在化学宇宙中寻找 美丽分子 :生成式 AI 药物设计的现状、挑战与未来

在化学宇宙中寻找 美丽分子 :生成式 AI 药物设计的现状、挑战与未来

DrugIntel
发布于 2026-04-21 11:08:11
发布于 2026-04-21 11:08:11
文献来源:van den Broek R L, Patel S, van Westen G J P, et al. In Search of Beautiful Molecules: A Perspective on Generative Modeling for Drug Design. J. Chem. Inf. Model. 2025, 65, 9383–9397. DOI:10.1021/acs.jcim.5c01203 作者单位:Leiden University(荷兰莱顿大学药学院)& Psivant Therapeutics(波士顿)
导读:为什么这篇文章值得认真读?
生成式 AI(Generative AI,简称 GenAI)正在以前所未有的速度改变各行各业。在制药领域,各大生物技术公司纷纷声称 AI 将颠覆药物发现——但临床成功的案例寥寥无几,绝大多数 AI 生成的分子依然止步于纸面。
这篇 2025 年发表于 Journal of Chemical Information and Modeling 的综述,由荷兰莱顿大学与美国 Psivant Therapeutics 联合撰写,是对"生成式 AI 药物设计(GADD)"领域系统、清醒的批判性总结。
论文的核心命题是:生成式药物设计的终极目标,是产出"美丽"分子——那些真正符合治疗目标、具备临床转化潜力的化合物。
本文将系统梳理这篇综述的主要内容,深入解析其核心论点,并结合领域背景进行延伸评述。
一、背景:GenAI 的浪潮与药物发现的落差
1.1 GenAI 的爆发式渗透
2021 年 DALL·E 发布、2022 年 ChatGPT 问世,标志着生成式 AI 进入大众视野。根据麦肯锡 2024 年初的全球调查,仅在 ChatGPT 发布两年后,65% 的企业已将生成式 AI 融入日常运营。营销、内容创作、软件开发、制造业原型设计……几乎每个行业都在投入资源开发专属生成模型。
1.2 药物发现领域的尴尬处境
然而,GenAI 在药物发现中的表现却明显滞后。尽管学术界发表了大量关于分子生成的论文,真正在前瞻性药物发现项目中体现出明确、可重复价值的案例却极为有限——以临床成功率衡量,GenAI 尚未显著改变药物研发的成功概率。
论文作者认为,这一落差的根源在于:大多数生成模型只是在优化数字指标,而非真正对齐治疗需求。
1.3 为什么需要"美丽分子"这一概念?
作者引用了诺贝尔化学奖得主 Roald Hoffmann 1990 年的经典论文《Molecular Beauty》:
"什么让分子美丽?也许是其简洁性,对称的结构;或是其复杂性,完成特定功能所需的丰富结构细节……新颖性、惊喜感、实用性同样在分子美学中扮演着角色。"
在药物发现的语境下,"美"不再是单纯的几何对称,而是合成实用性、分子功能和疾病改善能力的整体融合。一个美丽的药物分子,必须:
- • 在合理的时间和成本内可被合成
- • 在体内具备可接受的 ADMET(吸收、分布、代谢、排泄与毒性)性质
- • 对靶点有足够的选择性和亲和力
- • 具有清晰的临床转化路径
二、化学空间的规模与虚拟筛选的局限
2.1 为什么 GenAI 是必要的?
一个常见的质疑是:超大规模虚拟筛选库(ultra-large virtual library)能否替代生成式设计?
