随机I/O的实际成本


随机I/O的实际成本
random_page_cost 这个参数是在约25年前引入[1]的,从一开始它的默认值就被设为4.0。自那以后,存储技术发生了巨大变化,Postgres 的代码也随之不断演进。如今这个默认值很可能已不再符合实际情况。那你应该改用什么值呢?闪存存储在处理随机I/O方面性能要出色得多,所以或许你应该调低这个默认值?有些观点甚至建议将其设为1.0,与seq_page_cost的默认值相同。这种想法是正确的吗?
我们来做一个实验,"衡量" 随机读取一页内容相较于顺序读取的成本。我们可以这样进行:
- 1. 创建一张包含随机列和索引的表
- 2. 通过顺序扫描读取该表
- 3. 通过索引扫描读取表
- 4. 计算顺序和随机页读取的时间
共享缓冲区保留默认值(128MB)。表的大小比共享缓冲区大一个数量级,但仍相对较小,因此运行时间相当短。effective_cache_size 设置为128MB以匹配共享缓冲区,并且我们启用直接I/O以消除页缓存的影响。
这些选择让缓存效果更容易预测。页面命中和未命中的估算会非常准确(参见 cost_index[2] 和 index_pages_fetched[3] )。这正是我们所需要的。如果输入数据偏差极大,评估成本就没有太大意义。输入垃圾,输出垃圾。
这样就能得到一个约 4.4GB 的表:
CREATE TABLE t (a int, b int) WITH (fillfactor=10);
INSERT INTO t SELECT i, i FROM generate_series(1, 10_000_000) s(i) ORDER BY random();
CREATE INDEX ON t (a);
VACUUM ANALYZE t;我们可以执行一次顺序扫描
EXPLAIN (ANALYZE, TIMING OFF) SELECT * FROM t;
QUERY PLAN
-----------------------------------------------------------------------------------------
Seq Scan on t (cost=0.00..554546.12 rows=10000012 width=8)
(actual rows=10000000.00 loops=1)
Buffers: shared read=454546
Planning:
Buffers: shared hit=38 read=11
Planning Time: 0.597 ms
Execution Time: 708.420 ms
