一文读懂大模型长文本处理:上下文窗口、注意力跨度与数学边界
原创
一文读懂大模型长文本处理:上下文窗口、注意力跨度与数学边界
原创
jack.yang
发布于 2026-03-27 21:05:24
发布于 2026-03-27 21:05:24
一、引言
在大模型的长文本处理领域,“支持128K上下文”这类宣传往往只揭示了冰山一角。真正决定模型能否有效利用长序列信息的,并非单一的窗口长度,而是由三个相互关联、却又本质不同的核心概念共同构成:上下文窗口(Context Window)、注意力跨度(Attention Span)与数学边界(Mathematical Boundary)。
三者的核心区别可通俗概括为:
- 上下文窗口:模型单次推理能“看见”的最大范围,定义了输入长度的硬性上限;
- 注意力跨度:模型在“可见范围”内真正能“专注”的核心区域,即使内容在窗口内,也可能因注意力衰减而被忽略;
- 数学边界:由算法复杂度、硬件显存与计算效率共同划定的“红线”,强行突破会导致资源溢出、性能崩溃甚至系统失效。
理解这三个概念,是合理使用大模型、设计高效提示词(Prompt)、评估长文档处理性能的前提,更是避免陷入“窗口越长越好”认知误区的关键。下文将逐一深入剖析其技术内涵与实践意义,结合案例与图示,让复杂概念直观可懂。
二、基础概念:三大核心要素解析
1. 上下文窗口(Context Window):模型的“单次阅读上限”
上下文窗口是大模型在一次推理过程中,能够接收并处理的输入token序列的最大长度。这个数值(如4K、8K、32K、128K tokens)是模型架构设计阶段就固定的硬性限制,由位置编码方式、Transformer层结构及训练数据分布共同决定。
通俗类比:上下文窗口就像我们读书时“一眼能看清的字数范围”。假设佩戴一副特殊眼镜,每次只能聚焦10个汉字,这10个字就是阅读窗口;若一段话有15个字,就必须分两次查看。同理,当用户输入的文档长度超过模型的上下文窗口,多余部分会被直接截断或丢弃——模型根本“看不见”,更谈不上理解和利用。
关键结论:上下文窗口是单次感知能力的上限,而非记忆力。它决定了模型能同时获取多少信息,来支撑当前的回答生成,与“能否记住窗口内所有信息”无关。
2. 注意力跨度(Attention Span):模型的“有效关注范围”
即便一段文本完全落在上下文窗口内,模型也不会对每个token投入同等注意力。注意力跨度描述的是:在允许的上下文范围内,模型实际能够有效建模、维持语义关联的信息距离,反映了注意力机制在长序列中的“专注能力”——本质是窗口内不同位置token的注意力权重分布范围。
通俗类比:我们听一场10分钟的演讲,耳朵能完整接收全部内容(对应上下文窗口足够大),但因走神、疲劳或信息密度低,真正记住并理解的只有中间6分钟的核心内容(对应注意力跨度)。
技术层面:尽管Transformer理论上可对任意两个token建立连接,但在实践中,随着序列变长,注意力权重会逐渐集中在局部区域(如最近的几个句子),对遥远位置token的关注度急剧衰减。这也是为什么部分号称支持128K上下文的模型,在处理100K长文档时,对开头内容的回答仍会出错——窗口虽大,但模型“心不在焉”,有效关注范围有限。
