让AI习得药化直觉:基于匹配分子对变换的可扩展类似物设计新范式

让AI习得药化直觉:基于匹配分子对变换的可扩展类似物设计新范式

DrugIntel
发布于 2026-04-21 11:12:56
发布于 2026-04-21 11:12:56

论文信息
- • 标题:Scalable and Generalizable Analog Design via Learning Medicinal Chemistry Intuition from Matched Molecular Pair Transformations
- • 作者:Hao-Wei Pang*, Peter Zhiping Zhang*(共同一作), Bo Pan, Liang Zhao, Xiang Yu, Liying Zhang
- • 机构:Merck & Co., Inc.(默克); Emory University 计算机科学系
- • 发表平台:ChemRxiv 预印本(DOI: 10.26434/chemrxiv.15001722/v1)
- • 发表时间:2026年4月7日
目录
- 1. 研究背景与动机
- 2. 核心概念:MMP vs. MMPT
- 3. 方法论:模型架构与训练策略
- 4. 实验设计:基准、任务与评估体系
- 5. 主要结果与深度分析
- 6. 生成分子的性质分析
- 7. 局限性与未来方向
- 8. 参考文献精选
1. 研究背景与动机
1.1 药物化学类似物设计的核心挑战
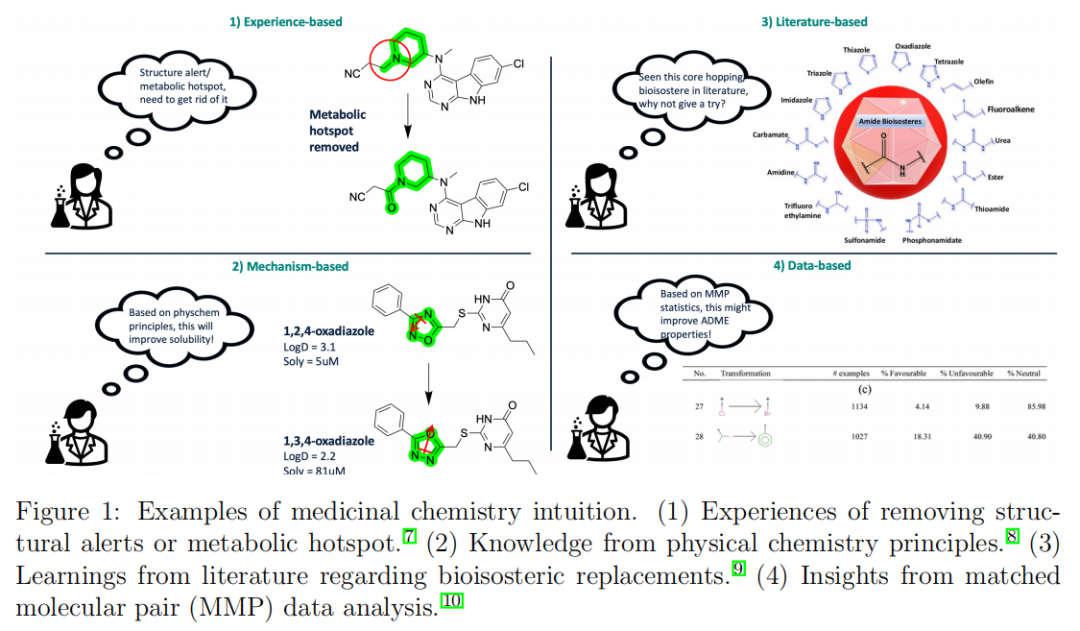
新药研发的命中物到先导物(hit-to-lead)和先导物优化(lead optimization)阶段,药物化学家需要系统性地对活性分子进行结构修饰,以在效力(potency)、选择性(selectivity)、药代动力学(PK)、安全性和可开发性之间寻求最优平衡。这一过程通常遵循"设计-合成-测试-分析"(DMTA)迭代循环。
每一轮结构修饰的决策,依赖的不仅是知识,更是药化直觉(medicinal chemistry intuition)——这是个人在多个项目、多种靶点、跨越数年甚至数十年积累而成的隐性知识体系。其具体表现包括:
- • 经验性知识:识别并消除代谢热点(metabolic hotspot)或结构警报(structural alert)
- • 机制性知识:根据物理化学原理(如logD与溶解度的关系)预判修饰效果
- • 文献性知识:基于已知生物电子等排体(bioisostere)开展骨架跃迁(scaffold hopping)
- • 数据驱动直觉:从MMP统计分析中识别改善ADME性质的有利变换
1.2 现有AI方法的核心缺陷
当前用于分子类似物生成的生成模型可分为两大类:
全分子类似物生成(whole-molecule analog generation):模型以分子A为输入,直接输出结构相似的分子B。代表性方法包括基于变分自编码器(VAE)的图生成模型(如Junction Tree VAE)和基于Transformer的分子翻译模型。该类方法的缺陷在于对修饰位置缺乏显式约束,生成结果的化学可解释性较弱。
变量级生成(variable-level generation):模型在用户指定位点上提出修饰方案,代表性方法有REINVENT 4中的LibINVENT(R基修饰)和LinkINVENT(连接子生成)。
上述两类方法均依赖MMP实例(即具体的分子对)作为训练数据,由此引入了根本性偏差:训练数据的变换频率分布严重不均。历史数据中,卤素替换、甲基化等常见操作拥有数万个实例,而罕见但化学价值极高的核心骨架变换可能仅出现数次甚至从未出现。导致现有模型对高频变换能很好地泛化,而对低频变换几乎完全失效——恰恰是在新药研究中最需要突破的区域。
