@mysql2:3306', {restart: true})
dba.configureInstance('root@mysql3:3306', {restart: true})
// 创建集群
var cluster = dba.createCluster('shopCluster')
cluster.addInstance('root@mysql2:3306', {recoveryMethod: 'clone'})
cluster.addInstance('root@mysql3:3306', {recoveryMethod: 'clone'})
// 验证状态
cluster.status()
EOF
# 部署 MySQL Router
mysqlrouter --bootstrap root@mysql1:3306 \
--directory /opt/router \
--user=mysqlrouter \
--conf-use-gr-notifications
mysqlrouter --config /opt/router/mysqlrouter.conf &Spring Boot 连接 Router(应用层透明 HA)
# 应用连接 Router,完全不感知后端节点切换
spring:
datasource:
url: jdbc:mysql://router:6446/shopdb?useSSL=false&characterEncoding=UTF-8
&serverTimezone=Asia/Shanghai
# 读写分离:读流量走只读端口 6447
datasource-readonly:
url: jdbc:mysql://router:6447/shopdb?useSSL=false&characterEncoding=UTF-8
&serverTimezone=Asia/Shanghai// 多数据源配置(读写分离)
@Configuration
public class DataSourceConfig {
@Bean("primaryDataSource")
@ConfigurationProperties("spring.datasource")
public DataSource primaryDataSource() {
return DataSourceBuilder.create().build();
}
@Bean("readonlyDataSource")
@ConfigurationProperties("spring.datasource-readonly")
public DataSource readonlyDataSource() {
return DataSourceBuilder.create().build();
}
// 使用 AbstractRoutingDataSource 实现动态路由
@Bean
@Primary
public DataSource routingDataSource(
@Qualifier("primaryDataSource") DataSource primary,
@Qualifier("readonlyDataSource") DataSource readonly
) {
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put("write", primary);
targetDataSources.put("read", readonly);
AbstractRoutingDataSource routing = new AbstractRoutingDataSource() {
@Override
protected Object determineCurrentLookupKey() {
// @Transactional(readOnly=true) 路由到只读库
return TransactionSynchronizationManager.isCurrentTransactionReadOnly()
? "read" : "write";
}
};