目前最大的化合物虚拟库(如 GDB-17 和 Enamine REAL Space)已达 10¹⁰ 至 10¹¹ 量级。但相比于理论上可能存在的类药化学空间(估计为 10³³ 至 10⁶⁰),这些库仍是沧海一粟。
更重要的是,结构-活性关系(SAR)往往是高度非线性的——即"活性悬崖"(activity cliff)现象普遍存在:两个结构高度相似的分子,活性可能相差数个数量级。固定库中可能正好缺失那个关键的突破性化合物。
因此,GenAI 的价值在于:探索固定库无法覆盖的全新化学空间,动态生成兼具新颖性和可合成性的分子。
三、核心模块一:合成可及性与采购策略
3.1 化学有效性 ≠ 合成可及性
早期 GADD 研究过度关注"化学有效性"——确保生成分子符合基本化学规则。SMILES、DeepSMILES、SELFIES 等序列表示方法都尝试在表示层面保证有效性,但实践中,化学有效的分子与可合成的分子之间仍存在巨大鸿沟。
更重要的是,还有一个常被忽视的问题:立体化学。立体构型对生物活性、受体结合和代谢稳定性有决定性影响,而大多数生成模型并未显式处理这一问题。
3.2 三种分子采购策略
论文系统比较了三种主要采购路径:
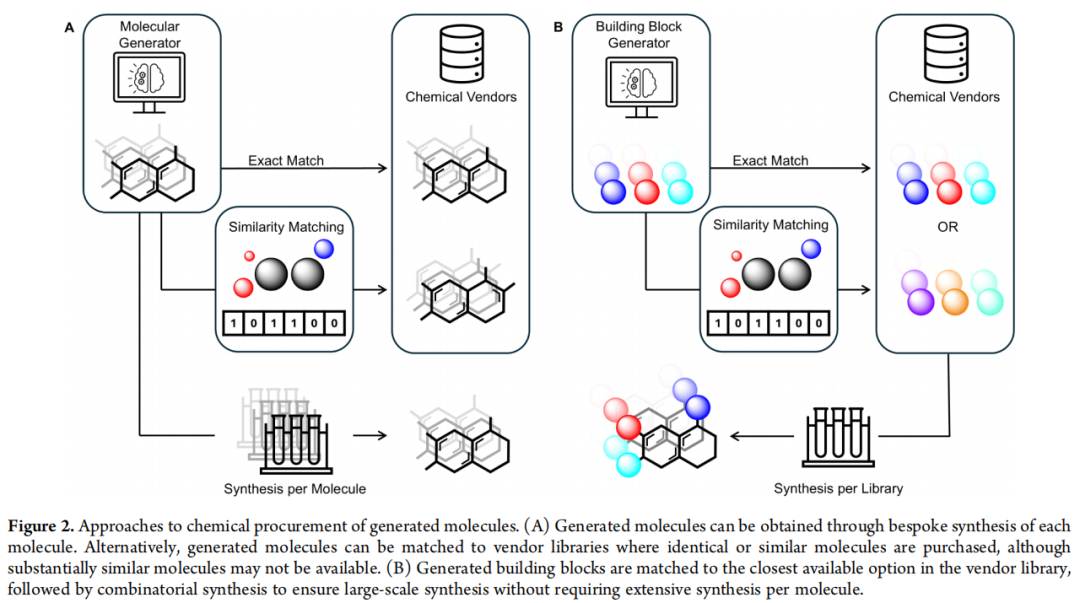
① 供应商匹配(Vendor Mapping)
通过 Tanimoto 相似性或药效团/形状匹配,在供应商库中寻找与生成分子最接近的已有化合物。优点是快速、低成本;缺点是本质上限制了化学空间的探索范围——即便 Enamine 的库已突破 10⁹,也仅是理论化学空间的极小片段。
② 组合库合成(Combinatorial Libraries)
利用预定义的合成策略,通过标准化反应组合已知构建块,快速合成多达 10⁶ 量级的分子集合。当与供应商构建块匹配结合时,可兼顾多样性与可合成性。但其本质是枚举已知反应的排列组合,在构建块空间足够大之前,GenAI 并不比传统枚举具有明显优势。
自动化闭环平台(如 DMTA 流程:设计-制备-测试-分析)尤其适合组合库策略,贝叶斯优化可用于实时精调反应条件。
③ 逆合成规划(Retrosynthesis)
理想中,GADD 应能直接给出目标分子的合成路径。但现实是,计算机辅助合成规划(CASP)仍处于早期阶段——当前工具可以提示潜在反应起始点,但无法自动给出精确的反应条件,仍需专业合成化学家大量人工干预。
闭环合成中,反应条件预测(如借助贝叶斯优化)已取得进展,但对任意给定分子预测最优反应参数仍是重大挑战。
一个已成熟的特例:多肽化学。由于构建块(氨基酸)和反应(酰胺偶联)高度模块化,固相多肽合成(SPPS)已可完全自动化,适合高通量候选分子生成——但多肽固有的细胞渗透性差、蛋白酶降解快和口服生物利用度低等局限性不容忽视。