1.3 本文的核心假设
核心假设:匹配分子对变换(Matched Molecular Pair Transformations, MMPTs),而非单个MMP实例,才是药化直觉的基本单元。
将变换从具体分子上下文中解耦,使其成为独立的学习对象,可以:
- 1. 消除上下文噪声,提炼可复用的结构修饰模式
- 2. 避免性质学习偏差,专注于编码变换本身的化学合理性
- 3. 天然支持跨项目、跨靶点迁移,实现变换先验的上下文无关复用
2. 核心概念:MMP vs. MMPT
2.1 匹配分子对(MMP)的定义与局限
定义:MMP是一对化合物(分子A与分子B),两者仅在一个明确定义的子结构处存在差异——即共享相同的"常数"(constant)部分,仅在"变量"(variable)子结构上不同。变量可以是R基(R-group substitution)或骨架(core hopping)。
形式表示:
MMP = (Molecule A, Molecule B)
其中 Molecule A = Constant C + Variable A
Molecule B = Constant C + Variable BMMP的价值:由于MMP来源于真实合成并经过化学家隐性筛选的分子,其变换具有天然的合成可行性背书;同时,变量差异通过合成可及的键连接,生成分子更易于合成。
MMP的根本局限:
- • 同一个变换(如 H→CH₃ 的甲基化)可能在数万个不同常数结构上出现,每次都作为独立的训练实例
- • 不同常数下的同一变换被视为不同样本,引入大量冗余的"上下文噪声"
- • 模型难以将同一变换的化学本质从其多变的分子背景中分离
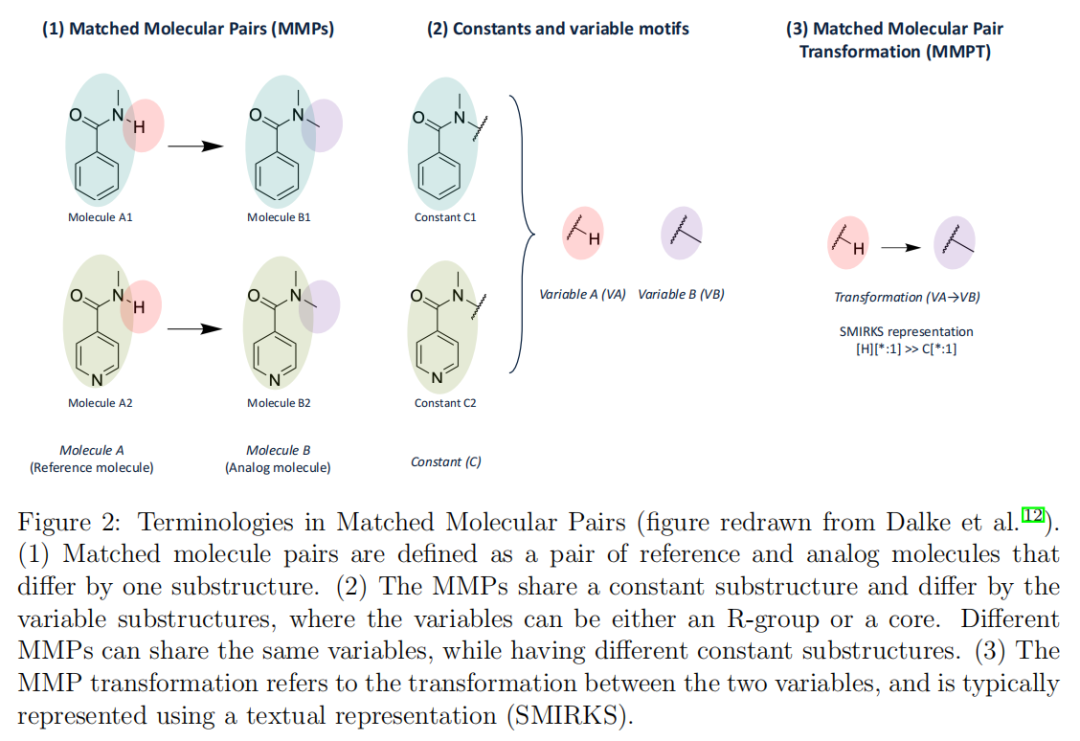
2.2 匹配分子对变换(MMPT)的定义
定义:MMPT是从MMP中提取的、独立于常数结构的变换本体,即变量A到变量B的映射关系,通常以SMIRKS格式表示。
SMIRKS示例:
[H][*:1] >> C[*:1]此SMIRKS表示将一个氢原子替换为甲基,是最经典的甲基化变换。
关键区别对比:
维度 | MMP实例 | MMPT |
|---|---|---|
训练单元 | 分子A→分子B对 | 变量A→变量B变换 |
上下文依赖 | 强(依赖全分子或常数结构) | 无(完全上下文无关) |
数据规模(本研究) | ~263万条 | ~80万条(去重后) |
频率偏差 | 严重 | 大幅缓解 |
跨系列迁移能力 | 弱 | 强 |
化学可解释性 | 较好 | 更直接(SMIRKS明确) |
去重逻辑:MMPT-FM的训练数据对变换进行了上下文无关的去重——同一个变换无论出现在多少个不同常数结构的MMP中,只保留一条。这使得80万条MMPT涵盖了与263万条MMP相同的变换多样性,却消除了上下文重复带来的频率偏差。
3. 方法论:模型架构与训练策略
3.1 训练数据的构建流程
数据来源:ChEMBL数据库,使用MMPDB工具进行MMP提取。
数据预处理流程:
- 1. 以Walters结构警报列表进行过滤,去除含有结构警报的化合物
- 2. 采用medchem包的"类药软标准"(rule of druglike soft)进行类药性筛选
- 3. 限制分子量 ≥ 200 Da
- 4. MMP提取参数:
max-variable-ratio = 0.33(变量部分不超过分子重原子数的33%) - 5. 构建MMPT:从MMP中提取变量对,按上下文无关方式去重
数据质量验证:研究者发现,未经结构警报过滤的模型在输入含有结构警报的分子时,其生成物也大概率含有结构警报;而过滤后训练的模型,>90% 的情况下能生成不含结构警报的分子,甚至能学会主动"消除"结构警报——这正是药化先导优化中的核心任务之一。
