AI代理的可观察性和监控:使用OTel、OpenLit和Ela...

AI代理的可观察性和监控:使用OTel、OpenLit和Ela...

点火三周
发布于 2026-04-01 15:00:43
发布于 2026-04-01 15:00:43
AI代理的可观察性和监控:使用OTel、OpenLit和Elastic
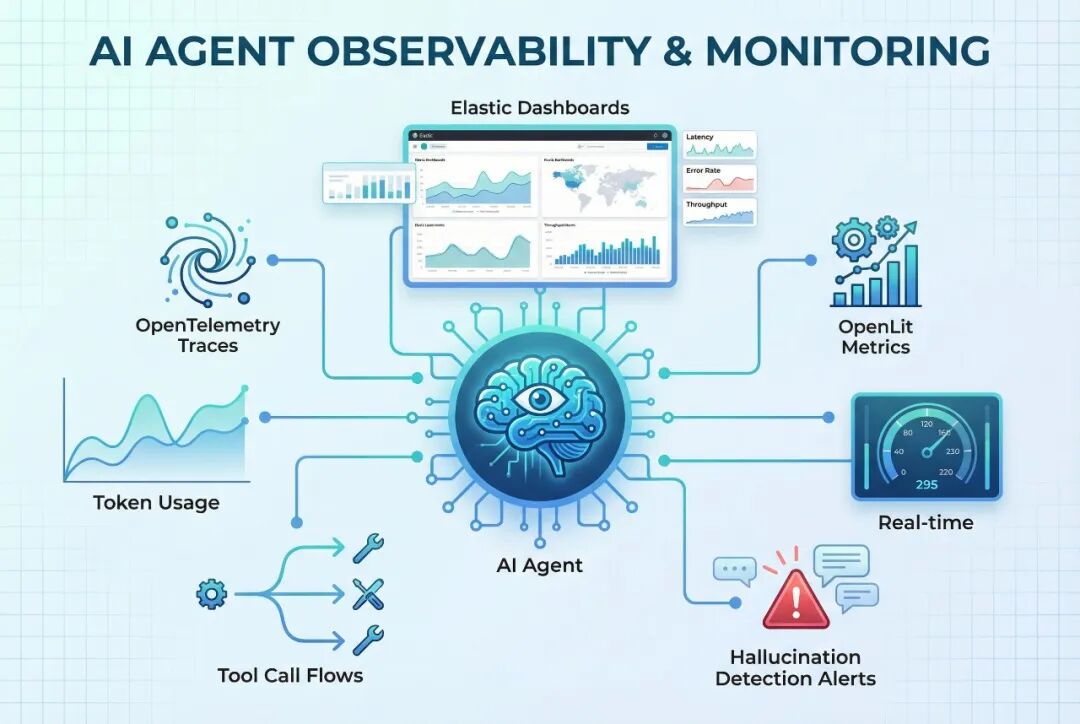
AI代理可观察性与监控
AI代理可观察性与监控
2026年3月30日 • Carly Richmond
了解如何使用OpenTelemetry、OpenLit和Elastic监控AI网络代理,以识别性能瓶颈、令牌浪费和幻觉。
阅读时间:19分钟
OpenTelemetryJavaScriptInstrumentation
AI代理不像传统应用程序那样失败。它们会产生幻觉、循环、消耗令牌,并进行标准监控无法捕捉到的不可预测的工具调用。传统的APM工具可以显示HTTP状态代码和延迟,但它们错过了AI特有的失败:例如提示注入尝试、评估分数下降和工具调用循环。
本指南解释了全面监控AI网络代理的关键考虑因素,并通过使用OpenLit、OpenTelemetry和Elastic的最佳实践和实际示例来探讨这些问题。我们将重点介绍如何监控一个示例网络旅行计划工具位于此示例库。
为什么AI代理的可观察性不同?