3.3 主动学习:真正的闭环设计
主动学习(Active Learning) 是将 GenAI 价值最大化的关键框架。其核心是:在 DMTA 循环中,优先合成和测试预计能带来最大信息增益的分子,将实验结果实时反馈给预测模型,持续提高模型准确性和生成质量。
这一框架的意义在于:它将"探索"与"利用"动态平衡,而非固化为一次性的分子生成。每一轮实验数据都使系统更聪明,使化学空间的探索更有目的性。
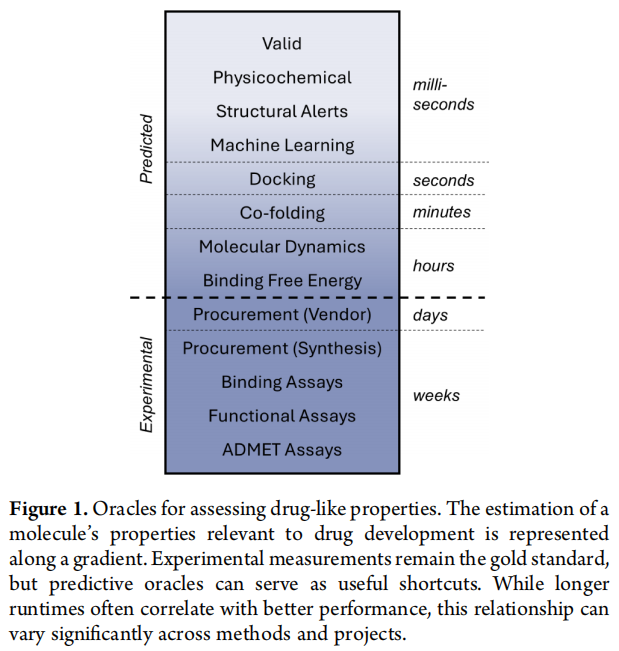
四、核心模块二:ADMET 预测——最难攻克的堡垒
4.1 ADMET 的重要性与现实困境
ADMET 性质不佳是药物研发后期失败的头号原因。将 ADMET 筛查前移至苗头化合物(hit)和先导化合物(lead)优化阶段,是提升临床成功率的关键策略。
然而,将 ADMET 预测模型整合进 GenAI 框架面临严峻挑战:
- • 数据质量差:公开数据集普遍存在测量噪声、实验条件不一致、跨实验室可重复性差等问题
- • 泛化能力弱:大多数 ADMET 模型在训练域之外严重失准。而 GenAI 的核心能力恰恰是探索新颖化学空间——这本质上就是在训练域之外操作
- • "反讽式困境":生成模型的探索能力(其最大优势),使其特别容易提出 ADMET 预测器存在盲点的分子,导致计算上"完美"、实验上彻底失败的结果
关键警示:在 GenAI 工作流中,模型引导生成的准确性往往被系统性高估,在那些泛化性至关重要的探索性项目中尤为突出。
4.2 三类预测方法的比较
① 基于机器学习的 ADMET 模型
方法 | 优点 | 局限 |
|---|---|---|
随机森林(RF) | 可解释性强,特征重要性明确 | 非线性关系捕捉有限 |
深度学习(CNN/RNN) | 层次化特征提取,性能优异 | 数据需求量大,黑盒性强 |
图神经网络(GNN) | 天然适配分子图结构,可建模拓扑交互 | 训练成本高,泛化仍受数据制约 |
核心瓶颈:无论模型架构多先进,训练数据的质量和多样性是根本限制。"垃圾进,垃圾出"的铁律在 ADMET 预测中尤为严峻。
② 基于物理的 ADMET 模型
包括:分子对接/共折叠(预测代谢酶结合)、分子动力学(MD,捕捉蛋白柔性)、量子力学(QM/DFT,预测代谢机制与毒性团)。AlphaFold 3、Boltz-2、Chai-1 等新一代共折叠模型正在与传统对接方法竞争,并在某些场景下表现出优势。
这类方法的优势是机制可解释、泛化能力相对更强,但计算代价过高,无法在 GenAI 内循环中实时使用,只能作为最终合成前的筛选过滤器。
③ 混合方法
将机器学习与高保真物理模拟数据结合,辅以迁移学习和主动学习策略,是当前改善 ADMET 模型泛化性的最有前景方向之一。