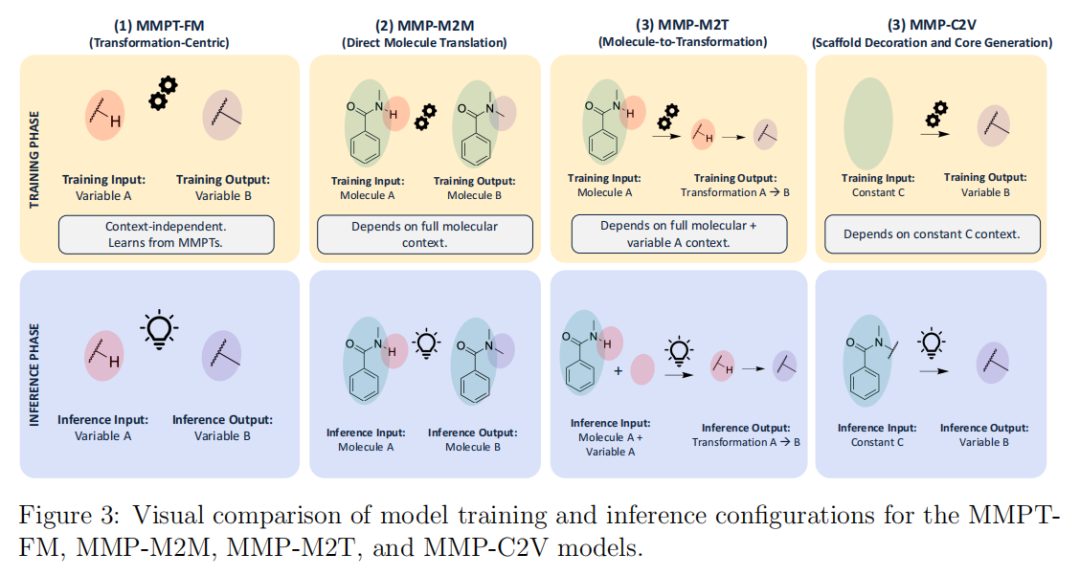
3.2 各模型的训练范式对比
本研究在相同底层数据上训练了四个模型变体,形成严格的对照实验:
MMPT-FM(本文核心模型)
训练输入:Variable A(变量A的SMILES)
训练输出:Variable B(变量B的SMILES)
上下文依赖:无
学习对象:MMPT(变量间变换)
训练数据:~80万条独特MMPTMMP-M2M(分子到分子直接翻译)
训练输入:Molecule A(完整分子SMILES)
训练输出:Molecule B(完整分子SMILES)
上下文依赖:完整分子上下文(隐式)
对应参照:类REINVENT4 mol2mol模块
训练数据:~263万条MMPMMP-M2T(分子到变换)
训练输入:Molecule A + Variable A(分子+变量联合输入)
训练输出:变换 Variable A → Variable B
上下文依赖:完整分子+变量A(显式)
特点:需要用户提供变量A作为解码头
训练数据:~263万条MMPMMP-C2V(常数到变量)
训练输入:Constant C(常数骨架SMILES;多片段用"."连接)
训练输出:Variable B(R基或核心变量)
上下文依赖:常数结构(显式)
对应参照:类REINVENT4 LibINVENT+LinkINVENT
训练数据:~263万条MMP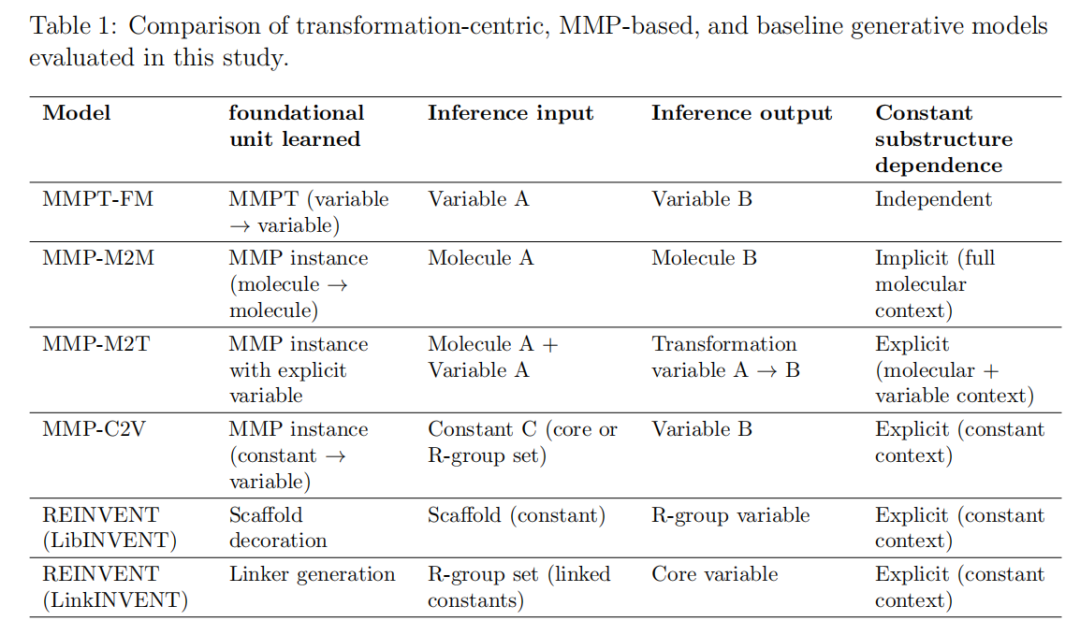
3.3 模型架构与训练细节
骨干网络:编码器-解码器Transformer(T5架构),基于ChemT5预训练权重进行微调。ChemT5是在大规模化学语料上预训练的多任务语言模型,已具备对分子表示语言(SMILES、SMIRKS等)的语法理解能力。
训练超参数:
- • 批大小(batch size):64
- • 学习率(learning rate):5×10⁻⁴
- • 训练策略:带teacher forcing的监督学习,交叉熵损失(cross-entropy loss)
- • 收敛判据:在验证集上的性能达到最优的checkpoint
推理策略:束搜索(beam search),每个输入生成1000个候选输出,最大序列长度250个token。
计算资源:
- • MMPT-FM:4×NVIDIA A6000 GPU
- • MMP-M2M/M2T/C2V:4×NVIDIA H100 GPU(M2M需重建完整分子,M2T因显式变量解码头GPU显存需求更高)
4. 实验设计:基准、任务与评估体系
4.1 评估任务设计
本研究选用PMV Pharmaceuticals的两个真实药物研发专利构建评估任务,这是该领域罕见的、面向工业界真实场景的严格测试。
任务一:专利内类似物生成(Within-patent,pmv17)
- • 专利:WO2017143291A1(2017年,867个分子)
- • 靶点:突变型p53蛋白,恢复p53与DNA结合及激活下游肿瘤抑制通路的能力
- • 任务描述:给定专利内已知分子,模型能否快速提议更多符合同一化学系列设计意图、值得纳入同一专利族的候选物?
- • 核心考察:局部化学空间探索能力,即在已知化学系列的近邻区域中高效采样
任务二:跨专利类似物生成(Cross-patent,pmv17→pmv21)
- • 源专利:WO2017143291A1(PMV 2017)
- • 目标专利:WO2021061643A1(PMV 2021)
- • 任务描述:以2017年专利的分子为出发点,模型能否预测出2021年后续专利中实际出现的化学进化方向?
