蛋白语言模型能设计 AAV 吗?关键不在生成,而在如何兼顾可行性与新颖性

蛋白语言模型能设计 AAV 吗?关键不在生成,而在如何兼顾可行性与新颖性

Tom2Code
发布于 2026-04-17 17:29:44
发布于 2026-04-17 17:29:44
今天来介绍一篇使用蛋白质语言模型设计AAV衣壳的文章:这篇论文开发了一种结合蛋白质语言模型和强化学习的生成式设计框架,旨在生成兼具高度序列新颖性与功能活性的新型腺相关病毒(AAV)衣壳,并提出了一套基于生物物理特性的候选序列筛选策略。

1. 一句话概括
这篇论文的核心目标,是在 AAV2 capsid 的局部可变区域中,用“蛋白语言模型微调 + 强化学习奖励引导”去生成既有功能可行性、又尽量跳出训练分布的新序列;它最重要的贡献不是单纯把模型换成了 PLM,而是把“可行性约束”和“新颖性驱动”同时放进生成框架里,并进一步加上一个基于极性和电荷的候选筛选策略。
更直白地说,这篇论文想解决的不是“会不会生成 AAV 序列”,而是“能不能在保证大概率不坏掉的前提下,往更远的序列空间探索”。作者认为,单纯的 fine-tuning 只能生成“像训练集”的序列,而 reinforcement learning 才是把模型往“新但不至于失活”的方向推了一步。
2. 研究背景与问题提出
AAV 是当前基因治疗里最重要的递送载体之一,但临床推进也暴露出一系列现实瓶颈:免疫原性、转导效率、器官毒性、组织特异性、可制造性等,都要求下一代 capsid 继续优化。问题在于,蛋白序列空间极其庞大,实验筛选只能覆盖其中极小一部分,因此 AAV 工程越来越依赖机器学习来缩小搜索空间。
在这条技术路线上,过去不少 AAV 生成工作使用的是 VAE。VAE 的优势是能学到一个连续潜空间,但它有两个明显问题:第一,生成结果容易贴着训练集附近走;第二,潜空间可能退化,导致真实序列多样性学得不够好。对于 AAV 这类任务,这个缺陷很关键,因为“更远的序列空间”里,才更可能出现训练集中没有覆盖的新性质,例如不同抗原性、更好稳定性或不同组织嗜性。
作者因此把视角转向 protein language model。PLM 的优势不是“更大”这么简单,而是它通过大规模蛋白序列预训练,已经学到了一套接近“蛋白语法”的统计规律,所以生成的东西通常比纯随机扰动更像一个“像样的蛋白”。但这里又出现第二个问题:预训练 PLM 只会生成“像蛋白”的序列,不会天然生成“像可行 AAV capsid”的序列。所以必须做 task-specific fine-tuning;而 fine-tuning 之后,又会遇到第三个问题:模型虽然更会生成 viable 序列了,但往往又重新被拉回训练分布附近。作者这篇文章真正想补的,就是这第三个缺口。
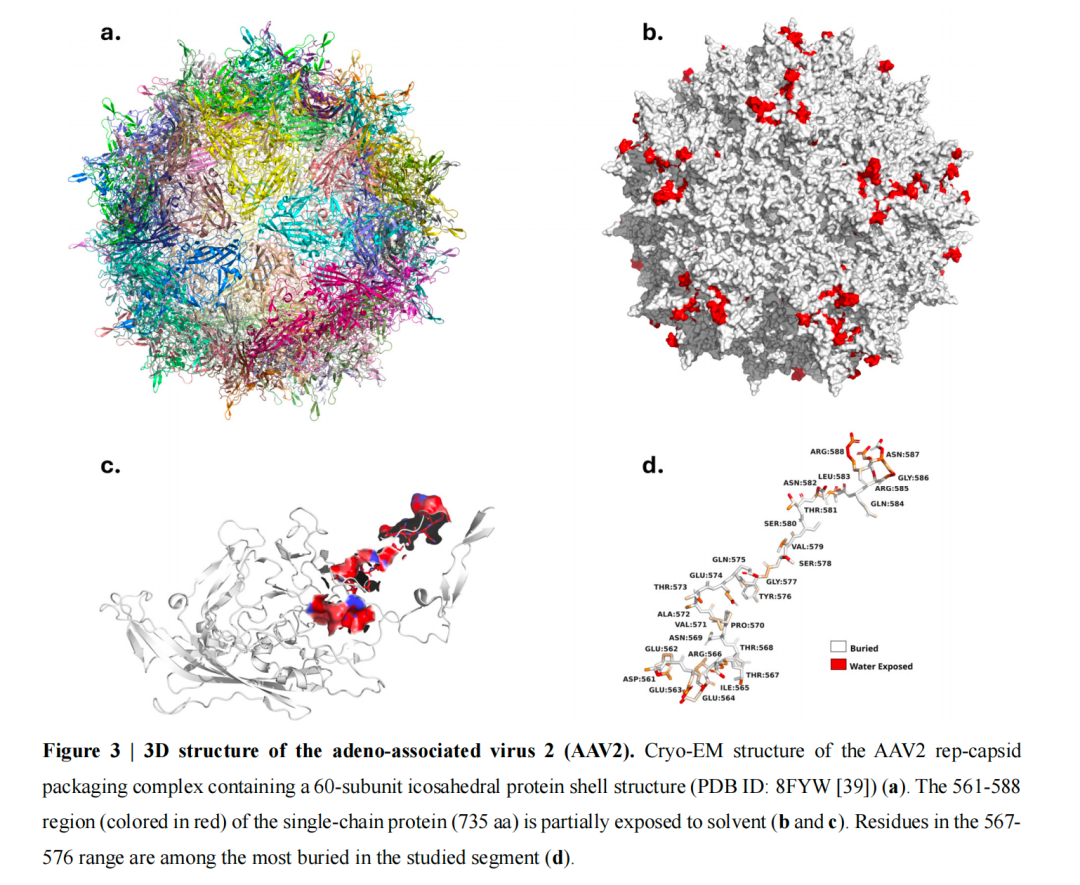
