Claude Code 写完代码就完了?我用一个自研 Skill 编排了 7 阶段严谨开发工作流,拦下 10 个 Critical Bug

Claude Code 写完代码就完了?我用一个自研 Skill 编排了 7 阶段严谨开发工作流,拦下 10 个 Critical Bug

码哥字节
发布于 2026-04-21 13:02:43
发布于 2026-04-21 13:02:43
一个真实线上特性从实施到 ready-to-merge 的完整复盘:为什么仅靠 Claude 写代码不够、为什么 cold-context review 能找出熟人看不到的 bug、如何把工作流固化成可复用 skill。
我用 Claude Code 做了一个订单改单幂等重试的特性。
12 个 task,Claude 帮我一个一个写完,都能编译、过单测,self-review 也通过了。按过去的习惯,我就准备 merge 了。
后来想起还有 superpowers 生态的 code-reviewer skill,顺手让一个完全不知道设计方案的独立 reviewer agent 看一眼。
30 分钟后它甩给我一份报告——10 个 Critical / High 级别的 bug。其中两个会直接造成重复扣款或订单永久卡死的并发漏洞。
看完那份报告我冷汗直冒。如果按原计划 merge 到 master,少说是几十单生产事故。
这不是 Claude Code 不够强。Claude 写代码的能力已经很够了。问题是:我把「Claude 写完代码」当成了「这事做完了」。对一个涉及并发、资金、状态机的关键特性来说,这个认知差得太远。
这篇文章要讲的是我从这次踩坑里沉淀下来的整套工作流:从需求到 ship 的 7 个阶段,怎么把 Claude Code 和 superpowers 生态编排起来,怎么用 4 种独立视角交叉验证,怎么把方法论固化成一个 skill 让同事一键复用。
不是 Claude Code 不够强,是工作流不够严谨
Claude Code 非常擅长"把一段需求转成可运行代码"。但严谨的特性开发不只是这一件事。它还包括:
- 设计阶段考虑过并发 / 失败 / 幂等吗?
- 实施中每个 task 有独立 review 吗?
- 实施后能发现自己的盲点吗?
- 改动意外改变原有业务逻辑了吗?
- 影响其他仓库了吗?
- 简化代码时踩陷阱了吗?
- 文档和代码还对齐吗?
每一步都是潜在的事故源。Claude Code 原生只覆盖中间"写代码"那一步。
在订单中台做关键业务特性时,我总结出一个对比:
环节 | 普通 AI 辅助开发 | 严谨 AI 辅助开发 |
|---|---|---|
需求 | 一段话 prompt | 显式 spec 文档,每个决策点都有论证 |
计划 | 脑内规划 | 显式 task 清单,文件/行号精确到位 |
实施 | 一次性写完 | 逐 task fresh subagent,独立 review |
验证 | 跑测试 + 自测 | 4 种独立视角交叉验证 |
修复 | 直接改 | 走一遍新的 plan |
简化 | 直接删冗余 | 带怀疑的验证,随时准备回滚 |
文档 | 写完就忘 | 强制回填 evolution log |
普通工作流对简单特性够用。对关键特性,它缺的环节太多。问题是出事之前你根本不知道缺了什么——这正是需要工作流把每个环节都兜住的原因。
真实案例:一个改单幂等特性的完整生死劫
先讲背景。这是订单中台的改单幂等重试特性(修改已下单订单的产品 / 价格),跨两个微服务(订单、履约),涉及:
- 分布式锁
- 多状态机转换(APPLIED → MODIFYING → FINISH)
- 多次外部 RPC(退款服务、履约服务、订单服务)
- MQ 发布(多个下游消费者)
- Redis 缓存一致性
- 重试调度(多 pod 定时任务)
任何一个环节出错都能直接卡死订单或造成重复扣款。
