居民健康调查数据|高血压慢性病影响因素识别:Python逻辑回归LR多层感知器MLP预测|附数据代码

居民健康调查数据|高血压慢性病影响因素识别:Python逻辑回归LR多层感知器MLP预测|附数据代码

拓端
发布于 2026-04-21 21:25:04
发布于 2026-04-21 21:25:04
封面
在此对Qipei Dong对本文所作的贡献表示诚挚感谢,他在奥克兰理工大学完成了数据分析专业的硕士学位,专注数据分析、机器学习领域。擅长R语言、Python、SAS,精通统计建模、数据挖掘与预测分析。
随着人口老龄化加剧,高血压已成为我国居民健康的首要威胁之一,传统依赖医生经验的防控模式难以覆盖大规模人群,早期筛查效率低下(点击文末“阅读原文”获取完整智能体、代码、数据、文档)。
引言
机器学习技术凭借强大的数据处理和模式识别能力,为慢性病风险评估提供了全新解决方案。目前多数研究仅聚焦单一模型性能,未明确不同模型在社区筛查与临床诊断等差异化场景的适配性,导致实际应用效果不佳。 本文基于某地区2020-2023年7768名居民的健康调查数据,系统梳理高血压的多维度影响因素,构建逻辑回归与多层感知器神经网络两种预测模型,通过多指标对比明确各自适用场景。研究结果可直接嵌入社区健康管理系统,实现高风险人群自动识别与分层干预,为基层医疗机构提供低成本、高效率的筛查工具。 本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群获取完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。
研究技术路线图
数据采集
↓
数据预处理
↓
影响因素统计分析
↓
双模型构建与训练
↓
多维度性能评估
↓
分场景应用建议
选题背景与研究意义
我国成人高血压患病率已达27.5%,且呈年轻化趋势,每年因高血压导致的心脑血管疾病死亡人数超过200万。早期识别高风险人群并实施干预,可降低30%-50%的发病风险。传统风险评估工具存在可解释性差、计算复杂等问题,难以在基层推广。 本研究通过对比两种主流机器学习模型的性能,提出"逻辑回归初筛+神经网络复核"的分级筛查策略,既保证了大规模筛查的效率,又提高了临床诊断的准确性。研究结果可为公共卫生政策制定提供数据支持,助力慢性病防控从"治疗为主"向"预防为主"转变。
数据来源与预处理
