榨干MLP的剩余价值:大模型“即插即用”的动态记忆改造术

榨干MLP的剩余价值:大模型“即插即用”的动态记忆改造术

赛博解生
发布于 2026-04-22 20:08:51
发布于 2026-04-22 20:08:51
大家好,我是赛博解生酱。在推进大模型业务落地的过程中,固定的流程是先训练,再评估,然后是部署。一旦业务上线,只能等待线上的反馈然后进行修复提升。今天给大家带来一篇关于大模型动态适应能力的前沿架构探索,即就地测试时训练(In-Place Test-Time Training, In-Place TTT),希望对大家理解大模型持续演化的思路带来启发。
在这个信息量爆炸且要求AI高度定制化的时代,让静态大模型去处理真实世界中源源不断的流式任务,常常会让人体会到一种疲惫感。一座伟大的商用建筑之所以能在时代变迁中持续满足不同租户的复杂需求,靠的绝不是一旦需求改变,就把核心承重墙推倒重建;而是依赖于一套极其精细且灵活的原位改造技术(In-Place Retrofitting)——在不破坏大楼主体力学结构的前提下,将原有的普通隔断墙巧妙升级为可重配置的模块化智能空间。
在LLM架构的浩瀚海洋中,也恰好出现了这样一种极具工程美学的范式。它不舍弃大模型既有的注意力机制,不破坏百亿级预训练权重的完整性,而是试图在模型推理阶段,通过巧妙唤醒现有的多层感知机(MLP)层——使其成为如同大楼动态隔断般的“快速权重(Fast Weights)”。这种能够通过“即插即用”的方式,让静态模型在不消耗海量算力重置的前提下,就具备对无限长上下文进行动态记忆与流式演化能力的策略,完美契合了我们在真实场景下“以小博大”的核心诉求。而这篇由字节跳动与北大联合提出的 In-Place TTT 论文,恰好为我们绘制了这样一份精准的架构施工图纸。
基本信息
●标题: In-Place Test-Time Training
●出处: 2026年,由字节跳动(ByteDance Seed)与北京大学的研究团队提出。
●核心内容: 本文提出了一种“就地测试时训练”(In-Place TTT)框架,通过直接将大型语言模型(LLMs)现有的多层感知机(MLP)中的投影矩阵复用为推理期可更新的“快速权重”,并结合专为语言建模设计的前向对齐目标,使现有大模型能够以“即插即用”的方式获得动态推理演化能力,大幅提升了超长上下文任务的性能。
概要
论文的动机与待解决的问题
当前大型语言模型(LLMs)的成功严重依赖于“先训练,后部署”的静态范式。然而,这种固定权重的设计阻碍了模型在推理阶段动态适应持续流入的新信息流。虽然现有的“上下文学习”(In-context learning)通过将历史信息堆叠在输入中来缓解这一问题,但其受限于注意力机制固有的二次复杂度瓶颈,极难扩展到无限流或超长序列。
测试时训练(Test-Time Training, TTT)作为一种替代范式,允许模型在推理时更新少量“快速权重”来动态编码上下文。然而,在当前的LLM生态系统中,TTT的潜力被三大严峻障碍所束缚:
1.架构不兼容:现有TTT方法往往引入非标准的新型注意力/循环层,导致必须舍弃现有庞大的预训练权重,进行极其昂贵的从头重训。
2.计算效率低下:经典的TTT严重依赖于逐个Token的顺序更新,无法充分利用现代AI加速器(GPU/TPU)的并行计算能力。
