Transformer位置编码的深度解析


1
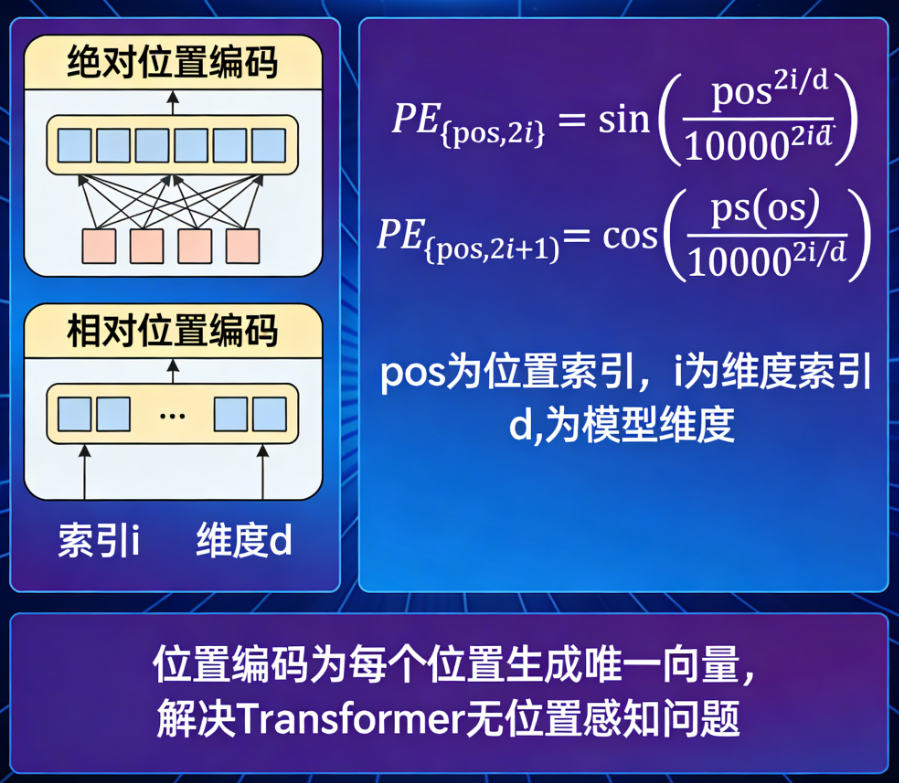
位置编码是什么?
一句话定义 :位置编码是加到输入序列每个元素上的一个向量,用来告诉模型该元素在序列中的位置(或相对位置)。
假设输入是一个长度为 n的序列,每个元素用一个 d维向量表示(例如词嵌入),将这些向量堆叠成矩阵 $X \in R^{n \times d}$。形式 上 看,对于一个长度为 n 的序列,有一个位置索引 $pos \in \{0,1,…,n−1\}$,位置编码会为每个pos 生成一个d 维向量 $PE(pos)$,然后与输入词向量相加(或拼接),得到最终的输入表示:
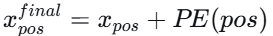
这样,模型既能知道当前词是什么(来自词向量),又能知道它出现在哪里(来自位置编码)。
2
为什么需要位置编码?
1. 自注意力的“盲点”——无视顺序
自注意力计算的是“查询”与“键”的点积,它本质上是在计算两个向量的相似度,而不考虑它们在序列中的位置。如果我们将句子中的词随机打乱,然后输入自注意力,由于每个词本身的向量没变,它们之间的注意力分数也不会变,最终输出的表示也是一样的——这意味着 自注意力本身是完全“无序”的 ,它把序列当成一个集合(bag-of-words)来处理。
但语言是有顺序的。比如:
“猫追老鼠” 和 “老鼠追猫” 是两个完全不同的意思。
“我吃饭” 和 “饭吃我” 显然不同。
如果没有位置信息,模型就无法区分这些顺序差异。
2. 并行计算带来的挑战
RNN天然有顺序,因为它是一个词一个词处理的,位置信息隐含在时间步中。但Transformer为了并行,一次性输入所有词,这就必须显式地注入位置信息。
所以,位置编码的作用就是给模型补充“顺序感”,让模型在计算时能知道词的前后关系。
3
怎么实现位置编码?