图 3 | 腺相关病毒 2 (AAV2) 的 3D 结构。包含 60 个亚基的二十面体蛋白质外壳结构的 AAV2 rep-衣壳包装复合物的冷冻电镜(Cryo-EM)结构 (PDB ID: 8FYW [39]) (a)。单链蛋白(735 个氨基酸)的 561-588 区域(标为红色)部分暴露于溶剂中 (b 和 c)。在所研究的片段中,567-576 范围内的残基是掩埋最深的 (d)。
3. 核心创新点
创新点 1:把 AAV capsid 生成从“单纯微调”推进到“微调后再强化学习引导”
文章不是只比较不同 PLM,而是构造了三种清晰的模型状态:预训练 ProGen、只用正样本微调的 ProGen,以及微调后再做 RL 的 ProGen。这个设计的价值在于,它把“PLM 是否有用”和“RL 是否真的带来额外探索能力”拆开看,而不是把所有改动混在一起。
创新点 2:奖励函数同时编码“可行性”和“新颖性”
这篇文章的关键不是“用了 RL”,而是 RL 奖励里到底放了什么。作者把 reward 设计成两个分支:一个分支用 ProtBERT 分类器给出 viability 概率,另一个分支用冻结的 ESM2 embedding 计算相对 reference 的 cosine distance,作为 novelty 代理指标。更重要的是,novelty 不是简单线性加分,而是做了 percentile 标准化和超出最大已观测值时的 power-tail bonus,说明作者想有意识地把模型推向“训练集以外的远区”。
创新点 3:训练时只对可变窗口计算损失,避免模型被不变区域“带偏”
AAV2 capsid 序列里,真正变化的是 561–588 这一段,前缀和后缀大多不变。作者在 supervised fine-tuning 时只对这个变量窗口计算 loss,mask 掉 prefix/suffix,避免模型浪费容量去记忆那些所有样本都相同的位置。这一点看起来像工程细节,但实际上非常重要:它让模型真正学习的是“功能相关变异模式”,而不是整条序列的表面统计规律。
创新点 4:候选筛选不再只看 predicted viability,而引入“正交”的生物物理筛选框架
作者意识到,RL 之后大多数序列都被判成 viable,此时 viability 分数本身已经不再是一个好筛子。因此他们又引入了 极性与净电荷 两个 developability 维度,在中间 90% 的正样本参数空间里做网格采样,并在每个网格里选 novelty 最高的序列。这不是在训练时优化的指标,而是在训练后加入的“第二层筛选逻辑”,属于一个很实用的 pipeline 创新。
创新点 5:它把“生成—探索—筛选”连成了完整工作流
很多生成论文停在“我能生成”,但这篇文章往前多走了一步:从预训练 PLM 到 task adaptation,到 novelty-guided exploration,再到 biophysics-guided candidate selection,给出了一个可以直接进入后续 MD 或实验验证的候选池。它真正的价值更像是 workflow building,而不是只提出一个孤立模型模块。
4. 方法与技术路线拆解
输入