3.优化目标错配:主流的TTT多采用通用的“自重构”目标(Reconstruction),这与LLM核心的“预测下一个Token(Next-Token Prediction, NTP)”自回归任务并未实现底层逻辑的对齐,限制了模型的最终效能。
论文的核心观点与贡献
无需改变现有大模型的主干架构,通过在推理时将广泛存在的MLP层的最终投影矩阵“就地”转化为快速权重,并采用定制的块状组装与前向预测对齐机制,即可让静态LLM无缝具备强大的动态自我更新能力。
这一观点极具突破性,因为它将过去被视为“推倒重来”的架构替换问题,巧妙地化解为一次轻量级的“即插即用(Drop-in)”增强。它不仅完全保留了数十亿预训练参数中蕴藏的通用知识,还通过一种与语言建模本质完美契合的学习目标,实现了极低的显存开销与极高的并行吞吐量,为大模型迈向类似人类的持续学习(Continual Learning)范式铺平了道路。
核心概念与技术贡献
核心概念的直观解读
●【直观比喻】:假设我们将一个预训练大模型视为一位“拥有海量固定藏书的渊博学者”。当他需要阅读并推理一本10万字的全新侦探小说时,传统的注意力机制要求他必须把读过的每一页都平铺在书桌上(KV Cache),一旦桌子放满(超出上下文窗口),他就无法继续推理。传统的TTT方案则是试图把学者的“大脑神经元”(核心架构)挖出来替换成新的,风险极高。
●【比喻映射】:In-Place TTT 的做法是给这位学者发一本“神奇活页笔记本”。这本笔记本由他原本就拥有的一般记忆区(即MLP层的 矩阵)临时改造而来。学者在阅读当前章节时,可以直接把重要的新鲜线索“就地(In-Place)”写进笔记本(动态更新权重),并且他做笔记的方法不是把原文盲目抄写一遍(通用重构目标),而是有目的性地预测下一段情节的发展(LM对齐目标)。这样一来,旧知识毫发无损,新线索又能被持续压缩吸收,且桌子永远不会被塞满。
关键技术细节实现
本研究在技术层面主要依托对标准Transformer的门控多层感知机(Gated MLP)的巧妙重构与计算流重组。在给定隐藏表示 时,Gated MLP的标准输出为 。研究人员保持输入投影矩阵 和 冻结(作为“慢权重”),唯独将输出投影矩阵 视作在测试时可被实时微调的“快权重(Fast Weights)”。为配合这一架构,论文使用一维卷积操作提取未来Token的嵌入向量,构建出专属于自回归任务的目标变量 ,进而驱动单步梯度下降完成参数的流式更新。
论文的主要贡献点分析
1.架构创新(In-Place 重用机制):提出了将传统MLP块的输出投影层直接转化为测试时训练的快权重,彻底消除了过往TTT方法带来的“架构不兼容”与“从头重训高成本”壁垒。
2.目标对齐(LM-Aligned Objective的设计):彻底摒弃了主流的“自相似重构”目标,首创性地提出了一种融入未来Token信息的定制化目标函数,并在数学期望层面上严谨证明了该目标对提高下一个Token预测概率的绝对优势。
3.计算革新(兼容上下文并行的组块更新):摆脱了传统TTT严苛的逐Token递归更新限制,设计出了可支持极大尺寸(如 或 )的分块更新(Chunk-wise update)算法,使其完美适配现代GPU的并行机制,且通过因果填充(Causal padding)保证了推理的严格因果性。
4.工程验证与性能跃升:实验证明,该方法作为无缝增强插件,仅需经过短期的增量训练,即可将Qwen3-4B等模型的有效上下文长度从32k拔高至128k以上;同时在从零预训练赛道上,全面碾压了包括SWA、GLA及现有TTT变体在内的强基线模型。