(6 rows)以及索引扫描(它执行几乎完美的随机 I/O):
SET enable_seqscan = off;
SET effective_cache_size ='128MB';
EXPLAIN (ANALYZE, TIMING OFF) SELECT*FROM t ORDERBY a;
QUERY PLAN
-----------------------------------------------------------------------------------------
Index Scan using t_a_idx on t (cost=0.43..38900782.85rows=10000012 width=8)
(actual rows=10000000.00 loops=1)
Index Searches: 1
Buffers: shared hit=342789 read=9684524
Planning:
Buffers: shared hit=44 read=18
Planning Time: 0.957 ms
Execution Time: 392976.430 ms
(7rows)顺序扫描执行了 454546 次顺序读取,而索引扫描执行了约 9660336 次随机读取(页面会被重复访问,每一行数据访问一次)。据此我们可以计算出单页顺序读取和单页随机读取的耗时:
seq_page_time = (708.420 ms / 454546) = 1.559 us
random_page_time = (392976.430 ms / 10000000) = 39.298 us我们常说成本不等于时间,且这种映射关系很复杂。但在这个简单的例子中,我们可以通过将这两个时间值相除,直接计算出random_page_cost。
random_page_cost = random_page_time / seq_page_time = 39.298 / 1.559 = 25.2这显然比默认值 4.0 要高得多。这可能令人惊讶,并且它直接与在固态硬盘(SSD)上降低random_page_cost值的建议相矛盾。
这个计算有些粗略,因为它忽略了 cost_index 中包含的其他部分。我们可以通过减去每元组的cpu_tuple_cost、cpu_index_tuple_cost 和 cpu_operator_cost 来"去除"这些组成部分。然后计算 random_page_cost ,使总成本的比例与时间匹配。
CPU 开销远小于 I/O 开销,因此结果不会有太大差异。另外还有一个问题,即那些其他的单元组开销有多"准确"。我们将直接忽略这一点。
