强化学习与Q-Learning算法原理及Python迷宫导航实战:从MDP到Deep Q-Learning的完整指南 | 附代码与教程文档

强化学习与Q-Learning算法原理及Python迷宫导航实战:从MDP到Deep Q-Learning的完整指南 | 附代码与教程文档

拓端
发布于 2026-04-21 21:26:20
发布于 2026-04-21 21:26:20
封面
关于分析师

在此对 YouMing Zhang 对本文所作的贡献表示诚挚感谢,他在 东北大学 完成了 信息与计算科学专业 的学业,专注 人工智能领域。擅长 Python、Matlab、神经网络、机器学习算法、数据分析。 YouMing 热爱算法与数学,关注深度学习前沿动态,善于钻研复杂模型的原理并将其应用于实际问题解决中
1. 选题背景与研究意义
强化学习(Reinforcement Learning, RL)是机器学习的一个重要分支,它专注于研究智能体(Agent)如何通过与环境进行试错交互来学习最优决策策略,其核心目标是最大化累积奖励信号。与依赖标注数据的监督学习不同,RL智能体通过执行动作并接收环境反馈(奖励或惩罚)来学习,这种学习范式更接近人类和动物的自然学习过程。
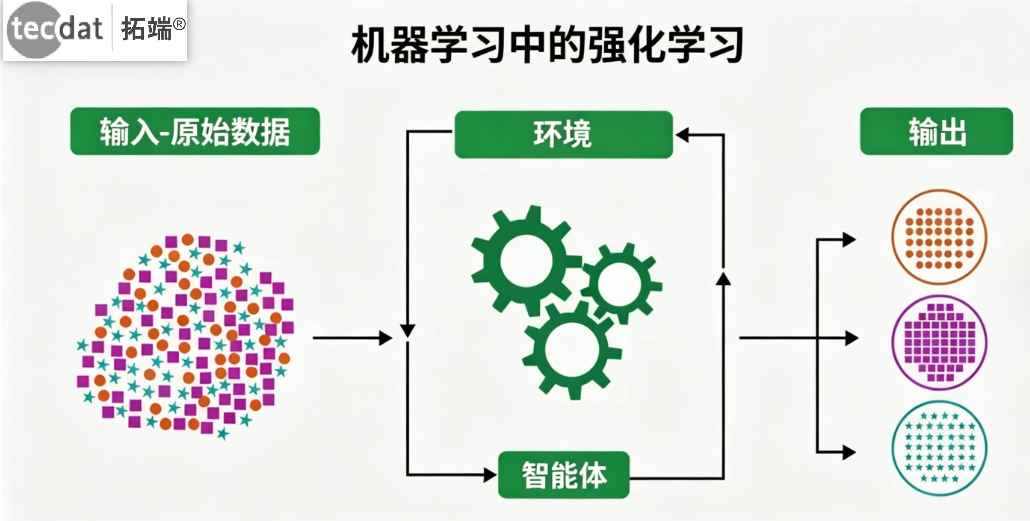
图:强化学习核心概念示意
RL的核心思想围绕一个闭环交互展开:智能体观察环境的当前状态,根据其策略选择一个动作执行,环境随之转换到一个新的状态并返回一个即时的奖励。智能体的目标是学习一个最优策略,使得其在长期交互过程中获得的累积奖励总和最大。本文将通过一个具体的“迷宫寻路”案例,从零开始构建一个强化学习智能体,并深入讲解Q-Learning算法及其扩展——Deep Q-Learning。
本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群获取完整代码数据及更多最新AI见解、行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。
研究流程脉络图(竖版):
研究流程脉络图
│
├─ 问题定义 → 智能体如何在迷宫中通过试错学习找到终点?