技术细节与实验验证
方法流程与理论证明(In-Place TTT 核心机制)
相关背景与整体框架:
传统的测试时训练(TTT)通常旨在“替换”Transformer中的自注意力机制,这导致必须引入新的网络层并进行昂贵的从头预训练。本论文放弃了这一高风险路径,转而构建了一个“即插即用(Drop-in)”的重用框架。其核心思想是:将Transformer网络中广泛存在的门控多层感知机(Gated MLP)的“输出投影矩阵”原位(In-Place)剥离出来,在推理阶段将其视作可被动态优化的“快速权重(Fast Weights)”。
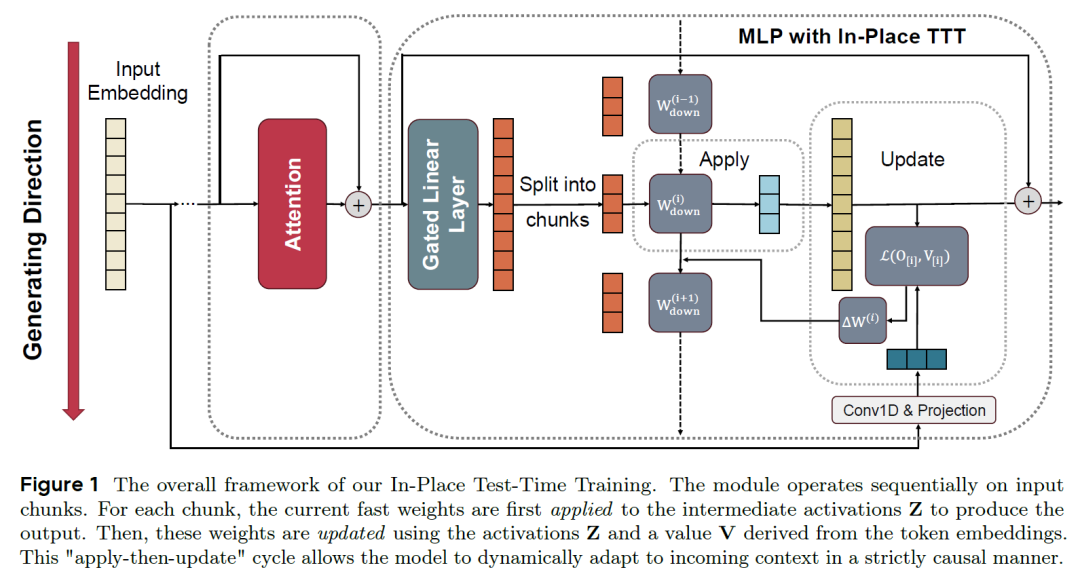
图一:In-Place TTT框架结构图。
详细步骤(数据流向与参数更新的完整生命周期):
1. 问题形式化与架构“就地”改造(In-Place Repurposing)
●基础架构: 在标准的Gated MLP中,给定输入隐藏层表示 ,其输出计算公式为:。其中 为激活函数, 为逐元素乘法。
●角色重分配: 框架保持输入投影 和门控投影 彻底冻结(作为慢权重),同时将中间激活值定义为 。此时,输出公式可简写为 。
●改造核心: 唯独将最终投影矩阵 视作“快速权重”。在推理时, 将根据上下文的输入实时发生改变。
2. 组块化数据切分(Chunk-wise Partitioning)
为了打破传统TTT逐Token更新导致的计算低效瓶颈,模型采用大尺寸切块策略。
●操作: 将当前序列的中间激活值 、目标值 和输出 按照大小为 (如 )进行非重叠切片。
●定义: 第 个块的激活值记为 ,其对应的更新前权重记为 ,初始权重 等于预训练权重。
3. 生成“语言模型对齐”的预测目标(LM-Aligned Objective)
传统TTT使用当前Token自身作为重构目标(死记硬背),本文则利用未来Token构建目标(预测未来)。
●目标构造: 对于每个块,从最底层的Token嵌入(Token Embeddings) 出发,计算目标变量:。
●组件解析: 是一维因果卷积(核大小通常设为5),用于提取当前词及之前词的时序特征; 是一个可学习的线性投影矩阵。
●因果隔离: 为了保证自回归生成的严格因果性,卷积操作必须进行因果填充(Causal padding),绝对禁止第 块的目标 窥探到 块之后的任何未来信息。
4. 基于上下文并行(CP)的极速计算流
这部分是实现高吞吐量的工程核心。基于简单的相似度损失函数 ,本文在数学上将其化简为了纯线性的赫布学习(Hebbian-like)更新规则,从而解锁了并行计算。
算法的具体并行执行逻辑如下:
●并行计算增量(Compute Deltas): 针对所有块 并行计算该块独立产生的参数更新量:。
●前缀和聚合(Prefix Sum): 利用现代GPU极速的前缀和算法,计算到达第 块之前的累积更新量:。
●并行应用与输出(Apply & Output): 并行计算每个块生效的实际快速权重:(其中 为学习率),随后立即计算该块的输出:。
●注:为了防止无限长文本导致权重数值爆炸,在计算出 时,若其F范数超过阈值 (设为1e-5),则会进行归一化截断。
5. 核心定理推导(Theorem 1:为什么对齐目标一定有效?)