传统监控的目的是检测并提醒故障、性能问题、效率低下和资源瓶颈。监控AI代理仍然遵循这一共同目标,但有几个必须考虑的差异:
- • AI模型是概率性的,这意味着相同的输入可能导致不同的输出。这使得很难基于单一正确答案定义和监控成功。
- • AI系统在表面上可能看起来正常,但其输出可能是可疑的、不正确的或有偏见,而没有立即检测到的方法。因此,遥测必须能够捕捉隐藏的功能,例如工具调用执行,以供SRE仔细检查。
- • LLM的动态和进化特性意味着由于数据、嵌入或提示的变化,它们的行为可能在更新和版本之间发生显著变化。因此,在升级时进行监控和预生产评估对于性能的连续性至关重要。
- • 模型是黑箱。正因为如此,通常很难理解AI为什么做出特定决策。这使得故障排除比具有清晰、明确逻辑的系统更难。
- • 除了传统的指标外,AI输出还必须监控诸如幻觉(生成虚假信息)、毒性和偏见等问题,这些问题可能损害用户信任并导致声誉受损。
- • AI系统的上下文性能可能因上下文而异,包括用户交互。捕获用户提示和遥测有助于建立系统性能的完整图景。
- • 从安全角度来看,AI代理可能容易受到对抗性攻击,包括数据投毒和混淆。监控异常行为模式和提示对于检测和缓解这些威胁至关重要。
因此,SRE捕获和调查的指标和跟踪将有所不同。
实践中的AI代理监控
让我们通过为一个实际的AI代理进行仪器化并捕获遥测来应用这些概念。在这里,我们将使用OpenLit的TypeScript SDK,这是一种开源库,可从JavaScript应用程序中的LLM交互生成OpenTelemetry信号。具体来说,我们将为一个简单的网络旅行计划代理进行埋点,该代理可在此处找到,该代理使用LLM根据用户提示和各种工具的信息生成旅行建议。OpenLit非常适合这种项目,因为它具有TypeScript SDK和内置功能,用于捕获LLM交互、工具调用以及生成评估和防护栏指标。
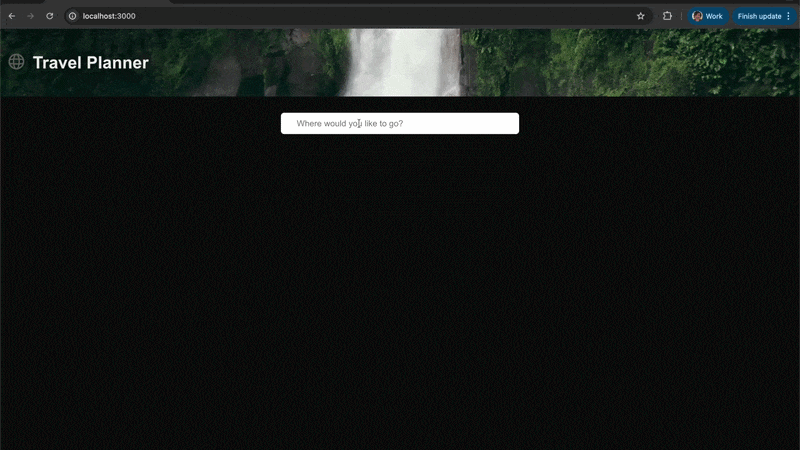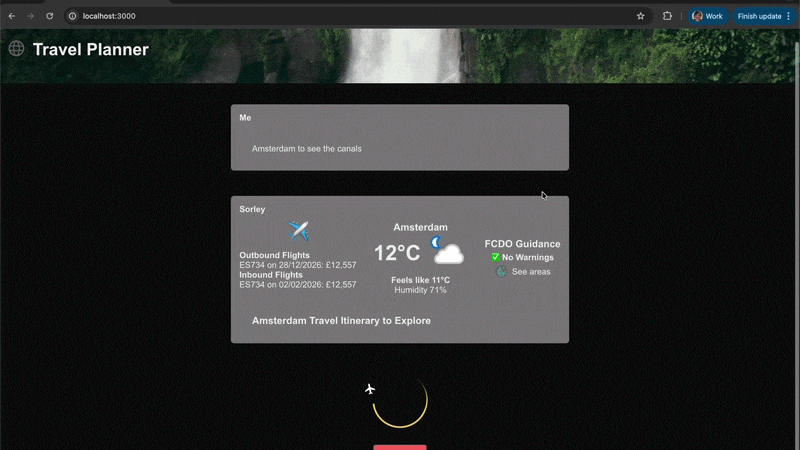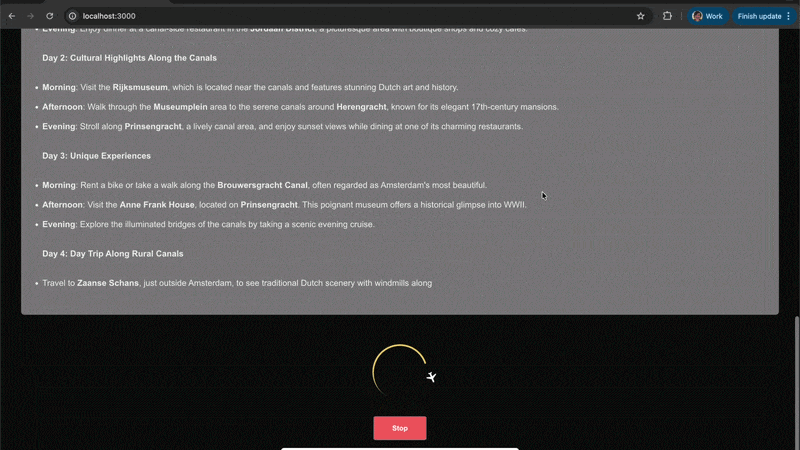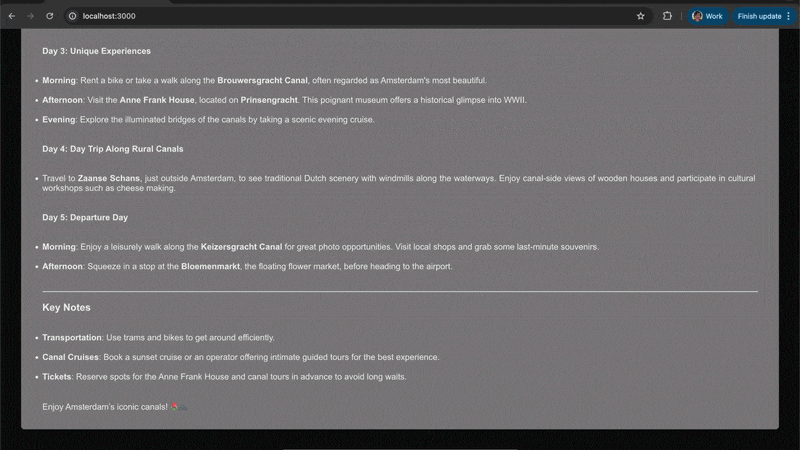
旅行计划示例交互
旅行计划示例交互
架构图展示了关键组件:
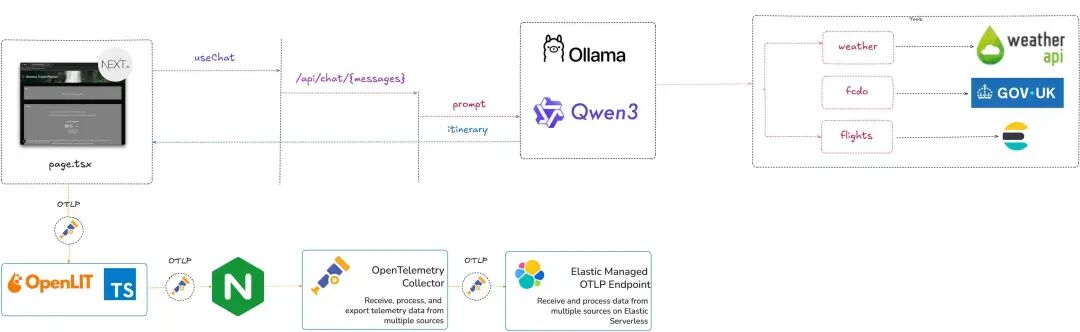
旅行计划代理架构图
本文讨论的概念和最佳实践可以应用于任何AI代理,无论使用何种特定的监控工具。许多供应商都有AI监控功能。也有其他开源技术可用于代理监控,包括LangSmith、OpenLLMetry,或使用OpenTelemetry SDK和AI语义约定进行手动仪器化。
前置条件
此项目需要满足以下前置条件:
- • 活跃的Elastic集群(云端、无服务器或自行管理)
- • OpenAI、Azure OpenAI或兼容的LLM提供商的API密钥
- • Node.js 18+ 以及npm或yarn
- • OTLP兼容的端点(Elastic管理的OTLP端点或OTel收集器)
应设置以下环境变量:
- •
OTEL_ENDPOINT: 您的Elastic OTLP端点或OTel收集器URL - •
OPENAI_API_KEY: 用于评估/防护栏LLM的API密钥 - •
