当模型越来越强,AIDD 真正稀缺的东西是什么?

当模型越来越强,AIDD 真正稀缺的东西是什么?

MindDance
发布于 2026-04-21 13:38:34
发布于 2026-04-21 13:38:34
有些模型结果看起来特别漂亮,但一落到真实项目,根本不是那么回事。
做 AIDD 久一点的人,对这种感觉大概都不陌生。
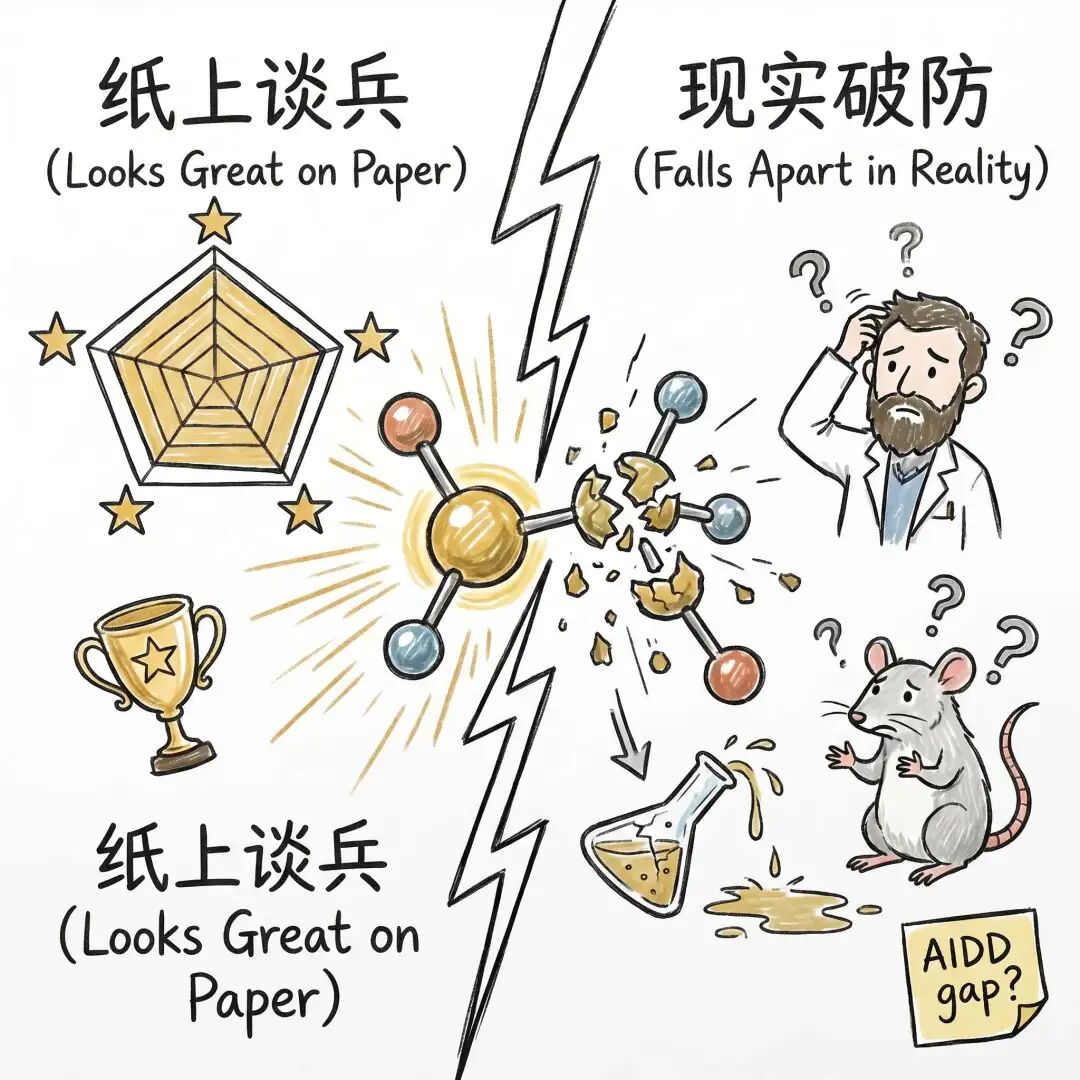
图画得很好,分数也很好,论文里看起来几乎没有明显短板;可一旦往前走一步,进到真实的设计、合成、测试和迭代里,很多原本在 paper 上成立的东西,突然就不再那么成立了。
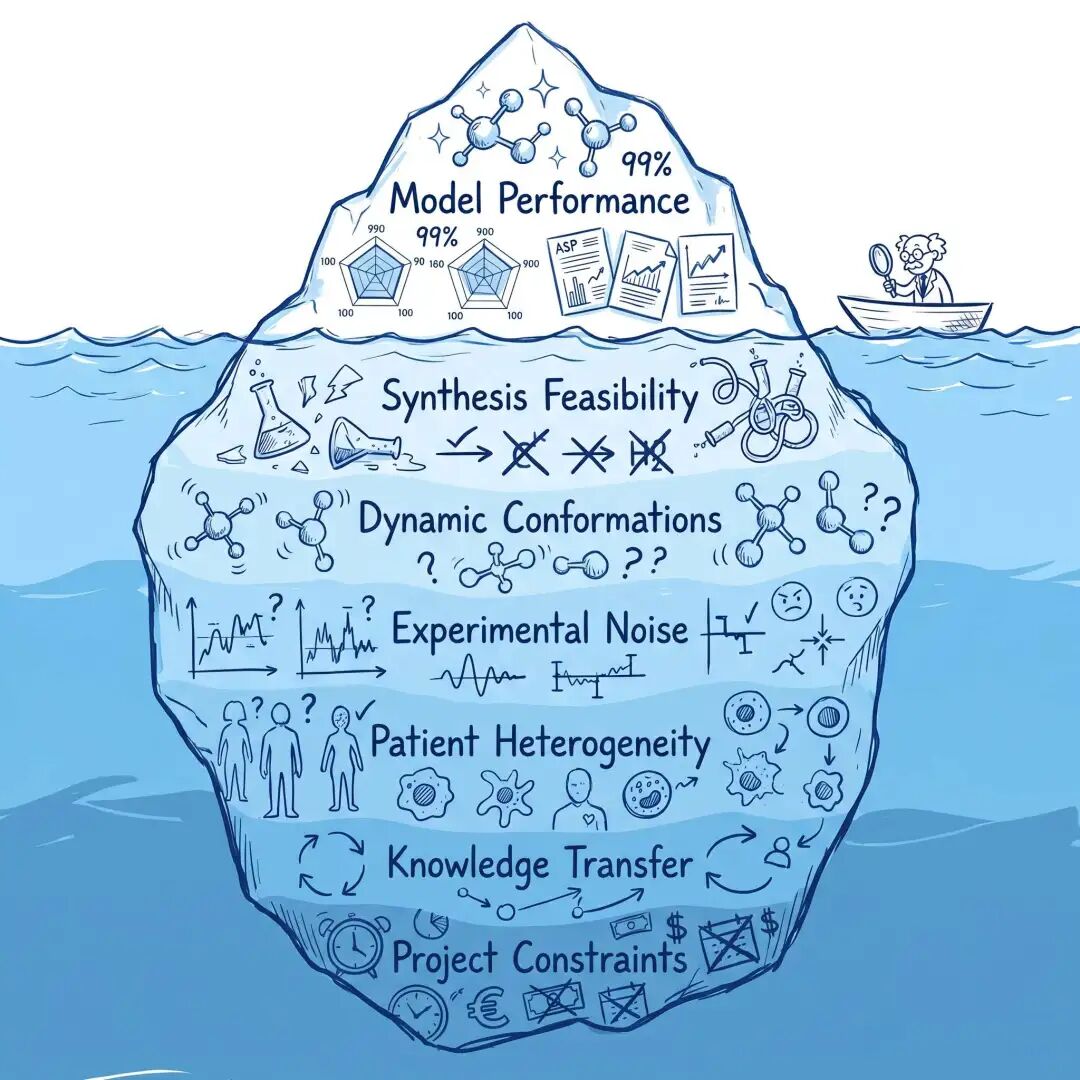
这几年,AIDD 尤其是小分子领域,进展当然是非常快的。结构预测、多模态建模、生成式模型、主动学习、自动化实验平台,一个接一个地往前推。站在技术演进的视角看,这个领域几乎一直处在火热的状态里。
但如果把视角从模型能力稍微往外挪一点,就会发现一个更值得反复想的问题:
AIDD 下一阶段真正稀缺的,可能不只是更强的模型,而是更接近真实药物发现的问题定义。
这句话听起来有点抽象,但我越来越觉得,它可能正是理解这个领域下一波高质量创新的一个关键入口。
01|我们曾经以为,问题主要在模型里
过去几年,AIDD 的很多工作,核心逻辑其实都很熟悉:给定一个任务、一个数据集、一个评价指标,然后努力把模型做得更强一点,把分数再往上推一点。
这条路线当然有价值。没有这些基础工作,也不会有今天这么丰富的方法生态。
但问题在于,药物发现本身并不是一个被天然定义好的机器学习任务。它不是一张干净的监督学习表格,也不是一个边界清晰的优化问题。它更像是在一个噪声很大、反馈很慢、约束很多、目标还会不断变化的系统里做决策。