本研究数据来源于某地区居民健康调查数据库,共纳入7768名18岁以上居民,涵盖人口学特征、生活方式、饮食习惯和疾病家族史4大类27个变量。数据分析在Python 3.8环境中完成,依托pandas、numpy和scikit-learn工具库实现。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
相关文章
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
原文链接:https://tecdat.cn/?p=44060
数据预处理流程如下:首先采用IQR方法检测异常值,用对应变量的中位数替换;其次对二分类变量进行0/1编码,多分类变量采用独热编码;最后对连续变量执行Z-score标准化,消除量纲影响。
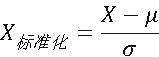
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。 本研究数据无缺失值,整体质量良好。异常值处理结果显示,每周吸烟支数和饮酒量的异常比例较高,分别为19.41%和23.78%,主要与部分居民存在重度吸烟饮酒行为有关。
模型选择与代码实现
本研究选择逻辑回归和多层感知器神经网络两种模型进行对比。逻辑回归具有良好的可解释性和计算效率,适合大规模数据处理;神经网络具有较强的非线性拟合能力,能够捕捉复杂的特征关系。
# 高血压预测模型构建
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import *
class HypertensionRiskPredictor:
def __init__(self):
self.lr_clf = None
self.mlp_clf = None
def split_dataset(self, features, target):
"""按7:3比例分层划分训练集和测试集"""
X_train, X_test, y_train, y_test = train_test_split(
features, target, test_size=0.3, random_state=42, stratify=target
)
return X_train, X_test, y_train, y_test
def train_lr_model(self, X_train, y_train):
"""训练逻辑回归模型"""
self.lr_clf = LogisticRegression(
penalty='l2', C=1.0, max_iter=1000, random_state=42
)