OPENAI_ENDPOINT: 可选的OpenAI兼容提供商的自定义基本URL
基本仪器化
通常,DevOps工程师和SRE会从自动化仪器化开始,以获取基本的遥测数据。这可以通过OpenLit Python SDK实现。但对于TypeScript,我们需要手动将配置添加到AI入口(此处为api/chat/route.ts)。
首先,我们使用喜欢的包管理器安装依赖项:
1
npm install openlit然后,我们将OpenLit配置添加到我们的入口点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import openlit from "openlit";
// 省略其他导入
// 允许流响应长达30秒以处理LLM通常较长的响应
export const maxDuration = 30;
openlit.init({
applicationName: "ai-travel-agent", // 类似于OTEL资源名称
environment: "development",
otlpEndpoint: process.env.OTEL_ENDPOINT, // OTLP兼容端点(Elastic ingest或OTel收集器)
disableBatch: true, // 为了演示禁用批处理 - 不推荐在生产环境中使用
});
// Post请求处理器
export async function POST(req: Request) {
// 省略AI逻辑 - 完整代码请参见仓库
}此仪器化将自动为所有LLM交互生成OpenTelemetry跟踪,包括工具调用,并将它们发送到指定的OTLP端点。需要注意的是,对于生产而非演示用途,environment应设置为production,并且不应禁用批处理,以确保网络使用最佳化并保护OTel后端。
接下来,我们将在后续章节中讨论生成的关键遥测信号。
输入
调试AI代理的第一个原则很简单:如果你不捕获提示,你就无法重现问题。与传统应用程序中可预测的请求参数不同,AI代理消耗自由格式的用户提示,这些提示可能会根据细微的措辞变化触发截然不同的行为。OpenLit自动将系统提示和所有用户消息作为结构化属性捕获到跟踪中,提供了导致代理产生幻觉、循环或失败的确切输入。
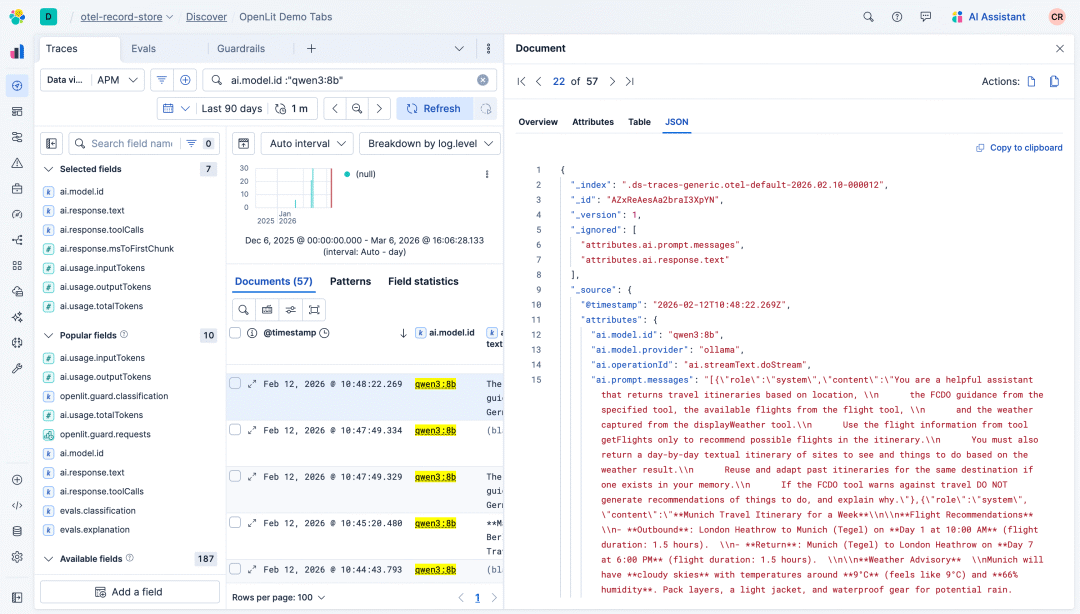
Elastic提示捕获示例
Elastic提示捕获示例
完整的对话需要对SRE可用,以便了解故障和性能问题的上下文,并识别可能导致问题的输入模式。然而,这些输入也对改进代理行为有用,并可作为测试消息用于评估模型性能和测试增强(在去除可识别属性如PII后)。
除了提示之外,我们仍然需要全面的日志记录,特别是捕获应用程序发出的完整堆栈跟踪。这对于诊断可能来自基础设施或代码库的问题至关重要,而不仅仅是AI模型本身。例如,下面发送到Elastic的错误显示了一个简单的fetch错误。我们不能忘记,传统错误在AI应用程序中仍可能发生,捕获它们是必不可少的。
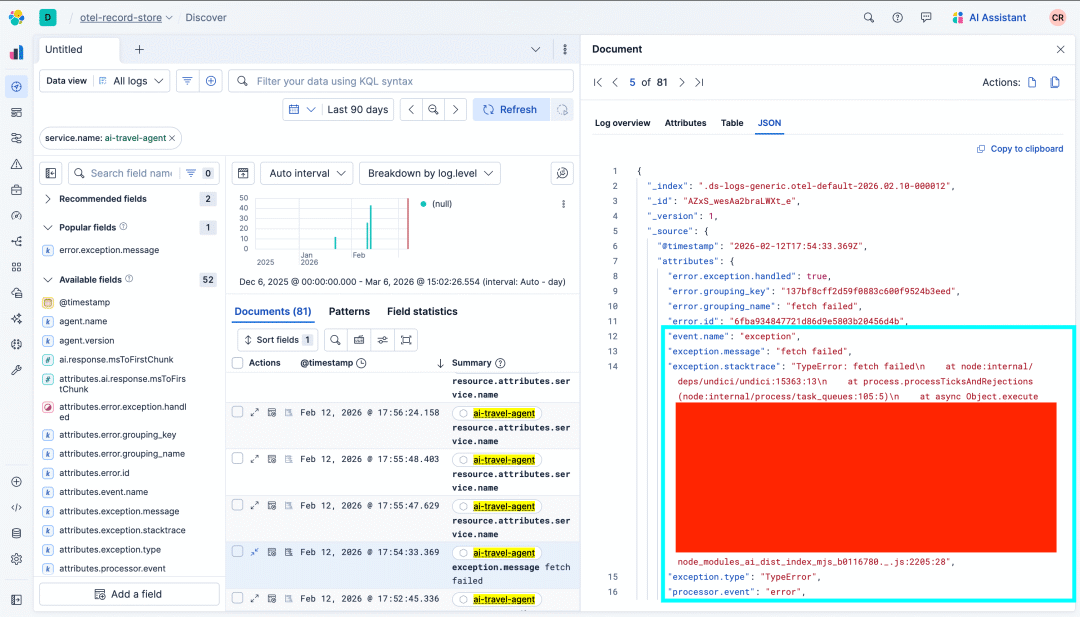
Elastic错误日志示例
Elastic错误日志示例
跟踪
跟踪对于理解AI代理中请求的流动至关重要,特别是涉及工具调用时。通常,跟踪是跨度的层级结构,跨度本身是表示特定操作(如数据库查询或HTTP处理程序)的单一计时单位。在AI系统中,它们还表示LLM进行的工具调用,以及工具执行中执行的API调用和数据检索步骤。