实验
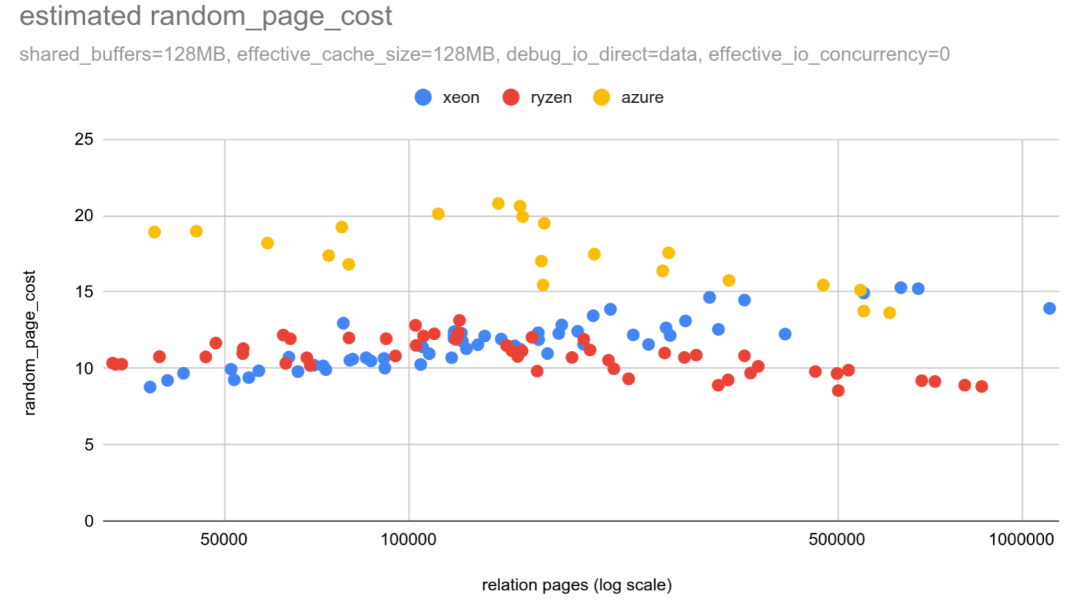
我在三个系统上重复了这项测试,使用的是包含500万到2500万行数据且填充因子随机的表。其中两个系统配备本地固态硬盘(分别为锐龙、至强处理器),另一个部署在Azure上,使用的是远程固态硬盘。
这里有一张图表展示了估算的 random_page_cost 值:
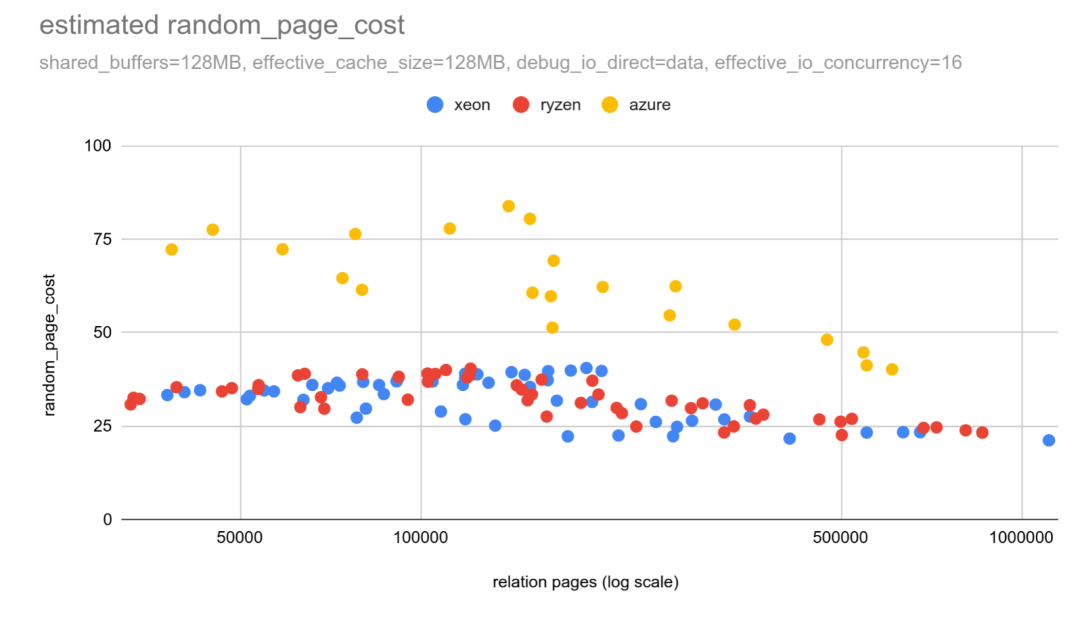
在本地固态硬盘上,估计的 random_page_cost 值约为25-35。这与之前的结果相符,且比默认值高出近一个数量级。而在远程固态硬盘上,这一差异甚至更大。
这在实际中意味着什么?成本参数用于查询规划,如果 random_page_cost 的数值差了一个数量级,它会影响规划结果吗?当然,如果真的会影响,那就太奇怪了。
我们来考虑顺序扫描和索引扫描这两种执行基本的顺序与随机I/O操作的执行计划。其成本和耗时与被访问的页面数量呈线性比例增长。
这是一个返回表中可变部分的查询:
SELECT * FROM t WHERE a BETWEEN $1 AND $2;如果我们为一个包含1000万行的表绘制不同比例(与 BETWEEN 子句匹配)对应的成本和耗时,我们会得到如下图表:
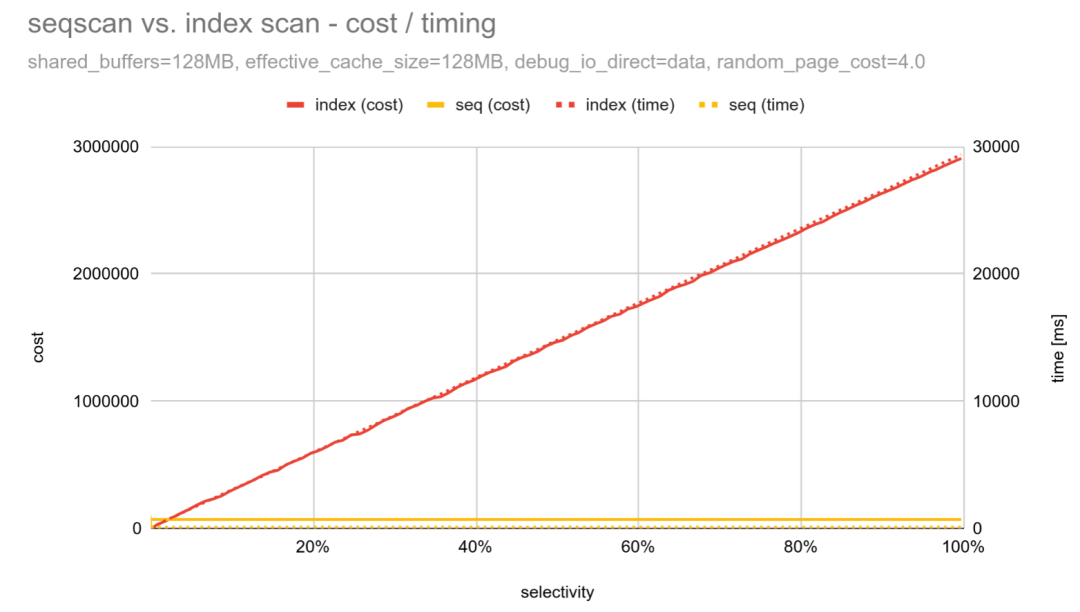
横轴显示符合条件的行占比,左侧和右侧纵轴分别表示成本和持续时间。
由于索引扫描的成本/持续时间值极端,难以看清接近1%的“关键”部分发生了什么,在该位置成本(和持续时间)相互交叉。
这是一张放大展示该部分的图表:
索引扫描的成本和耗时具有相同斜率并非偶然。这是数值随扫描访问的页面数呈线性变化的直接结果。假设未命中缓存,它会按每条元数据读取一个页面,而每个页面的成本为 random_page_cost 。
对于顺序扫描,其成本和持续时间是固定的,因为无论有多少行满足条件,扫描都必须读取所有页面。
关键在于成本(以及耗时)的交点在哪里。
成本(实线)在约2.2%处相交,此时规划器切换为顺序扫描。而耗时(虚线)则在0.2%处相交,此时顺序扫描的速度更快。
这意味着在选择性介于0.2%到2.2%之间时,规划器会选择“错误”的计划。在接近2.2%的选择性时,查询的执行时间可能会延长至原来的约10倍。
成本核算永远不可能做到完美——毕竟这是一个基于估算的简化模型。但成本和工期的匹配度越高越好。这些选择性指标之间的差距越大,我们就越有可能得出错误的方案。
对于 random_page_cost = 30.0(这是我们的实验针对本地固态硬盘给出的建议值),该图表会呈现出什么样的情况?