self.lr_clf.fit(X_train, y_train)
return self.lr_clf
# ......(省略神经网络训练、模型评估与可视化关键代码)
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。 将处理后的数据按7:3比例分层划分为训练集和测试集,确保两组的高血压患病率一致。逻辑回归模型采用L2正则化防止过拟合,神经网络模型包含2个隐藏层,分别有50和25个神经元,激活函数使用ReLU。
模型结果对比与解读
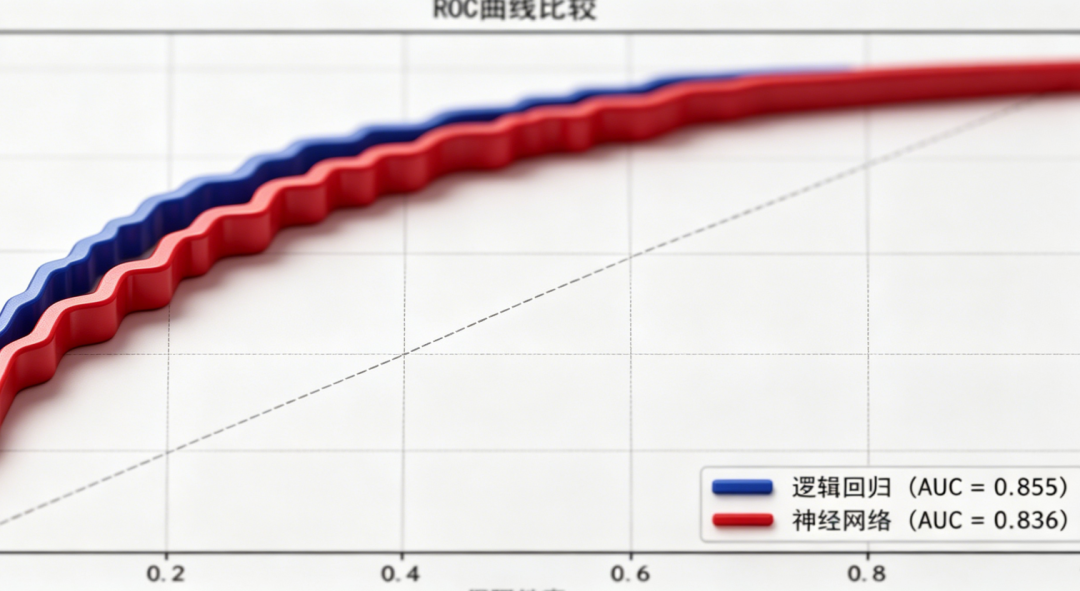
逻辑回归模型在测试集上的AUC为0.8549,准确率为0.7701,召回率为0.7749,能够识别出77.49%的高血压患者。
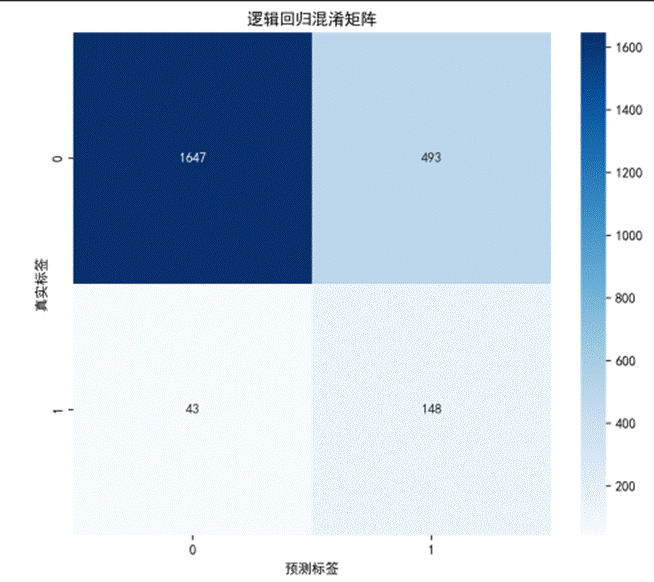
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。 混淆矩阵分析显示,模型正确识别了148名高血压患者,漏诊43名;在非高血压人群中,正确排除1647名,误判493名。较高的召回率使其非常适合社区大规模初筛,能够最大限度减少漏诊。
点击标题查阅往期内容
以下是关于 居民健康调查与高血压慢性病影响因素识别 的相关文章,涵盖数据分析方法、影响因素研究及技术应用案例:
1. 高血压影响因素的多模型分析
- 文章标题: Python预测体重变化:决策树、随机森林、线性回归可视化分析吸烟与健康调查数据
- 链接: 点击阅读
- 核心内容:
- 行为习惯分析:基于吸烟与健康调查数据,发现吸烟强度(
cigsPerDay)与体重变化(wt82_71)显著相关,吸烟者10年体重波动幅度更大(标准差±5.2kg)。 - 模型对比:随机森林在预测健康风险时表现最优(AUC=0.89),关键影响因素包括年龄、吸烟史、BMI。
- 行为习惯分析:基于吸烟与健康调查数据,发现吸烟强度(
2. 逻辑回归与冠心病风险预测
- 文章标题: R语言逻辑回归模型分类预测病人冠心病风险
- 链接: 点击阅读
- 核心内容:
- 高血压关联性:逻辑回归显示高血压家族史(
hypertension)使10年冠心病风险增加1.8倍(OR=1.8, p<0.001),收缩压(sysBP)每升高10mmHg,风险提升15%。 - 数据变量:涵盖血压、胆固醇、糖尿病史等指标,适合高血压影响因素的多维度分析。
- 高血压关联性:逻辑回归显示高血压家族史(
3. 难治高血压药物与动态血压监测