在这种系统里,预测更准当然重要,但它并不自动等于“更接近真实问题”。
很多时候,我们以为自己在优化药物发现,实际上优化的是一个被过度简化之后的代理任务;我们以为自己在验证模型的泛化能力,实际上验证的可能只是模型对现有数据分布的复用能力;我们以为自己在生成候选分子,实际上生成的只是一些在指标上好看、但在项目中难以前进的结构。
这也是为什么,很多 AIDD 论文技术上很完整,结果也很漂亮,但读完以后,总会隐约有一种感觉:它离真实项目推进,似乎还差着一层东西。
那一层东西,往往不是模型少了几个参数,也不是网络结构再改一个模块就能解决。它更像是:问题本身设得还不够真。
所以我现在越来越倾向于把 AIDD 的下一阶段理解成一次问题重构,而不只是一次模型升级。
02|结构越来越强,不等于答案自动出现
这种变化,在结构建模上其实已经很明显了。
过去一段时间,结构生物学和 AI 的结合极大地抬高了整个领域的期待。大家会自然地觉得:只要结构越来越准,后面的事情是不是就会顺理成章?
但真正做小分子的人通常很快就会意识到,结构很重要,却从来不是全部答案。
因为药物发现关心的,从来不只是“某个复合物在某一时刻看起来像什么”,而是这个口袋到底有多稳定,这个构象是不是可利用的,分子进入体系以后会不会发生重排,变构位点能不能被真正调动起来,溶剂、柔性和能量地形会不会把原本那张很漂亮的 pose 图推翻。
换句话说,静态结构很有价值,但它并不能天然替代动态过程、物理约束和实验现实。
所以,今天真正值得关注的方向,已经不只是能不能把结构看得更准,而是能不能把结构、动力学、能量、不确定性和实验验证更自然地接起来。真正有说服力的工作,不只是给出一个结果,还能解释这个结果为什么可靠、在哪些条件下会失效、以及它对后续设计意味着什么。
