Hermes Agent 深度分析:一快一慢两个循环实现自我改进

Hermes Agent 深度分析:一快一慢两个循环实现自我改进

技术人生黄勇
发布于 2026-04-17 15:51:46
发布于 2026-04-17 15:51:46
有朋友在前两天的文章《拆解 Hermes Agent:开源 Agent 里唯一的闭环学习系统》下留言:
"数据飞轮是不是指给有训练能力的环境使用才有用?"
答案既是需要的,也是可以不需要训练循环的。
需要的途径:如果你想要通过 RL 训练来改进模型权重,确实需要有 GPU 训练环境。
不需要的方法(咱们日常使用就足够用):Hermes Agent 的自我改进并不只有"训练模型权重"这一条路。
这篇文章就来讲清楚 Hermes Agent 的两条自我改进路径:
改进提示与技能 vs 改进模型权重。
两条路径的本质区别
维度 | 改提示/技能 | 改模型权重 |
|---|---|---|
优化对象 | 文本制品(prompts、skills、tool descriptions) | 模型权重(LoRA adapter) |
依赖资源 | API 调用 | GPU(24GB+ VRAM) |
单次成本 | $2-10 | 算力成本高(数小时 A100) |
执行速度 | 分钟级 | 小时级 |
生效方式 | 修改文件 + 重启 | 合并权重 + 部署 API 服务 |
改进提示是在改变给模型的"输入上下文":模型还是原来那个模型,但你给它的指令更精确了。
改模型是在改变模型的"内在能力"——模型学会了什么,它变了。
两条路不是替代关系,而是分工。
先用低成本方案把指令优化到极致,再考虑是否需要昂贵的模型训练。
路径一:改进提示与技能(快循环)
Hermes Agent 的快循环包含四个闭环学习机制。
它们有一个共同特点:不改动模型,只改动文本。
1. 定期自省(Periodic Nudge)
机制:每隔 N 轮对话,Agent 自动审查自己的行为是否符合约束。
实现位置:gateway/run.py 中的后台任务调度。
Hermes 会周期性地触发一个"nudge"信号,让 Agent 暂停当前任务,回顾最近的对话历史,检查是否有偏离目标的行为。
触发条件:可配置。
默认每 10 轮对话触发一次,或在会话超时前触发。
学习成果:Agent 会基于自省结果调整后续行为。
比如发现自己频繁调用某个低效工具,后续会减少调用;
或者发现某个约束被违反,会在 system prompt 中强化该约束。
依赖的记忆:需要读取当前会话的对话历史(SessionDB 中的 messages 表)。
2. 自主技能创建(Autonomous Skill Creation)
机制:当 Agent 发现某种任务模式反复出现,且自己已经有成功的解决方法时,自动把这套方法沉淀为可复用的技能文件。
实现位置:tools/skill_manager_tool.py
触发条件:Agent 在对话中判断"这个任务模式值得沉淀",调用 skill_manager 工具的 create 动作。
技能文件结构:
~/.hermes/skills/
├── my-skill/
│ ├── SKILL.md # 技能说明书(YAML frontmatter + Markdown 正文)
│ ├── references/ # 参考文档
│ ├── templates/ # 模板文件
│ ├── scripts/ # 脚本
│ └── assets/ # 资源文件SKILL.md 格式:
---
name: my-skill
description: 一句话描述这个技能做什么
version: 1.0
author: agent
---
## 触发条件
(什么情况下应该使用这个技能)
## 执行步骤
1. 第一步做什么
2. 第二步做什么
...