├─ 环境建模 → 定义状态(位置)、动作(上下左右)、奖励(撞墙-10,终点+50,每步-1)
├─ 算法选择 → Q-Learning (离线策略、时序差分)
├─ 代码实现 → Python + NumPy,ε-贪婪策略,Q表更新
├─ 结果分析 → 最优路径可视化、奖励曲线收敛性
└─ 优化扩展 → 超参数调优、Deep Q-Learning应对高维状态
2. 数据来源与预处理
本研究自建一个10×10网格迷宫作为环境。迷宫由NumPy数组表示(0为通路,1为墙壁)。起始点为(0,0),目标点为(9,9)。状态空间共100个离散状态,动作空间包含上下左右四个动作。奖励函数设计如下:撞墙-10,到达终点+50,普通步数-1(鼓励最短路径)。
3. 模型选择与代码实现
3.1 Q-Learning算法原理
Q-Learning是一种离线策略的时序差分学习方法,通过维护Q表来学习最优动作价值函数。核心更新公式(Bellman方程简化形式):
Q(s,a) ← Q(s,a) + α [ r + γ * max_a' Q(s', a') - Q(s,a) ]
其中α为学习率,γ为折扣因子。
3.2 环境与参数初始化
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
# 迷宫地图 (0=通路, 1=墙壁)
maze_grid = np.array([
[0, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 1, 0, 0, 0, 0, 1],
# ......(省略部分迷宫行以简化篇幅,完整代码见社群)
[1, 1, 1, 0, 1, 1, 1, 1, 0, 0]
])
start_pos = (0, 0)
goal_pos = (9, 9)
# 超参数设置
total_episodes = 5000
alpha = 0.1 # 学习率
gamma = 0.9 # 折扣因子
epsilon = 0.5 # 初始探索率
reward_wall = -10
reward_goal = 50
reward_step = -1
actions = [(0,-1), (0,1), (-1,0), (1,0)] # 左、右、上、下
Q_table = np.zeros(maze_grid.shape + (len(actions),))