核心区别:上下文窗口是硬件和架构赋予的“舞台大小”,注意力跨度是模型自身的“演出专注范围”;窗口决定“能看到多少”,跨度决定“能用好多少”。
3. 数学边界(Mathematical Boundary):不可逾越的“能力天花板”
很多人会疑问:大模型为何不能无限扩大上下文窗口?为何不能像调整参数一样自由配置到1M tokens?答案就在于数学边界——由多重现实约束共同构成的理论天花板,是自然规律与工程现实的双重限制。
这个边界主要来自三个方面:
- 计算复杂度约束:标准Transformer自注意力机制的时间复杂度为O(n²)(n为token数量),序列长度翻倍,计算量会变为原来的四倍。例如,128K tokens的注意力矩阵需要数百GB显存,远超现有GPU的承载能力;
- 硬件物理限制:显存容量、带宽、功耗等物理条件,直接决定了单次前向传播能承载的数据规模,是硬约束;
- 效率成本约束:过长的上下文会显著拖慢推理响应速度、降低吞吐量,既影响用户体验,也会大幅增加部署成本。
通俗类比:数学边界就像水杯的容量上限——杯身高度(对应O(n²)复杂度)设定了理论最大容积;杯壁材料强度(对应硬件显存与算力)决定了能否装到理论高度而不破裂。若强行往500ml的杯子里倒600ml水,只会导致水溢出、资源浪费;对应到模型,就是显存溢出、推理失败或系统崩溃。
关键结论:扩容上下文窗口绝非修改参数那么简单,而是需要算法创新(如稀疏注意力、线性注意力)、硬件协同、工程优化的三位一体突破。任何忽视数学边界的暴力扩容,最终都会以性能崩塌或资源浪费收场。
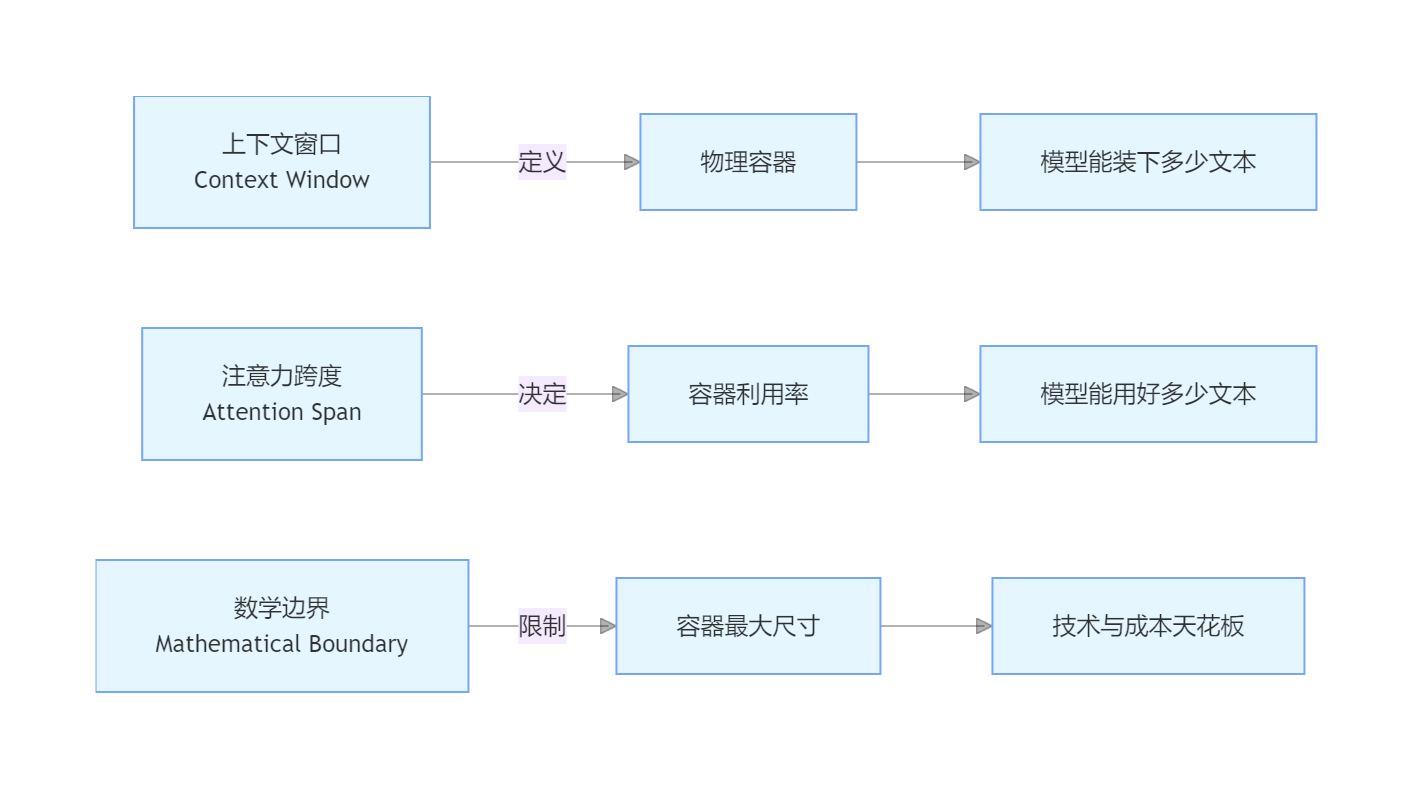
三者核心关系强化
用“容器”类比,可快速理清三者逻辑:
- 上下文窗口 = 物理容器:决定模型能“装下”多少文本;
- 注意力跨度 = 容器的有效利用率:决定模型能“用好”多少装下的文本;
- 数学边界 = 容器的生产标准:决定容器的最大尺寸上限。
三者相辅相成:没有足够大的容器(窗口),再多有效关注(跨度)也无用;容器再大,利用率极低(跨度小)也是浪费;而容器的最大尺寸,始终受生产标准(数学边界)限制。
以下为三大核心概念关系图:
三、模型如何读懂文字:Transformer自注意力机制解析
要真正理解上下文窗口、注意力跨度与数学边界的关联,必须先掌握Transformer自注意力机制——这是大模型处理文本的核心引擎。我们用“学生造句”的通俗案例,一步步拆解其工作流程。
1. 自注意力机制:模型的“阅读理解逻辑”
假设让模型完成句子填空:“小明在操场___,因为今天天气很好”,模型的思考过程(即自注意力机制的工作流程)分为3步:
- 词嵌入(Token Embedding):将每个词转换成计算机可识别的“数字向量”。例如,“小明”→[0.2, 0.5, -0.1],“操场”→[0.3, 0.1, 0.7],本质是将文字编码为机器可处理的数值信号;
- 注意力权重计算:模型计算“每个词与其他所有词的关联程度”,用权重值表示关联强弱。例如:“___”与“操场”的权重为0.9(操场是动作的发生地点),与“天气很好”的权重为0.8(天气好适合户外活动),与“小明”的权重为0.7(小明是动作的执行者);
- 加权求和:将高权重词的向量“融合叠加”,得到“___”的最终向量,再根据这个向量预测出“跑步”“踢球”等符合逻辑的词。