作者使用的是 Bryant et al. 2021 的 AAV2 capsid viability 数据集。变异只发生在 reference sequence 的 561–588 位窗口,包含替换、插入和缺失。经过预处理后,最终数据集包含 293,835 条 experimentally validated 的 unique capsid sequences,其中正样本用于生成模型微调。
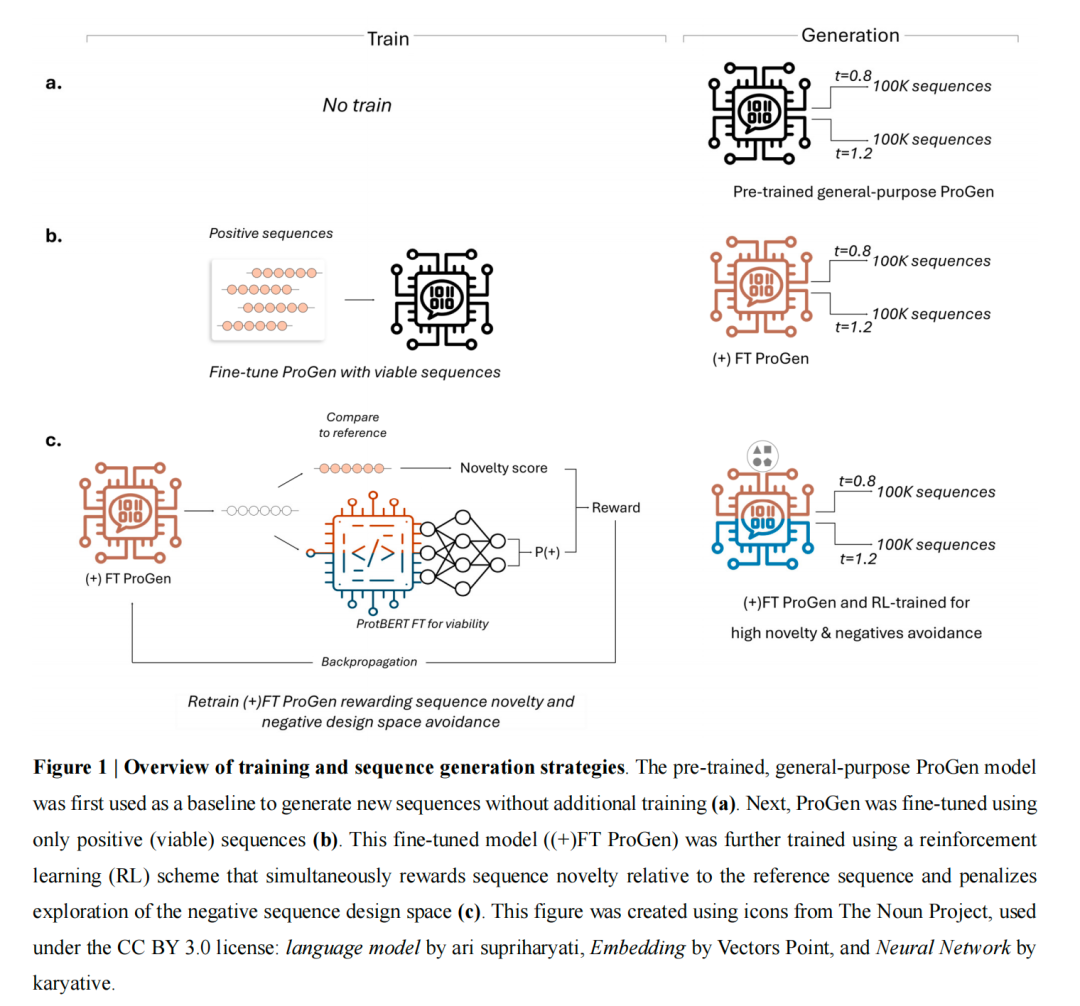
这张图简要概括了 ProGen 模型从通用预训练 (a) 到有效序列微调 (b),再到通过强化学习 (c) 实现“高新颖度”与“生物活性”双重优化的蛋白质序列定向设计流程。
处理过程:第一阶段——监督微调
生成骨干模型选的是 ProGen2-small。作者没有用更大的 ESM3,不是因为它不强,而是因为 RL 反复迭代成本太高。微调时,模型输入完整 capsid 背景,但 loss 只在中间 variable fragment 上计算,prefix 和 suffix 被 mask,以防模型过度学习不变位点。优化器为 AdamW,训练 5 epochs,batch size 4,10-fold cross-validation 的 90/10 split。
这里的逻辑很清楚:先让模型学会“什么样的局部变异仍然像 viable AAV2”。这一步解决的是功能可行性问题,但它本质上仍然只是在正样本分布附近重建“安全区域”。
处理过程:第二阶段——强化学习引导
RL 阶段,模型在相同 N 端 prefix 条件下生成 variable fragment,再拼接 suffix 还原 full-length 序列。每条生成序列得到两个分数:
- • viability score:由 ProtBERT-based classifier 给出;
- • novelty score:由 pretrained ESM2 embedding 相对 reference 的 cosine distance 给出。
奖励函数的本质是:只有 viability 过阈值的序列才有资格拿到奖励,然后在此基础上,新颖性越高,奖励越大;如果 novelty 超过 fine-tuned 集合中已见最大值,还会额外加 power-tail bonus。 训练时还加入了 KL regularization、top-q 保留、entropy bonus 等机制,防止策略完全漂移或塌缩。
这一步的方法论意义在于: 它不是简单“追高 viability”,而是在 viability 设了门槛之后,尽量把模型推向更远但仍可能成立的序列区域。换句话说,它把蛋白设计里最难的事情显式化了:不是生成最像训练集的优等生,而是生成训练集没见过但仍有可能活的异类。 这正是 RL 在这里比普通 fine-tuning 更合理的地方。
输出