完整时间线:
- Day 1-3:用
superpowers:brainstorming做设计。产出 82KB 的设计文档,覆盖 4 种 crash 场景、8 种风险和缓解策略。 - Day 4:用
superpowers:writing-plans把设计拆成 12 个 task 的实施计划。 - Day 5-10:用
superpowers:subagent-driven-development逐 task 实施,每个 task fresh subagent 写代码 + spec reviewer 审查 + code quality reviewer 审查。12 task 全部通过。 - Day 11:常规自测,能编译、过单测。按之前的节奏,现在就该 merge。
Day 12 是转折点:我顺手跑了一次 cold-context code review。给一个 fresh reviewer agent 只看分支名 + 一句话目标,明确禁止它看设计文档。30 分钟后它列出 10 个 Critical/High 级别 bug。
- Day 13-14:又走一遍
writing-plans规划 11 个修复 task,再走一遍subagent-driven-development实施。 - Day 15:修完觉得某段缓存代码"看起来冗余",尝试简化。删了 154 行代码,所有测试都通过。
- Day 15 晚:同事 review 发现致命问题——我以为可以从 DB 字段重建的
refund_id,在另一条业务分支下存的是payment_id(同一个字段,多义)。简化版本会把 PaymentID 作为 refund_id 泄漏给下游。当场git revert。 - Day 16:把设计文档和 plan 文档回填,记录完整的 evolution log + 失败简化尝试的教训。
从计划到真正 ready-to-merge,用了 2.5 周。比"让 Claude 一口气写完"多出约 60% 的时间。换来的是 10 个 Critical bug 在 merge 前被发现,以及一次及时回滚的失败简化尝试。
核心洞察:独立视角产生的信号彼此独立
为什么我自己 review 代码找不到的 bug,一个 agent reviewer 能找出来?
关键不在"agent 比我强"。关键在它不知道我是怎么设计的。
设计文档代表作者相信系统应该如何工作。熟悉设计的 reviewer 会默认作者的假设是对的,从而看不到"这个假设本身就是错的"。Cold-context reviewer 只看代码实际做什么,反而能发现设计层面的漏洞。
这个洞察推广一下,就是一条更强的原则:
“用 N 个互不知情的 reviewer 轮询一个特性,发现的 bug 集合接近是并集而不是重复。
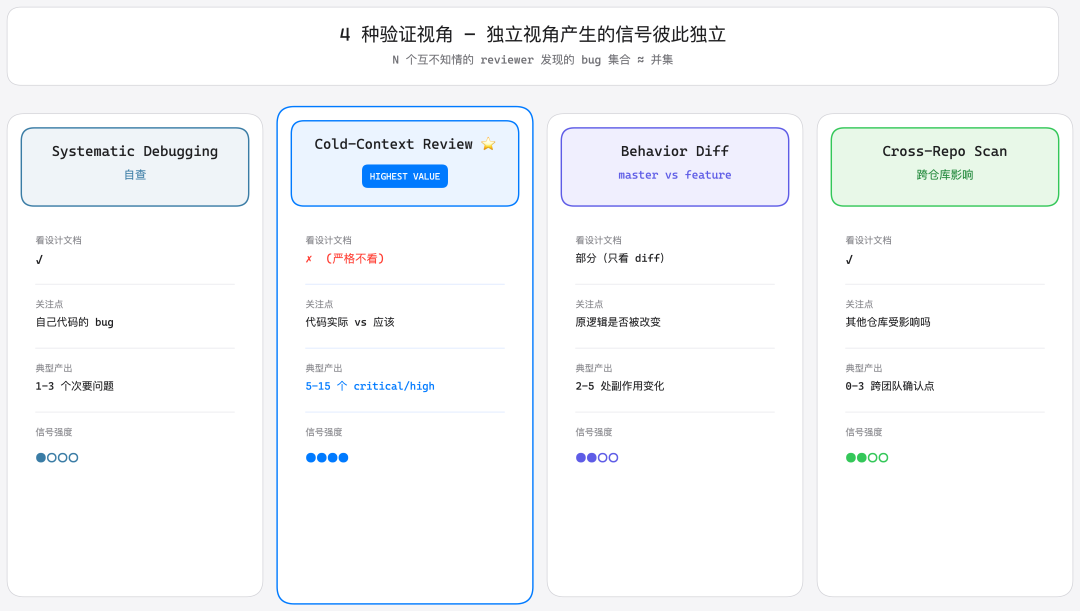
4 种验证视角的独立信号矩阵
4 种验证视角的独立信号矩阵
在这次实施中,我用了 4 种独立视角,每种产出的信号几乎不重叠:
视角 | 是否看设计文档 | 关注什么 | 典型产出 |
|---|---|---|---|
Systematic Debugging(自查) | 看 | 自己代码的潜在 bug | 1-3 个次要问题 |
Cold-Context Review ⭐ | 严格不看 | 代码实际做什么 vs 应该做什么 | 5-15 个 critical/high |
Behavior Diff(master vs feature) | 只看 diff | 原业务逻辑是否被改变 | 2-5 处副作用变化 |
Cross-Repo Scan | 看 | 其他仓库受影响吗 | 0-3 个需跨团队确认点 |
Cold-Context Review 是信号最独立、最有价值的一轮。我在 prompt 里明确写:
DO NOT read the design document.