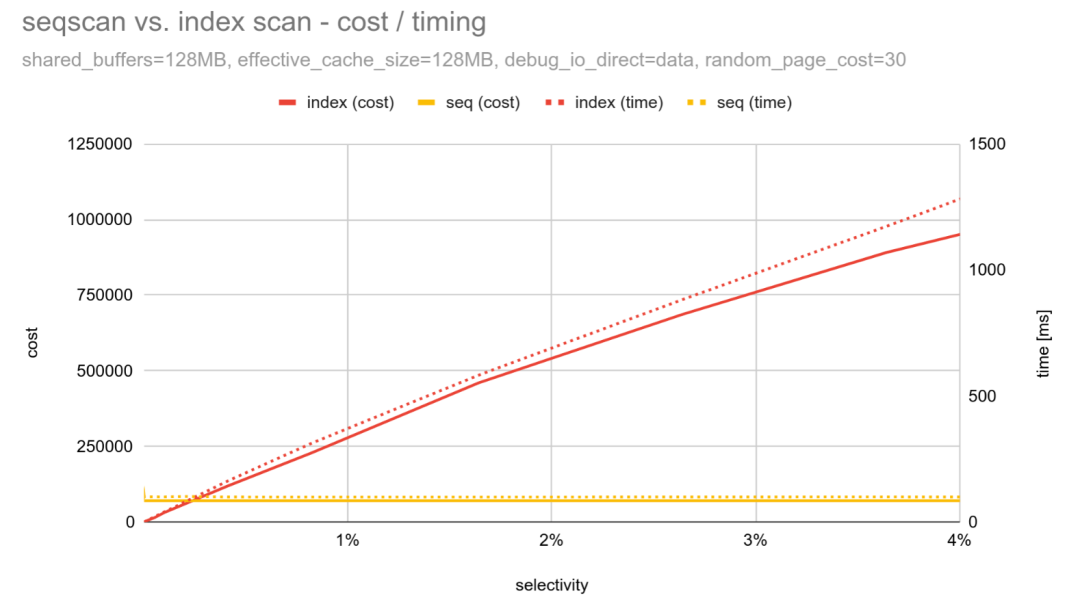
成本和持续时间几乎完全匹配!
注意左侧纵轴的范围已调整,以应对约8倍更高的索引扫描成本。这一调整“压低”了顺序扫描成本,且成本交点现在几乎完美地与0.2%对齐。
Bitmap Scans
0.2% 到 2.2% 的选择率“差距”相当大,因此选择低效计划的风险看似相当高。但实际上情况并没有那么糟,这要归功于位图扫描——这是一种适用于访问大量行的查询的索引扫描变体。
这里有一张展示全部三种扫描类型的图表(对应 random_page_cost = 4.0 ):
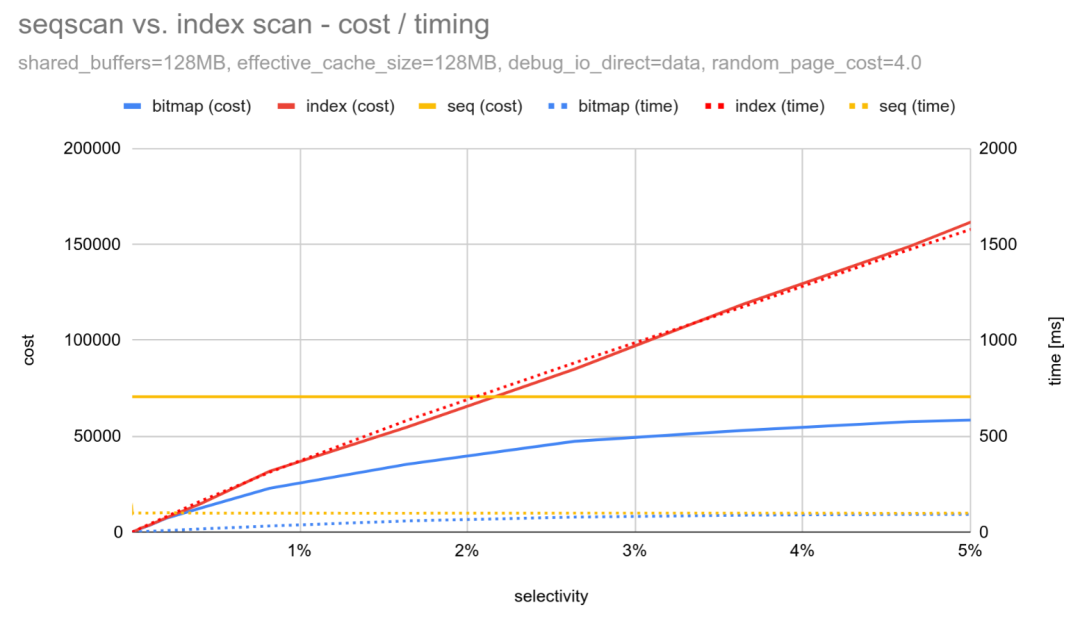
位图扫描的开销始终低于顺序扫描和索引扫描,仅在接近0%的极小区域内索引扫描更具优势。其执行时长也始终低于索引扫描。位图扫描能让数据访问更具顺序性,还支持I/O预取(提前发起I/O操作)。
Cost vs. prefetching
说到预取,这是一个非常有趣的话题。它能显著提升性能,但成本模型却完全没有考虑到这一点。将 effective_io_concurrency = 0 设置为禁用预取,执行时长可能会增加10倍,但成本却完全不变。
据我所知,这主要是因为预取功能是随着时间推移逐步添加到部分选定的执行计划(例如位图扫描)中的,并非原始成本模型的组成部分。此外,也很难预测预取带来的影响(它对某一特定计划能起到多大的帮助作用)。
假设这种方法无效,那么可以将其视为一种“防御性”策略。预取本身相对安全——它通常能带来显著的优化效果,也可能仅造成轻微的性能回落。调整成本会带来选择不同执行计划的可能性,这一风险则大得多。遗憾的是,执行计划的切换是一种相当常见的性能问题。
更糟糕的是,这并非对所有扫描类型都产生同等影响。位图扫描支持对最长数据进行预取。得益于异步输入输出(AIO),顺序扫描现在也具备了预取功能(此前它依赖于内核的预读机制)。你可以在我关于AIO 的帖子中看到部分相关效果。