routing.setDefaultTargetDataSource(primary);
routing.setTargetDataSources(targetDataSources);
return routing;
}
}故障演练
# 模拟主库宕机
docker stop mysql1
# 等待 10-30s,验证自动切换
mysql -u appuser -p -h router -P 6446 \
-e "SELECT @@hostname, @@server_id, @@read_only;"
# 预期输出:主机变为 mysql2 或 mysql3
# 应用层验证(无需重启)
curl -X POST http://localhost:8080/api/orders \
-H "Content-Type: application/json" \
-d '{"userId":1,"productId":1,"qty":1}'
# 预期:订单正常创建,无错误十三、特性八:VECTOR 向量搜索(AI RAG 场景,MySQL 9.x)
"问渠那得清如许,为有源头活水来。"——朱熹
场景:企业知识库问答,用户输入问题,系统在文档库中检索语义最相关的段落,喂给 LLM 生成答案(RAG 架构)。
注意:VECTOR 类型需要 MySQL 9.x。若生产仍在 8.4,可替换为 pgvector 或 Milvus,架构不变。
DDL(MySQL 9.x)
CREATE TABLE document_chunk (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
doc_id BIGINT NOT NULL COMMENT '文档 ID',
doc_title VARCHAR(500) NOT NULL,
chunk_text TEXT NOT NULL COMMENT '分段文本',
embedding VECTOR(1536) NOT NULL COMMENT 'OpenAI text-embedding-3-small 向量',
category VARCHAR(100) COMMENT '文档分类',
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
INDEX idx_doc (doc_id),
INDEX idx_category (category),
VECTOR INDEX idx_embedding (embedding) -- ANN 近似最近邻索引
) ENGINE=InnoDB;依赖(Spring AI)
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>1.0.0</version>
</dependency>Service(RAG 核心)
@Service
@Slf4j
public class RagService {
@Autowired private EmbeddingClient embeddingClient; // Spring AI
@Autowired private EntityManager entityManager;
@Autowired private ChatClient chatClient;
@Autowired private DocumentRepository docRepo;
/**
* 场景:知识库文档入库(Embedding 写入 MySQL)
* MySQL 特性:VECTOR 列存储 float32 数组
*/
@Transactional
public void indexDocument(Long docId, String title, List<String> chunks, String category) {
for (String chunk : chunks) {
// 调用 OpenAI 生成 embedding(1536 维)
float[] vector = embeddingClient.embed(chunk);
entityManager.createNativeQuery("""