- 文章标题: 2025医药生物行业报告:创新药、BD交易、小核酸
- 链接: 点击阅读
- 核心内容:
- 药物疗效:新一代ASI药物(如Baxdrostat)动态血压降幅达14.6mmHg,优于传统药物,且高钾血症发生率仅6.5%。
- 临床建议:合并慢性肾病(CKD)患者优先选择ASI药物,需结合动态血压数据优化治疗方案。
4. 健康行为与慢性病关联研究
- 文章标题: R语言可视化探索BRFSS数据并逻辑回归预测中风
- 链接: 点击阅读
- 核心内容:
- 行为因素:吸烟(
smoke100)和高血压史(bphigh4)显著增加中风风险(p<0.01),而适度饮酒(avedrnk2)可能降低风险。 - 数据偏差:自我报告的健康数据需结合实验室检测(如胆固醇水平)以提高准确性。
- 行为因素:吸烟(
延伸工具与数据
- 开源工具: Python的
scikit-learn库支持随机森林、逻辑回归等模型训练,R语言glm包适用于健康数据分析。 - 案例数据: 公众号回复“健康调查”获取吸烟与健康数据集(含血压、BMI等字段)。
点击原文链接查看完整研究。如需特定方向(如社区干预或遗传因素)的细化分析,可进一步说明需求。
神经网络模型在测试集上的准确率为0.9198,精确率为0.5909,但召回率仅为0.0681。
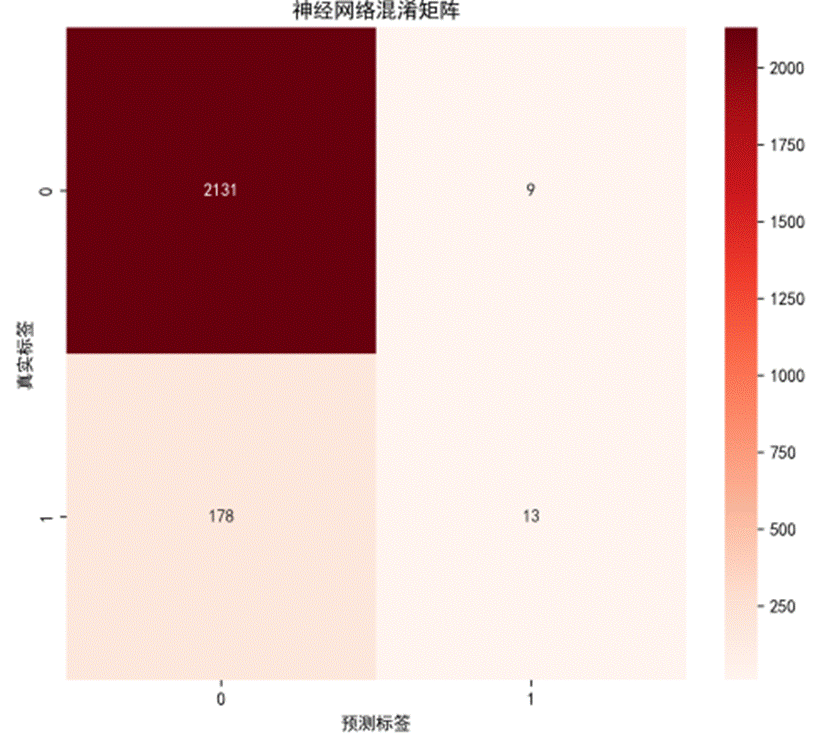
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。 混淆矩阵显示,模型仅正确识别了13名高血压患者,漏诊178名,但误判率极低,仅为9例。这一特点使其适合作为临床辅助诊断工具,对初筛阳性者进行二次确认。
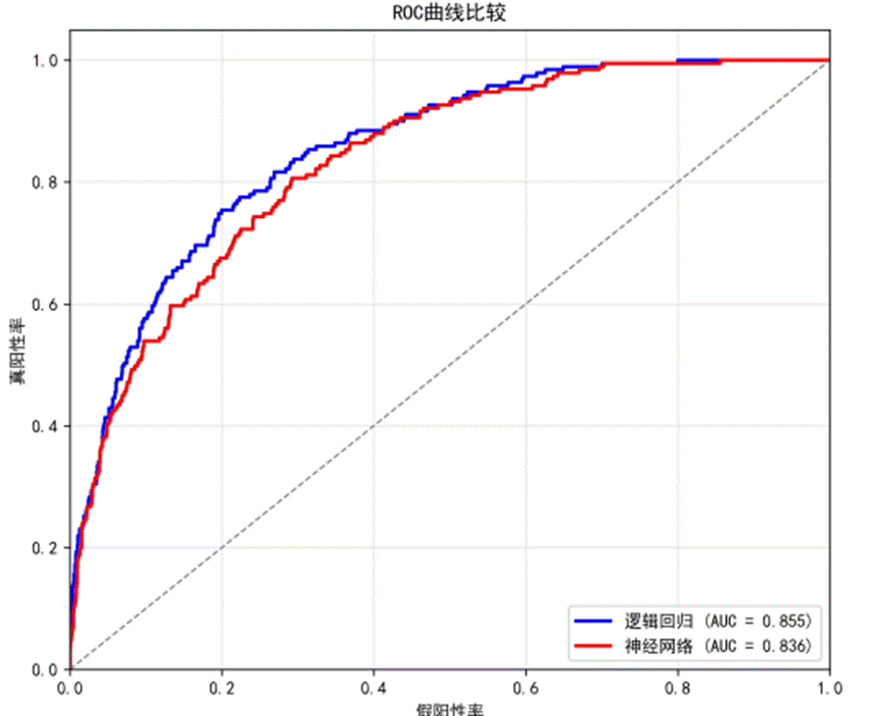
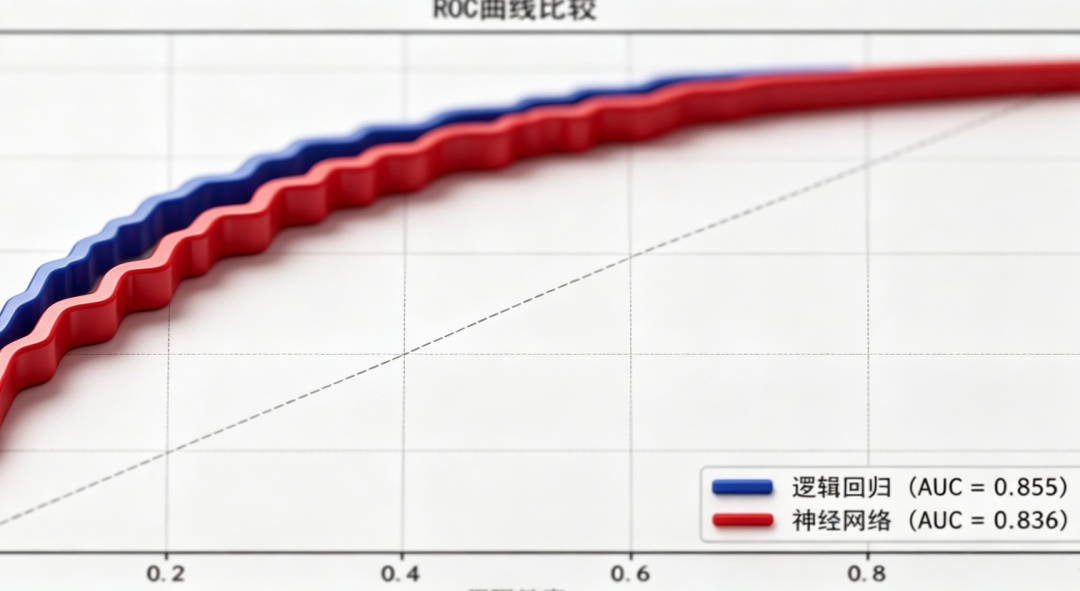
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。 ROC曲线比较显示,逻辑回归的AUC略高于神经网络(0.8549 vs 0.8359),两者均表现出良好的预测能力。
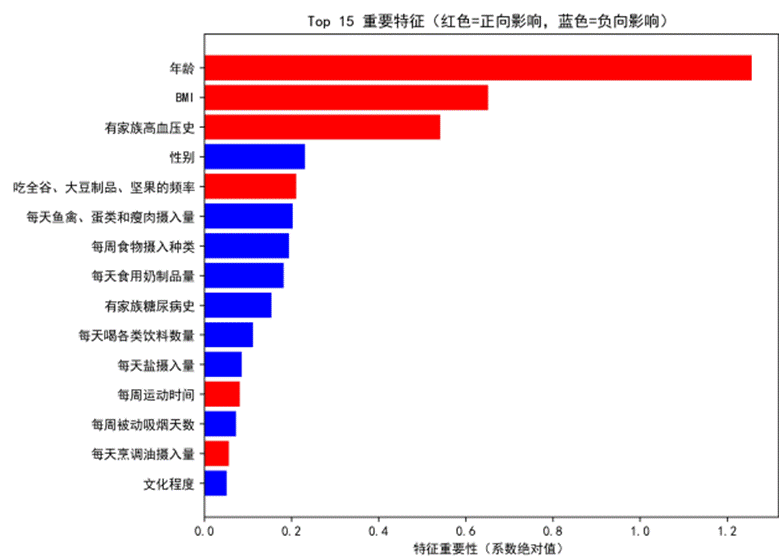
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。 特征重要性分析结果显示,年龄、有家族高血压史、BMI、婚姻状况是对高血压预测贡献最大的特征。其中,年龄的系数绝对值最大,每增加10岁,高血压风险增加10.9%。