从这个角度看,AIDD 里有分量的创新,正在慢慢从会不会预测转向能不能形成机制层面的理解。
一旦问题走到机制层面,模型就不再只是一个做分数的工具,而开始真正参与科学判断。
03|生成式模型的分水岭,不在 novelty,而在交付
类似的变化,也发生在生成式模型上。
前几年生成式模型最打动人的地方,是它似乎一下子把化学空间打开了。模型能生成大量新颖分子,能做 scaffold hopping,能在多目标条件下搜索,甚至还能表现出某种像药化学家一样思考的错觉。
但时间稍微拉长一点,大家也会慢慢意识到,生成能力本身并不是终点。
因为在真实项目里,一个分子的价值,从来不是“看起来新不新”,而是它能不能被合成、能不能被验证、能不能接出后续的 SAR、能不能在项目约束下继续往前走。
也就是说,生成式模型真正的分水岭,并不在于它能不能画出很多分子,而在于它能不能交付分子。
这两者之间,看起来只差了两个字,实际上差的是整套问题设定。
前者更像一个开放式创造任务,强调模型的表达能力和搜索能力;后者则要求模型正面面对药物发现里的现实约束:反应可行性、building block 可得性、路线复杂度、项目节奏、性质权衡、实验反馈,甚至失败历史。
一旦把这些东西都放回去,生成问题就不再只是我能设计出什么,而变成什么样的分子,值得被真正做出来。
我觉得这才是小分子 AIDD 里生成式模型真正值得进入深水区的地方。不是继续追求更漂亮的 novelty,而是开始对 deliverability 负责。
04|闭环系统最重要的,不只是更快,而是更会沉淀知识
过去大家谈 closed loop,更多是在讲效率:怎样用更少轮实验找到 hit,怎样更高效地做主动学习,怎样把 design–make–test–analyze 的流程自动化。