为在理论上锤实上述架构的合理性,论文基于“归纳头(Induction Head)”任务进行了严谨的数学证明。
●关键假设引入: 1) 词嵌入近似正交假设:不同Token的嵌入向量内积接近于0(绝对值 ),且自身模长平方 ;2) 键查询对齐假设:在查询位置 ,其隐藏层激活值 与历史上匹配的Key位置 的激活值 具有正相关性 。
●核心定理推导: 当使用本文提出的LM-Aligned目标(即目标包含下一个Token )时,模型经历一次快速权重更新后,预测出正确Token 的Logit(即 )的期望增量满足下界:
且对其他错误Token词汇的Logit影响趋近于极小值 ()。
●反向论证: 若采用传统的“重构当前词”作为目标,正确预测词的Logit期望增量为极小值(),即在数学原理上对语言模型的预测毫无裨益。
结论:
通过严格的重组、块状化、因果卷积特征对齐以及前缀和并行加速,In-Place TTT将原本静态的MLP改造为一个高效的、严格满足因果律的、具备数学理论增益保证的动态键值记忆库。
实验验证与应用流程
目标:
本实验体系全方位验证了三种场景:1)In-Place TTT作为“外挂插件”直接武装现有开源大模型的效果;2)从网络初始化阶段(从头预训练)开始内置此机制与同领域SOTA架构的硬碰硬对比;3)模型核心超参数(块大小、状态规模等)的敏感性与资源消耗消融分析。
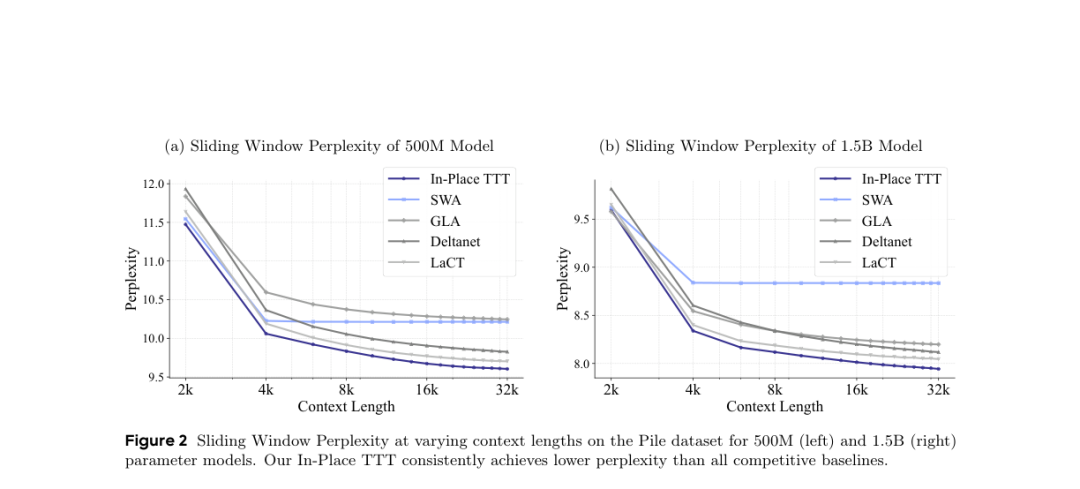
图二:在Pile数据集上不同上下文长度的滑动窗口困惑度。In-Place TTT在所有竞争基线中始终保持较低的困惑度。
验证模块一:预训练模型的“即插即用”长文本能力飞跃
●基线与环境设置: 选取主流开源基座模型 Qwen3-4B-Base、LLaMA-3.1-8B 和 Qwen3-14B-Base。
●初始化技巧(关键细节): 刚插入模块时,如果不加干预会瞬间摧毁原模型的预训练分布。论文采用巧妙的零化策略:将 初始化为0, 初始化为极小的稀疏对角矩阵。这使得初始更新量 ,模型最初表现完全等同于其原始形态,随后在增量训练中缓慢“觉醒”动态适应能力。
●两阶段增量训练流: 1. 阶段一:输入32k上下文长度的数据(约20B Tokens),学习率极低(5e-6),激活TTT模块。
ii.阶段二:引入YaRN旋转位置编码扩展技术,将序列飙升至128k长度,继续训练约15B Tokens。
●结果分析: 经 RULER 基准测试(涵盖4k至256k长度),以Qwen3-4B为例,其在超长文本(64k及以上)表现出质的飞跃(64k准确率从74.3%飙升至78.7%,在128k下达到77.0%),且在面对从未训练过的256k长度时,展现出了卓越的“外推(Extrapolation)”泛化能力。
验证模块二:从零预训练(Pre-training from scratch)的全方位降维打击
●实验设置: 在500M和1.5B规模上,使用滑动窗口注意力(SWA)为骨干,对比纯SWA、GLA(门控线性注意力)、DeltaNet和LaCT(大块TTT的前沿变体)。所有模型在32k长度的数据上进行预训练。随后扩展至4B参数量级,训练高达120B Tokens。