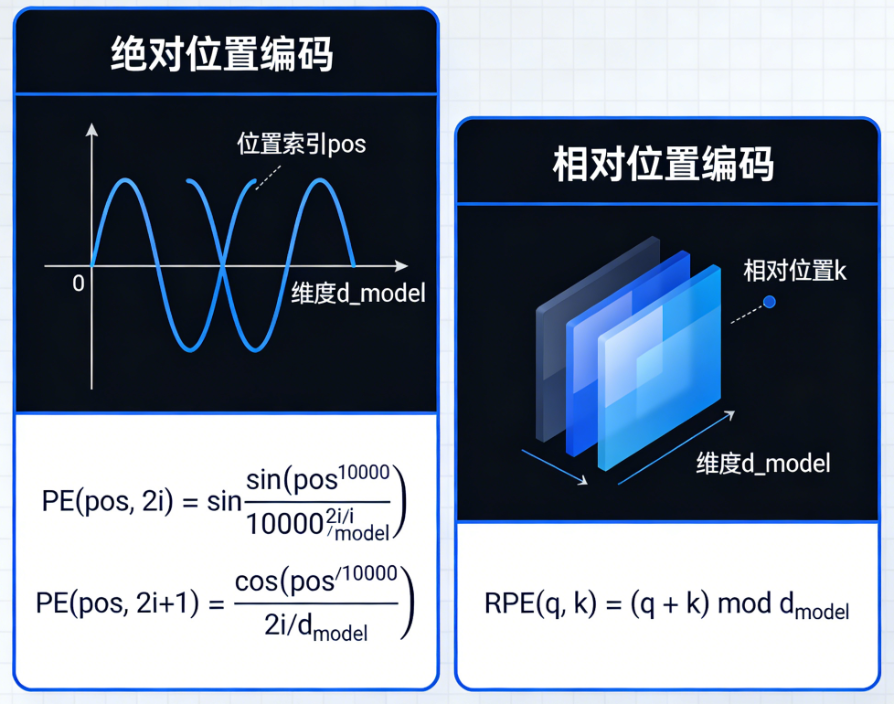
实现位置编码的核心思想是:为每个位置分配一个唯一的向量,并且这些向量之间应该能反映位置的远近关系(相近位置的向量相似,远距离位置的向量差异大)。
方法一:绝对位置编码
1. 原始Transformer的正余弦函数
Vaswani等人提出的Transformer使用了固定公式的位置编码,不参与训练。公式如下:对于位 置 $pos$和维度索 引 $i$ ( $i$从0开始):
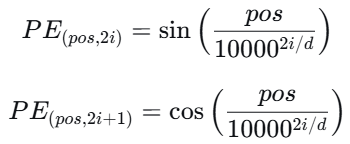
直观解释 :
每个维度对应一个正弦或余弦函数,频率从高到低变化(随着 $i$ 增大,分母指数增大,频率降低)。
这样,不同维度的函数组合在一起,就能唯一标识每个位置。
同时,正弦/余弦函数具有 相对位置关系 的线性表示能力: 对于固定的偏移量 $k$,$PE{pos+k}$ 可以表示为 $PE{pos}$ 的线性函数(利用三角恒等式),这有 助于模型学习到相对位置信息。
优点 :
- 无需训练,参数少。
- 理论上有很好的外推性(可以处理比训练时更长的序列,因为函数是连续的)。
缺点 :
- 外推性其实有限,当序列长度远超过训练见过的长度时,性能会下降(因为模型没有见过那些位置的组合)。
- 固定函数可能不够灵活。
2. 可学习位置编码
这是更简单粗暴的做法:把位置编码当作一个嵌入层来训练,就像词嵌入一样。模型会为每个可能的位置学习一个向量。BERT、GPT 等模型用的就是这种方法。
优点 :
- 灵活,让数据自己决定最佳的位置表示。
缺点 :
- 无法外推到训练时未见过的位置(如果训练时最大长度为512,那么处理超过512的序列就没有对应的嵌入,通常需要截断或特殊处理)。
- 参数量会随最大长度增加而增加。
方法二:相对位置编码
绝对位置编码给了每个位置一个“绝对坐标”,但有时我们更关心的是两个元素之间的 相对距离 。比如在理解“他”指代谁时,我们想知道“他”和前面某个名词之间隔了多少个词,而不是它们各自的绝对位置。
核心思想 :在计算注意力分数时,考虑查询和键之间的相对位置偏移。
1. 简单做法:在注意力分数上加一个可学习的偏置
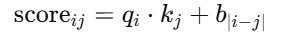
其中 $b_{|i-j|}$是一个可学习的标量,依赖于相对距离 $|i-j|$。Transformer-XL 就采用了类似思路。
2. 旋转位置编码
这是目前非常流行的相对位置编码(LLaMA、PaLM等模型使用)。它的核心思想是:将位置信息通过旋 转矩阵融入到 $q$ 和 $k$中,使得点积 $qi \cdot kj$ 自动包含 相对位置信息。
直观理解 :
- 对每个词向量,我们将其按照位置 i 进行旋转,旋转角度与位置成比例。
- 这样,两个向量的点积就会自动依赖于它们之间的角度差,即相对位置。
优点 :
- 在长序列上外推性好(因为旋转可以延续到任意长度)。
- 同时具有相对位置编码的优点,且实现高效。
3. ALiBi
另一种简单高效的相对位置编码:直接在注意力分数上加上一个与距离成线性关系的负偏置,让距离远的词受到抑制。公式为:
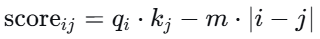
其中 $m$ 是一个固定的斜率(或每个头不同),该方法在BLOOM等模型中使用,外推性也很强。
4
各种位置编码的对比
类型 | 代表模型 | 是否可学习 | 外推性 | 复杂度 | 特点 |
|---|---|---|---|---|---|
正弦/余弦 | Transformer原版 | 固定 | 中等 | 低 | 数学优美,无需训练 |
可学习绝对 | BERT、GPT | 可学习 | 差 | 低 | 简单,但无法外推 |
Transformer-XL式 | Transformer-XL | 可学习 | 好 | 中 | 引入相对偏置 |
RoPE | LLaMA、PaLM | 可学习(旋转矩阵固定) | 好 | 中 | 目前最流行,平衡性好 |
ALiBi | BLOOM | 固定斜率 | 好 | 低 | 极简,效果好 |
- 如果在微调一个预训练模型(如BERT),直接沿用它的位置编码即可(通常是可学习的绝对位置编码,最大长度固定)。
- 如果需要自己设计一个模型,并希望处理长序列(如长文档、长视频),RoPE 或 ALiBi 是很好的选择,因为它们外推性好。
- 如果序列长度很小且固定,可学习绝对位置编码简单够用。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号