4.3 数据集质量:被忽视的关键
论文特别强调了训练数据的质量问题:
- • 不同实验室间,即便使用"相同"方案,同一化合物的测量值也可能显著不同,引入标签噪声
- • 对于转运体介导的渗透性、肝脏清除率、药物性肝损伤(DILI)等复杂端点,标准化、可重复的检测方法本身就很稀缺
- • 这些限制导致模型在窄化合物系列上过拟合,在新颖应用中极度脆弱
五、核心模块三:靶点结合预测——从对接到共折叠
5.1 配体-靶点结合的预测方法体系
预测分子与靶点的结合亲和力,有两大方法论传统:
基于配体的方法:
- • QSAR(定量构效关系):利用已知活性数据和分子描述符训练预测模型
- • 蛋白化学计量学(PCM):将蛋白质序列信息融入 QSAR,实现跨蛋白家族预测,可处理突变体
特点:几乎即时预测,计算成本低;缺点是受制于训练数据的化学和生物空间覆盖范围。
基于结构的方法:
方法 | 精度 | 速度 | GenAI 可用性 |
|---|---|---|---|
分子对接 | 中(粗糙近似) | 秒级 | 内循环可用 |
共折叠(AlphaFold3等) | 中-高 | 分钟级 | 内循环潜力大 |
分子动力学(MD) | 高 | 小时级 | 仅后处理过滤 |
自由能微扰(FEP) | 最高 | 天级/分子 | 不可用于内循环 |
5.2 共折叠:范式转移的新前沿
共折叠(Co-folding) 将配体和蛋白作为整体系统建模,不同于传统对接中蛋白结构固定的假设,它能捕捉配体依赖的蛋白构象变化。AlphaFold 3、Boltz-2、Chai-1 等模型代表了这一方向的最新进展。
其关键优势是:在分钟级时间内生成物理合理的蛋白-配体复合物结构,与生成模型结合后,可实现生成过程中的实时结构评估——这是对接难以实现的"动态结构感知"生成。
但共折叠模型仍有重要局限:尚不能达到精细亲和力排序所需的定量精度;其性能高度依赖高质量训练数据,而对于最有价值的"未成药靶点",恰恰数据最匮乏。
5.3 超越结合亲和力:动力学与功能效应
论文进一步指出,现代药物发现已超越单纯的"结合亲和力"范式,需要考量:
- • 结合动力学:结合速率(kon)和解离速率(koff)决定药物的"驻留时间"(residence time),这是体内疗效的关键预测因子
- • 共价结合:形成稳定共价键,可大幅延长驻留时间,适用于癌症和酶抑制领域,但需精心设计以避免脱靶反应
- • 变构调节:作用于非活性位点,选择性更高,活性调节更精细
- • 表型终点:整合系统级生物学数据,超越"单靶点-单效果"的还原主义模型
这些更复杂的靶点属性,无论从预测还是从生成优化角度看,目前都远超现有计算方法的能力边界。
六、核心模块四:多参数优化(MPO)——让"美"可以被计算
6.1 为什么需要 MPO?
