【Python技术】抓取同花顺的板块概念信息


今天有同学问我怎么获取同花顺的板块概念, 我记得我之前写过文章, 后面发现之前的同花顺概念指数 没怎么更新, 可能不是大家想要的。
抓取同花顺板块概念有2个方案。
1、抓取同花顺的数据。 具体可以参考我之前写的同花顺抓取财务数据那样。
2、直接通过同花顺问财获取板块。
其实分析同花顺板块,你会发现。 同花顺的二级行业,其实是881开头的, 那这里就 “主力流入金额排序,指数代码881开头” 获取所有的板块,
然后根据板块去抓取对应板块的个股。
还有一种思路, 直接问财 问 A股,同花顺二级行业,把全A市场5000多个股全部抓取包括它的同花顺二级分类,进行分组处理。
题外话:
之前写了不少akshare关于东方财富的文章, 自从东方财富频繁封禁以后,之前的功能慢慢用其他功能替换。
如果你用windows,关于量化分析,推荐直接使用QMT数据源。而我自己平时用MAC居多,一些功能还是用同花顺问财临时替代吧。
最后附上完整代码,需要的自取。 备注:如果发现格式有多余的特殊字符,用普通浏览器打开复制应该没问题
import streamlit as st
import pywencai
import requests
import json
import pandas as pd
# 启用Streamlit缓存
@st.cache_data(ttl=3600) # 缓存1小时
def get_concept_index():
"""获取概念指数数据并缓存"""
return pywencai.get(query="主力流入金额排序,指数代码881开头", query_type="zhishu", sort_order='desc', loop=True)
def app():
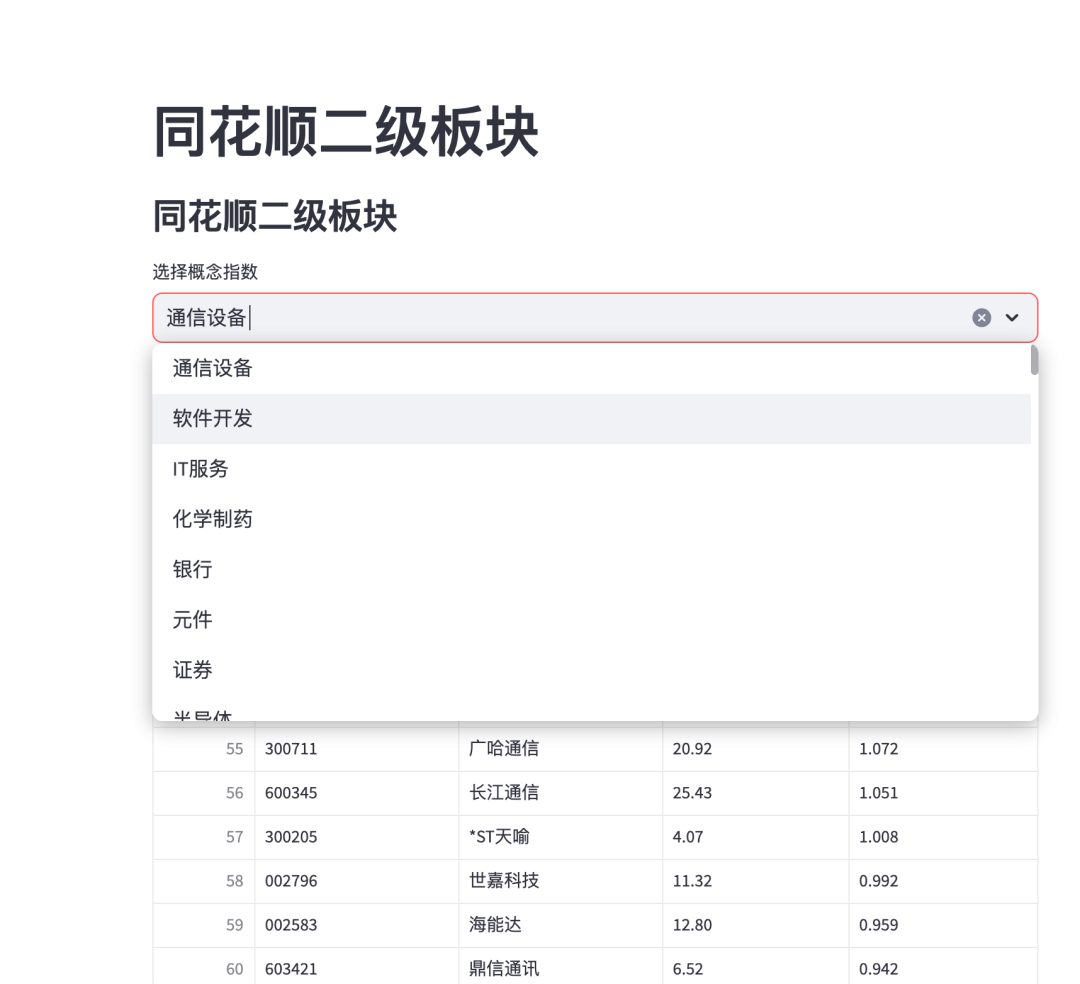
st.title("同花顺二级板块")
# 初始化session状态
if 'selected_code' not in st.session_state:
st.session_state.selected_code = None
# 第一部分:概念指数列表(使用缓存)
with st.container():
st.subheader("同花顺二级板块")
df = get_concept_index()
# 创建下拉选择框[1,4](@ref)
options = list(zip(df['指数简称'], df['code'])) # 生成(显示名称, code)元组列表
selected_code = st.selectbox(
"选择概念指数",
options=options,
index=None, # 默认不选中任何选项[3](@ref)
format_func=lambda x: x[0], # 显示简称[5](@ref)
key='concept_select'
)
# 更新选中状态
st.session_state.selected_code = selected_code[1] if selected_code else None
st.write(f"总共显示 {len(df)} 个概念指数")
# 第二部分:成分股展示(动态更新)
if st.session_state.selected_code:
with st.container():
st.subheader(f"概念指数 {st.session_state.selected_code} 成分股列表")
show_stock_list(st.session_state.selected_code)
def show_stock_list(code):
"""显示成分股的独立组件"""
# 构造请求URL
url = f"https://d.10jqka.com.cn/v2/blockrank/{code}/199112/d1000.js"
headers = {
'Referer': 'http://q.10jqka.com.cn/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
try:
with st.spinner("正在加载成分股..."):
response = requests.get(url, headers=headers, timeout=10)
print(response.text)
if response.status_code == 200:
# 处理JSONP数据
json_str = response.text.split('(', 1)[1].rsplit(')', 1)[0]
data = json.loads(json_str)
# 提取并展示数据
stock_list = data.get('items', [])
if stock_list:
stocks_df = pd.DataFrame(
[(s.get('5', '').zfill(6),
s.get('55', ''),
s.get('8', ''),
s.get('199112', 0))
for s in stock_list],
columns=['股票代码', '股票名称', '最新价', '涨跌幅']
)
st.dataframe(stocks_df, use_container_width=True)
else:
st.warning("未找到相关个股数据")
else:
st.error(f"请求失败,状态码:{response.status_code}")
except Exception as e:
st.error(f"获取数据时发生错误:{str(e)}")
if __name__ == "__main__":
#st.set_page_config(page_title="同花顺概念指数分析", layout="wide")
app()本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号