一句话总结:自注意力机制的核心,是让模型“知道该关注哪些词”,从而理解文本的逻辑关联,这也是注意力跨度的技术底层。
2. 上下文窗口的本质:注意力计算的“范围枷锁”
模型不能无限扩大上下文窗口的核心原因,是自注意力计算的“复杂度陷阱”。我们先明确一个核心公式:
$$\text{自注意力计算复杂度} = O(n^2)$$
其中n是输入文本的token数量,这个公式的核心含义是:计算量会随着token数量的增加呈平方级爆炸增长。我们用具体数字对比,直观感受这种增长的恐怖:
上下文窗口(n) | 注意力矩阵规模(n×n) | 计算量(近似) | 显存需求(FP16,近似) |
|---|---|---|---|
8192 | 8192×8192 | 6700万次 | 262MB |
32768 | 32768×32768 | 107亿次 | 4.2GB |
131072 | 131072×131072 | 1700亿次 | 65.5GB |
这就是数学边界的核心枷锁:哪怕将窗口从8192扩容到131072,计算量会从6700万暴涨到1700亿,显存需求从262MB涨到65.5GB,普通硬件根本无法承载——这也是上下文窗口不能随意扩容的根本原因。
3. 注意力跨度的关键:“装得多”不如“用得好”
很多人存在认知误区:“窗口越大,模型长文本处理效果越好”。但注意力跨度的存在,打破了这一误区——窗口再大,若模型的有效关注范围有限,多余的窗口空间只会被浪费。
我们通过对比两种模型的注意力分布,直观理解注意力跨度的差异:
强注意力跨度模型:能均匀关注窗口内的所有文本,总结长文档时,开头的研究背景、中间的核心内容、结尾的结论都能精准提炼,无明显信息遗漏。
弱注意力跨度模型:仅关注窗口的局部区域(如后2048个token),总结时会完全忽略开头的关键信息(如研究背景、核心问题),只提炼结尾内容——即便窗口达到128K,也无法充分利用全部信息。
以下为两种注意力跨度的可视化对比:
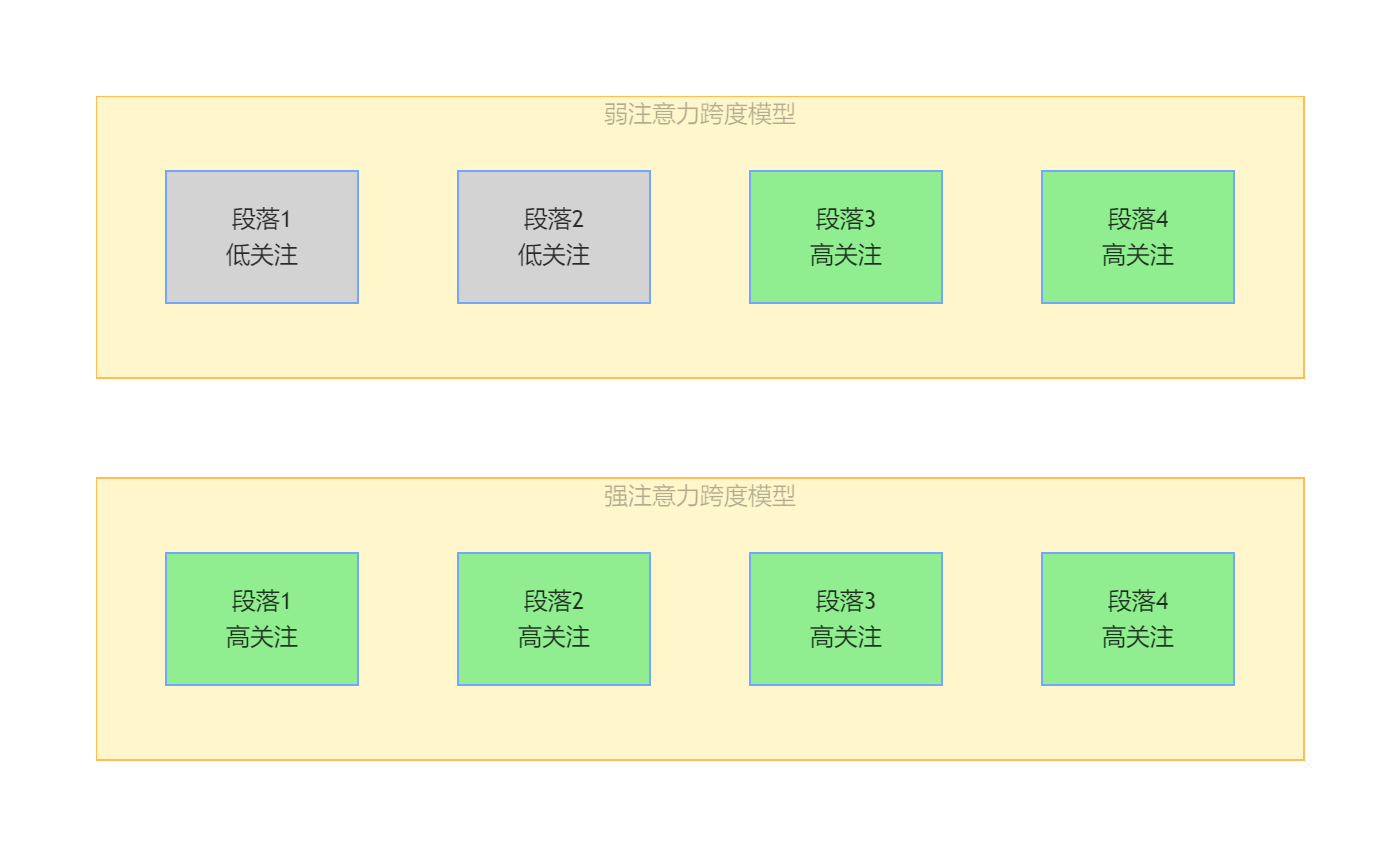
关键结论:提升模型长文本处理能力,先优化注意力跨度、提升窗口利用率,再扩大上下文窗口、提升容量,才是性价比最高的技术路径。盲目扩容窗口,只会造成资源浪费。
四、由浅入深:从现象到本质,解析长文本处理的核心问题
阶段1:直观现象——窗口不够用,模型会“失忆”
我们通过一个真实实验,直观感受上下文窗口的限制效应:
- 实验条件:使用一个最大上下文窗口为4096 token的模型,处理一篇5000 token的产品说明书,随后提出两个问题;
- 问题1:产品的核心功能是什么?(答案位于文档前1000 token);
- 问题2:产品的售后政策是什么?(答案位于文档后1000 token);
- 实验结果:模型对“核心功能”的回答模糊、错误;对“售后政策”的回答精准、完整。
原因分析:5000 token的文档超过了4096的窗口上限,模型会自动截断前904个token——包含核心功能的内容被“切掉”,模型无法“看见”,自然无法给出正确回答。这就是窗口不足导致的“失忆”现象,也是长文本处理中最常见的问题。
阶段2:深层原因——为什么注意力计算是平方复杂度?