作者最后并不把“所有 RL 生成序列”都当候选,而是又通过 polarity 和 net charge 做 developability-oriented 二次筛选:把高置信 viable 的 reinforced sequences 投到二维参数空间,限制在正样本分布的中间 90%,再做 9-bin 或 25-bin 分箱,每个区域选 novelty 最高者。最终 Table 2 给出了一组更可管理、也更适合后续验证的候选序列。
5. 关键实验与结果解读
结果 1:预训练 PLM 单独用,几乎没有实际设计价值
作者先看未微调的 ProGen。每个温度下各生成 100,000 条序列,几乎全是 unique,但 0% 被判为 viable。这说明大模型的“蛋白语法能力”并不等于“任务功能能力”。对于 AAV 这种功能约束很强的系统,仅靠通用蛋白先验远远不够。
这组结果的真正价值在于,它给一个很重要的负结论:通用 PLM 不能直接当 AAV 设计器。这听起来像常识,但实际上很多人容易误以为“会生成自然蛋白”就等于“会生成可用 capsid”。这篇论文的数据把这种误解直接打掉了。
结果 2:单纯 fine-tuning,能把“可行性”学回来,但仍带着训练集偏见
微调模型在 100,000 条采样中,t=0.8 时有 82,031 条 unique,98% 被判 viable;t=1.2 时有 72,509 条 unique,91% 被判 viable。同时与训练集存在少量重合(161 和 37 条),说明模型已明显学到 viability pattern,但仍然有 residual bias toward training data。
这组结果支持了一个很明确的判断:fine-tuning 的作用更像“收回功能约束”,而不是“打开新空间”。如果目标只是生成“像已知 viable capsid 的东西”,它已经够强;但如果目标是“在保证功能的同时变得更远”,它还不够。
结果 3:RL 的效果不是“生成更多 unique 序列”,而是“把生成重心推向更远的新颖区域”
这篇文章里一个容易被误读的数据是:RL 模型在 100,000 条生成里,t=0.8 只有 330 条 unique,t=1.2 也只有 9,403 条 unique,看上去反而比 fine-tuning 更差;但这些 unique 序列中 99%–100% 被判 viable。作者把这解释为 reward 带来的更强选择压力。
真正关键的不是“unique 个数”,而是 novelty 的定义并不是批内去重数量,而是 embedding space 中相对 reference 的距离。在 t-SNE 与 violin plot 分析中,reinforced sequences 整体被推向比 training/fine-tuned 更远的区域,且最高 novelty 超过 fine-tuned 和 training set 的上限,同时 predicted viability 仍维持较高水平。
所以这篇论文一个很重要的阅读点是:“更多 unique”不等于“更高 novelty”。RL 在这里干的事不是“让输出尽量不重复”,而是“让输出朝着训练集未覆盖、但在生物学表征空间里更远的方向移动”。