这些都很重要,尤其对平台建设来说,效率提升本身就是价值。
但如果只停在这里,我总觉得还是不够。因为药物发现真正稀缺的,不只是更快地跑流程,而是从流程里长出知识。
一套真正高级的闭环系统,不应该只是不断吐出下一批候选分子;它还应该帮助我们逐渐回答一些更难的问题:为什么这个系列有效,为什么另一个系列失效,哪些失败是偶然噪声,哪些失败其实在暗示某种更稳定的规律,哪些局部经验能够跨项目、跨靶点、甚至跨实验室迁移。
换句话说,闭环最理想的目标,不只是 optimization loop,而是 knowledge loop。
这个区别看起来不大,但它其实决定了一篇工作最终停留在工程优化还是进入科学发现。
如果一个系统最后只是帮我们更快地找到一个答案,它当然有用;但如果它还能让我们更清楚地知道,答案为什么会是这样,那它的意义就完全不同了。
05|AIDD 最终还是会回到真实世界
而所有这些变化,最后都在把 AIDD 推回一个更本质的问题:它到底要更靠近什么?
如果答案只是更靠近 benchmark,那很多事情已经做得很好了;如果答案是更靠近真实药物发现,那模型之外的很多东西就必须重新进入视野。
比如更真实的实验体系,更复杂但也更有价值的表型信息,更高维的细胞状态读出,更贴近人体生物学的验证路径,以及更早期地去考虑患者异质性和转化相关性。
这一步很难,也不如刷指标那样直接。但我越来越觉得,这可能才是 AIDD 最终绕不过去的方向。
因为模型能力再强,也不能自动替代生物学复杂性;结构再准,也不能自动解决人体相关性;生成再快,也不能自动回答这个分子在更真实的系统里究竟会发生什么。
从这个意义上说,AIDD 下一阶段最有价值的工作,可能并不是继续把某一个局部能力推到极致,而是想办法把化学、机制、实验和人类相关性放回同一个问题框架里。
这是真正困难的部分。
