基于场景的AI模型BERT和CLIP选型对比


1
CLIP的向量嵌入原理
1. 核心思想:对比学习 + 共享空间
CLIP的核心目标是将 图像和文本映射到同一个向量空间 ,让语义相近的图像和文本在空间中靠近,语义不同的则远离。
具体来说,CLIP使用 双编码器架构 :
- 图像编码器 :可以是ResNet或Vision Transformer(ViT),负责将图像转换为向量
- 文本编码器 :基于Transformer的编码器,负责将文本转换为向量
两个编码器将各自的输入映射到 相同维度的向量空间 (例如512维),然后通过 对比学习 来训练。
2. 训练过程:4个步骤
CLIP的训练可以概括为以下流程:
- 准备数据集 。使用海量的图文配对数据,例如OpenAI收集了4亿个图像-文本对。
- 编码 。将一批N张图片和N个文本分别通过图像编码器和文本编码器,得到N个图像向量和N个文本向量。
- 计算相似度矩阵 。计算所有图像向量与所有文本向量之间的余弦相似度,得到一个N×N的矩阵。对角线上的配对是“正样本”(匹配的图文对),其他位置是“负样本”(不匹配的图文对)。
- 优化目标 。训练的目标是 拉近对角线上的相似度,推远非对角线上的相似度 。公式上,模型最小化对比损失函数:
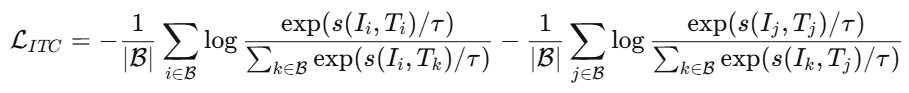
其中 s 是余弦相似度,τ 是温度参数。
通过这一“推拉”过程,模型学会了让匹配的图文对在向量空间中靠近,不匹配的远离。
3. 一个重要的现象:模态差距
研究表明,CLIP的文本向量和图像向量在空间中是 分开的 ——文本向量聚集在空间的一个区域,图像向量聚集在另一个区域。这意味着:
- 文本-文本比较 :不同文本之间可以直接比较,距离反映语义相似度
- 图像-图像比较 :不同图像之间可以直接比较
- 文本-图像比较 :虽然距离可以计算,但整体上文本和图像位于不同的子空间,这被称为“模态差距”
这个差距不是bug,而是CLIP的固有特性——它源于 初始化偏差 (预训练的单模态模型天然分布不同)和 对比学习的强化作用
2
CLIP与BERT的核心区别
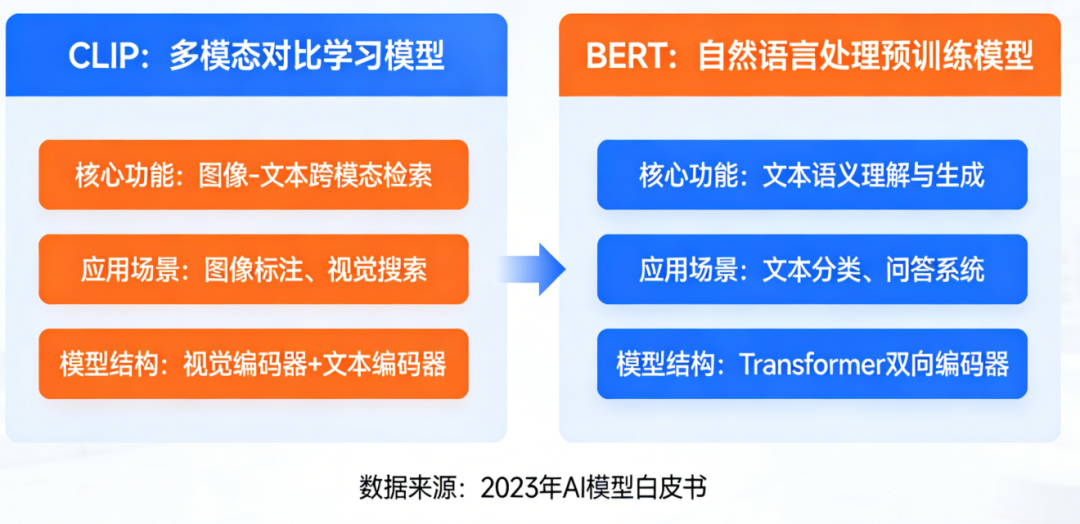
对比维度 | BERT | CLIP |
|---|---|---|
设计目标 | 通用文本理解 | 图文跨模态对齐 |
训练任务 | 掩码语言建模(MLM)+ 下一句预测(NSP) | 图文对比学习(ITC) |
训练数据 | 纯文本(BooksCorpus + Wikipedia) | 图文配对数据(4亿图像-文本对) |
输入模态 | 仅文本 | 文本 + 图像(双编码器) |
输出用途 | 文本分类、问答、序列标注等NLP任务 | 图文检索、零样本分类、多模态应用 |
向量空间 | 单模态空间(文本) | 多模态共享空间(文本+图像) |
BERT的训练方式
BERT通过 掩码语言建模 (MLM)训练:随机遮盖输入文本中15%的词,让模型预测被遮盖的词是什么。这是一种“填空”任务,模型必须利用上下文来理解每个词的含义。
这种训练方式让BERT学会了 深度的文本语义理解 ,在通用NLP任务上表现卓越。
CLIP的训练方式
CLIP通过 对比学习 训练:让模型学会判断图像和文本是否匹配。这不是生成任务,而是 判别任务 ——判断图文对是真是假。
这种训练方式让CLIP学会了 跨模态的语义对齐 ,能够理解“猫”这个文本和猫的图像是同一个概念。
3
优劣势对比
BERT的优势
- 深度文本理解能力 :在GLUE等通用NLP基准测试中,BERT显著优于CLIP的文本编码器。例如,BERT-base在GLUE上的平均得分为81.86,而CLIP-ViT-B/16仅为71.95。
- 细粒度语义捕捉 :能够理解复杂的语言现象,如否定、条件、逻辑推理等。
- 双向上下文建模 :同时利用左右两侧的上下文,这是BERT相比GPT等单向模型的核心优势。
- 丰富的微调生态 :有大量预训练变体(RoBERTa、ALBERT等)和下游任务微调方案。
BERT的劣势
- 仅支持文本 :无法直接处理图像、音频等其他模态。
- 缺乏视觉知识 :不理解“红色”在视觉上是什么样子,只理解这个词的文本含义。
- 训练数据规模相对小 :BERT的训练数据约33亿词,远小于CLIP的4亿图文对。