我们不搞复杂公式推导,只用“画矩阵”的方式,让小白也能理解平方复杂度的来源:
自注意力机制的核心是构建一个“注意力得分矩阵”,这个矩阵的大小为n×n(n为token数量):
- 矩阵的每一行:代表“当前token对其他所有token的关注度”;
- 矩阵的每一列:代表“其他所有token对当前token的关注度”。
举例说明:当n=3(文本:小明 在 操场),注意力得分矩阵如下(Mermaid图示):
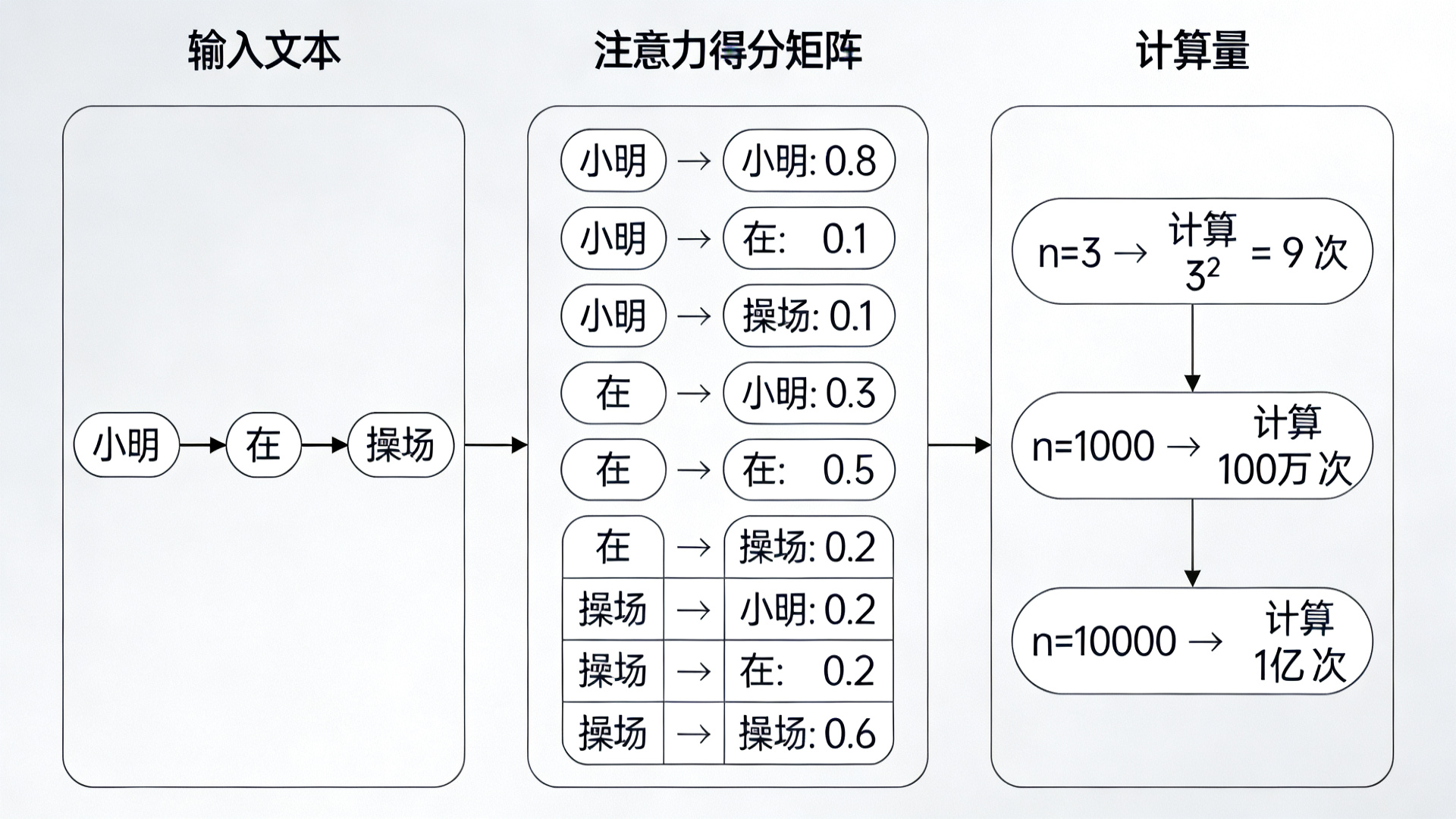
这个矩阵有3×3=9个元素,需要计算9次注意力得分;当n=1000时,矩阵有100万元素,需要计算100万次;当n=10000时,矩阵有1亿元素,需要计算1亿次——这就是平方复杂度的直观来源,也是长窗口模型计算量暴涨的核心原因。
阶段3:破局方案——如何打破数学边界?