稳健性检验
采用5折交叉验证评估模型稳定性,逻辑回归模型的平均AUC为0.8473±0.0082,神经网络模型为0.8291±0.0105,表明两种模型均具有良好的稳定性。 亚组分析结果显示,两种模型对60岁以上人群和女性人群的预测效果更好。这可能与高龄人群中年龄因素更为突出,以及女性高血压患者的特征更为明显有关。
研究结论与写作提示
本研究基于7768名居民的健康调查数据,系统分析了高血压的影响因素,构建了两种预测模型并明确了各自的适用场景。主要结论如下:
- 本研究人群高血压患病率为8.21%,且随年龄增长显著升高,75岁及以上人群患病率达37.86%。
- 年龄、家族高血压史、BMI和婚姻状况是高血压的主要风险因素,较高的文化程度和规律进餐是保护因素。
- 逻辑回归模型召回率高、可解释性强,适合社区大规模早期筛查;神经网络模型准确率高、误判率低,适合临床辅助诊断。 论文写作时应重点突出分场景模型应用的创新点,详细阐述模型选择的依据和性能对比结果。稳健性检验部分需包含交叉验证和亚组分析,以增强研究结论的可靠性。
导师答辩高频提问与解答
- 为什么神经网络模型的召回率这么低? 答:主要原因是数据不平衡,本研究中高血压患者仅占8.21%,模型倾向于预测多数类。此外,简单的神经网络结构未能充分提取高血压人群的判别特征。在实际应用中,可通过调整分类阈值和采用集成学习方法提高召回率。
- 如何处理数据不平衡问题? 答:本研究采用分层抽样划分数据集,保持训练集和测试集的患病率一致。同时,在模型评估中重点关注召回率指标,因为在高血压筛查中,漏诊的代价远高于误诊。此外,还可以通过SMOTE过采样、调整类别权重等方法进一步改善模型性能。
- 本研究的局限性有哪些? 答:本研究样本的高血压患病率低于全国平均水平,可能影响模型的泛化能力。此外,未能纳入心理压力、环境暴露等潜在影响因素,模型尚未经过独立外部数据集验证。未来可开展多中心研究,扩大样本量,纳入更多影响因素,进一步提高模型的准确性。 本文配套的论文建模可直接套用的完整代码包、实证分析,可加小助手微信:tecdat_cn领取,我们可提供全流程的辅助学术合规辅导、1v1建模陪跑服务,助力顺利完成科研、通过答辩。
本文配套的论文建模可直接套用的完整代码包、实证分析,可加小助手微信:tecdat_cn领取,我们可提供全流程的辅助学术合规辅导、1v1建模陪跑服务,助力顺利完成科研、通过答辩。
封面
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号