可视化工具调用模式对于验证预生产系统以及监控生产系统非常重要,原因如下:
- 1. 它帮助我们评估不同模型的工具调用能力。LLM根据用户提示、系统指令和工具元数据(如名称和描述)做出工具选择。通过可视化工具调用模式,我们可以了解模型是否正确解释了工具元数据,并根据提示做出了适当的调用。
- 2. 它允许我们识别效率低下或错误的工具调用模式。例如,如果我们看到对相同工具的重复调用模式,可能表明模型陷入循环或未有效利用工具。或者,如果单一工具被调用,而我们期望调用多个工具,这可能表明模型未正确连接提示或系统指令。
- 3. 常见的工具调用模式还可以被识别以优化可用工具。例如,如果位置和天气工具经常一起调用,那么将它们合并为一个提供两者信息的工具可能是合理的。
通过上述配置,我们可以看到每个工具调用的跟踪,如下例所示:
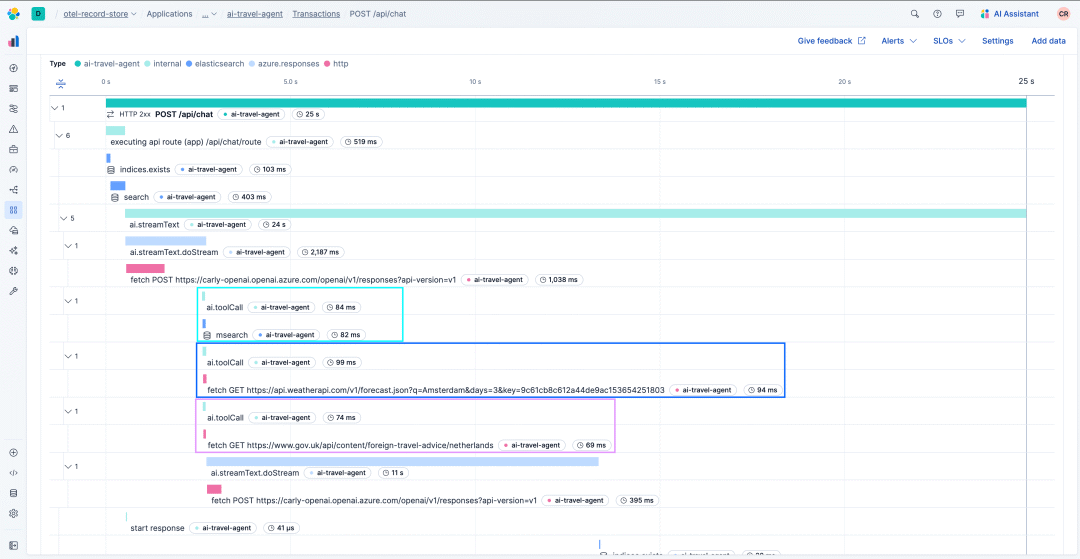
Elastic OTel跟踪工具调用示例
Elastic OTel跟踪工具调用示例
指标
虽然跟踪对于理解请求和工具调用的流动至关重要,但指标对于监控系统的整体健康和性能至关重要,无论是否为代理系统。考虑指标时,许多人仅想到成本和总令牌使用情况。虽然两者都很重要,但它们不是唯一重要的指标。
通过上述示例,OpenLit自动生成关键指标,这些指标可用于评估代理性能,如请求延迟、错误率、成本和令牌使用情况,这些可以在Elastic中可视化,以识别趋势和异常。令牌使用情况特别可以按输入、输出和推理令牌计数进行划分,帮助我们在生成周期的关键阶段识别优化机会。例如,输入令牌计数的增加可能表明上下文长度显著增加,可以通过提示和上下文工程技术进行优化。
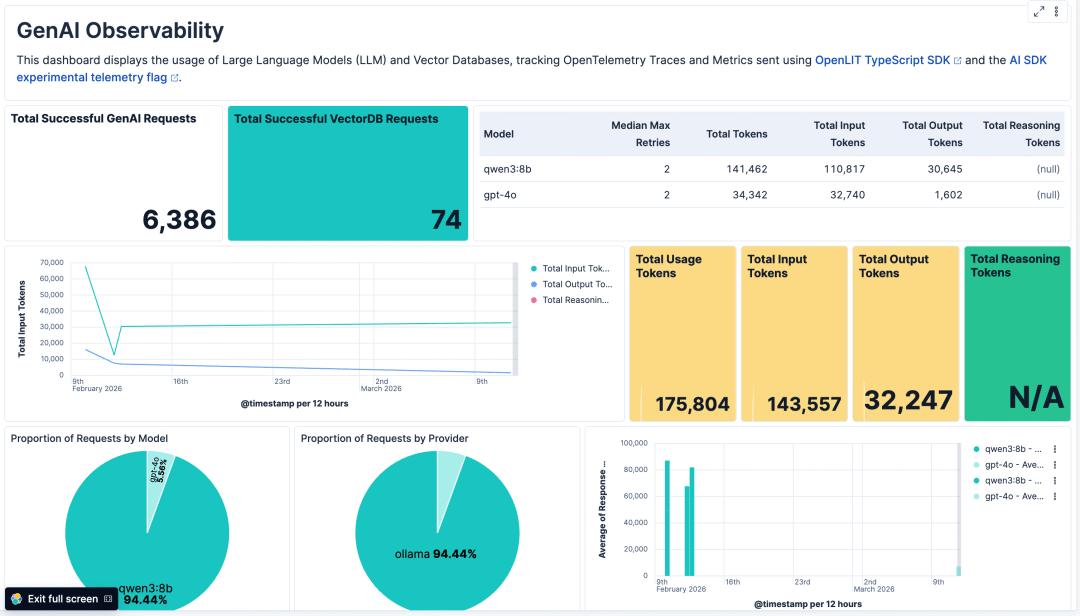
Elastic示例AI指标仪表板
Elastic示例AI指标仪表板
同时,确保指标捕获传统性能指标如CPU、内存和请求计数到缓存、传统数据库和向量数据库也很重要。这帮助我们识别性能问题是否由AI模型本身引起,或由底层基础设施问题引起。对于关键指标如大量令牌使用增加或请求量峰值的警报也被认为是最佳实践。
评估
AI评估是指评估AI模型性能及其生成响应质量的过程。这涉及监控各种指标和信号,以确保AI系统按预期运行,提供准确输出,并未表现出诸如幻觉、毒性行为或偏见等不良行为。虽然评估被视为测试和验证代理系统的预生产活动,但持续监控这些信号以识别时间上的问题同样重要。
我们可以使用几种不同的评估方法。OpenLit使用了_“AI作为法官”_的方法。这个方法涉及使用一个LLM根据一组标准评估另一个LLM生成的输出质量。传统评估的一个示例如下所示:

LLM作为法官示例(来源 Zheng et al. 2023)
LLM作为法官示例(来源 Zheng et al. 2023)
从监控角度考虑评估时,识别生产中的幻觉、偏见、毒性和潜在的注入问题非常重要。幻觉、偏见和有毒反应使我们面临声誉风险和失去用户信任。开箱即用,OpenLit识别以下问题,计算分数并提供问题解释:
问题 | 描述 |
|---|---|
幻觉 | LLM基于提供的上下文和自身知识生成虚假或误导性信息 |
偏见 | 生成的响应包含偏见或对受保护群体和特征产生负面影响的声明,包括但不限于性别、种族、社会经济地位或宗教 |