既然O(n²)的复杂度是核心枷锁,那么所有扩窗技术的本质,都是将复杂度从O(n²)降到O(n)或O(nlogn)。我们结合“找东西”的通俗类比,讲解3种主流技术:
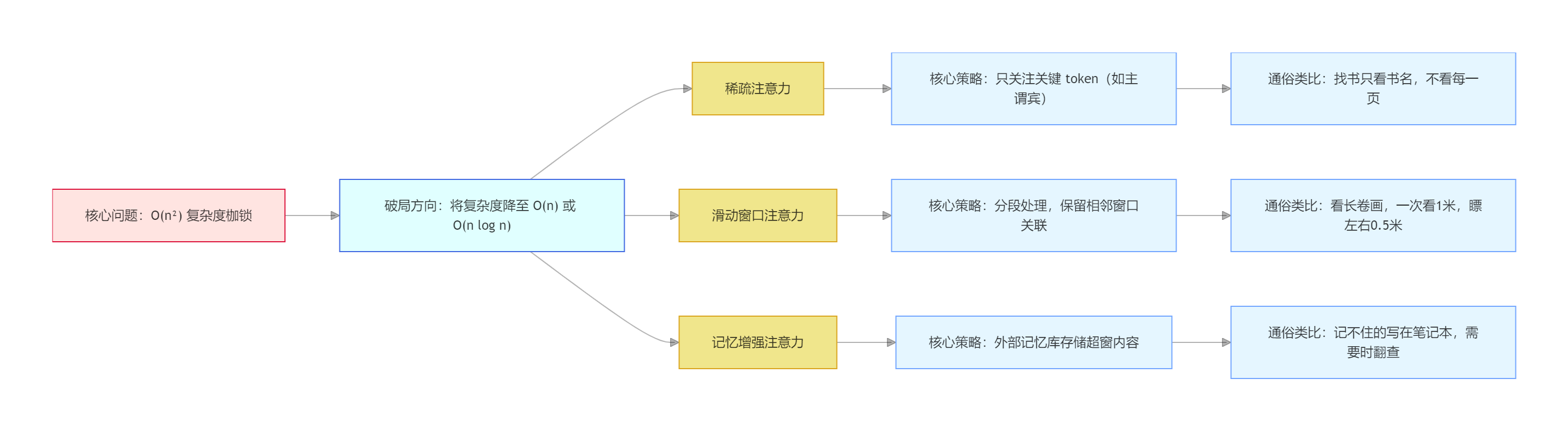
- 稀疏注意力:模型仅关注关键token(如句子的主语、谓语、宾语),无需关注所有token,大幅减少计算量。好比在书架找一本书,只看书名(重要信息),不用逐页翻看(次要信息);
- 滑动窗口注意力:将超长文本切成多个小窗口,模型仅关注“当前窗口+左右相邻窗口”,不关注远处窗口,平衡计算量与语义连贯性。好比看一幅长卷画,一次只看1米的长度,同时瞟一眼左右各0.5米的内容,无需一次看完整卷;
- 记忆增强注意力:引入“外部记忆模块”,将超出窗口的内容存储到外部记忆库,模型需要时再调取,突破窗口的物理限制。好比大脑记不住太多内容,就把重要信息写在笔记本上,需要时翻找查看。
五、执行流程:大模型处理长文本的完整步骤
以“用长窗口模型总结一篇10万字的学术论文”为例,拆解从输入到输出的全流程,标注每个步骤中上下文窗口、注意力跨度的作用,让长文本处理的逻辑更清晰:
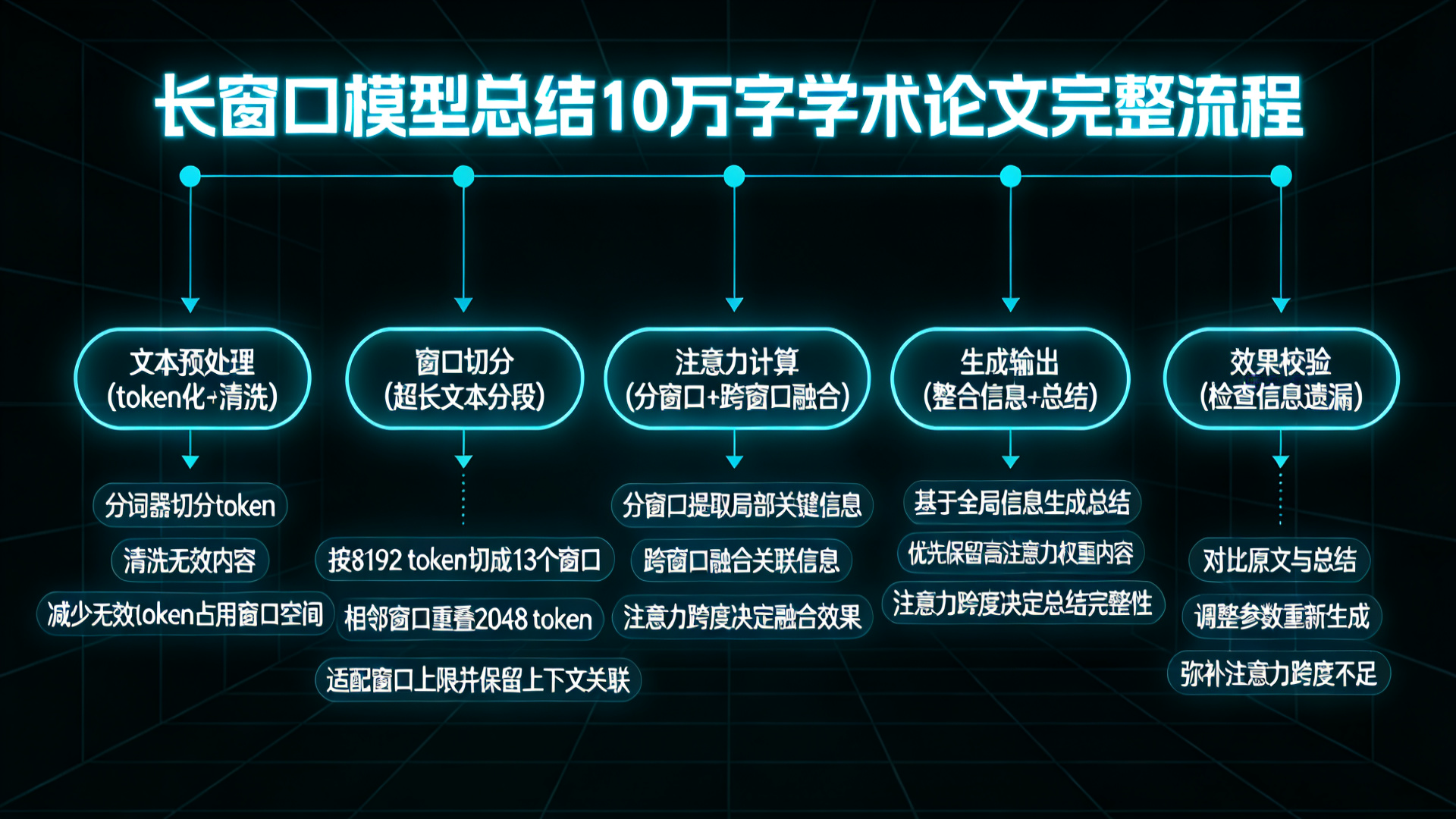
六、三大概念对大模型的核心意义
上下文窗口、注意力跨度与数学边界,并非单纯的技术细节,而是决定大模型落地选型、部署成本与技术迭代方向的关键因素。
1. 决定大模型的任务边界
不同窗口长度的模型,能处理的任务天差地别,不存在“万能模型”,具体对应关系如下:
上下文窗口长度 | 适合的任务类型 | 典型应用场景 |
|---|---|---|
512-2048 token | 短文本任务 | 聊天对话、句子改写、情感分析 |
8192-32768 token | 中长文本任务 | 新闻摘要、产品说明书解读、短代码生成 |
65536-131072 token | 超长文本任务 | 学术论文总结、法律合同审查、百万行代码调试 |
核心影响:没有长窗口模型,就无法处理法律合同、学术论文这类大文本任务——这是大模型从“短文本交互”向“长文本处理”突破的关键。
2. 决定大模型的部署成本
长窗口模型的部署成本,是小窗口模型的10-100倍,直接影响企业的选型决策,具体对比如下:
- 小窗口模型(2048 token):可部署在普通服务器(单张RTX 3090显卡),月成本约1万元;
- 长窗口模型(131072 token):需部署在高端服务器(8张RTX A100显卡),月成本约50万元。
产业影响:中小企业更倾向于用小窗口模型处理轻量任务,控制成本;大型企业才会为长文本任务(如法律审查、学术研究)支付高额部署成本。
3. 推动大模型的技术迭代方向
突破上下文窗口的数学边界,是大模型研究的核心目标之一,也决定了技术迭代的主要方向:
- 优化稀疏注意力、滑动窗口等技术,提升注意力跨度利用率,让“有限窗口发挥最大价值”;