结果 4:模型不是盲目乱变,而是在“允许变”的地方更激进地变
突变景观分析显示,fine-tuned 模型复现了正样本里已有的 viability signature:567–576 位点区段倾向避免突变,若有变化,也以 substitution 为主,而不是 insertion/deletion。结合第 9 页的结构图,这一区域在 capsid 中更 buried,更可能承担结构稳定性角色。RL 模型不仅保留了这条签名,还把更高强度的突变集中到允许区域,从而实现“保守关键位点、放开非关键位点”的探索策略。
这一点很值得注意,因为它说明 RL 不是在“随机变得更远”,而是在一种接近结构约束感知的方式下去探索。这里虽然没有直接做结构预测或湿实验验证,但从突变景观和 buried/exposed 的对应关系看,这个生成过程至少不是纯统计幻觉。
结果 5:最终候选筛选体现了作者对“实验可落地性”的考虑
由于 RL 之后大部分序列都被判 viable,viability 不再是一个好筛子,于是作者引入 polarity 和 net charge。结果显示,正样本略偏更高极性和轻度阴离子化,而过强正电荷似乎不利于 viability。但这些差异不足以设严格阈值,因此作者改用 grid-based sampling,在中间 90% 可接受区域内均匀覆盖不同 biophysical 组合,再在每个 bin 中选 novelty 最高者。
这个结果说明,作者意识到“高 novelty + 高 viability prediction”并不等于“适合推进实验”,所以他们额外加了 developability 维度。这不是最花哨的部分,却是离实验现实最近的一部分。
6. 论文的局限性与可商榷之处
局限性 1:本文的“功能性”主要还是预测出来的,不是新序列的实验验证结果
训练数据本身来自 experimentally validated viability set,但本文生成出来的新序列,核心评估仍然依赖 viability classifier,而不是湿实验验证。作者自己也承认,用于评估 viability 的分类器和用于训练生成模型的数据同源,因此对高度新颖序列可能存在偏置,尤其可能产生 false negatives。
这意味着文章目前最强的结论应该是:“我们能生成大量高 predicted viability、且更 novel 的候选序列。”而不是:“我们已经实验上证明这些新序列可用。”
局限性 2:设计空间只覆盖 AAV2 的局部变异窗口,不是全 capsid de novo 设计
这项工作聚焦的是 561–588 位的局部窗口,不是全长 capsid 从头设计。即使作者重建了 full-length sequence,真正学习和生成的变化仍是一个有限区域。
因此,这篇论文的适用边界很明确: 它更像是在回答“局部可变区域的智能探索怎么做”,而不是“完整 AAV capsid 生成设计怎么做”。
局限性 3:RL 的代价是输出分布显著收缩,可能存在模式集中