- • 核心考察:前瞻性泛化能力,即超越原始专利系列、预测未来化学空间演化的能力
4.2 MMPT提取方法
对pmv17专利内分子及pmv17→pmv21分子对,同样使用MMPDB提取MMPTs,形成评估集。重要细节:pmv17 MMPT提取使用与训练数据相同的MMPDB参数,确保变换粒度的一致性,避免评估-训练不对齐。
4.3 评估指标
主要指标:召回率(Recall)
模型生成中覆盖的真实变换数评估集中真实变换总数
辅助分析维度:
- 1. 按变换类型:R基替换 vs. 核心跃迁
- 2. 按训练频率:将pmv17变换按其在ChEMBL训练数据中的出现频率分为6个区间(0次、1-10次、11-100次、101-1000次、1001-10000次、10001+次)
- 3. 按变量相似性:计算变量A和变量B之间的Tanimoto相似度(基于count-based Morgan指纹),分为[0.0-0.2]、[0.2-0.4]、[0.4-0.6]、[0.6-0.8]、[0.8-1.0]五个区间
- 4. 按样本数量:召回率作为生成样本数(100/500/1000/2000)的函数,衡量采样效率
- 5. 物理化学性质分布:生成变量的重原子数、HBA、HBD、可旋转键数、芳香氮数、碳芳香环数
5. 主要结果与深度分析
5.1 总体性能:两种任务场景下的全面对比
专利内生成(pmv17)
模型 | R基替换召回(N≈5028-3704) | 核心跃迁召回(N≈4433-2275) |
|---|---|---|
MMPT-FM | ~60%(最优或并列最优) | ~63%(最优) |
MMP-M2M | ~50%(第二) | ~55%(第二) |
MMP-C2V | ~40%(第三) | ~47%(第三) |
MMP-M2T | ~25%(最差) | ~20%(最差) |
REINVENT | ~63%(R基,与MMPT-FM接近) | 0%(核心跃迁完全失败) |
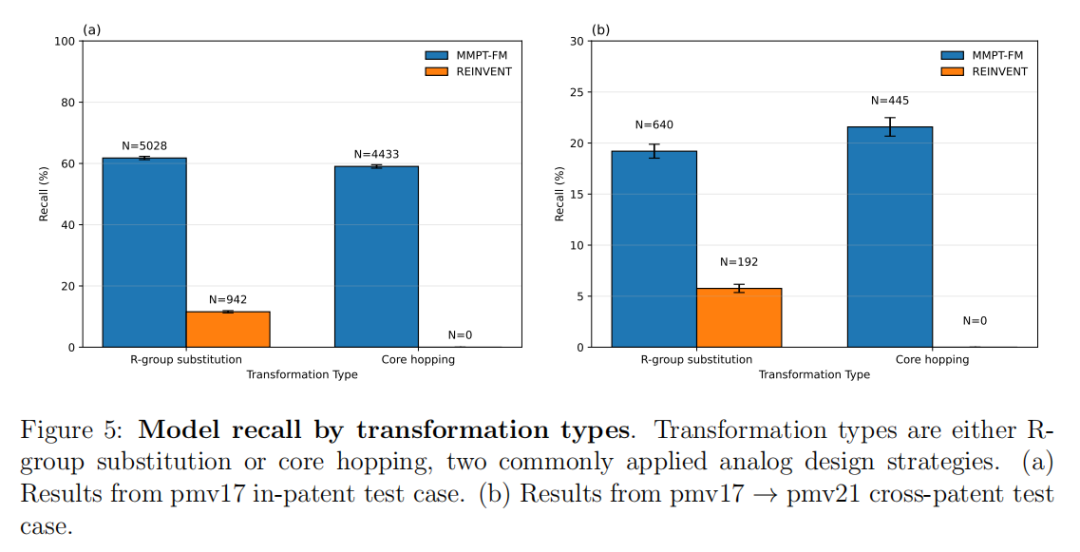
关键发现:REINVENT的LibINVENT在R基替换任务上表现与MMPT-FM相当,但其LinkINVENT模块在核心跃迁任务上完全失效(召回率为0),原因在于LinkINVENT被设计用于连接子生成而非核心跃迁,且其词汇表不含溴原子。这一结果揭示了专用模块方法的根本局限:无法统一处理不同类型的变换任务。
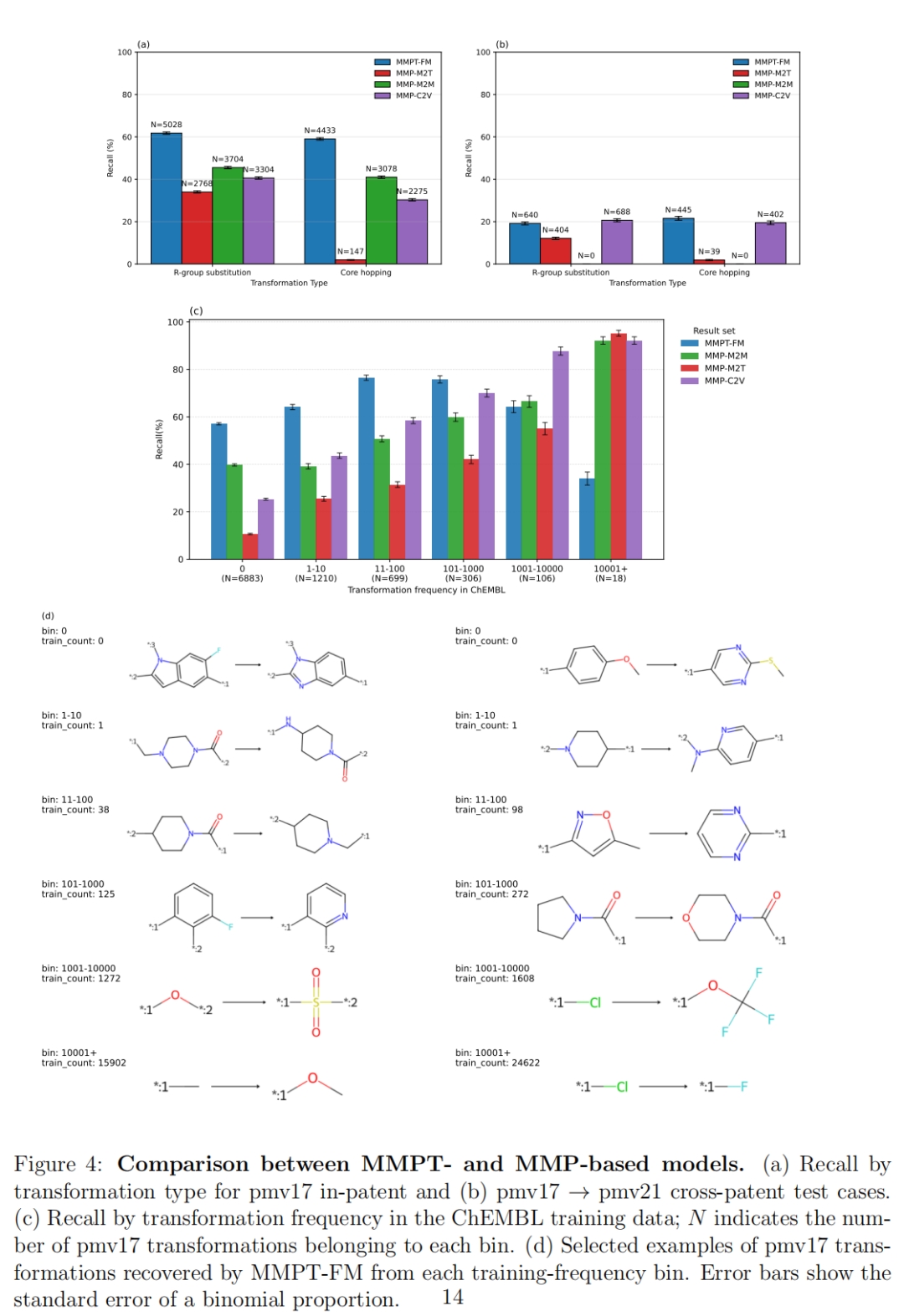
跨专利生成(pmv17→pmv21)
模型 | R基替换召回(N≈640-404) | 核心跃迁召回(N≈688-402) |
|---|---|---|
MMPT-FM | ~20%(最优) | ~22%(最优) |
MMP-C2V | ~17%(第二) | ~19%(第二) |
MMP-M2T | ~15%(第三) | ~13%(第三) |
MMP-M2M | ~5%(最差) | ~8%(第三-四) |
REINVENT | ~7%(R基) | 0%(核心跃迁) |