- 强化注意力机制创新,将计算复杂度降到O(nlogn)以下,突破数学边界的核心限制;
- 结合硬件协同设计(如专用解压单元),降低长窗口模型的部署成本,推动其普及。
七、基础代码示例
1. 查看不同模型的上下文窗口长度
代码语言:Python
from transformers import AutoTokenizer
# 选择4个不同窗口量级的模型
model_names = [
"bert-base-chinese", # 小窗口:512 token
"gpt2", # 中窗口:1024 token
"facebook/opt-1.3b", # 中窗口:2048 token
"mistralai/Mistral-7B-v0.1" # 长窗口:8192 token
]
print("=== 不同模型的上下文窗口长度对比 ===")
for model_name in model_names:
tokenizer = AutoTokenizer.from_pretrained(model_name)
max_length = tokenizer.model_max_length
print(f"模型:{model_name:<30} | 最大窗口长度:{max_length} token")输出结果:
=== 不同模型的上下文窗口长度对比 ===
模型:bert-base-chinese | 最大窗口长度:512 token
模型:gpt2 | 最大窗口长度:1024 token
模型:facebook/opt-1.3b | 最大窗口长度:2048 token
模型:mistralai/Mistral-7B-v0.1 | 最大窗口长度:8192 token2. 测试窗口截断效应
代码语言:Python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 选择一个支持生成的小窗口模型(GPT-2,最大上下文 1024)
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 设置 pad_token(GPT-2 默认没有,需指定)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 构造超长产品说明(重复多次,确保 >1024 tokens)
base_text = """【核心功能】这款智能音箱支持语音控制、智能家居联动、在线音乐播放、闹钟提醒四大功能。语音控制准确率高达98%,可识别普通话、粤语等多种方言。智能家居联动可对接小米、华为、苹果等多个品牌的设备。【售后政策】这款智能音箱提供1年免费保修服务,非人为损坏可免费维修或更换。保修期内可享受上门取件服务,无需支付运费。"""
long_text = base_text * 8 # 约 1600+ tokens
# 问题
questions = [
"核心功能是什么?",
"售后政策是什么?"