药物发现是一个多目标优化问题,且目标之间往往相互矛盾:提高亲脂性可能增强效力,但损害溶解度和代谢稳定性;增大分子量可能改善结合,但降低细胞渗透性……
多参数优化(MPO) 提供了一个将这些矛盾目标整合为单一可优化信号的框架,在 RL 驱动的分子设计中扮演核心角色。
6.2 MPO 评分函数的三种主要形式
形式 | 描述 | 优缺点 |
|---|---|---|
加权求和 | 各性质线性组合,可动态调整权重 | 简单直观,但权重设定主观 |
期望值函数 | 将每个性质映射到 0–1 尺度,差性质可主导复合得分 | 适合强制约束某一关键性质 |
Pareto 优化 | 识别各目标均无支配劣势的解集 | 无需显式权重,但难以从 Pareto 前沿选择单一候选 |
更先进的框架(如 ACEGEN、DrugEx v2)会基于实验反馈或项目阶段动态调整权重,接近真实药物研发的迭代决策模式。
6.3 奖励黑客(Reward Hacking):最危险的陷阱
这是论文中最具警示意义的部分,并配有具体案例:
案例研究:以 DOCK6 对接得分为唯一奖励函数,REINVENT4 生成的最高分分子普遍带有冗长、柔性的脂肪侧链——这些侧链通过与蛋白口袋建立大量弱接触来"刷高分"。但这类分子:
- • 配体效率(ligand efficiency)极低
- • 细胞膜渗透性差
- • 合成极度困难
- • 大概率具有 ADMET 问题
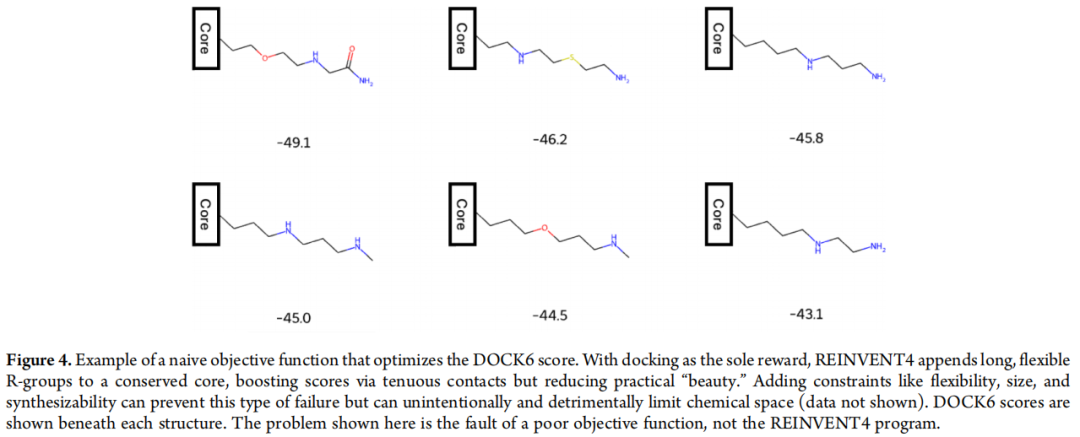
这就是"奖励黑客":分子在优化目标上表现完美,但违背了一个真正好药物候选的全部原则。
作者给出的解决方案是构建阶段适配的 MPO 函数,对上述失效模式施加多重约束:
- 1. 对接得分归一化(如按重原子数归一化,或设定上限)
- 2. 添加柔性和分子大小的反向惩罚(可旋转键数量、最大脂肪链长度)
- 3. 约束可合成性评分(SA score)、分子量、cLogP、TPSA
- 4. 惩罚超出适用域(Applicability Domain)的不可靠预测
6.4 两种常见优化失效模式
① 奖励黑客(Reward Hacking):生成模型通过利用评分函数的漏洞产生虚高得分,但实质上与治疗目标背道而驰。
② 局部最优(Local Minima):过严的约束权重抑制探索,导致优化收敛到单一分子系列,错失潜在更优的候选物。
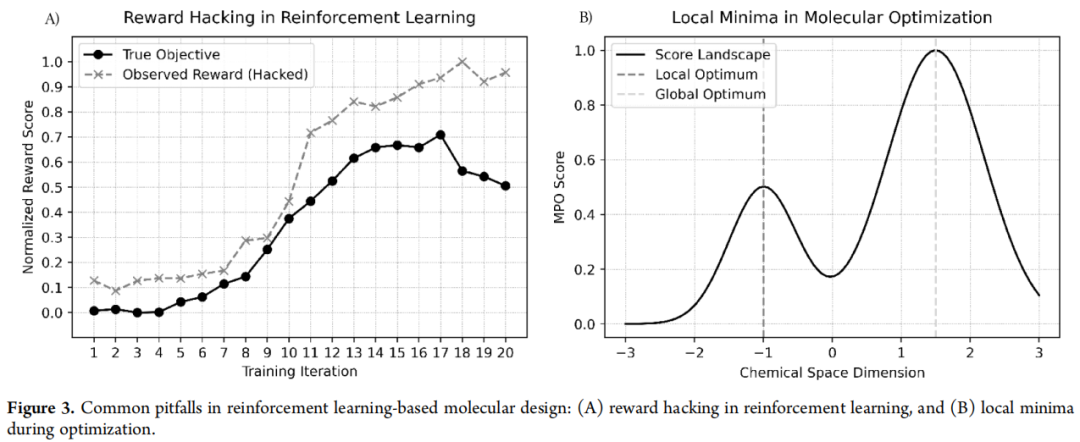
对策:在多样化、经实验验证的数据上迭代重训练;交叉验证(MD/FEP);引入不确定性感知的探索;新颖性激励机制。
6.5 可解释性 AI(XAI):尚待开发的能力
