破解无样本难题 | 无监督工业缺陷检测技术概述

破解无样本难题 | 无监督工业缺陷检测技术概述

OpenCV学堂
发布于 2026-04-02 20:44:37
发布于 2026-04-02 20:44:37
在工业制造领域,产品质量是生命线,而表面缺陷检测是保障产品质量的关键环节。传统的人工检测方法效率低下、容易疲劳且标准不一,而基于有监督深度学习的方案需要大量带有缺陷标注的数据进行训练,这在工业场景中极难获取(因为良品率高,缺陷样本稀少且形态多变)。
无监督缺陷检测优势
无监督缺陷检测技术彻底颠覆了传统模式。其核心思想是:仅使用大量的“正常”(无缺陷)样本进行训练,学习正常产品的模式和分布。在推断时,任何偏离该“正常”模式的区域都会被识别为缺陷。 这种方法完美解决了缺陷样本稀缺、形态未知的难题,成为工业AI落地最成功的领域之一。
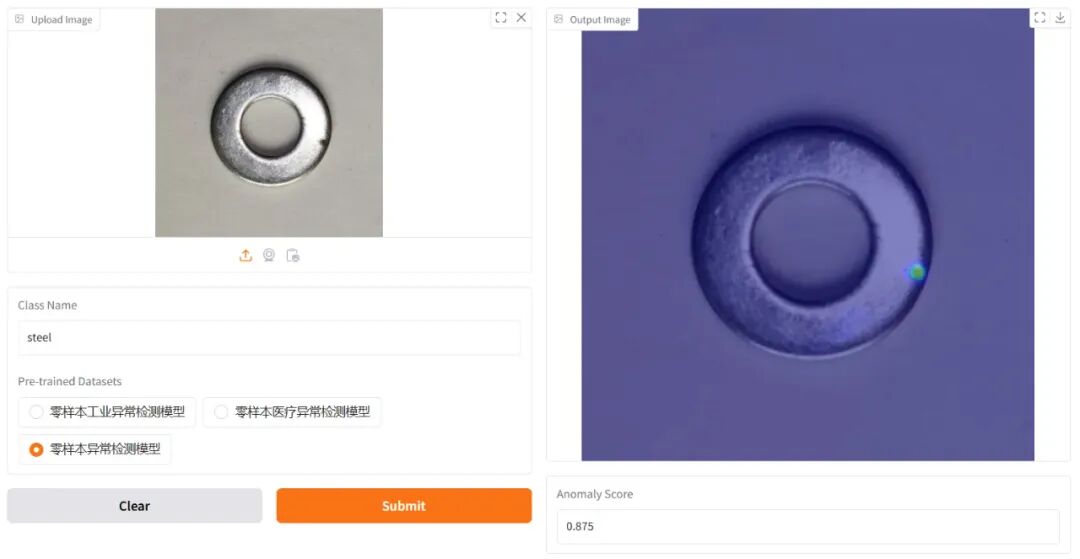
无监督缺陷检测的核心优势
无需缺陷样本:
仅需正常样本即可训练,极大降低了数据收集和标注的成本与难度。
检测未知缺陷:
不对任何特定缺陷进行学习,因此对于从未见过的、新的缺陷类型也具备检测能力。
高适应性与可扩展性:
训练完成后,可快速部署到相似的新产品线上,迁移成本低。
一致性高:
避免了人工检测的主观性和疲劳问题,提供稳定、可靠的检测结果。
典型应用场景
新能源:锂电池极片、隔膜的涂覆缺陷、划痕、粉尘检测。
半导体:硅片、芯片表面的污染、刮伤、裂纹检测。
纺织业:布匹的破洞、污渍、色差、经纬度问题检测。
金属加工:钢板、铝材表面的凹坑、辊印、氧化斑检测。
食品医药:包装瓶罐的瑕疵、标签错贴、药品杂质检测。主流模型介绍
01
1. Padim模型
核心思想:
PaDiM是一个里程碑式的模型。它认为图像中每个局部图像块(Patch)的特征都服从一个多元高斯分布。训练时,它为每个位置(i, j)估计一个高斯分布 N(μ_ij, Σ_ij),其中均值μ代表该位置正常的特征,协方差Σ代表正常特征允许的波动范围。
工作流程:
使用预训练CNN(如ResNet)提取多层级特征,以获得不同尺度的信息。将每个位置的特征拼接起来,形成一个高维特征向量。为每个位置估计高斯参数(μ, Σ)。检测时,计算测试图像每个位置的特征向量到其对应高斯分布的马氏距离(Mahalanobis Distance),距离越大,该处是缺陷的概率就越高。
特点:
简单有效,同时利用了空间信息和特征相关性,生成了高质量的分割图。
02
PatchCore
核心思想:
PatchCore可以看作是PaDiM思想的一个高效且强大的演进。它认为存储一个庞大的、具有代表性的“正常特征记忆库”比拟合一个参数化分布(如高斯)更有效、更精确。
工作流程:
特征提取与缓存:使用宽预训练网络(如Wide-ResNet)提取所有正常训练图像的多层级特征,并构建一个巨大的“记忆库”(Memory Bank),其中包含了海量的正常模式特征块。
核心集降采样:由于记忆库过于庞大,直接搜索效率低下。PatchCore采用贪心核心集采样(Coreset Sampling) 算法,从海量特征中选取一个最小的子集,这个子集能够最大限度地代表原始特征集的分布。
异常检测:对于测试图像,提取其特征,并在降采样后的核心集记忆库中为每个测试特征寻找其最相似的最近邻(Nearest Neighbor)正常特征。两者之间的距离(如欧式距离)即为异常分数。距离越远,异常可能性越高。
特点:通过记忆库和核心集技术,它几乎完全保留了正常的细节信息,对微小缺陷极其敏感,且检测速度极快,非常适合工业实时检测。
03
WinCLIP模型
核心思想:
随着视觉-语言大模型(如CLIP)的崛起,WinCLIP巧妙地将缺陷检测问题转化为一个视觉-语言匹配问题。它无需训练特征提取器,直接利用CLIP强大的图文理解能力。