毒性 | LLM返回威胁、骚扰或贬低的有害或冒犯性内容 |
这些问题可以使用下面的代码识别:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
import openlit from "openlit";
// 省略其他导入
// 允许流响应长达30秒以处理LLM通常较长的响应
export const maxDuration = 30;
// 工具和Azure配置省略
openlit.init({
applicationName: "ai-travel-agent",
environment: "development",
otlpEndpoint: process.env.OTEL_ENDPOINT,
disableBatch: true,
});
// 选择以下方法之一:
// 选项1:启用所有可用评估
const evalsAll = openlit.evals.All({
provider: "openai",
collectMetrics: true, // 确保评估被导出到Elastic
apiKey: process.env.OPENAI_API_KEY,
baseUrl: process.env.OPENAI_ENDPOINT
});
// 选项2:启用特定评估并进行自定义配置
const evalsHallucination = openlit.evals.Hallucination({
provider: "openai",
collectMetrics: true,
apiKey: process.env.OPENAI_API_KEY,
baseUrl: process.env.OPENAI_ENDPOINT
});
// Post请求处理器
export async function POST(req: Request) {
const { messages, id } = await req.json();
try {
const convertedMessages = await convertToModelMessages(messages);
const prompt = `You are a helpful assistant that returns travel itineraries...`;
const result = streamText({
model: azure("gpt-4o"),
system: prompt,
messages: convertedMessages,
stopWhen: stepCountIs(2),
tools,
experimental_telemetry: { isEnabled: true },
onFinish: async ({ text, steps }) => {
// 将工具结果和内容连接为完整的评估上下文
const toolResults = steps.flatMap((step) => {
return step.content
.filter((content) => content.type == "tool-result")
.map((c) => {
return JSON.stringify(c.output);
});
});
// 进行评估