论文指出,生成式化学中的可解释性仍是活跃研究领域。结构化 VAE 可暴露可控的性质轴,基于片段和反事实的方法提供结构层面的推理依据。但 GENTRL、MolGPT、REINVENT 等广泛使用的系统,即便在性质导向的奖励下,对为何提出某个特定结构也几乎没有可解释性。
七、核心论点:人类反馈强化学习(RLHF)是必经之路
7.1 从 ChatGPT 到药物设计的类比
论文最核心的战略洞见,来自一个跨领域类比:
RLHF 之于 ChatGPT,正如 RLHF 之于 GADD。
ChatGPT 的基础能力来自大规模预训练,但使其真正"对齐"人类期望、变得实用的关键,是 RLHF——通过人类评分者的反馈训练奖励模型,再用该奖励模型约束语言模型的输出。
类似地,在药物发现中,无论 MPO 设计得多精巧,都无法完全捕捉有经验的药物化学家的综合判断。这种判断包含:
- • 对反应活性基团(reactive metabolites)的直觉预警
- • 对合成瓶颈的预判
- • 对知识产权风险的考量
- • 对项目战略拟合度的判断
- • 难以量化的"je ne sais quoi"——那种资深药物猎手对"这个分子有潜力"的直觉
7.2 RLHF 实践闭环:一个最小化可行方案
作者给出了一个具体的、可操作的 RLHF 最小实践方案:
第一步:收集偏好
每周组织化学家小组(包括合成化学家、计算化学家、DMPK 科学家)
对分子对(A vs B)进行两两比较评分
评分维度:可合成性、ADMET 风险、新颖性/IP 价值、临床可行性
第二步:拟合奖励模型
训练轻量级图神经网络(GNN)作为偏好预测模型
进行校准以确保奖励模型的可靠性
第三步:策略更新
使用 KL 散度正则化更新生成模型策略
始终维持硬约束门控(结构警报、适用域门控、性质窗口)
第四步:护栏机制
红队解码(red-team decoys)——主动测试失效模式
正交交叉验证(分子动力学 spot-check、结合姿势合理性验证)
检测链延长黑客等典型奖励黑客模式
第五步:追踪与汇报
监控关键指标:设计→制备转化率、制备→测定转化率
人类偏好预测准确率、配体效率提升幅度7.3 分阶段的 MPO 策略
论文将 GenAI 在不同药物发现阶段的应用策略梳理如下:
研发阶段 | MPO 重点 | 关键评分要素 | 人类介入频率 |
|---|---|---|---|
苗头化合物识别 | 化学多样性、基本效力 | 化学有效性、结构警报过滤、粗糙对接 | 低频,主要用于校准初始库 |
苗头→先导优化 | ADMET 性质提升 | 溶解度、渗透性、代谢稳定性、hERG 筛查、LLE | 中频,每周 RLHF 偏好收集 |
先导优化 | 效力-选择性-PK 三角平衡 | 靶点亲和力、脱靶选择性、半衰期、口服生物利用度 | 高频,每轮设计周期 |