## 注意事项
(容易踩的坑、边界情况)学习成果:技能创建后,后续对话中如果遇到类似任务,Agent 会自动加载这个技能,按照技能说明书执行,避免重复探索。
依赖的记忆:需要读取当前会话的对话历史,提取成功的任务模式。
3. 技能自我优化(Skill Self-Improvement)
机制:当 Agent 发现某个技能执行失败或效果不佳时,自动修改技能文件进行优化。
实现位置:tools/skill_manager_tool.py 的 patch 和 edit 动作。
触发条件:
- 技能执行后,Agent 发现结果不符合预期
- 用户给出负面反馈
- Agent 在自省中发现某个技能的缺陷
优化方式:
patch针对 SKILL.md 或支持文件的局部修改(类似 git diff)edit完全重写 SKILL.md 的内容
约束保护:
- 单个技能文件不超过 100,000 字符(约 36K tokens)
- 支持文件不超过 1 MiB
- 所有修改都经过安全扫描(
tools/skills_guard.py)
学习成果:技能持续迭代,质量逐步提升。
依赖的记忆:需要读取执行轨迹,分析失败原因。
4. 跨会话搜索与 LLM 摘要(FTS5 Session Search)
机制:Agent 可以搜索历史会话中的对话内容,提取相关上下文,并用 LLM 生成摘要。
实现位置:hermes_state.py 中的 SessionDB.search_messages() 方法。
技术细节:
- 使用 SQLite 的 全文索引(Full-Text Search 5 )虚拟表
- 对所有消息内容建立全文索引
- 支持 FTS5 查询语法:关键词、短语、布尔操作、前缀匹配
搜索示例:
# 搜索包含 "docker deployment" 的消息
db.search_messages("docker deployment")
# 搜索精确短语
db.search_messages('"exact phrase"')
# 布尔操作
db.search_messages("docker OR kubernetes")
db.search_messages("python NOT java")
# 前缀匹配
db.search_messages("deploy*")返回结果:匹配消息 + 前后文上下文(各 1 条消息)+ 会话元数据。
学习成果:Agent 可以"回忆起"之前对话中的关键信息,避免重复提问,保持上下文一致性。
依赖的记忆:核心依赖就是 SessionDB 本身,所有对话历史都存储在 SQLite 数据库中。
昨天文章《告别盲目运行:Hermes Agent Web 界面追踪Token消耗、记忆容量、技能进化》里提到的技能进化监控就是反映这部分的改进。
Corrections & Lessons Learned 面板展示的是「错误修正与经验教训」记录:
数据来源(2个渠道)
从 ~/.hermes/ 目录的记忆文件中提取 category: correction 类型的条目⚠️ 严重程度分级
级别 | 图标 | 含义 | 触发关键词示例 |
|---|---|---|---|
Critical | ⚠ | 用户直接发现具体错误 | caught me, verify before |
Major | ✦ | 陷阱/坑点被吸收 | gotcha, Read ... before making |
Minor | · | 限制/局限性被记录 | doesn't work, won't help, not yet confirmed |
🔍 数据提取逻辑
1. Memory 中的修正
系统会扫描记忆文件中带有特定关键词的条目:
gotcha, don't ... as a problem, caught me, verify before, Read ... before making, supersedes, not usable, doesn't work...
2. Session 会话中的修正
从数据库查询用户消息中包含以下关键词的对话:
wrong, incorrect, verify, actually, not right, not correct, not true, push back
最多展示最近 20 条。
记忆系统:快循环的基础设施
上述四个闭环学习机制,全部依赖于 Hermes 的记忆系统。
存储位置:~/.hermes/state.db(SQLite 数据库)
核心表结构:
-- 会话表
CREATE TABLE sessions (
id TEXT PRIMARY KEY,
source TEXT NOT NULL, -- 'cli', 'telegram', 'discord' 等
user_id TEXT,
model TEXT,
system_prompt TEXT,
parent_session_id TEXT, -- 支持会话链(压缩后续)
started_at REAL,
ended_at REAL,
message_count INTEGER,
tool_call_count INTEGER,
input_tokens INTEGER,
output_tokens INTEGER,
title TEXT,
...
);
-- 消息表
CREATE TABLE messages (
id INTEGER PRIMARY KEY,
session_id TEXT,
role TEXT, -- 'user', 'assistant', 'tool'
content TEXT,
tool_calls TEXT, -- JSON 序列化的工具调用
timestamp REAL,
reasoning TEXT, -- 推理过程(支持 extended thinking)
...
);
-- FTS5 全文索引
CREATE VIRTUAL TABLE messages_fts USING fts5(
content,
content=messages,
content_rowid=id
);关键设计:
- WAL 模式支持多进程并发读写(gateway + CLI + cron 任务同时运行)
- FTS5 索引毫秒级全文搜索
- 会话链通过
parent_session_id支持上下文压缩后的会话续接 - Token 统计自动追踪输入/输出/缓存命中的 token 数
支持外挂记忆接口:
Hermes 还支持外挂记忆实现(Memory Provider),通过 agent/memory_provider.py 的抽象接口:
class MemoryProvider(ABC):
def initialize(self, session_id: str, **kwargs): ...