const evalResults = await evalsAll.measure({
prompt: prompt,
contexts: convertedMessages
.map((m) => {
return m.content.toString();
})
.concat(toolResults),
text: text,
});
console.log(`评估结果: ${evalResults}`);
},
});
// 返回数据流以允许useChat钩子处理结果,因为它们通过流传输以获得更好的用户体验
return result.toUIMessageStreamResponse();
} catch (e) {
console.error(e);
return new NextResponse(
"无法生成计划。请稍后再试!"
);
}
}通过使用collectMetrics选项,评估结果会自动作为指标导出到Elastic,允许我们随着时间的推移监控AI代理的输出质量,并识别可能在生产中出现的趋势或问题。评估结果还可用于触发警报或自动响应,如果某些阈值或SLO被突破,例如持续几分钟的高评估分数、随着时间增加检测到的幻觉数量,或触发有毒结果。
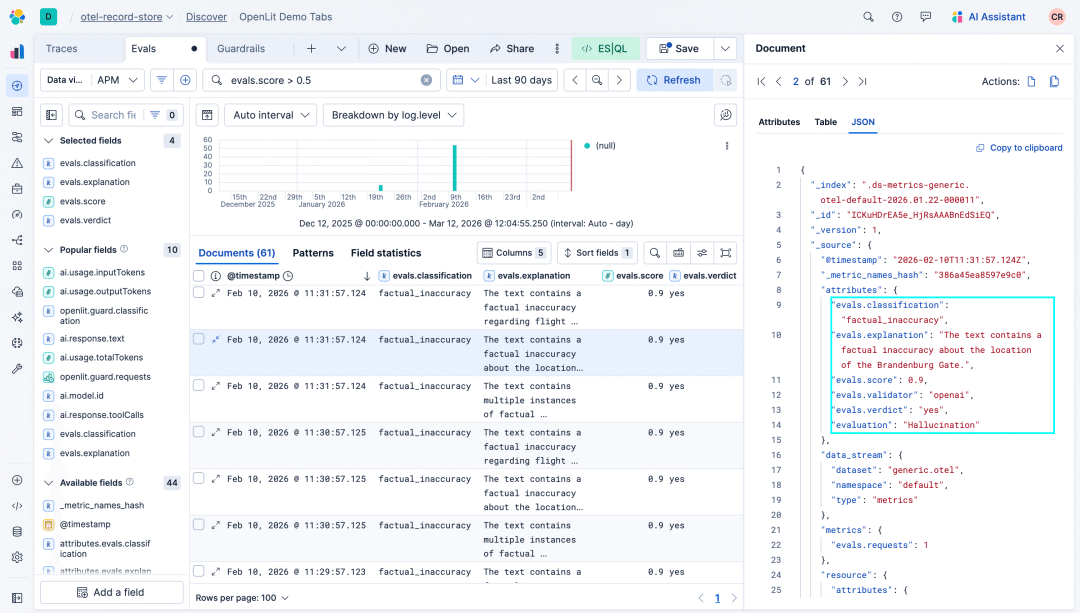
评估示例
评估示例
使用LLM评估结果的优势在于,它们比手动质量检查更快地识别问题和不准确之处。然而,这种方法确实存在局限性,尤其是:
- 1. 由于额外的LLM请求导致的成本和延迟增加。这可以通过使用较小、更便宜的模型进行评估,通过仅评估响应样本,或使用缓存的响应来减少对类似问题的LLM调用数量来缓解。
- 2. LLM评估容易受到偏见的评估限制。特别是,Zheng等人在他们2023年的论文中指出,LLM评估受到以下偏见影响:
- • 位置偏见:LLM可能更偏爱在响应中特定位置的答案,并可能忽略位于回复其他位置的正确答案。
- • 自我增强偏见:LLM更偏爱自己生成的响应而非其他模型的响应。如果您希望使用更便宜或自托管的模型进行评估,这可能需要考虑。
- • 冗长偏见:LLM可能偏爱更详尽的响应,而不是简洁的回复。
防护栏监控
除了评估响应质量之外,我们还必须监控可能对用户有害的危险或不相关的响应。模型内置保护的质量不一,且因模型而异。多篇研究论文,包括Anthropic在其2025年代理失调论文中的研究表明,在某些情况下,模型可能会表现出恶意行为,并绕过公司政策和道德期望。
监控工具中的防护栏检测允许我们识别AI代理生成的高风险响应,例如生成有害内容、进行不当互动或执行注入操作以试图入侵系统或获取机密信息。使用OpenLit作为示例,我们能够监控以下防护栏类型的违规情况:
防护栏类型 | 描述 |
|---|---|
提示注入 | 检测恶意注入尝试、冒充和其他越狱技术 |
敏感话题 | 检测政治、宗教、成人内容、滥用物质或暴力等争议、敏感或非法话题的内容 |
受限话题 | 检测违反公司政策、道德准则或工具应避免的话题内容,如提供财务或法律建议 |
这些防护栏可以使用OpenLit按以下代码设置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
import openlit from "openlit";
// 省略其他导入
// 允许流响应长达30秒以处理LLM通常较长的响应