CLIP的优势
- 跨模态对齐能力 :能够将图像和文本映射到同一空间,实现“以文搜图”、“以图搜文”。
- 零样本学习能力 :无需微调,直接通过文本提示(如“一张狗的照片”)进行分类。
- 视觉-语言联觉(Synesthesia) :CLIP的文本编码器在学习过程中无意中获得了 视觉知识 ——它“知道”文本描述对应的视觉特征。研究发现,CLIP文本编码器生成的向量,可以直接用于生成图像。
- 大规模预训练 :在4亿图文对上训练,泛化能力强。
CLIP的劣势
- 通用文本理解能力弱 :在纯文本任务上显著落后于BERT,例如在语法判断(CoLA)任务上,BERT-base得分为57.78,而CLIP仅约30。
- 模态差距限制 :由于文本和图像向量在空间中是分开的,无法直接判断“文本A是否比文本B更接近某图像”这类细粒度问题。
- 对中文不友好 :CLIP的预训练数据以英文为主(超90%),对中文的分词、成语、文化语境理解存在天然局限。
- 细粒度识别能力弱 :难以区分高度相似的物体(如不同品种的狗),除非文本提示非常精确。
- 训练成本高 :从头训练CLIP需要4亿图文对和大量计算资源。
4
适用场景对比
- BERT适合的场景
场景 | 说明 | 示例 |
|---|---|---|
文本分类 | 情感分析、垃圾邮件识别、新闻分类 | 判断用户评论是正面还是负面 |
问答系统 | 从文档中提取答案 | 根据产品手册回答用户问题 |
序列标注 | 命名实体识别、词性标注 | 从文本中提取人名、地名、时间 |
文本相似度计算 | 计算两段文本的语义相似度 | 判断两篇新闻是否报道同一事件 |
语义解析 | 理解复杂指令、逻辑推理 | 将用户指令转化为结构化查询 |
- CLIP适合的场景
场景 | 说明 | 示例 |
|---|---|---|
以文搜图/以图搜文 | 跨模态检索 | 用“夕阳下的海滩”搜索相关图片 |
零样本图像分类 | 无需训练即可分类新类别 | 用“猫”、“狗”、“鸟”三个文本判断图像类别 |
多模态搜索 | 结合图像和文本的搜索 | 找“看起来像猫但不是猫的动物”图片 |
文本到图像生成 | 作为扩散模型的文本编码器 | Stable Diffusion使用CLIP编码文本描述 |
图像描述生成 | 结合其他模型生成图像描述 | CLIPCap:CLIP + GPT生成图片标题 |
视觉-语言预训练 | 作为下游多模态任务的基础 | 视频理解、视觉问答的预训练模型 |
- 两者协同的场景
在某些应用中,BERT和CLIP可以 协同工作 :
场景 | BERT的角色 | CLIP的角色 |
|---|---|---|
智能图像检索系统 | 理解用户复杂查询的语义 | 将理解后的查询与图像库匹配 |
机器人视觉语言导航 | 解析“先走到沙发旁,再拿起遥控器”这类复杂指令 | 识别图像中的“沙发”、“遥控器” |
多模态问答 | 理解问题的语义和逻辑 | 从图像中提取与问题相关的视觉特征 |
5
选型建议
- 如果需要处理 纯语言任务 (如指令解析、对话管理) → 选BERT或其变体 。它在这类任务上的表现远超CLIP的文本编码器。
- 如果需要 连接视觉和语言 (如场景理解、物体识别) → 选CLIP 。这是它的核心优势,能让你用自然语言描述来检索图像或识别物体。
- 如果应用 以中文为主 且对精度要求高 → 考虑国产替代模型 ,如Qwen3-VL-30B、Chinese-CLIP。它们在中文分词、成语理解、文化语境上明显优于原生CLIP。
- 如果资源受限 (如Jetson Nano部署) → 选CLIP的小版本 (如ViT-B/32,约1亿参数),BERT也有轻量版本(如TinyBERT)。
- 如果需要 同时做两件事 (理解指令 + 识别物体) → 考虑架构组合 :用BERT解析指令提取关键信息,用CLIP将提取的信息与视觉输入对齐。这种组合在机器人导航、人机交互中很常见。
- 如果需要 降低存储和计算成本
→ 考虑CLIP的二值量化版本 。研究表明,通过在训练中加入伪量化损失,可以将CLIP的向量从float32压缩为二进制,内存减少32倍,同时保持约87-93%的性能
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号