候选药物优选 | 安全、配方、IP | 长期毒性预测、剂型可行性、竞争格局 | 最高频,全程监督 |
八、延伸评述:论文未明言的深层洞见
8.1 "苦涩的教训"与 GenAI 的长期命运
作者引用了 Richard Sutton 的"苦涩的教训"(The Bitter Lesson):在 AI 历史中,依赖大规模数据和计算力扩展的通用算法,长期来看总是胜过精心设计的领域专用系统。
这意味着:随着计算能力增长、高质量数据积累,GenAI 在药物发现中的表现将持续提升,即便当前的特定方法充满缺陷。量子计算可能在远期为化学空间探索提供全新可能,但在可预见的未来实用价值仍属推测。
8.2 "美丽"是动态的、情境依赖的
论文特别强调了一个容易被忽视的事实:对美丽分子的定义随着项目进展不断演化。竞争对手数据的出现、新临床靶点的发现、早期安全信号的浮现……这些都会根本性地改变"好分子"的定义。这正是为什么 MPO 函数必须动态更新,也是为什么静态的自动化流程无法完全替代人类判断。
8.3 数据质量是被低估的根本制约
全文贯穿着一个核心判断:当前 GADD 领域最大的瓶颈,不是架构设计,不是计算资源,而是高质量、多样化、标准化的实验数据。
- • ADMET 模型的脆弱性,根源在于训练数据
- • 靶点结合预测的不准确,根源在于训练数据
- • 奖励黑客的根源之一,是模型对训练域外分子的系统性误判
在这个意义上,构建高质量、可共享的药物发现数据集,其战略价值可能不亚于任何模型架构创新。
九、结论:生成式药物设计的现实路线图
论文的核心结论可以总结为五条实践原则:
① 评分函数必须与项目目标动态对齐 不存在"万能"的 MPO 函数。随着项目数据的积累和优先级的转移,奖励函数必须持续修订。
② 实验反馈必须紧密整合到模型更新中 主动学习框架是最大化 GenAI 价值的关键机制。每一轮实验数据都应改善下一轮的设计方向。
③ 人类专家监督必须贯穿设计周期 奖励黑客、ADMET 模型脆弱性和领域偏移将持续存在,除非通过主动学习、不确定性量化和人类反馈加以明确应对。
④ 构建可信的不确定性估计 适用域检查(Applicability Domain,AD)和共形预测(Conformal Prediction)等方法,可以让 MPO 框架在预测不可靠时自动降低该指标的权重,避免基于错误预测的过度优化。
⑤ "美"是主观的,需要人类来定义 最终,定义什么是美丽分子的,是有经验的药物猎手和临床成功——不是算法。GenAI 是强大的探索工具,但它探索的方向,需要人类来导航。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号