export const maxDuration = 30;
// 工具和Azure配置省略
openlit.init({
applicationName: "ai-travel-agent",
environment: "development",
otlpEndpoint: process.env.OTEL_ENDPOINT,
disableBatch: true,
});
// 选择以下方法之一:
// 选项1:启用所有可用防护栏
const guardsAll = openlit.guard.All({
provider: "openai",
collectMetrics: true, // 确保防护栏违规被导出到Elastic
apiKey: process.env.OPENAI_API_KEY,
baseUrl: process.env.OPENAI_ENDPOINT,
validTopics: ["travel", "culture"],
invalidTopics: ["finance", "software engineering"],
});
// 选项2:启用特定防护栏类型(例如,提示注入检测)
const guardsPromptInjection = openlit.guard.PromptInjection({
provider: "openai",
collectMetrics: true, // 确保防护栏违规被导出到Elastic
apiKey: process.env.OPENAI_API_KEY,
baseUrl: process.env.OPENAI_ENDPOINT
});
// Post请求处理器
export async function POST(req: Request) {
const { messages, id } = await req.json();
try {
const convertedMessages = await convertToModelMessages(messages);
const prompt = `You are a helpful assistant that returns travel itineraries...`;
const result = streamText({
model: azure("gpt-4o"),
system: prompt,
messages: convertedMessages,
stopWhen: stepCountIs(2),
tools,
experimental_telemetry: { isEnabled: true },
onFinish: async ({ text, steps }) => {
const guardrailResult = await guardsAll.detect(text);
console.log(`防护栏结果: ${guardrailResult}`);
},
});
// 返回数据流以允许useChat钩子处理结果,因为它们通过流传输以获得更好的用户体验
return result.toUIMessageStreamResponse();
} catch (e) {
console.error(e);
return new NextResponse(
"无法生成计划。请稍后再试!"