INSERT INTO document_chunk (doc_id, doc_title, chunk_text, embedding, category)
VALUES (:docId, :title, :chunk, STRING_TO_VECTOR(:vec), :category)
""")
.setParameter("docId", docId)
.setParameter("title", title)
.setParameter("chunk", chunk)
.setParameter("vec", vectorToString(vector))
.setParameter("category", category)
.executeUpdate();
}
log.info("文档 {} 入库完成,共 {} 段", title, chunks.size());
}
/**
* 场景:语义检索 + LLM 回答(完整 RAG 流程)
* MySQL 特性:VECTOR 余弦距离查询 DISTANCE(..., 'COSINE')
*/
public RagAnswerDTO query(String question, String category, int topK) {
// Step 1: 问题向量化
float[] queryVector = embeddingClient.embed(question);
// Step 2: MySQL 向量相似度检索
List<Object[]> relevant = entityManager.createNativeQuery("""
SELECT id, chunk_text, doc_title,
DISTANCE(embedding, STRING_TO_VECTOR(:vec), 'COSINE') AS score
FROM document_chunk
WHERE (:category IS NULL OR category = :category)
AND DISTANCE(embedding, STRING_TO_VECTOR(:vec), 'COSINE') < 0.5
ORDER BY score ASC
LIMIT :topK
""")
.setParameter("vec", vectorToString(queryVector))
.setParameter("category", category)
.setParameter("topK", topK)
.getResultList();
if (relevant.isEmpty()) {
return RagAnswerDTO.noContext("未找到相关文档,请换个问法。");
}
// Step 3: 构建上下文
String context = relevant.stream()
.map(row -> "【" + row[2] + "】\n" + row[1])
.collect(Collectors.joining("\n\n---\n\n"));
// Step 4: 调用 LLM(带上下文)
String prompt = String.format("""
你是企业知识库助手。请基于以下文档内容回答用户问题。
如果文档中没有相关信息,请明确说明,不要编造。
文档内容:
%s
用户问题:%s
""", context, question);
String answer = chatClient.prompt()
.user(prompt)
.call().content();
List<String> sources = relevant.stream()
.map(row -> (String) row[2])
.distinct()
.collect(Collectors.toList());
return RagAnswerDTO.builder()
.answer(answer)
.sources(sources)
.contextCount(relevant.size())
.build();
}
private String vectorToString(float[] vector) {