Your value comes from NOT knowing what the author intended.
越严格地 gate reviewer 的信息输入,它的发现越有价值。听起来反直觉——我们平时习惯"给 reviewer 更多上下文帮助它理解",但在 bug hunting 场景下,信息越少越独立。
7 阶段工作流的全景
把上面这些经验总结下来,我形成了一个完整的 7 阶段工作流:
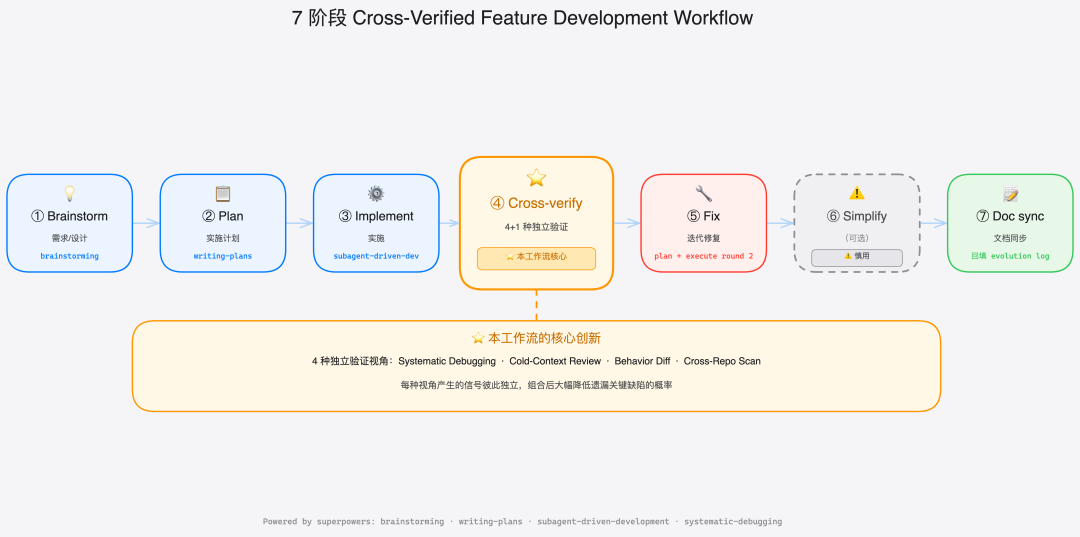
7 阶段工作流全貌
7 阶段工作流全貌
① Brainstorm → superpowers:brainstorming 需求/设计
② Plan → superpowers:writing-plans 实施计划
③ Implement → superpowers:subagent-driven-development 实施
④ Cross-verify → 4+1 种独立验证 ⭐ 核心创新
⑤ Fix → writing-plans + executing 再走一遍
⑥ Simplify → 带怀疑的优化(可选)
⑦ Doc sync → 回填 evolution log
前 3 个阶段委托给 superpowers 生态。Phase 4 是本工作流的核心贡献。Phase 5 只在 Phase 4 发现问题时才触发。Phase 6 是可选的优化环节,但最危险——很多生产事故不是写代码写出来的,是"优化"优化出来的。Phase 7 是知识的回填,防止半年后代码和文档互相打架。
每个阶段的心态完全不同:
- Phase 1-2:系统性思考,把模糊需求变成可执行 task
- Phase 3:小步慢跑,每个 task fresh context,不积累 bias
- Phase 4:刻意制造独立性,不让 reviewer 被你的思路污染
- Phase 5:按严重性分批,每个修复独立 commit 便于回滚
- Phase 6:怀疑一切简化冲动(详见下一节的翻车案例)
- Phase 7:诚实记录失败,教训比成功更有价值
最值得分享的 3 个翻车案例
多义字段陷阱:ReferenceId 的 PaymentID 泄漏
这是 Phase 6 的教训,也是这次最惊险的一次。
项目里有一张表有字段 (reference_type, reference_id):
reference_type = "refund" → reference_id 存退款单号