重要反转:MMP-M2M在专利内任务中排名第二,但在跨专利任务中排名最差。这说明全分子翻译模型虽然能够记忆已见的分子上下文,但跨化学系列泛化能力严重不足——恰恰是前瞻性创新所最需要的能力。
5.2 变换频率分析:长尾能力的决定性差异
这是本研究最具洞察力的分析之一。pmv17评估集中的变换按ChEMBL训练频率分布如下:
频率区间 | pmv17变换数 | MMPT-FM召回 | MMP-M2M召回 | MMP-M2T召回 | MMP-C2V召回 |
|---|---|---|---|---|---|
0次(从未见过) | 6,883 | ~58% | ~40% | ~8% | ~25% |
1-10次 | 1,210 | ~63% | ~45% | ~15% | ~40% |
11-100次 | 699 | ~70% | ~60% | ~25% | ~42% |
101-1000次 | 306 | ~75% | ~65% | ~38% | ~55% |
1001-10000次 | 106 | ~78% | ~68% | ~42% | ~62% |
10001+次 | 18 | ~95% | ~95% | ~58% | ~92% |
核心洞察:
- 1. 从未出现(0次)的变换占pmv17评估集的75%以上(6883/9222),这意味着绝大多数真实药物研发中的分子操作,在训练数据中从未直接出现
- 2. 所有MMP模型均呈现清晰的频率偏差:召回率随频率近似线性-对数增长
- 3. MMPT-FM在0次区间的召回率(58%)远高于MMP-M2T(8%),差距高达50个百分点
- 4. 这证明变换中心学习(transformation-centric learning)能够真正实现对罕见变换的泛化,而非对已见变换的记忆
为什么MMPT-FM能召回"从未见过"的变换?
尽管某个具体的SMIRKS变换在训练集中频率为0,但MMPT-FM学到了更深层的化学结构规律。模型学到的不只是"哪些变换出现过",而是"变量结构的化学语法"——它能够从已见的相关变换中外推到未见的合理变换,类似于人类药化学家从类比和化学原理中举一反三的能力。
5.3 变量相似性分析:从常规到非常规的修饰
高相似度区间(Tanimoto > 0.6):
- • 代表常规、经典的药化操作:同分异构体变换(regioisomerism)、卤素替换(F/Cl/Br互换)等
- • 所有模型均能较好召回,MMPT-FM保持领先但差距较小
- • 这类变换属于"教科书式"直觉,任何基于MMP的模型都能从大量训练实例中学会
低相似度区间(Tanimoto < 0.2):
- • 代表非常规、高创意的药化操作:极性杂环替换为芳香环(大幅改变极性和氢键模式,常用于解决溶解度问题)、甲基替换为芳香环(引入π-π堆叠)
- • MMPT-FM在此区间保持较高召回,MMP模型则大幅下滑
- • 跨专利设置下,低相似度区间的召回率所有模型均有所下降,反映了前瞻性泛化对罕见、非经典编辑的固有难度
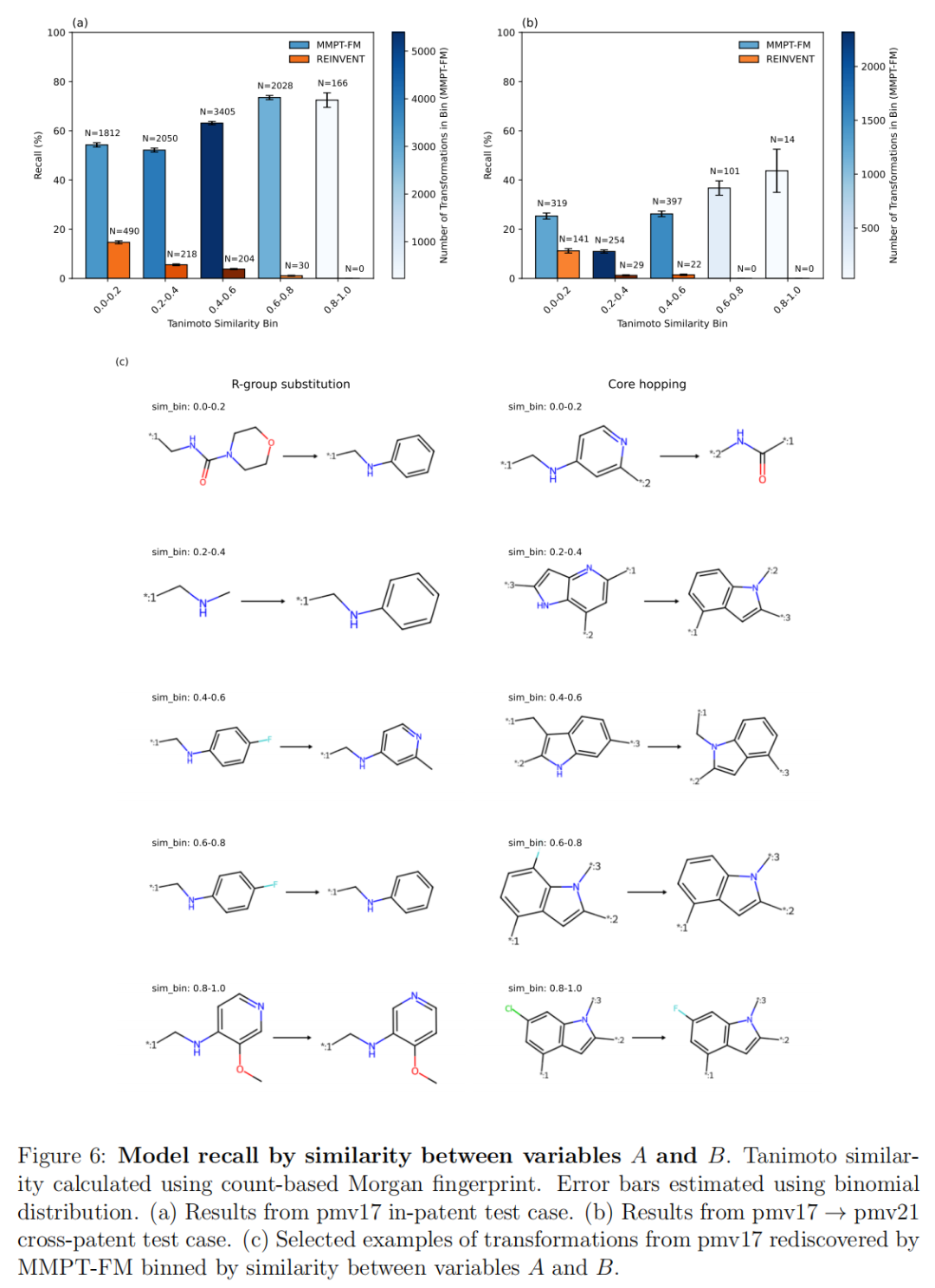