StringBuilder sb = new StringBuilder("[");
for (int i = 0; i < vector.length; i++) {
sb.append(vector[i]);
if (i < vector.length - 1) sb.append(",");
}
return sb.append("]").toString();
}
}8.4 LTS 降级方案(不升级到 9.x 的过渡方法)
/**
* 在 MySQL 8.4 中存储向量的兼容方案
* 用 BLOB 列存 float[] 的二进制,通过应用层计算余弦距离
* 性能低于原生 VECTOR,适合数据量 < 10万 的场景
* 大规模建议外接 Milvus 或 pgvector
*/
@Service
public class VectorSearchFallback {
@Autowired private JdbcTemplate jdbc;
public void saveEmbedding(Long chunkId, float[] vector) {
byte[] bytes = floatArrayToBytes(vector);
jdbc.update("UPDATE document_chunk SET embedding_blob = ? WHERE id = ?", bytes, chunkId);
}
public List<Long> findTopK(float[] queryVector, int k) {
List<Map<String, Object>> rows = jdbc.queryForList(
"SELECT id, embedding_blob FROM document_chunk WHERE embedding_blob IS NOT NULL");
return rows.stream()
.map(row -> {
float[] stored = bytesToFloatArray((byte[]) row.get("embedding_blob"));
double score = cosineSimilarity(queryVector, stored);
return Map.entry(((Number) row.get("id")).longValue(), score);
})
.sorted(Map.Entry.<Long, Double>comparingByValue().reversed())
.limit(k)
.map(Map.Entry::getKey)
.collect(Collectors.toList());
}
private double cosineSimilarity(float[] a, float[] b) {
double dot = 0, normA = 0, normB = 0;
for (int i = 0; i < a.length; i++) {
dot += a[i] * b[i];
normA += a[i] * a[i];
normB += b[i] * b[i];
}
return dot / (Math.sqrt(normA) * Math.sqrt(normB));
}
}十四、开源协议深度解读
"名不正则言不顺,言不顺则事不成。"——《论语》
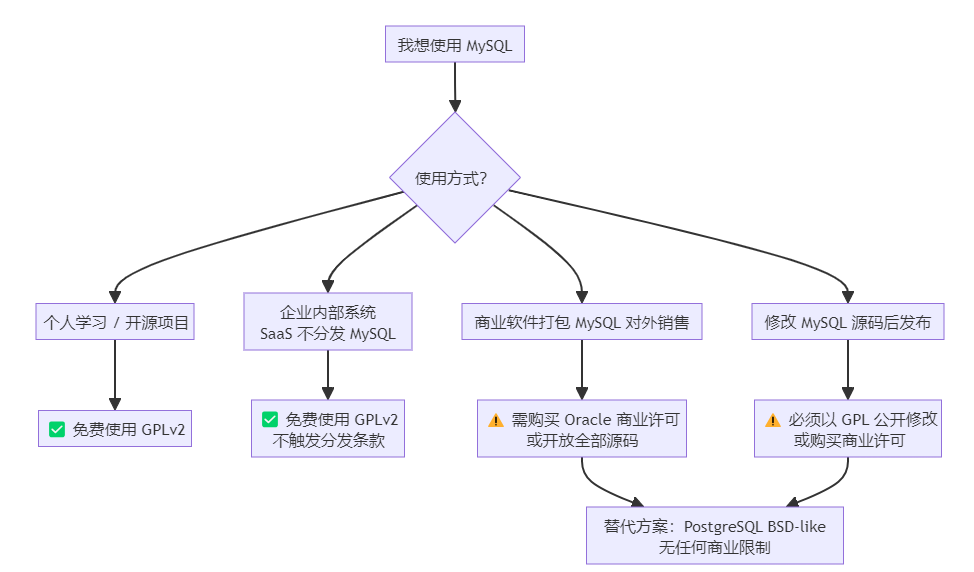
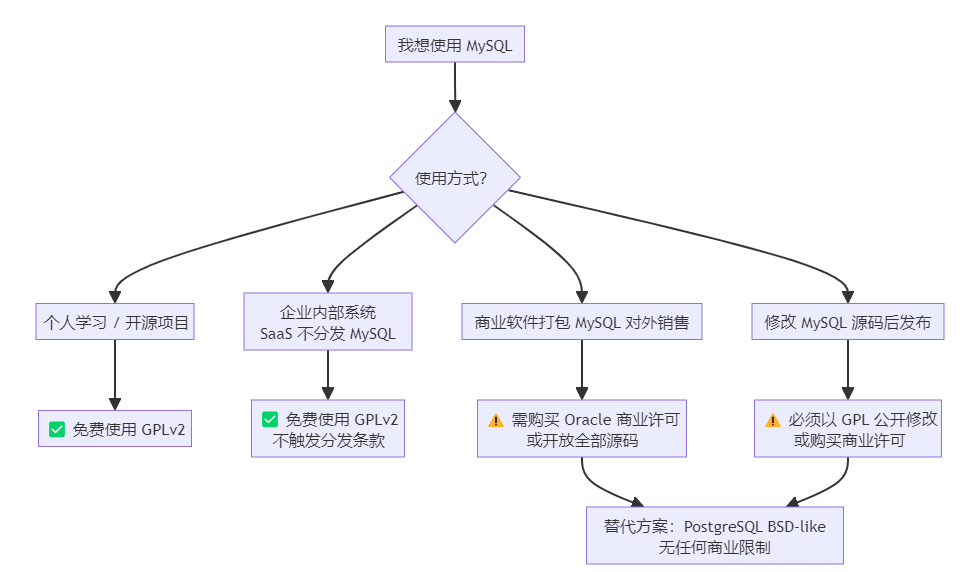
场景 | 社区版 GPLv2 | 商业版 | 推荐 |
|---|---|---|---|
个人/学习 | ✅ 免费 | — | 社区版 |
企业内部 SaaS | ✅ 免费 | — | 社区版 |
嵌入商业产品销售 | ⚠️ 需开放源码 | ✅ 付费解除 | 商业版 或 PostgreSQL |
需要审计/防火墙/企业备份 | ❌ 无此功能 | ✅ 企业版包含 | 企业版 |
对许可证零容忍 | ❌ | — | PostgreSQL |
十五、替代方案对比与快速迁移
"他山之石,可以攻玉。"——《诗经》
维度 | MySQL 8.4 | PostgreSQL 17 | MariaDB 11.x |