reference_type = "payment" → reference_id 存支付单号
我只看过主路径(退款场景),以为 reference_id 就是退款单号。Phase 6 简化时我想把一段缓存代码删了,改成"直接从 reference_id 字段读"。所有测试都过,性能还更好。
幸好同事一眼看出来:在少补(top-up)场景下,reference_id 存的是 PaymentID。简化后的代码会把 PaymentID 作为 refund_id 返回给下游。下游用错误的 ID 去做退款查询,会引发连锁故障。当场 git revert。
教训是——简化前对每个"看似冗余"的字段 / 缓存 / 变量问自己:
- 这个值源头是什么?(RPC 返回值?计算结果?外部输入?)
- 如果用 DB 字段代替它,那个 DB 字段还可能被谁写?
- 那个 DB 字段的类型语义是唯一的,还是依赖另一个字段?
- 你无法确定某个写入路径的语义时,就不要简化。
APPLIED 并发 race:锁粒度不足
Phase 4.2 cold-context reviewer 找出的第一个 Critical。
原设计加了分布式锁,但只加在 MODIFYING 状态(重试入口)——我当时想"首次执行不会并发"。
Reviewer 一眼看穿:两个并发的首次请求都能读到 APPLIED 状态,都执行无条件的 UPDATE status='modifying' WHERE id=?——都成功,各自走全量副作用,导致重复退款 + 重复建履约单。
修复方案:锁提到入口,覆盖 APPLIED 和 MODIFYING 两个分支;APPLIED→MODIFYING 转换加 CAS WHERE id=? AND status='applied' 作为 DB 层 defense-in-depth。
教训:对每个锁问"它覆盖哪些状态转换?"——如果某个状态也会并发(哪怕你"觉得不会"),就必须覆盖。"觉得不会并发"往往是错的。
UnlockOrder 其实不幂等
Phase 4.2 找出的另一个 Critical。
我写 Path B retry 逻辑时调用了现有的 UnlockOrderForAmend RPC,假设它"应该幂等"。实际它的底层 SQL 是:
UPDATE order_basic SET amendment_status=0
WHERE order_id=? AND amendment_status=1 AND pending_amendment_no=?