●评价指标: 采用“滑动窗口困惑度(Sliding Window Perplexity)”以及五大常识推理集(HellaSwag, ARC, MMLU, PIQA等)。
●结果验证: 在困惑度图表中,In-Place TTT的验证损失曲线全方位包裹并压制了所有强劲基线。在4B规模的常识推理中,全注意力模型+In-Place TTT的组合在长文本 RULER-16k 上的得分甚至从纯全注意力的6.58分暴涨至19.99分,证明了其在不损失短逻辑推理的情况下,极大拔高了长序列信息的压缩提取率。
验证模块三:核心组件设计的消融与效率剖析(Ablation Study)
●状态规模(State Size)分析: 通过调整带有TTT更新能力的MLP层的占比(如0.5x, 1x, 4x),结果呈严格单调递增,即赋予模型越多可更新的 参数层,其长文本得分越高,验证了“MLP层本身就是优质的隐性键值存储区”这一假说。
●组块大小(Chunk Size)权衡: 测试 。数据表明,极端的颗粒度(太小导致视野受限,太大导致更新迟缓)均非最优, 与 取得了最佳的性能权衡,而 因极大地释放了GPU硬件级并发,被选为最终推荐配置。
●目标组件剥离(Objective Decoupling): 去除 或 。结果显示:去除卷积(失去对未来Token的提前洞察)会导致长文本(如 RULER-16k)能力直接断崖式归零;而去除投影矩阵则削弱了短文本理解能力,完美呼应了 Theorem 1 的理论推演。
●工程效率证明: 作者记录了不同配置下的 Prefill TPS(预填充吞吐量)与 Peak Memory(峰值显存)。直观数据显示,无论是在8k还是高达128k的上下文中,附加了In-Place TTT的模型其显存消耗和处理速度与纯净基线模型几乎紧密贴合,彻底击碎了“动态参数更新必遭致严重计算延时”的工程偏见。
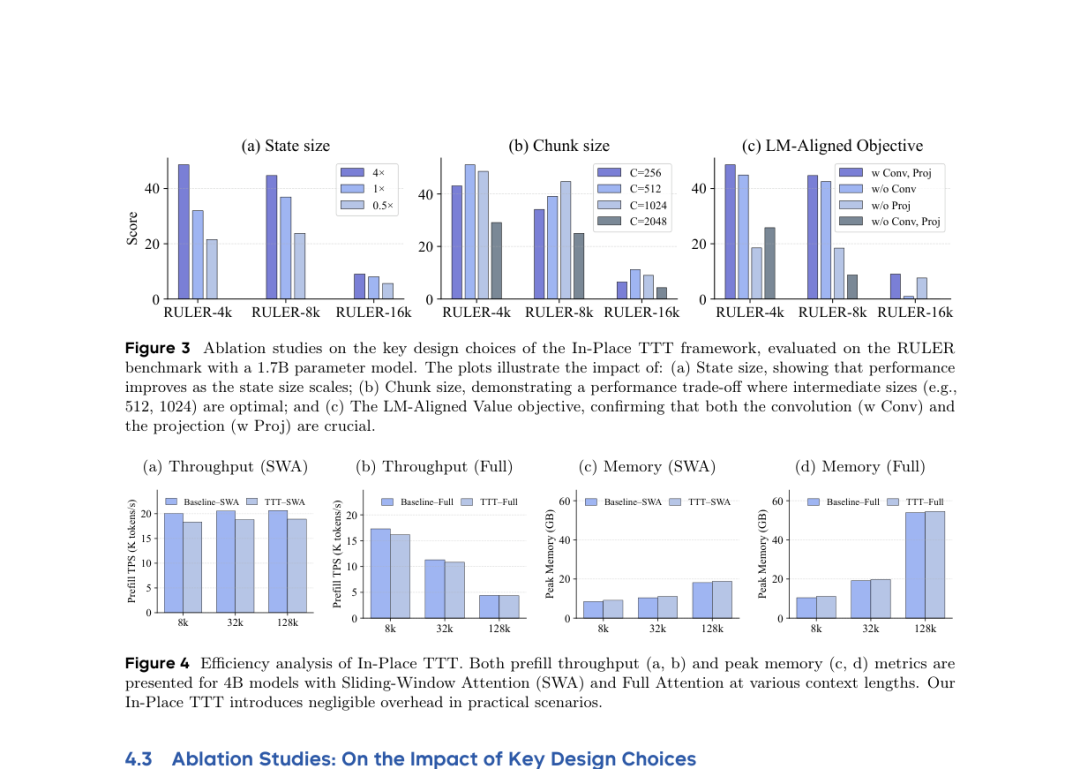
图三:原图3:In-Place TTT框架关键设计选择的消融研究,在1.7B参数模型的RULER基准上评估。(a) 状态规模的影响;(b) 组块大小的权衡;(c) LM对齐目标各组件的必要性。
原图4:In-Place TTT的效率分析。展示了4B模型在不同上下文长度下的预填充吞吐量(a,b)和峰值内存(c,d),包含SWA和Full Attention两种配置。In-Place TTT在实际场景中引入的开销可以忽略不计。
结论:
实验充分证明,对于预训练模型,In-Place TTT能在保持短文本能力不降的情况下,实现128k甚至256k长文本解析能力的巨大飞跃(如Qwen3-4B在RULER-64k上从74.3%飙升至78.7%)。从头预训练时,其在语言困惑度与多维度常识推理中均确立了对现有基线的压倒性优势,同时计算与显存开销仅出现极轻微的上涨,兼顾了极致性能与工程可用性。
总结与评估
研究的优势与创新亮点
●理论层面:文章展现出了极高的原创性和严密的逻辑自洽。其核心贡献Theorem 1通过将大模型内部隐层的动力学更新与特征向量正交假说结合,漂亮地从数学本质上驳斥了在语言模型中盲目套用计算机视觉“重构(Reconstruction)”目标的行为,为后续所有语言模型的TTT优化指明了“必须包含未来前向预测信息”的理论公理。