但也正因为困难,它才更可能孕育出真正高水平的创新。
End|也许,我们真正该期待的,不只是更聪明的机器
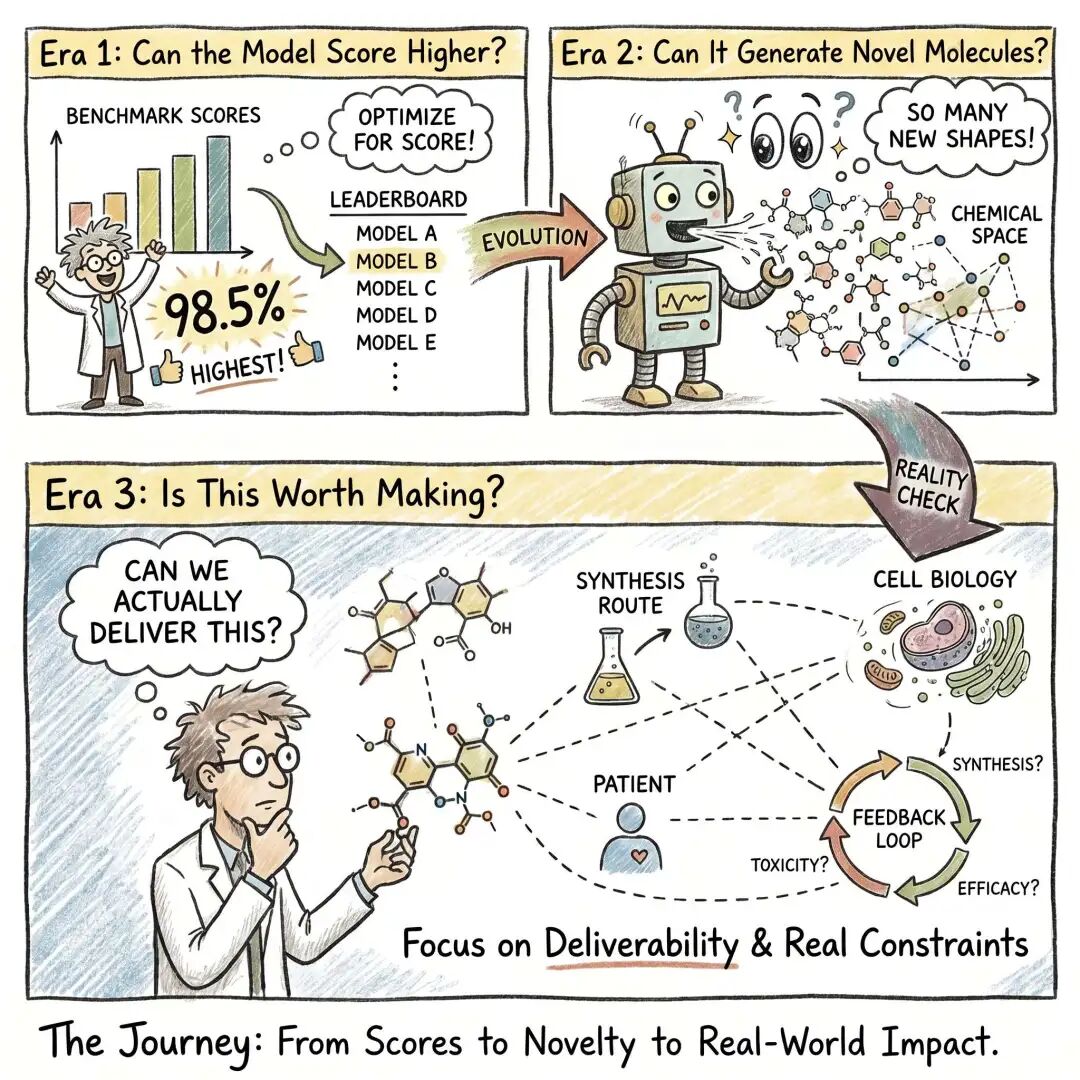
如果今天再回头看 AIDD,尤其是小分子领域,我会觉得这个方向正在发生一种很有意思的变化。
一开始,大家关注的是模型够不够强。
后来,大家开始关注结构、多模态、生成和自动化。
而现在,真正值得认真对待的问题也许正在变成:这些能力,究竟有没有被放进一个足够真实的问题里。
这并不是说模型不重要。恰恰相反,我觉得模型今天比任何时候都更重要。只是它终于开始被要求放在一个更严格、也更接近真实发现过程的坐标系里被审视。
在这个坐标系里,好的工作不只是更会预测,而是更能解释;不只是更会生成,而是更能交付;不只是更会自动化,而是更能沉淀知识;不只是更像一个 AI 任务,而是更像一个真正的药物发现问题。
回头看,AIDD 这些年的热闹,很容易让人产生一种错觉:好像只要模型继续变大、结构继续变准、生成继续变强,药物发现就会自然向前推进。
但真正做过项目的人都知道,现实从来不是一条平滑的技术曲线。很多时候,决定一个分子命运的,不是它在图上看起来有多漂亮,而是它能不能被合成、能不能被解释、能不能在更复杂的生物体系里站得住。
也因此,我越来越相信,AIDD 下一阶段最重要的创新,不会只是让机器更聪明,而是让整个发现过程变得更诚实:更尊重物理约束,更面对实验现实,更靠近人类生物学,也更愿意从一次次失败里沉淀出真正可迁移的知识。
如果说过去几年,我们主要是在教会机器如何设计分子;
那么接下来真正值得期待的,也许是它开始帮助我们回答另一个更难的问题:
什么样的分子,才真的值得被做出来。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号