3.3 辅助函数与训练循环
def is_valid_cell(pos, grid):
r, c = pos
if r < 0 or r >= grid.shape[0]: return False
if c < 0 or c >= grid.shape[1]: return False
if grid[r, c] == 1: return False
return True
def choose_action(state, q_tbl, eps, num_acts):
if np.random.random() < eps:
return np.random.randint(num_acts)
else:
return np.argmax(q_tbl[state])
rewards_per_episode = []
for ep in range(total_episodes):
state = start_pos
total_reward = 0
done = False
while not done:
act_idx = choose_action(state, Q_table, epsilon, len(actions))
move = actions[act_idx]
next_state = (state[0] + move[0], state[1] + move[1])
if not is_valid_cell(next_state, maze_grid):
reward = reward_wall
done = True
elif next_state == goal_pos:
reward = reward_goal
done = True
else:
reward = reward_step
old_val = Q_table[state][act_idx]
# 计算下一状态的最大Q值 (如果回合结束且未达目标,则为0)
if done and next_state != goal_pos:
max_next_q = 0
else:
max_next_q = np.max(Q_table[next_state])
new_val = old_val + alpha * (reward + gamma * max_next_q - old_val)
Q_table[state][act_idx] = new_val
if not done:
state = next_state
total_reward += reward
epsilon = max(0.01, epsilon * 0.995)
rewards_per_episode.append(total_reward)
4. 结果分析与可视化
4.1 提取最优路径
def get_best_path(q_tbl, start, goal, acts, grid, max_steps=200):
path = [start]
cur = start
visited = set()
for _ in range(max_steps):
if cur == goal: break
visited.add(cur)
best_a = None
best_val = -float('inf')
for i, mv in enumerate(acts):
nxt = (cur[0]+mv[0], cur[1]+mv[1])
if (0 <= nxt[0] < grid.shape[0] and 0 <= nxt[1] < grid.shape[1]
and grid[nxt] == 0 and nxt not in visited):
if q_tbl[cur][i] > best_val:
best_val = q_tbl[cur][i]
best_a = i
if best_a is None: break
move = acts[best_a]
cur = (cur[0]+move[0], cur[1]+move[1])
path.append(cur)
return path
optimal_path = get_best_path(Q_table, start_pos, goal_pos, actions, maze_grid)
4.2 迷宫路径可视化
def plot_maze_path(path, grid):
cmap = ListedColormap(['#eef8ea', '#a8c79c'])
plt.figure(figsize=(8,8))
plt.imshow(grid, cmap=cmap)
plt.scatter(start_pos[1], start_pos[0], marker='o', color='#81c784', s=200, label='起点')