RL 模型在 100,000 次采样里 unique 序列数量明显少于 fine-tuning,这说明 reward 虽然把模型推到了更远的新颖空间,但也显著提高了输出集中度。作者把它解释为 selective pressure,但从另一角度看,这也可能意味着策略空间被压缩,存在一定程度的 mode concentration。
也就是说,RL 在这里确实增强了“往正确方向探索”的能力,但是否牺牲了“探索的广度”,这是值得继续追问的。
局限性 4:novelty 指标是 embedding distance,不等于真实功能新颖性
作者用 pretrained ESM2 embedding 与 reference 的 cosine distance 作为 novelty 代理。这个指标比 raw sequence identity 更聪明,因为它带有结构与进化语义;但它仍然只是一个代理变量。t-SNE 分析里作者也特别说明:在 t-SNE 空间离得远,不一定等于 novelty 很高;反过来,embedding novelty 也不直接等于新功能。
因此,这篇文章证明的是“表征空间里的生物学新颖性”,不是功能层面已经被证实的新颖性。
局限性 5:候选筛选虽然更可解释,但仍然是训练数据间接驱动的
polarity 和 charge 的 grid sampling 是一个很实用的补充,但它的边界来自正样本分布的中间 90%。这意味着它虽然是“正交于训练目标”的筛选轴,但并没有真正摆脱训练集定义的安全区。
换句话说,它更像一个保守但可落地的候选筛选器,而不是一个能完全放大意外发现的机制。
7. 这篇论文的真实价值
如果要给这篇论文定性,我会说它更像是 “方法框架上的工程性突破”,而不是基础原理层面的范式革命,也不是实验发现型论文。它最大的价值不在于单个模块多么惊艳,而在于它把 PLM 预训练先验、task-specific fine-tuning、RL 引导的新颖性探索,以及 developability-aware 候选筛选 这几件事串成了一条完整路径。
它对领域最大的启发有两点。第一,AAV 设计里真正难的不是把可行性学出来,而是在不丢掉可行性的前提下跳出已知库;这件事单靠 fine-tuning 不够,必须显式鼓励 exploration。第二,生成模型的终点不能停在“分数更高”,而要接上一个更接近实验现实的筛选层。
它是否会改变后续研究方向?我认为它有机会影响 AAV 设计 pipeline 的组织方式,尤其是“生成 + RL + developability filters”这一套组合拳,未来很可能被迁移到其他蛋白工程任务中。但它要真正成为领域转折点,还需要至少两件事补上:
一是新序列的系统性实验验证;
二是从局部窗口设计,进一步走向更复杂、更多位点甚至全长层面的设计问题。
论文地址:https://arxiv.org/pdf/2603.19473
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号