关键意义:药物研发中真正创造价值的突破往往来自低相似度变换——这正是专利差异化和化学空间拓展的核心所在。MMPT-FM在此区间的优势,直接对应于其在创新性先导优化中的实际价值。
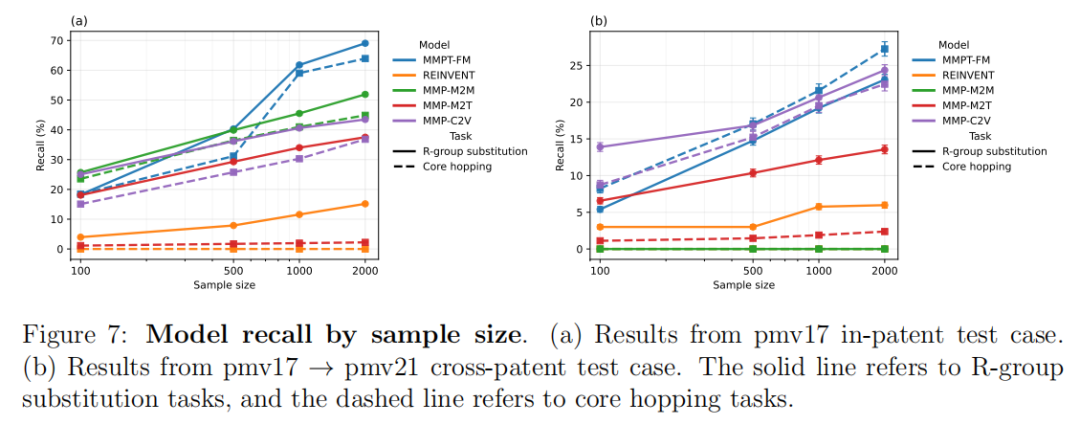
5.4 采样效率:样本数-召回率曲线
所有模型均呈现线性-对数的样本数-召回率关系,即:召回率随样本数的对数值近似线性增长,边际收益递减。
MMPT-FM的斜率优势:在相同的样本数下,MMPT-FM的召回率增长斜率更陡,表明其化学空间探索效率更高——用更少的生成次数覆盖更多的真实变换。这对计算成本敏感的工业应用尤为重要:1000个样本的MMPT-FM往往等效于2000个样本的MMP模型。
5.5 变换类型:R基替换 vs. 核心跃迁
核心跃迁(core hopping)是药物化学中"高风险高回报"的策略:
- • 回报:骨架与知识产权格局强相关,跃迁可规避专利壁垒;同时可解决代谢问题、提升可开发性、探索新化学空间
- • 风险:需保持效力,必须找到维持三维几何、静电相容性、芳香性和刚性的合适生物电子等排体
MMPT-FM在核心跃迁(≥2个连接位点的变换)和R基替换上取得了可比的召回率,而REINVENT的LinkINVENT在核心跃迁上完全失效。这表明变换中心学习能够统一处理质量上不同的类似物设计策略,无需针对不同任务类型分别构建专用模块。
6. 生成分子的性质分析
6.1 物理化学性质分布
研究比较了输入变量、MMPT-FM生成变量、LibINVENT生成变量在六个关键性质上的分布:
性质 | 输入变量(均值) | MMPT-FM生成(均值) | LibINVENT生成(均值) |
|---|---|---|---|
重原子数 | 7.5 | 7.6 | 10.7 |
氢键受体数(HBA) | 1.6 | 1.8(+0.2) | 2.1 |
氢键供体数(HBD) | 0.6 | 0.5(-0.1) | 0.5 |
可旋转键数 | 1.3 | 1.3(持平) | 1.9 |
芳香氮数 | 0.3 | 0.6(+0.3) | 0.4 |
碳芳香环数 | 0.3 | 0.3(持平) | 0.4 |
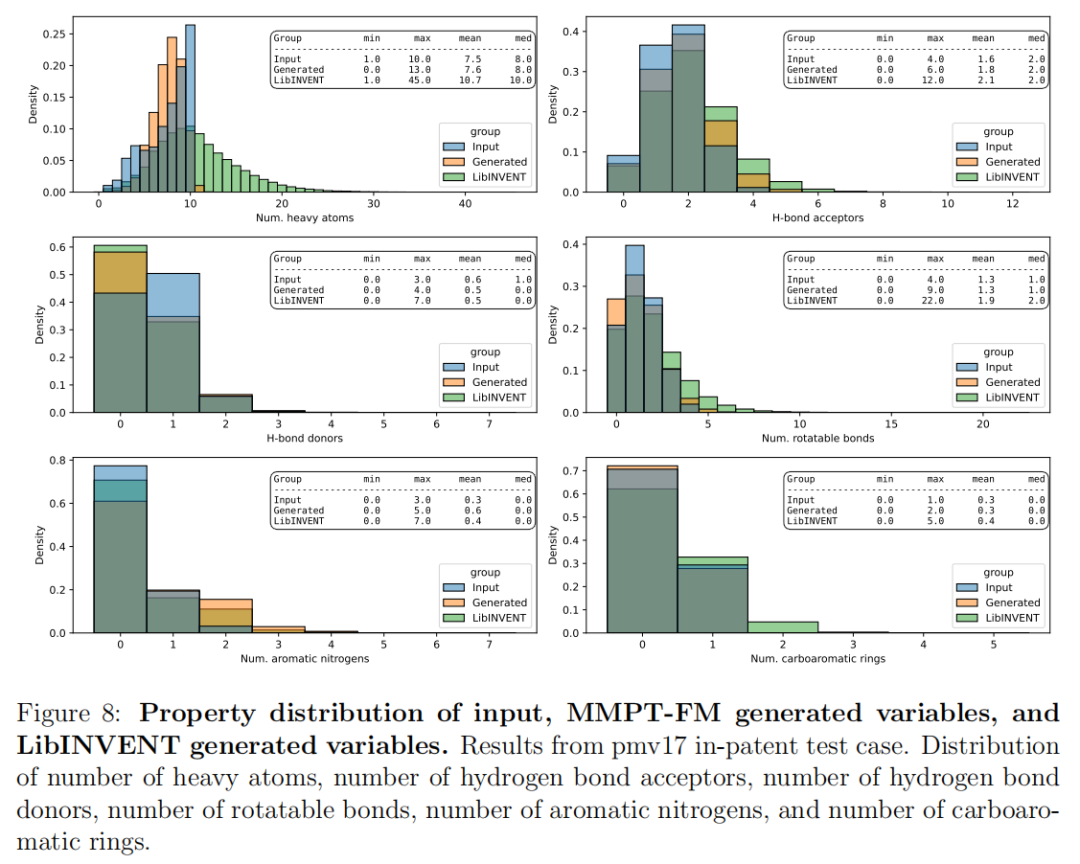
6.2 性质漂移的药化意义
MMPT-FM生成变量相对于输入呈现的性质偏移,与当代成功药物优化的规律高度吻合:
HBA轻微增加(+0.2):增加氢键受体可提升极性,降低logD,从而减少脱靶效应(如对PXR的激活、hERG抑制等)。这是药化团队在ADME优化中的常规操作。
HBD轻微减少(-0.1):减少非必要的氢键供体是改善膜通透性和口服生物利用度的经典策略。过多的HBD是"超越Lipinski空间"的主要障碍。
可旋转键数保持不变:维持输入分子的刚柔性特征,意味着模型不会无节制地引入软链结构,保持了分子的构象可控性。
芳香氮数增加(+0.3):用含氮杂环替代碳芳香环是近年来成功优化中的显著趋势(Leeson 2026年综述明确指出),有利于改善溶解度、降低代谢清除率,同时维持生物活性所需的π体系。