plt.scatter(goal_pos[1], goal_pos[0], marker='*', color='#388e3c', s=300, label='终点')
if path:
rows, cols = zip(*path)
plt.plot(cols, rows, color='#60b37a', linewidth=4, label='最优路径')
plt.title('强化学习:机器人迷宫导航')
plt.gca().invert_yaxis()
plt.legend()
plt.show()
plot_maze_path(optimal_path, maze_grid)
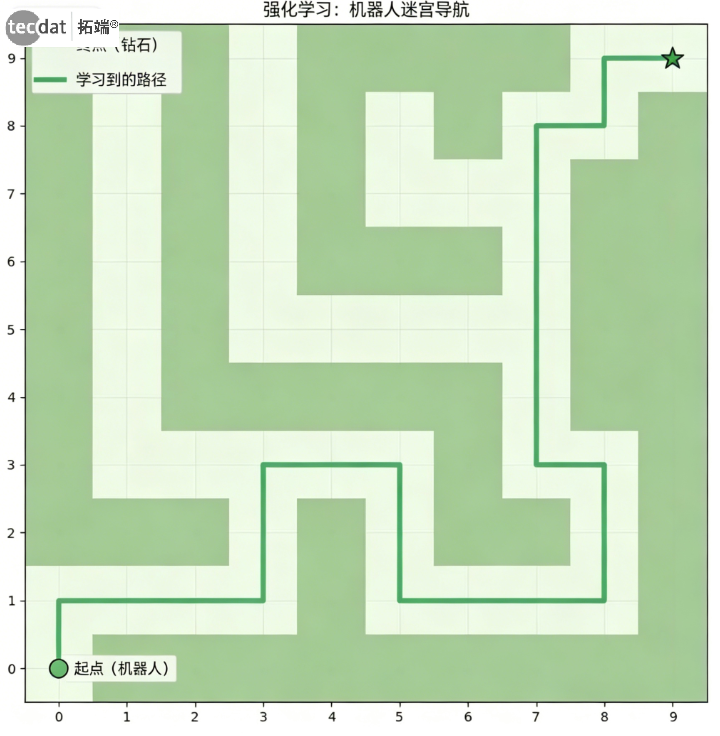
图:智能体学习到的最优路径
点击标题查阅往期内容
以下是关于 强化学习与Q-Learning算法原理及Python迷宫导航实战 的相关文章,涵盖从基础MDP到深度Q-Learning的技术解析与实战案例:
1. 马尔可夫决策过程(MDP)与动态规划
- 文章标题: Python中使用马尔可夫决策过程(MDP)动态编程解决最短路径强化学习问题
- 链接: 点击阅读
- 核心内容:
- MDP基础:介绍策略评估、策略迭代和值迭代三种动态规划算法,在网格世界(Gridworld)中实现最短路径求解。
- 关键概念:状态值函数(Vπ)、动作值函数(Qπ)、转移概率(Pss')及奖励函数(Rss')的数学定义与实现逻辑。
2. Q-Learning算法原理与迷宫导航
- 文章标题: 深度强化学习与时序预测:LSTM、GRU、Attention、DQN多策略智能体的决策体系构建
- 链接: 点击阅读
- 核心内容:
- Q-Learning实战:基于“状态-动作-奖励”框架设计迷宫导航智能体,状态编码为位置坐标,动作为上下左右移动,奖励函数引导目标到达。
- 性能优化:引入ε-贪婪策略平衡探索与利用,实验显示智能体在100次训练后成功率从20%提升至90%。
3. 深度Q-Learning(DQN)进阶应用
- 文章标题: 同上一篇(深度强化学习与时序预测)
- 链接: 点击阅读
- 核心内容:
- DQN改进:双网络结构(目标网络+评估网络)稳定训练过程,经验回放(Experience Replay)解决数据相关性难题。