def prefetch(self, query: str) -> str: ... # 每轮对话前预取相关记忆
def sync_turn(self, user, assistant): ... # 每轮对话后同步
def get_tool_schemas(self): ... # 暴露给模型的工具
def handle_tool_call(self, tool_name, args): ...内置的 BuiltinMemoryProvider 管理 MEMORY.md 和 USER.md 文件。
可以接入外部记忆服务,如 Honcho、Hindsight、Mem0。
快循环的记忆依赖总结:
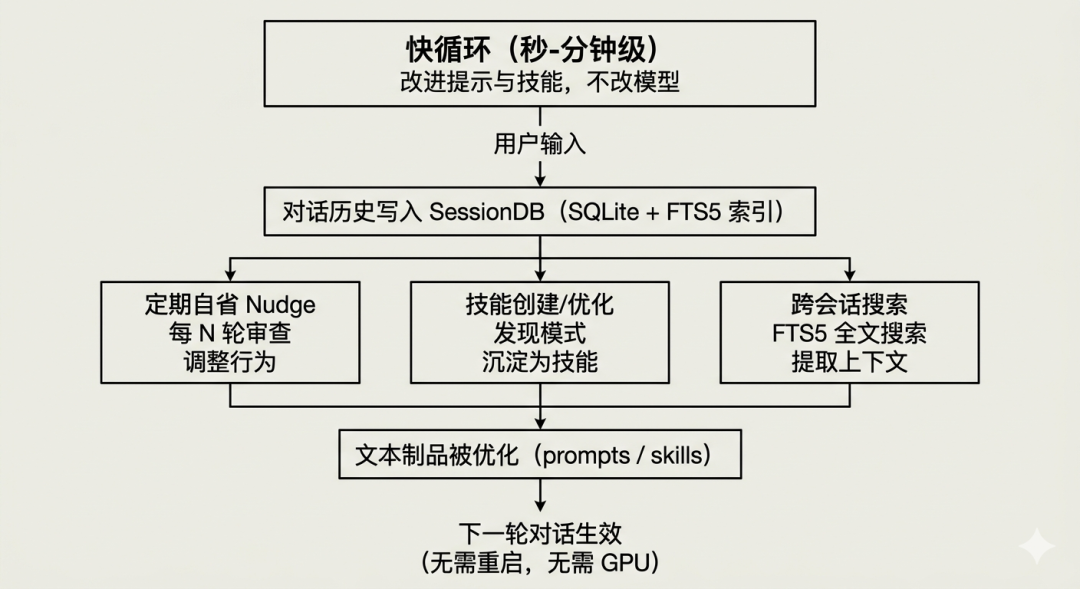
闭环机制 | 依赖的记忆 |
|---|---|
定期自省 | 当前会话对话历史 |
自主技能创建 | 当前会话对话历史 + 成功模式提取 |
技能自我优化 | 执行轨迹 + 失败分析 |
跨会话搜索 | 全量会话历史(FTS5 索引) |
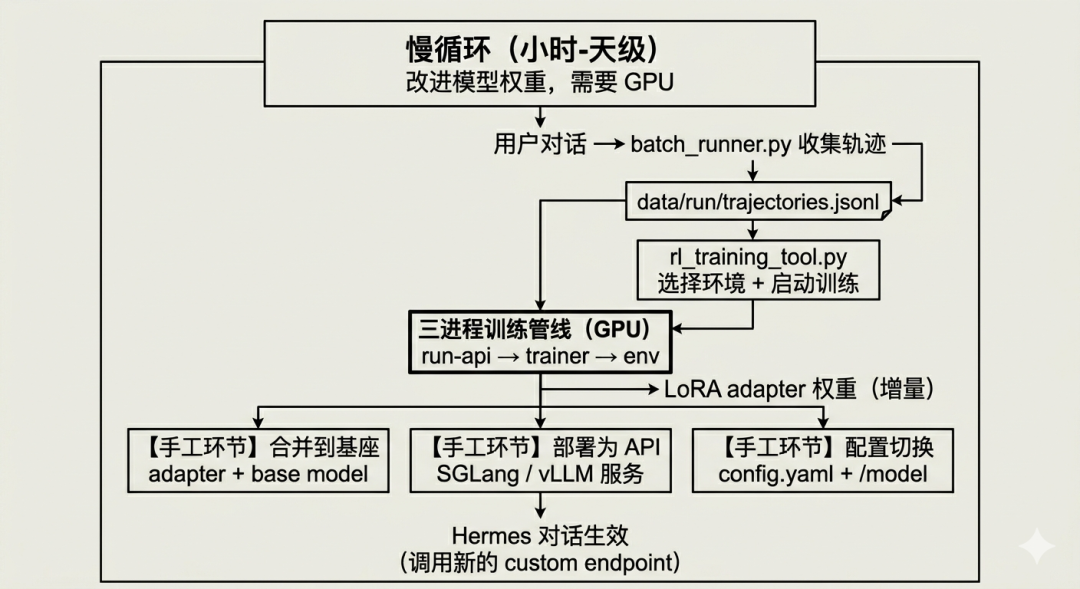
路径二:改进模型权重(慢循环)
当提示和技能已经优化到极致,但模型本身的推理能力仍然不够时,就需要考虑改进模型权重——也就是"训练一个专属模型"。
这条路是传统的 RL(Reinforcement Learning)路径,Hermes 通过 rl_training_tool.py 提供了完整的基础设施。
慢循环的完整链路(五步)
Step 1: 收集轨迹数据
Step 2: 选择 RL 环境
Step 3: 启动 RL 训练
Step 4: LoRA 合并到基座模型
Step 5: 部署为新模型Step 1:收集轨迹数据
入口:batch_runner.py
命令:
python batch_runner.py \
--dataset_file=data.jsonl \
--batch_size=10 \
--run_name=my_run \
--model=anthropic/claude-sonnet-4.6输出:data/my_run/trajectories.jsonl
每条记录包含:
conversationsShareGPT 格式的完整对话轨迹tool_stats工具调用统计reasoning_stats推理覆盖率metadata模型、时间戳、batch 编号
断点续跑:--resume 会扫描已有 batch 文件,按 prompt 内容去重,跳过已完成样本。
数据清洗:自动过滤无效工具名(模型幻觉),丢弃没有推理过程的样本。
Step 2:选择 RL 环境
入口:rl_training_tool.py(通过 rl_* 工具系列调用)
命令:
rl_list_environments() # 列出所有可用环境
rl_select_environment(name="...") # 选择环境可用环境:
SWE-bench 风格编码任务Step 3:启动 RL 训练
命令:
rl_get_current_config() # 查看可配置项
rl_edit_config(field="...", value=...) # 调整超参
rl_start_training() # 启动训练训练启动后,三个进程同时运行:
进程 1: run-api (Atropos 轨迹 API 服务器)
↓
进程 2: launch_training.py (Tinker trainer + SGLang 推理服务器)
↓