LibINVENT对比:LibINVENT生成的变量明显更大(重原子数均值10.7 vs. 7.6)、可旋转键更多(1.9 vs. 1.3),这意味着其生成物更"胖"且更"软"——在先导优化的后期(需要精细调控分子大小和刚性)通常是不受欢迎的性质。
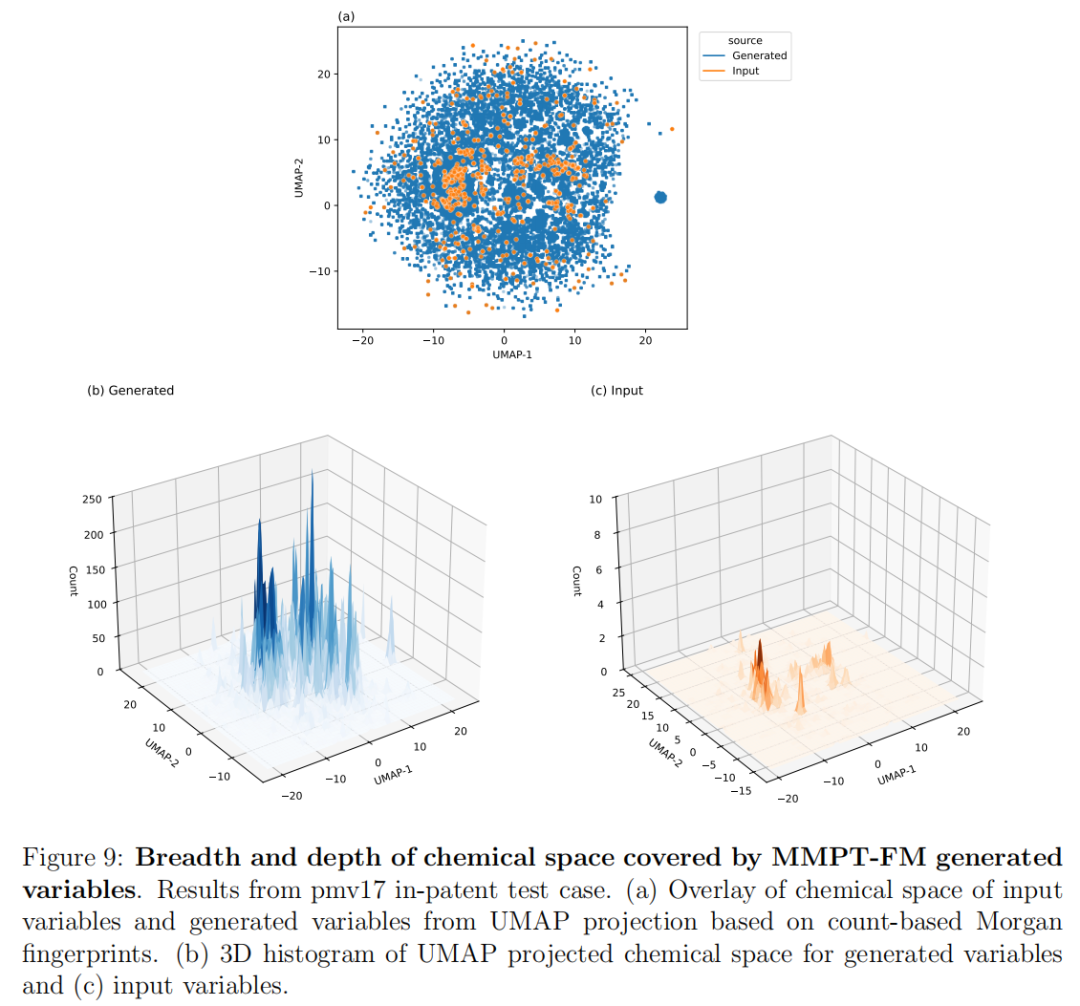
6.3 化学空间覆盖分析(UMAP可视化)
基于count-based Morgan指纹的UMAP投影显示:
- • 广度:MMPT-FM生成变量的化学空间覆盖远广于输入变量,探索了输入空间之外的多个区域
- • 深度:生成变量密集覆盖了输入变量所在的核心区域,实现了对原始化学系列的精细采样
- • 密度分布:生成变量的3D密度图(UMAP空间直方图)显示多个高密度峰,对应化学空间中的多个有意义的聚类;而输入变量的密度图则相对稀疏且均匀
这种"既广又深"的探索模式,正是药化先导优化所期望的:既能快速拓展化学多样性(横向),又能在已知活性区域精细优化(纵向)。
7. 局限性与未来方向
7.1 已识别的局限性
历史数据依赖:MMPT-FM在ChEMBL历史数据上训练,其变换知识边界受制于已有药化实践。对于全新化学类型(如周环反应产物、有机金属化合物等)的变换,模型可能表现不佳。
立体化学表示缺陷:当前SMIRKS变换格式不能完整捕捉立体化学信息(手性中心、顺反异构等)。在手性对活性至关重要的靶点(如蛋白激酶、GPCRs)中,这是一个实质性限制。
无多步编辑支持:模型仅支持单步变换,无法处理需要多处同时修饰的情况(如同时优化两个不同位置的R基)。
不直接优化分子性质:MMPT-FM本质上是一个无条件生成模型,生成的类似物反映历史数据中的隐含偏好,但无法针对特定效力、选择性或ADME指标进行定向优化。这限制了其在精确多目标优化任务中的直接应用。
无检索增强验证:先前工作(Pan等, arXiv:2602.16684)引入了检索增强的MMPT基础模型(RA-MMPT-FM),但本文未将其纳入对比,未来工作应评估检索增强对性能的进一步提升。
7.2 未来研究方向
- 1. 立体化学感知的MMPT表示:引入能够编码手性信息的扩展SMIRKS表示,或引入3D几何约束
- 2. 与性质预测/优化的集成:将MMPT-FM与多目标优化框架(如强化学习、贝叶斯优化)结合,实现定向的类似物生成
- 3. 私有数据的企业定制:基于企业内部历史数据(包含专有活性数据)对MMPT-FM进行微调,将数十年内部药化知识编码为专有竞争优势
- 4. 多步变换学习:扩展至序列变换(sequential transformations),支持复杂的多位点同步优化
- 5. 生成评估的扩展:引入合成可行性评分(SA score)、多目标成药性(Fsp³、QED)等维度,更全面评估生成质量
参考文献精选
以下列出本论文中方法论构建最直接相关的参考文献:
- 1. Dalke et al. (2018). mmpdb: An open-source matched molecular pair platform for large multiproperty data sets. J. Chem. Inf. Model., 58, 902–910.(MMPDB工具,MMP提取基础)