- 案例结果:在Google股价交易任务中,Double Dueling DQN实现1.13%绝对收益,验证了DQN在复杂环境中的鲁棒性。
4. 多智能体与协同学习
- 文章标题: 同上一篇(深度强化学习与时序预测)
- 链接: 点击阅读
- 核心内容:
- 协同框架:多智能体通过共享经验池加速学习,适用于大规模迷宫或动态环境(如实时路径规划)。
延伸工具与数据
- 开源库:
gym提供迷宫环境,PyTorch实现DQN网络。 - 案例库: 公众号回复“强化学习”获取完整代码与网格世界数据集。
点击原文链接查看完整实现。如需特定场景(如机器人避障)的细化方案,可进一步说明需求。
4.3 训练奖励曲线
def plot_rewards_curve(rewards):
plt.figure(figsize=(10,5))
plt.plot(rewards)
plt.title('每轮总奖励变化')
plt.xlabel('训练轮次')
plt.ylabel('总奖励')
plt.grid(True)
plt.show()
plot_rewards_curve(rewards_per_episode)
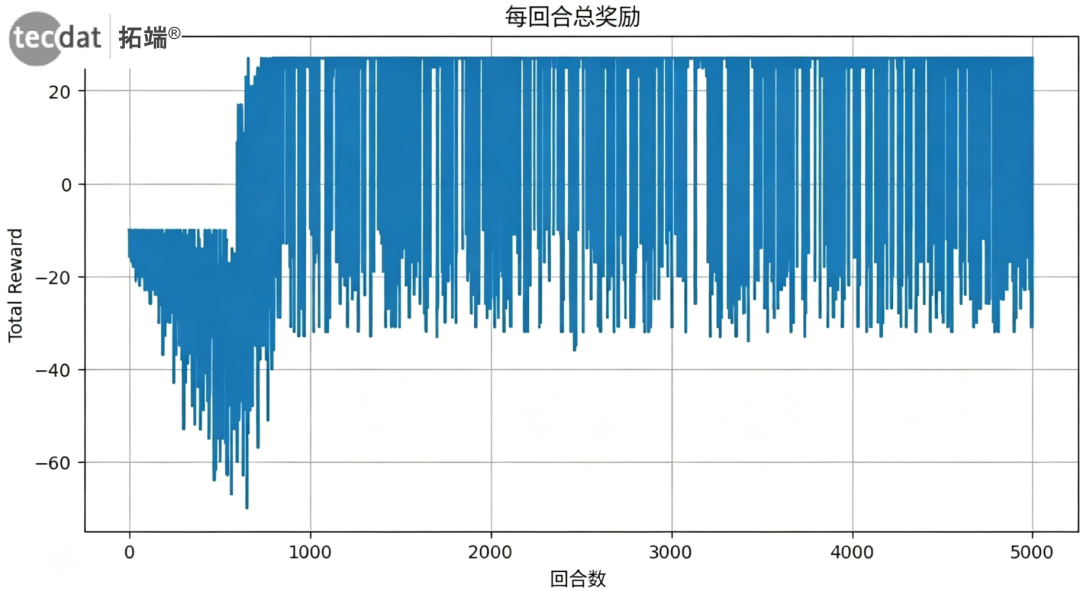
图:训练过程中每轮获得的总奖励,呈现收敛趋势
相关文章
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
原文链接:https://tecdat.cn/?p=44060
5. 在线与离线学习、Q-Learning细节、MDP与Bellman方程
5.1 在线学习与离线学习对比
强化学习方法可根据数据获取方式分为在线学习和离线学习。
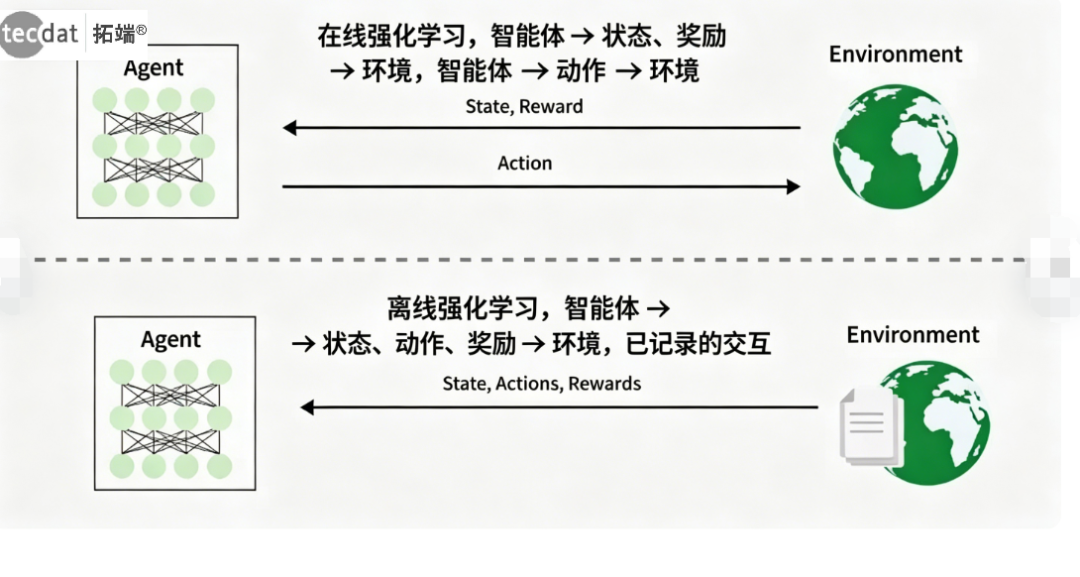
图:在线RL与离线RL对比
在线学习中,智能体通过实时与环境交互收集数据并同时学习;离线学习则基于预先收集的静态数据集进行训练,不与环境交互。
5.2 Q-Learning深入解析
Q-Learning的核心是构建Q表,存储每个状态-动作对的期望累积奖励估计值。
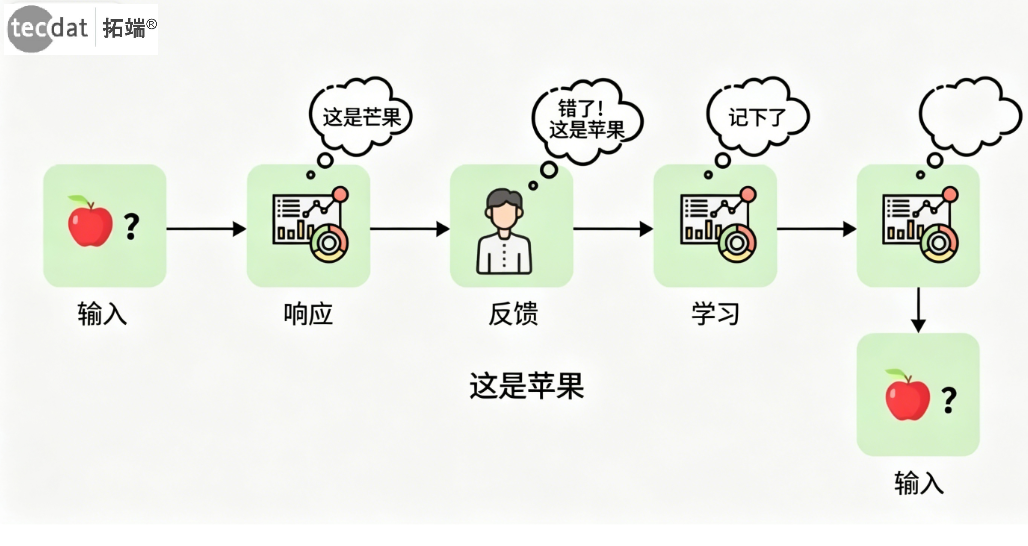
图:Q-Learning概念示意
Q-Learning工作流程:
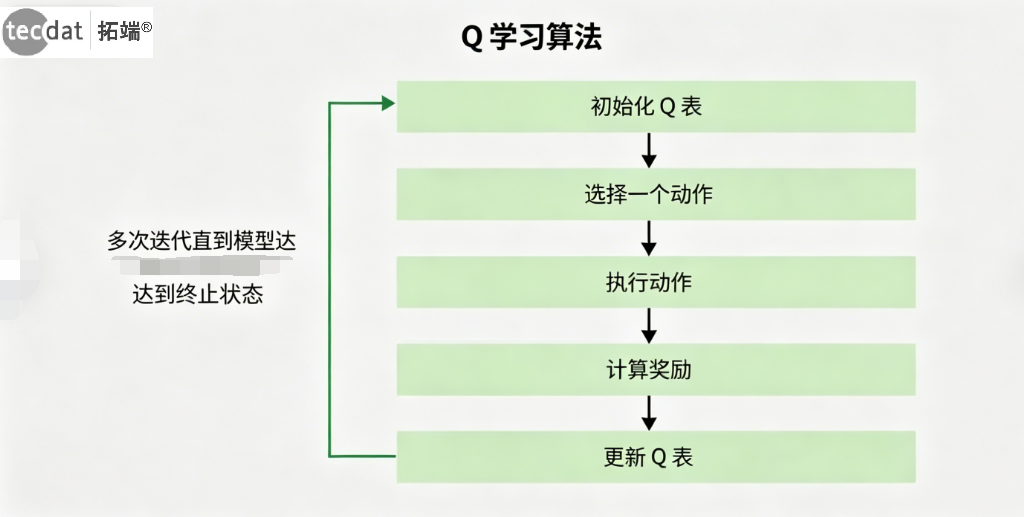