进程 3: environment.py serve (RL 环境)硬性要求:GPU
从 rl_training_tool.py 的 LOCKED_FIELDS 配置可以确认:
"openai": [
{
"model_name": "Qwen/Qwen3-8B",
"base_url": "http://localhost:8001/v1", # 本地推理服务器
"server_type": "sglang", # SGLang(GPU 推理框架)
}
]训练时模型会启动一个本地 SGLang 推理服务器,这个服务器必须跑在 GPU 上。
资源需求:
- 单卡 A100/A10G/4090 起步(24GB+ VRAM)
- LoRA 训练 + 近 9K token context 长度
- 训练时长:数小时
监控:
rl_check_status(run_id="...") # 每 30 分钟查一次(限速),返回 WandB 指标
rl_stop_training(run_id="...") # 手动中断WandB 追踪指标:reward_mean、percent_correct、eval/percent_correct
Step 4:LoRA 合并到基座模型
RL 训练输出的不是完整模型权重,而是 LoRA adapter:
tinker-atropos/checkpoints/
├── run_<uuid>/
│ ├── step_00025/
│ │ └── adapter.safetensors # LoRA adapter 权重
│ └── final/
│ └── adapter.safetensorsLoRA adapter 不能单独使用,必须用 merge_lora.py 或类似脚本合并到基座模型,产出新的 safetensors 权重文件。
这一步是手工的:Hermes 代码并没有自动完成这个合并。
Step 5:部署为新模型
四步手工链路:
Step A: LoRA → 合并权重
adapter.safetensors + Qwen3-8B base → merged_model.safetensors
Step B: 合并权重 → SGLang/vLLM 服务
sglang or vllm serve \
--model /path/to/merged_model.safetensors \
--base-url http://localhost:8001/v1
Step C: 注册到 Hermes 模型目录
在 ~/.hermes/config.yaml 中添加 custom provider:
model:
provider: custom
base_url: http://localhost:8001/v1
model: qwen3-8b-hermes-v1
Step D: 运行时切换
/model custom:qwen3-8b-hermes-v1
或修改 config.yaml 的 default_modelHermes 本身不运行任何模型,它只是 OpenAI-compatible API 的客户端。
RL 训练出来的模型只要能通过 HTTP API 对话,就能被 Hermes 使用。
完全不需要改动 Hermes 代码,只需要正确配置 base_url 和 model 字段。
慢循环的断点分析
环节 | 状态 |
|---|---|
1. 轨迹收集 → JSONL | ✅ 自动(batch_runner.py) |
2. JSONL → RL 训练 | ✅ 需人工准备数据、手动调用工具 |