然后代码检查 RowsAffected > 0,否则报错。
第一次调用成功后,amendment_status 已经变成 0。第二次调用(retry 场景):
- UPDATE 匹配 0 行
RowsAffected = 0- RPC 返回错误
结果:retry 永远失败,订单永久卡死在 MODIFYING 状态。
修复方案:在调用方做预检查——先 GetOrderBasicByOrderID,如果 amendment_status == 0 || pending_amendment_no != our_amendment_no,说明已经解锁了(或是别人的锁),跳过调用。
教训:对每个 retry 路径调用的 RPC / SQL,要读它底层实现,不能只看接口签名。特别关注 WHERE 子句是否依赖前置状态、RowsAffected 是否被当作错误信号。
把工作流沉淀成 Skill
这套工作流如果只留在我脑子里,价值有限。我用 skill-creator 把它做成了一个 Claude Code skill,其他团队成员只需要安装、然后说 /cross-verified-workflow <需求> 就能复用。
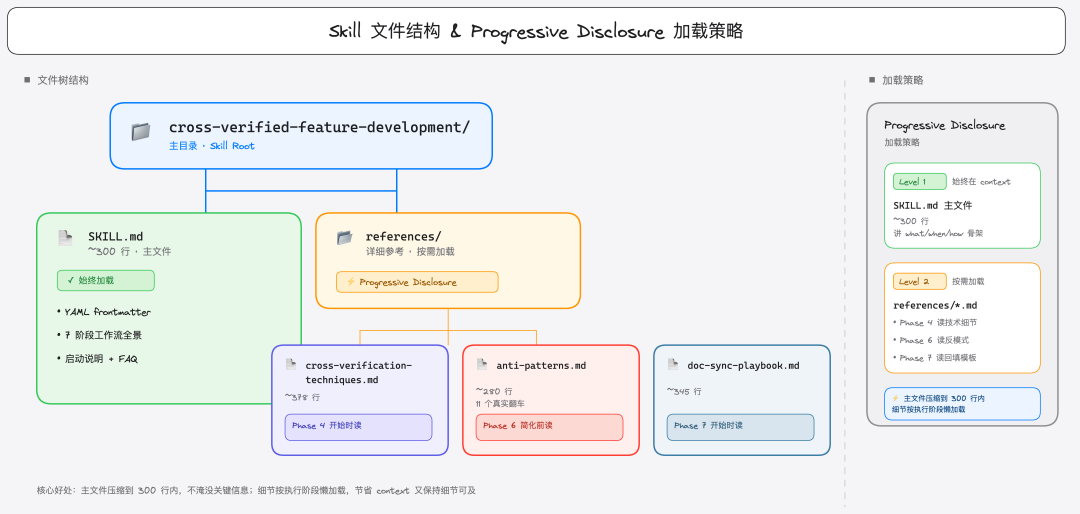
Skill 文件结构和加载策略
Skill 文件结构和加载策略
目录结构:
cross-verified-feature-development/
├── SKILL.md # 主文件(~300 行)
│ ├── YAML frontmatter (name + description)
│ ├── 7 阶段工作流全景
│ ├── 与 superpowers 生态的协作关系
│ └── 启动说明 + 常见问题
└── references/ # 详细参考文件(按需加载)
├── cross-verification-techniques.md # ~378 行,4+1 种验证技术 + prompt 模板
├── anti-patterns.md # ~280 行,11 个真实翻车案例
└── doc-sync-playbook.md # ~345 行,Phase 7 doc 回填模板
Progressive disclosure(渐进式加载)是核心设计:
- SKILL.md 主文件始终在 Claude 的 context 里——压缩到 300 行内,只讲 what / when / how 的骨架
references/*.md按需加载——Phase 4 开始时才读 cross-verification-techniques,Phase 6 简化前才读 anti-patterns
避免一次性塞满 context 把关键信息淹没。这也是 skill 生态的精妙之处:不用把所有细节全部塞进主文件,Claude 会根据当前阶段自动决定读哪些 reference。
SKILL.md 的 description 字段是触发机制。我写得相当具体:
description: 严谨多轮交叉验证的通用特性开发工作流。
适用于任何"失败代价高、bug会造成资金损失/数据损坏/
生产事故/业务卡单"的复杂特性开发。当用户的任务涉及
以下任一信号时,即使没有显式要求...,也应主动建议本工作流:
并发控制/分布式锁/数据一致性/幂等重试/
状态机改造/资金/库存/权限/订单等关键业务流程/...
这样 Claude 能在用户说"我要做一个改单幂等"时主动想起这个 skill,而不是只等 /cross-verified-workflow 显式触发。描述越具体,触发越准;越模糊,要么全触发要么不触发。
打包分发也很简单。skill-creator 自带打包脚本:
python -m scripts.package_skill ~/.claude/skills/cross-verified-feature-development /tmp/
# 生成 /tmp/cross-verified-feature-development.skill (24KB)
这个 .skill 文件是个 zip 包,接收方 unzip 到 ~/.claude/skills/ 就能用。也可以扔到内部 Git 仓库,整个团队 clone + 软链接到个人 skills 目录,配合 git pull 就能同步迭代。
实战建议:什么时候用这套工作流
不是所有特性都值得上这套流程。它有显著的额外成本——大约让总工作量增加 40-60%。
这是一套复杂系统重构和特性开发才适合的 skill,记住一定是复杂特性!