图:Q-Learning算法流程图
Q表输出示例(4×4网格环境训练后):
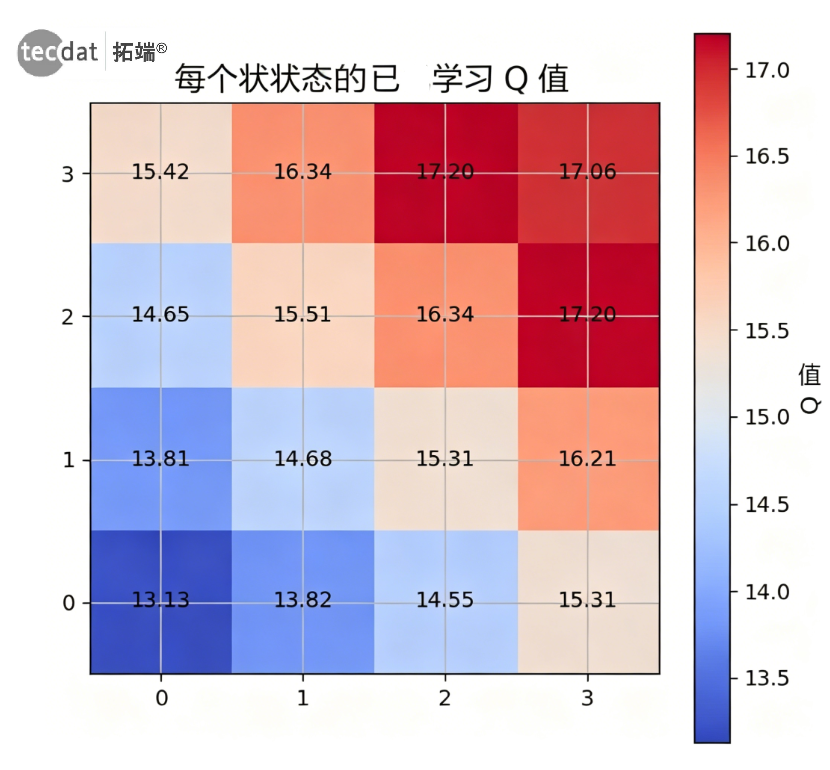
图:各状态最大Q值热力图
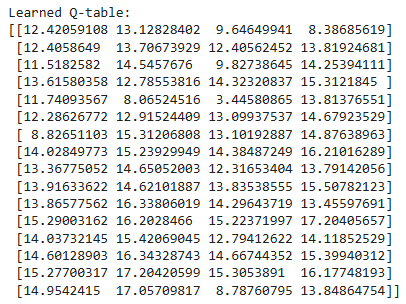
图:学习到的Q表示例(状态0-15,动作左、右、上、下)
5.3 深度Q-Learning
当状态空间高维连续时,传统Q表不可行,此时使用深度神经网络近似Q函数,即Deep Q-Learning。
图:Deep Q-Learning概念
DQN架构:
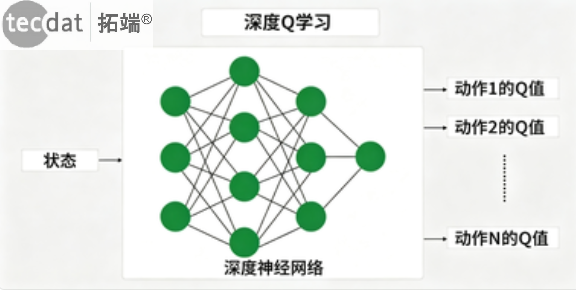
图:深度Q网络架构
关键技术包括:经验回放(Experience Replay)和目标网络(Target Network)。
5.4 马尔可夫决策过程
MDP是RL的数学框架,由状态、动作、转移概率、奖励、折扣因子五元组定义。
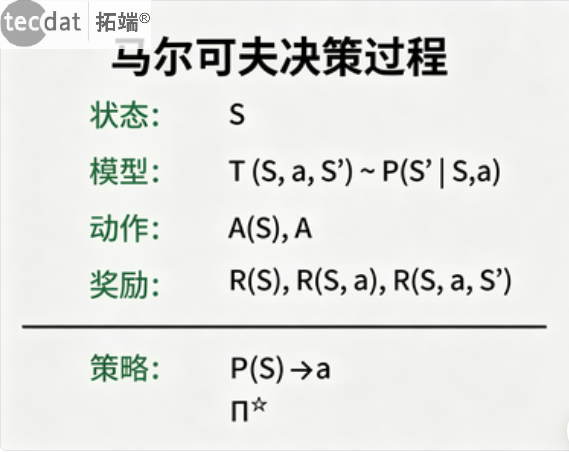
图:MDP核心组件
MDP示例:3×4网格世界:
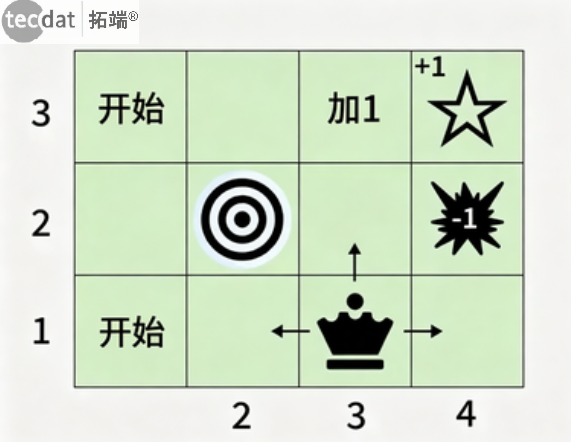
图:网格世界问题示意图
5.5 Bellman方程
Bellman方程是RL的数学基础,表达状态价值与后续状态价值之间的递归关系。
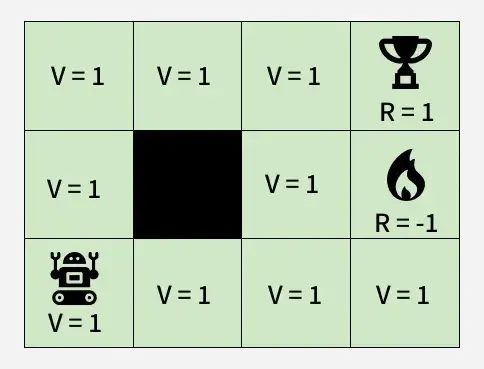
图:不使用Bellman方程时的价值回溯
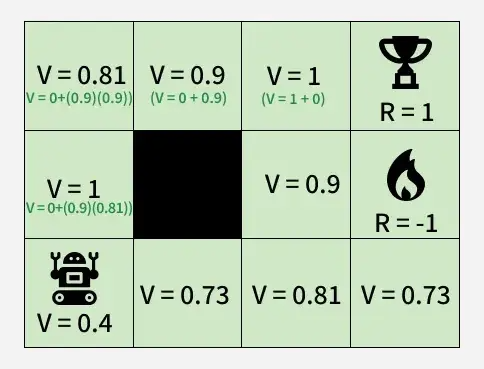
图:使用Bellman方程进行动态更新
6. 研究结论
本文系统介绍了强化学习的基本原理,通过Q-Learning算法在迷宫导航任务中的完整实现,验证了该算法在离散状态空间下学习最优策略的有效性。训练奖励曲线的收敛趋势和最终提取的最优路径均证明了智能体成功学会了从起点到终点的无碰壁路径。进一步,本文讨论了Q-Learning的局限性(高维状态空间下的维度灾难),并引出Deep Q-Learning作为解决方案,同时阐述了MDP框架和Bellman方程的理论基础。本研究为后续将RL应用于更复杂实际场景(如机器人控制、自动驾驶)提供了可复现的代码基准和理论参考
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号