索引扫描目前不进行任何预取操作,但这一情况很有可能在 Postgres 19 中得到改变。
调整 effective_io_concurrency 会影响持续时间,而非成本。它会改变持续时间的交叉点,却不会改变成本。其效果与 random_page_cost 相反,后者改变的是成本,而非持续时间。
但这意味着两个GUC在相互抵消!更改预取(启用/禁用)会改变 "正确的" random_page_cost 值。
下面是一张展示禁用预取时 random_page_cost 数值的图表:
这与本文中第一张图表的实验是同一个,但对比结果可以看到数值从约30降到了约10。禁用预读取让随机I/O的成本降低了约三分之二!
这听起来可能有些奇怪。预取本应是为了降低随机 I/O 的成本!但索引扫描目前还不支持预取,而顺序扫描则支持。因此,禁用预取会让顺序扫描变慢,却完全不会影响索引扫描。顺序读取的速度变慢,我们就会觉得随机读取的成本变高了。
当然,预取并不会让单次随机 I/O 变得更便宜。它只是让随机 I/O 看起来更划算,因为执行器无需等待那么久才能获取到数据。这与并行性通过并发执行任务来降低查询开销的原理类似。
我们很可能需要对此采取一些措施,并开始在成本核算中考虑预取。如果有两条路径,I/O 工作量相同,但其中一条可以进行预取,那么它的成本应该看起来“更低”。不过,估算预取带来的影响并非易事。
降低 random_page_cost 可行吗 ?
我们知道随机 I/O 的 "真实成本" 远高于默认值 4.0。在本地高速固态硬盘上,这一数值约为 30,而在云存储上则更高(延迟显然是关键因素)。难道仅仅因为 "固态硬盘的随机 I/O 速度很快",就应该调低random_page_cost吗?
不过,这就意味着它总是错的吗?当然不是。一些建议降低 random_page_cost 值的人无疑是非常有经验且受人尊敬的工程师和管理员。他们给出这个建议肯定有充分的理由。那会是什么理由呢?