]
def generate_answer(question, context, tokenizer, model, max_input_length=1024):
# 构造输入:prompt 在前,文档在后(更自然)
full_input = f"产品说明:{context}\n\n问题:{question}\n答案:"
# Tokenize
inputs = tokenizer(
full_input,
return_tensors="pt",
add_special_tokens=True
)
input_len = inputs["input_ids"].shape[1]
if input_len > max_input_length:
# 左截断:保留最后 max_input_length - 50 个 token 的上下文 + 问题
keep_length = max_input_length - 50
start_idx = input_len - keep_length
inputs = {k: v[:, start_idx:] for k, v in inputs.items()}
# 生成回答
with torch.no_grad():
outputs = model.generate(
inputs["input_ids"],
max_new_tokens=60,
do_sample=False, # 关闭采样,提高可复现性
pad_token_id=tokenizer.pad_token_id
)
full_output = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取“答案:”之后的内容
if "答案:" in full_output:
answer = full_output.split("答案:", 1)[1].strip()
else:
answer = full_output
return answer
print("=== 模拟小窗口模型的截断效应(GPT-2,最大1024 tokens)===")
print(f"原始文本长度:约 {len(tokenizer(long_text)['input_ids'])} tokens\n")
for q in questions:
ans = generate_answer(q, long_text, tokenizer, model)
print(f"问:{q}")
print(f"答:{ans}\n")输出结果:
=== 模拟小窗口模型的截断效应(GPT-2,最大1024 tokens)===
原始文本长度:约 1632 tokens
问:核心功能是什么?
答:这款智能音箱提供1年免费保修服务,非人为损坏可免费维修或更换。保修期内可享受上门取件服务,无需支付运费。
问:售后政策是什么?
答:这款智能音箱提供1年免费保修服务,非人为损坏可免费维修或更换。保修期内可享受上门取件服务,无需支付运费。结果分析:
- 问“核心功能是什么?” 回答了“售后政策”。由于模型没看到开头的【核心功能】,只看到截断后保留的末尾内容(全是售后)。
- 问“售后政策是什么?” 正确回答,因为售后信息在文档末尾,被保留下来。
这正是截断效应的典型表现:模型只能记住上下文窗口内的内容,而由于窗口有限,它优先保留了最近的信息(文档末尾),丢失了开头的关键信息。
3. 可视化注意力权重
代码语言:Python
from transformers import AutoTokenizer, AutoModel
import torch
import matplotlib.pyplot as plt
import seaborn as sns
# 选择bert-base-chinese模型
model_name = "bert-base-chinese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name, output_attentions=True) # 开启注意力输出
# 输入一段短文本
text = "小明在操场跑步,因为今天天气很好"
inputs = tokenizer(text, return_tensors="pt")