值得用:任何一句话能回答"这个 feature 最坏的 bug 会造成什么?"而且答案包含资金损失 / 数据错乱 / 订单卡死 / 权限越权 / 生产事故之一。
典型场景:
- 支付、退款、结算、优惠券核销
- 订单状态机、改单、售后、履约
- 库存扣减、预占、跨仓调拨
- 权限、授权、鉴权、合规
- 分布式锁、幂等重试
- 跨微服务的新接口、异步消息
- 核心数据模型或 proto 协议重构
- 在线 DDL、数据迁移、双写切换
不值得用:
- 纯 UI / 前端展示调整
- CRUD 无状态机语义
- 一次性数据处理脚本
- 修个小 bug
- 总工作量 < 1 人日
判定启发式:把"如果这段代码出 bug,会怎样"写成一句话。如果这句话让你不敢 merge,就上这套流程。如果后果不严重,走简单工作流就行。
常见问题
这套工作流主要是靠 Claude 还是靠人?
主要靠 Claude + superpowers 生态做具体执行,人做判断和决策。7 阶段每一阶段都由 Claude / agent 主导(写 spec、写 plan、写代码、跑 review),人决定是否采纳、何时进入下一阶段、发现偏离时怎么修正。人的价值在判断力和领域知识,不是写代码。
Cold-context reviewer 是怎么找出那么多 bug 的?它比 Claude 本体更厉害吗?
不是更厉害,是信息更少但更独立。它拿到的只有代码 diff 和一句话目标,没有设计文档。所以它不会被"作者相信系统应该如何工作"带偏,只看代码实际在做什么。这种"无先验"状态反而能挖出设计本身的漏洞。
Phase 6 的"谨慎简化"和 Phase 4-5 的修复有什么区别?为什么要单独拎出来?
Phase 4-5 修的是"已经发现的问题"。Phase 6 是"代码看起来已经 OK 了,但你想进一步优化 / 简化"。这两个心态完全不一样——Phase 6 发生在你最自信的时候,而"最危险的时刻就是你感觉最自信的时候"。大多数"简化引入的 bug"都是这时候发生的,所以单独拎出来强制提醒"慢一点"。
把工作流做成 skill 的核心好处是什么?
三个好处:(1) 同事不需要学整套方法论,只要说 /cross-verified-workflow 就自动走流程;(2) 知识固化下来不会随团队变动流失;(3) 方法论本身可迭代——改 skill 等于改整个团队的工作流,改一次全员受益。
我的团队还没用 Claude Code,能用这套吗?
工作流本身是独立的,可以不依赖 Claude。核心是独立视角交叉验证这个思路——你可以用真人 reviewer 代替 agent,只是成本更高、更慢。真正独特的是 skill 化——没有 Claude Code 就只能用纸面流程,触发和复用都会笨重很多。
我的判断
Claude Code 最被低估的用法不是"让它更快写代码",而是编排它进入严谨的工程流程。
AI 写代码的能力已经超过大多数人能有效审查的速度。瓶颈不在"写",在"验证"。而验证是可以被系统化、skill 化、团队化的。
我把这套工作流固化成 skill 之后,下次做关键特性我不用再记流程——Claude 带着我走。
我的同事也不用被动 onboard——他们拿到 skill 文件一键安装。方法论的迭代和代码的迭代一样,可以被 git 管理、被 PR review、被团队共建。
这比"我学会了某个 prompt 模板"高一个维度。
我把这个 skill 的完整源码、这次踩坑的所有设计文档和修复 plan 都整理好了,下一篇打算写「冷上下文 reviewer 找出的 10 个 Critical Bug 的详细复盘,每个 bug 附上原始 prompt 和修复 commit」,关注一下,发了第一时间推送。
如果你身边有人在做涉及并发、资金、状态机以及复杂系统的架构设计的特性,这篇可以直接甩给他,省得他也像我一样踩一遍。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号