我能想到几个原因。
随机且有针对性
我们假设数据未被缓存,这会产生大量随机I/O。但许多现实世界的系统并非如此运行。数据集可能很大,但"active set"(被查询访问的部分)要小得多,完全可以放入内存中。这意味着大多数随机读取根本不会触发物理I/O,成本也会非常低。
事实上,执行顺序读取可能会非常糟糕。读取整个表需要进行物理I/O,尤其是如果表非常大且无法装入内存时。这甚至可能将部分热点数据挤出内存。优先对小型缓存数据集进行随机I/O,而非无缓存的顺序I/O,会是更好的选择。
正如 pgsql-hackers[4] 讨论线程中指出的那样,OLTP 系统通常具有极高的缓存命中率。在因选择性小幅提升而选择是坚持索引扫描还是切换到顺序扫描时,还存在一种非对称情况。如果我们过早切换到顺序扫描,就会突然不得不付出高昂代价。而索引扫描的成本是线性增长的,这种逐步退化远比 性能骤降要好得多。
我们在规划阶段估算这一点的能力非常有限。effective_cache_size 提示能让我们大致了解有多少数据能放入缓存,但我们无法判断某个特定查询是否只访问了缓存数据。降低 random_page_cost 是一种间接方式,以此告知优化器我们预期会出现这种情况。
孤立规划
另一个有趣的细节是,我们会单独规划查询,就好像不存在其他查询一样。选择顺序扫描可能对我们的查询是有利的。但如果它将其他查询所需的数据从缓存中挤出,那可能会造成巨大的损失。
执行随机 I/O(索引扫描)的计划通常 "更具针对性" ,且需要访问的数据子集要小得多。这能降低缓存压力,并使活跃数据集更有可能装入内存。
错误的估算
我能想到的最后一个原因是估算错误。这篇文章中的示例使用的是非常简单的数据集(均匀分布),这使得优化器几乎可以做出完美的估算。而实际的数据集要复杂得多,存在相关性等诸多因素,此时估算结果可能会非常糟糕,进而导致优化器选择“错误”的执行计划。
缓解这一问题的一种方法是将成本参数(例如random_page_cost)调整为恰好能选择正确查询计划的“错误”值。但这是一种粗陋的手段,且通常仅适用于特定的数据集和/或查询(并非所有估算都会出现偏差)。
结论
降低 random_page_cost 是个好主意还是坏主意 ?仅从实际的 I/O 成本来看,随机 I/O 比默认值要昂贵得多。如果仅仅以 "固态硬盘速度快" 为理由做出这个调整,那就是一种错误的做法。
实际上,出于上一节提到的所有原因,这样做可能是正确的。如果你打算调整这个 GUC,强烈建议监控性能,并通过它来评估更改 random_page_cost 值的效果。当然,也可以用于评估其他任何参数的更改效果。
你应该配备一些监控手段——要么是专门的监控系统来跟踪查询延迟,要么至少是临时的 pg_stat_statements 快照。
还有很大的改进和补丁空间。如果你通读我发起的关于修改线程中 random_page_cost 默认值的讨论,至少能看到这些想法:
- • 将非 I/O 成本与 random_page_cost 分离[5] - random_page_cost 参数用于计算涉及随机 I/O 的各类操作的成本,同时也涵盖了一些额外开销(例如 I/O 合并的影响、部分 CPU 成本等)。将这些成本分离到专用的 GUC 参数中似乎是合理的。
- • 改进缓存数据的统计[6] 我们估算哪些数据(或至少其占比)已被缓存的能力非常有限。我们有 effective_cache_size ,但这还不够。它仅用于估算某个查询访问的数据是否被同一查询缓存过。
- • 在成本核算中考虑预取[7]目前,成本核算完全忽略了预取。然而预取可能会对性能产生巨大影响,通常能提升一个数量级(甚至更高)。这一影响的重要性足以在成本中体现出来。
引用链接
[1] 引入:https://www.postgresql.org/message-id/flat/14601.949786166@sss.pgh.pa.us
[2]cost_index:https://github.com/postgres/postgres/blob/4c1a27e53a508f74883cda52a6c8612121d7fd6b/src/backend/optimizer/path/costsize.c#L544
[3]index_pages_fetched:https://github.com/postgres/postgres/blob/master/src/backend/optimizer/path/costsize.c#L896
[4]pgsql-hackers:https://www.postgresql.org/message-id/5qum3e5rzblbuw4m5cb7g6l5d6y2gip4ltz6pouutqkljc645r%40ibvg5dygvqgl
[5]将非 I/O 成本与 random_page_cost 分离:https://www.postgresql.org/message-id/wc7mgalaplotpetwcackcbrm4lwdkvyajdcsi2gsslhknfavzi%40t5jo47nnyppa
[6]改进缓存数据的统计:https://www.postgresql.org/message-id/CA%2BTgmoagjyStEVKymvA_kxLfKXhHUj5beaBZ_JVU9mOxrX%2Bm2g%40mail.gmail.com
[7]在成本核算中考虑预取:https://www.postgresql.org/message-id/6ysaf44vvhgujw4tsl25vwshifizsuzfvcxlsdjrsqogmg2wzt%40wehmt3xd6ayj
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号