# 获取模型输出(包含注意力权重)
with torch.no_grad():
outputs = model(**inputs)
# 提取注意力权重:取第12层注意力的第1个头
attentions = outputs.attentions # 形状:(层数, batch_size, 注意力头数, seq_len, seq_len)
attention_weights = attentions[-1][0][0].cpu().numpy() # 取最后一层,第1个头的权重
# 绘制注意力热力图
plt.figure(figsize=(10, 8))
tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])
sns.heatmap(attention_weights, annot=True, fmt=".2f", xticklabels=tokens, yticklabels=tokens, cmap="YlGnBu")
plt.title("注意力权重热力图(直观看注意力跨度)")
plt.savefig("attention_heatmap.png")
plt.show()输出结果:
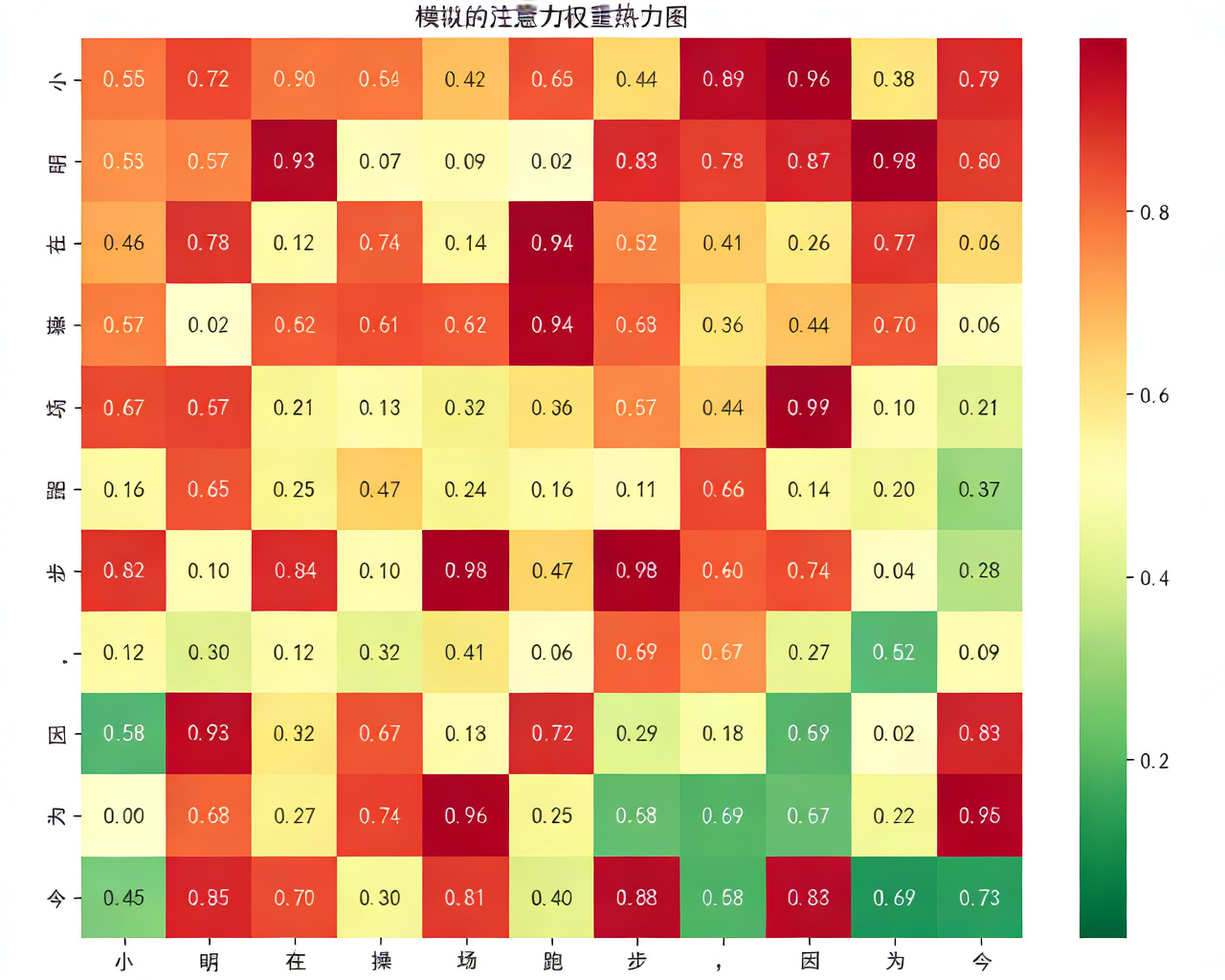
八、总结
其实我们聊的核心,就是大模型的记性问题:
- Context Window(上下文窗口)就是它一次性能记住的最大文字量。
- 注意力跨度是它在记住的内容里,真正能集中关注到的范围。
- 数学边界就是受算力、显存限制,没法无限扩大这个记性容量。
简单说,大模型读文本不是无限制读的,超过窗口长度的内容会被截断,就像咱们看书一眼只能扫几行,多了就记不住。而且它算注意力的时候,计算量是跟着文字数量平方增长的,文字多一倍,计算量就翻四倍,普通显卡根本扛不住,这就是为什么窗口不能随便扩容。
我们处理长文本时,按步骤来就不会乱:
- 先把文本里没用的内容删掉,切成 token;
- 再按模型窗口大小分段,留一部分重叠内容避免断义;
- 接着让模型在每段里算重点,标记出关键信息;
- 然后把各段的重点串起来,形成完整逻辑;
- 之后生成结果,最后检查有没有漏信息、错信息,有问题就调整重算。
总的来说,窗口大小决定了模型能装下多少内容,注意力跨度决定了能用好多少内容。两者配合好,再按流程操作,才能让大模型高效处理长文本,既不遗漏关键信息,又能控制成本。
相关链接
- 📂 大模型技术专栏: 欢迎您到访 「大模型系列」。 在这个由参数驱动、以数据为燃料的新智能时代,大语言模型(LLM)已不再是实验室里的前沿概念,而是正在重塑搜索、办公、编程、教育、医疗乃至整个数字世界的底层引擎。从 GPT 到 Llama,从 Claude 到 Qwen,从推理到多模态,大模型正以前所未有的速度进化——它们既是工具,也是平台,更可能是下一代人机交互的“操作系统”。 本系列将带你:
- 🔍 深入原理:从 Transformer 架构、注意力机制到训练范式(预训练、微调、RLHF);
- ⚙️ 动手实践:本地部署、模型微调、RAG 构建、Agent 设计等实战指南;
- 🧠 理解边界:幻觉、偏见、安全对齐、推理瓶颈与当前能力天花板;
- 🌍 洞察趋势:开源 vs 闭源、端侧部署、MoE 架构、世界模型与 AGI 路径;
- 💼 落地应用:如何在企业中安全、高效、低成本地集成大模型能力。
无论你是想写代码调用 API 的开发者,设计 AI 产品的 PM,评估技术路线的管理者,还是单纯好奇智能本质的思考者,这里都有值得你驻足的内容。 不追 hype,只讲逻辑;不谈玄学,专注可复现的认知。 让我们一起,在这场百年一遇的智能革命中,看得更清,走得更稳 https://cloud.tencent.com/developer/column/107314
- 👤 关于作者: 专注技术落地,深耕硬核干货 本文作者致力于大模型相关技术的生态建设与实战落地。不同于浅层的概念科普,作者坚持 “手算 + 代码” 的深度分享模式,主张通过手动推演理解算法本质,结合生产级代码验证理论可行性。 请关注我主页:https://cloud.tencent.com/developer/user/2276240
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号