|---|---|---|---|
许可证 | GPLv2 双重许可 | BSD-like(无限制) | GPLv2 |
AI 向量 | 9.x 才有(较新) | pgvector 最成熟 | 无 |
JSON | JSON 列 + 路径索引 | JSONB(更强) | JSON 列 |
读性能 | 最快(简单查询) | 复杂查询更强 | 接近 MySQL |
高可用 | InnoDB Cluster | Patroni+pgBouncer | Galera(最成熟) |
Spring Boot | 原生一流 | 原生一流 | 兼容 MySQL 驱动 |
适用场景 | Web/OLTP 首选 | AI/分析/新项目 | MySQL 替换过渡 |
PostgreSQL 17 + pgvector 快速启动
# docker-compose-pg.yml
version: "3.9"
services:
postgres:
image: pgvector/pgvector:pg17 # 官方含 pgvector 镜像
container_name: postgres17
environment:
POSTGRES_USER: appuser
POSTGRES_PASSWORD: apppass
POSTGRES_DB: shopdb
ports:
- "5432:5432"
volumes:
- pg_data:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U appuser -d shopdb"]
interval: 10s
volumes:
pg_data:-- 启用 pgvector 扩展
CREATE EXTENSION IF NOT EXISTS vector;
-- 向量列(与 MySQL 9.x 语义等价)
ALTER TABLE document_chunk ADD COLUMN embedding vector(1536);
-- HNSW 索引(最快的 ANN 算法)
CREATE INDEX ON document_chunk USING hnsw (embedding vector_cosine_ops);
-- 相似度查询
SELECT id, chunk_text, embedding <=> $1 AS distance
FROM document_chunk
ORDER BY distance LIMIT 5;<!-- Spring Boot 切换 PostgreSQL 只改驱动 -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.7.3</version>
</dependency># application.yml 只需改这两行
spring.datasource.url: jdbc:postgresql://postgres:5432/shopdb
spring.jpa.properties.hibernate.dialect: org.hibernate.dialect.PostgreSQLDialect十六、常见问题速查
"亡羊补牢,未为迟也。"——《战国策》
Q1:连接数耗尽 Too many connections
-- 诊断
SHOW STATUS LIKE 'Threads_connected';
SHOW PROCESSLIST;
-- 临时缓解
SET GLOBAL max_connections = 1000;# 根治:合理配置 HikariCP,总连接 = 实例数 × pool-size < max_connections
hikari:
maximum-pool-size: 20 # 每个 Spring Boot 实例
connection-timeout: 5000Q2:慢查询定位
-- 找 TOP 慢 SQL
SELECT query_time, sql_text FROM mysql.slow_log
ORDER BY query_time DESC LIMIT 10;
-- 分析执行计划(重点看 type=ALL 说明全表扫描)