- 2. Griffen et al. (2011). Matched molecular pairs as a medicinal chemistry tool: miniperspective. J. Med. Chem., 54, 7739–7750.(MMP方法论奠基综述)
- 3. Loeffler et al. (2024). Reinvent 4: modern AI-driven generative molecule design. J. Cheminformatics, 16, 20.(REINVENT 4基线,含mol2mol/LibINVENT/LinkINVENT)
- 4. Pan, Zhang, Pang et al. (2026). Retrieval-Augmented Foundation Models for Matched Molecular Pair Transformations to Recapitulate Medicinal Chemistry Intuition. arXiv:2602.16684.(本文前置工作,RA-MMPT-FM)
- 5. Christofidellis et al. (2023). Unifying molecular and textual representations via multi-task language modelling. ICML 2023, pp. 6140–6157.(ChemT5预训练模型)
- 6. Choung et al. (2023). Extracting medicinal chemistry intuition via preference machine learning. Nature Communications, 14, 6651.(从问卷调查提取药化直觉的对照方法)
- 7. Tibo et al. (2024). Exhaustive local chemical space exploration using a transformer model. Nature Communications, 15, 7315.(全分子翻译类方法的最新进展)
- 8. Leeson (2026). What Happens in Successful Optimizations? A Survey of 2018–2024 Literature. J. Med. Chem.(芳香氮增加、碳芳香环减少趋势的证据来源)
编者按:本论文的核心贡献在于将一个看似简单的训练目标调整(从分子对到变换对)转化为系统性的性能提升,尤其在药物研发中最具挑战性的罕见变换和前瞻性泛化场景中展现出决定性优势。对于有意将AI深度融入药物化学研发流程的团队而言,这一工作提供了极具参考价值的方法论框架与工程实现路径。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号