工作流程:
提示构建:定义一系列文本提示(Text Prompts),例如:“[Category] with [Defect]”。[Category] 是产品类别(如“hazelnut”),[Defect] 是缺陷描述(如“a crack”, “a scratch”, “good”)。
窗口特征提取:将测试图像滑动切割成多个小窗口(Windows)。
语义匹配:使用CLIP模型计算每个图像窗口与所有文本提示的相似度得分。例如,一个包含裂纹的窗口与“hazelnut with a crack”的相似度会远高于与“hazelnut good”的相似度。
异常评分:基于这些相似度得分,通过某种聚合策略(如最大异常分数)为每个窗口计算最终的异常分数。
特点:
真正的“零样本”(Zero-Shot) 检测,无需任何训练数据(正常样本也不需要)。开箱即用,特别适合快速原型验证和缺乏训练数据的极端场景。但其性能严重依赖文本提示词的设计,通常不及在特定数据集上训练过的PatchCore。
04
AnomalyCLIP / AdaClip
核心思想:
这类模型是WinCLIP的增强版,旨在解决WinCLIP的痛点——即提示词工程(Prompt Engineering)的难题和领域适应性。它们引入了自适应(Adaptation) 机制。
工作流程(以核心思想为例):
知识蒸馏:虽然仍然使用CLIP,但它们会利用少量的正常样本(或甚至无样本)来“微调”或“引导”模型。
自适应提示学习:不再手动设计文本提示,而是通过模型自动学习与当前任务最相关的提示词嵌入(Prompt Embeddings)。例如,AdaClip会优化提示向量,使其能更好地区分正常和异常模式。
特征对齐:将图像特征与自适应生成的文本特征在CLIP空间中进行更好的对齐,从而提升判别能力。
特点:
在保留零样本/少样本能力的同时,通过自适应学习弥补了WinCLIP的不足,性能更接近有监督训练的模型,灵活性和准确性更高。
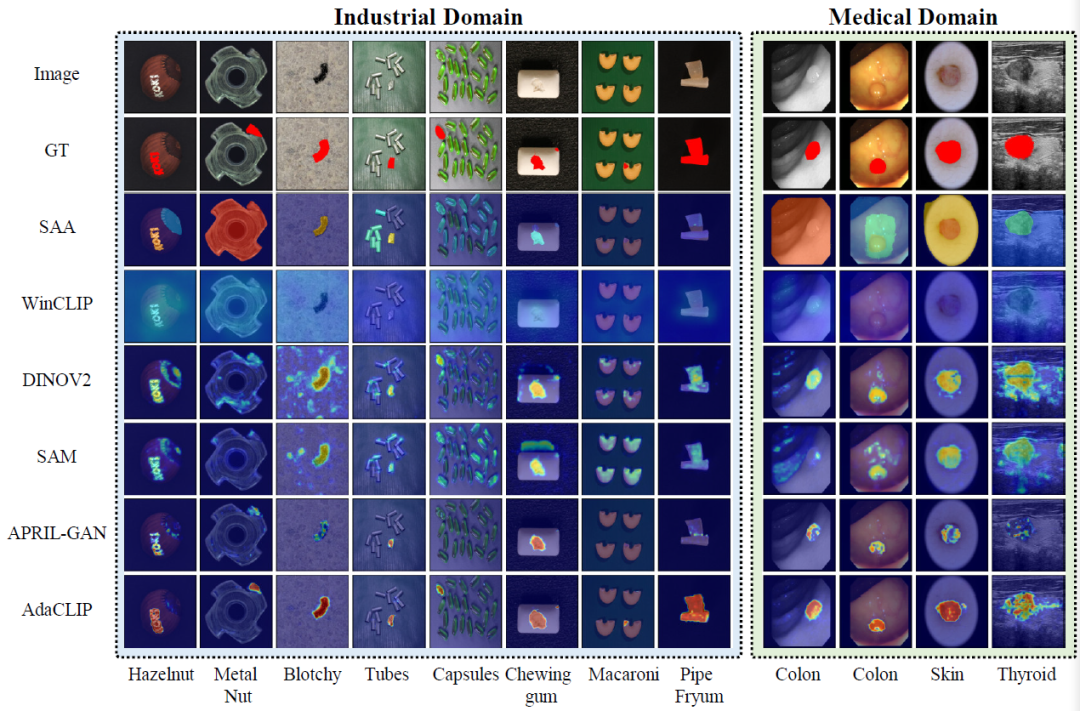
总结
选择哪种方案取决于具体的应用需求:追求极致性能且拥有正常样本,PatchCore是首选;需要快速验证或没有任何数据,WinCLIP系列提供了全新的解决方案。未来,随着大模型与特定领域知识的进一步融合,无监督缺陷检测必将变得更加精准、高效和普惠,成为“工业4.0”时代不可或缺的基石技术。
划重点:
想要学会无监督先搞懂深度学习跟大模型部署推理是第一步!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号