EXPLAIN ANALYZE SELECT * FROM `order` WHERE user_id = 123;
-- Online 加索引(不锁表)
ALTER TABLE `order` ADD INDEX idx_user_status (user_id, status);Q3:InnoDB 死锁频繁
-- 查看最近死锁
SHOW ENGINE INNODB STATUS\G
-- 8.0+ 跳过锁定行,高并发抢锁利器
SELECT id FROM product WHERE stock > 0
FOR UPDATE SKIP LOCKED LIMIT 1;Q4:主从复制延迟大
SHOW SLAVE STATUS\G -- 关注 Seconds_Behind_Master
-- 开启并行复制
SET GLOBAL slave_parallel_workers = 4;
SET GLOBAL slave_parallel_type = 'LOGICAL_CLOCK';Q5:Docker 容器时区不对
environment:
TZ: Asia/Shanghai # docker-compose 设置时区# my.cnf
default-time-zone = +08:00# JDBC URL
?serverTimezone=Asia/Shanghai十七、三条架构洞见
"知行合一。"——王阳明
洞见一:InnoDB 不是万能锁,选对锁策略决定并发上限
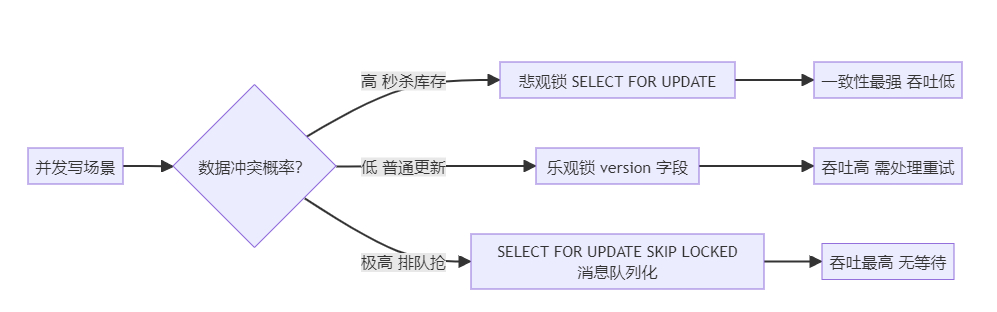
老李教训:大促前统一把秒杀接口改成
SKIP LOCKED+ Redis 令牌桶,QPS 从 500 涨到 5000。
洞见二:JSON 列 + 虚拟列索引,解锁 NoSQL 灵活性与 SQL 性能的结合
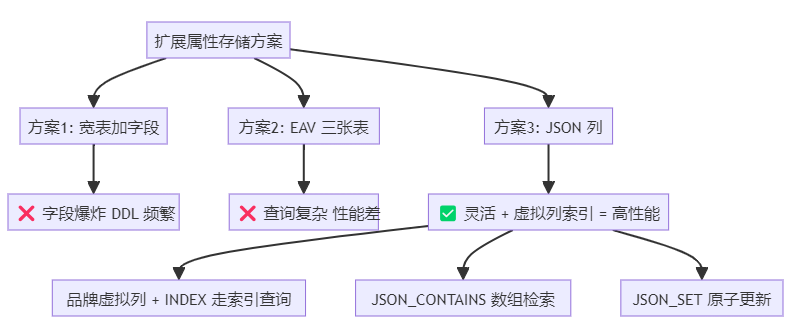
老李实测:为 JSON 字段的品牌路径加虚拟列索引后,
WHERE brand = 'Apple'的查询从 800ms 降到 2ms。
洞见三:MySQL 8.4 是 AI 应用的良好底座,但向量存储要找专业工具
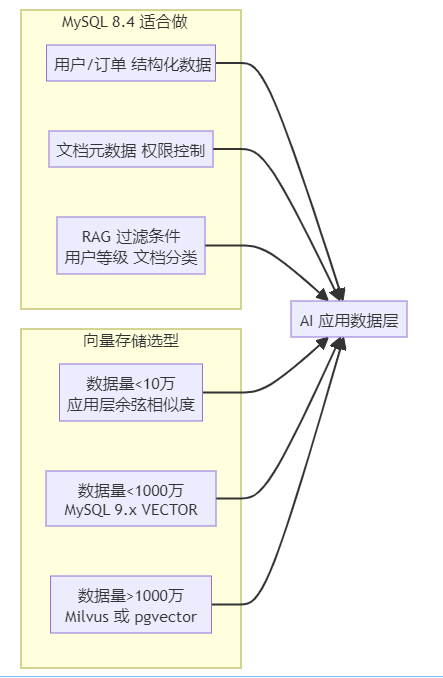
老李判断:如果团队不打算升级到 MySQL 9.x,且向量数据超过百万,直接上 pgvector,两者可以共存,各司其职。
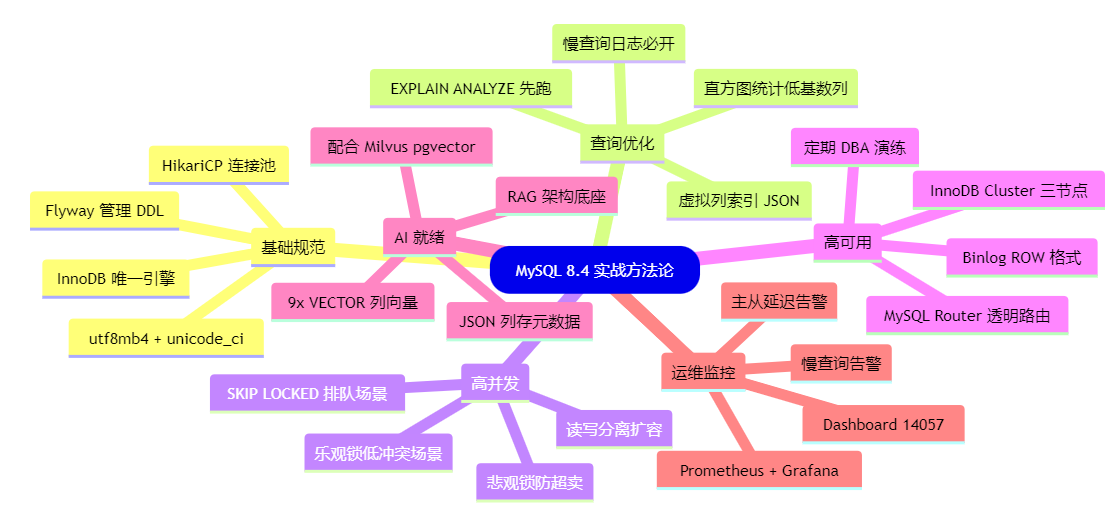
十八、总结方法论速查
特性 | 适用场景 | Spring Boot 核心 API | MySQL 关键语法 |
|---|---|---|---|
ACID 事务 + 行锁 | 库存/支付/下单 |
|
|
JSON 列 + 索引 | SKU 扩展属性 |
|
|
窗口函数 + CTE | 销售报表/排行 |
|
|
全文检索 ngram | 中文搜索 |
|
|
分区表 | 日志/时序数据 |
|
|
Online DDL | 大表加字段 |
|
|
InnoDB Cluster | 服务高可用 | 多数据源 + | MySQL Shell + Router |
VECTOR 列(9.x) | AI RAG |
|
|
参考资料MySQL 8.4 官方文档:https://dev.mysql.com/doc/refman/8.4/en/ MySQL 9.4 Release Notes:https://dev.mysql.com/doc/relnotes/mysql/9.4/en/ Oracle MySQL 许可证说明:https://www.mysql.com/about/legal/licensing/ pgvector:https://github.com/pgvector/pgvector Grafana Dashboard 14057(mysqld_exporter):https://grafana.com/grafana/dashboards/14057 Spring AI:https://spring.io/projects/spring-ai
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号