●方法层面:“化整为零”的思路堪称惊艳。避开了创造复杂新架构的内卷陷阱,敏锐地察觉到Transformer中占比最高且常被忽视的MLP参数天然具备“读写键值对内存”的属性。结合 生成目标与 的粗颗粒度组块并行扫描(Prefix sum),彻底扫清了阻碍TTT落地到千亿规模模型的算力壁垒,属于工程与算法极致融合的典范设计。
研究的局限与改进方向
●局限性分析:
i.更新深度的固化:当前框架中的更新机制被简化为单步随机梯度下降(SGD),这意味着模型对于复杂新概念的学习吸收可能不够彻底,单次梯度步进可能无法达到最优的特征融合。
ii.固定组块的边缘效应:采用固定的 Chunk-size(如 )虽然利好硬件并行,但生硬的切分可能割裂自然语言的逻辑句法边界。
iii.计算外推的潜在崩塌:虽然在256k长度上展现了优越性,但由于更新本身依赖不断累加的矩阵权重 ,若缺乏强大的遗忘或正则化机制(附录中虽提及了人为设定的范数截断规范化 ),在遭遇百万级甚至更长的无限数据流时,依然存在数值溢出或特征灾难性遗忘的风险。
●改进路径建议:
i.可引入自适应语义切块(Semantic-aware Chunking)机制,依据注意力显著度或标点符号动态划分并行块,而非机械的定长切分。
ii.利用更加高级的低秩优化器(如类Adam的动量记忆机制)替代当前的简单单步相似度更新,强化快速权重的收敛深度。
iii.探索主动的“遗忘衰减因子(Decay Factor)”,让过往的陈旧信息能够以指数速率从 中褪去,以适应无限长度的终身学习。
实验设计的有效性与结论支撑度
●实验设计的合理性:极其扎实且兼顾全面性。作者没有仅仅局限于“从头训”的理论模型(这是许多架构创新论文的通病),而是通过在极受欢迎的开源系列(Qwen 4B/14B、Llama 3.1 8B)上执行后续增量微调,硬碰硬地展示了其在工业界最看重的“即插即用”落地价值。
●结论的可信度:消融实验极度客观。对关键因子(State Size, Chunk Size,以及目标的Conv/Proj组件脱落)进行了详尽的解耦分析,无可辩驳地支撑了“LM对齐”中任意一个组件缺失都会导致长程推理断崖式下跌的论点。此外,作者诚实地报告了吞吐量与显存的细微代价,排除了选择性呈现结果的嫌疑。
领域贡献与后续研究启发
●实质性贡献:这不仅是一篇单纯提升跑分指标的工程论文,它代表了静态巨模型向动态自适应模型跨越过程中的一座关键里程碑,打破了“Test-Time Training 必须和注意力机制做架构替换”的思维定势,极大地降低了前沿实验室与工业界继续在此方向深耕的技术门槛。
●长期影响的预判:随着模型能力向Agent化和长程流式交互演进,未来的基座大模型极有可能将这种“慢权重(负责全局常识)+快权重(负责当前长文本语境实时推演)”的混合推理机制固化为行业标准范式。它也为探索大模型的类人终身学习(Lifelong Learning)打开了一扇无需高昂显存代价的崭新大门。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号