3. RL 训练 → 新权重 | ✅ rl_training_tool.py 实现 |
4. 新权重 → 部署为新模型 | ❌ 需人工操作 |
5. 新模型 → 成为默认 base model | ❌ 需人工修改配置 |
6. 新轨迹 → 重新训练 | ❌ 无自动触发机制 |
自动化的缺失在 Step 4→5 之间:
没有 cron job 或触发器自动把训练好的新模型纳入 Hermes 的模型池,也没有自动将高质量轨迹重新喂入下一轮训练。
整个慢循环靠人工判断节奏和质量阈值来驱动。
两条路径的协作关系
DSPy + GEPA:快循环的自动化升级
前面讲的四个闭环学习机制,还可以进一步自动化:通过 DSPy + GEPA 方法(ICLR 2026 Oral 论文)。
运行流程:
读取当前技能/提示
↓
生成评估数据集
↓
GEPA 优化器读取执行轨迹来理解为什么失败(不只是知道失败)
↓
生成候选变体
↓
约束门控(测试套件 100% 通过 + 技能文件不超过 15KB + 工具描述不超过 500 字符 + 语义不偏离原始目的)
↓
选出最佳变体 → PR 提交 → 人工审核成本:单次优化运行约 $2-10,全部通过 API 调用完成。
慢循环总结:
当前状态:
- Phase 1(技能文件优化):已实现
- Phase 2-5(工具描述、系统提示、工具实现代码、持续改进管线):计划中
从代码实现可以看出官方实现自我学习的思路:
- 先用 DSPy + GEPA 把提示优化到极致(分钟级迭代,成本低)
- 再用快循环的四个闭环机制持续改进技能(自动化程度高)
- 当提示已经最优但模型能力跟不上时,才考虑 RL 训练(小时级训练,成本高)
大多数情况下,步骤 1+2 就已经能解决 80% 的问题。
真正需要训模型的时候,往往是模型本身的推理能力瓶颈,而不是"指令写得不够好"。
数据飞轮需要训练能力吗
数据飞轮有两种,只有训练权重的慢循环需要训练环境。
常人日常使用,改进提示/技能足够用。
飞轮层级 | 需要训练环境 | 成本 | 速度 |
|---|---|---|---|
改提示/技能(快循环) | 不需要 | 低($2-10) | 快(分钟级) |
改模型权重(慢循环) | 需要(GPU) | 高(算力成本) | 慢(小时级) |
附录:Hermes Agent 自我改进机制清单
机制 | 类型 | 优化对象 | 资源需求 | 自动化程度 |
|---|---|---|---|---|
定期自省 Nudge | 快循环 | 行为约束 | 无 | 自动触发 |
自主技能创建 | 快循环 | SKILL.md | 无 | Agent 自动调用 |
技能自我优化 | 快循环 | SKILL.md | 无 | Agent 自动调用 |
跨会话搜索 | 快循环 | 记忆检索 | 无 | Agent 自动调用 |
DSPy + GEPA | 快循环 | prompts/skills | API 调用 | 半自动(需人工审核 PR) |
RL 训练 | 慢循环 | 模型权重 | GPU | 手工触发 + 手工部署 |
基于 Hermes Agent v0.9.0 源码分析。
-END-
推荐阅读:
8小时从零构建Linux桌面 |最强开源模型 GLM-5.1
开源语音 AI:3 秒克隆声音,支持 9 种语言 — Voxtral TTS
490万浏览量的方案:用 LLM 构建持续更新积累的个人知识库
给 OpenClaw 接入10000+工具和数据,为你盯盘,给出独家策略
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号