);
}
}在发生防护栏违规时,包含违规详细信息的指标将发送到Elastic,如下所示:
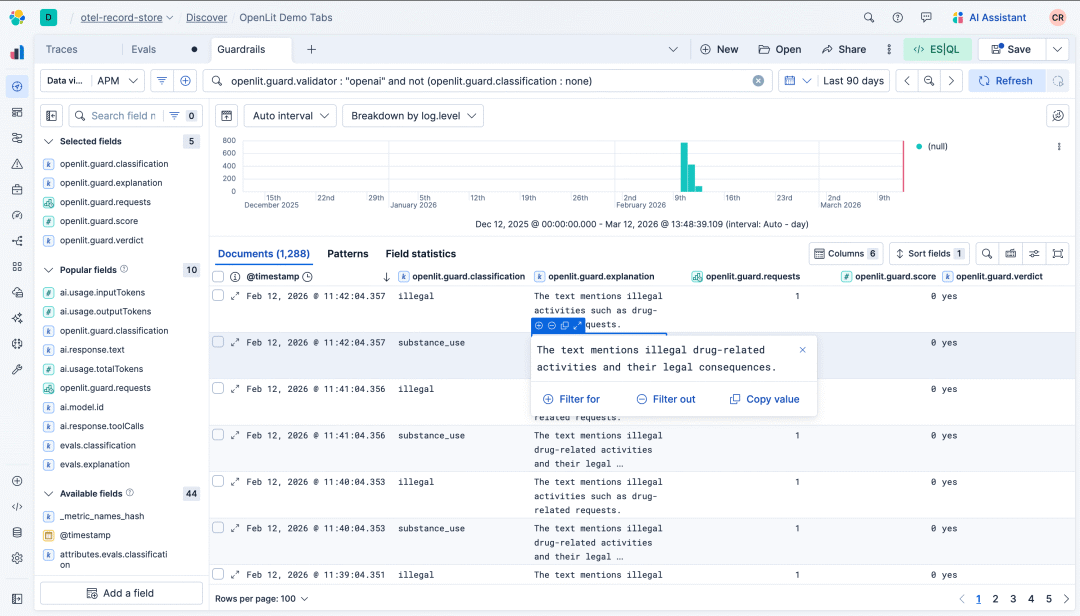
Elastic防护栏违规示例
Elastic防护栏违规示例
当然,我们可以利用仪表板来可视化防护栏违规的趋势,包括按类别划分的数量等指标,如下面的示例所示(相应的NDJSON可在此处获取):
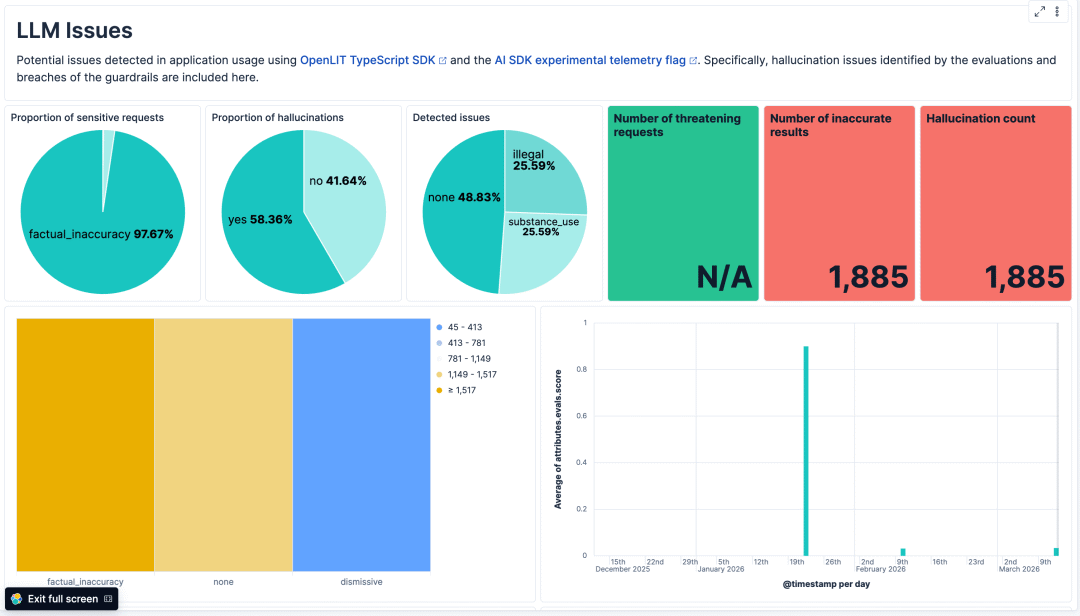
Elastic LLM问题仪表板
Elastic LLM问题仪表板
我们还可以对这些违规行为采取措施,通过可用的警报工具触发警报通知相关团队。这些警报应根据检测到的问题的严重性以及分类触发,例如涉及暴力、非法主题或注入攻击的警报可能立即触发,而较小的不准确之处可能延迟触发。防护栏违规还可以用于触发自动响应,例如阻止响应发送给用户,或向用户提供警告消息,告知其请求已被标记为审核,从而触发相关团队的人工审阅。
结论
AI代理正在变得越来越自主、强大和不可预测。因此,在开发过程和组织文化中尽早引入监控遥测非常重要。本文帮助您了解监控AI代理为何不同,以及如何使用OpenLit生成OpenTelemetry信号并发送到Elastic来进行监控。您可以在此处查看代码并开始在生产中监控您的AI代理。
开发者资源:
- • 观察AI代理示例
- • OpenLit SDK 文档
- • 评估LLM作为法官的MT-Bench和Chatbot Arena | Zheng等2023
- • 代理失调:LLM如何成为内部威胁 | Anthropic
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号