ATMOSSCI-BENCH:评估大语言模型在大气科学中的最新进展

ATMOSSCI-BENCH:评估大语言模型在大气科学中的最新进展

气象学家
发布于 2026-03-25 20:03:02
发布于 2026-03-25 20:03:02
文章摘要
大语言模型(LLMs)的快速发展,尤其是在推理能力上的突破,为应对大气科学中的复杂挑战、推动科学发现带来了变革性潜力。然而,要在这一领域有效发挥LLM的作用,需要一个健全且全面的评测基准。为此,香港科技大学潘乐陶气候变化与可持续发展研究中心主任陆萌茜教授团队联合计算机科学及工程学系袁彬航教授团队提出了全新的评测框架ATMOSSCI-BENCH,旨在系统性地评估LLM在大气科学五大核心问题类别上的表现:水文学、大气动力学、大气物理学、地球物理学和物理海洋学。该成果近期已正式被国际顶级机器学习会议NeurIPS 2025接收,题为《ATMOSSCI-BENCH:评估大语言模型在大气科学中的最新进展》(ATMOSSCI-BENCH: Evaluating the Recent Advances of Large Language Models for Atmospheric Science)。

ATMOSSCI-BENCH采用双格式设计,同时包含选择题(MCQs)和开放题(OEQs):前者支持规模化的自动化评估,后者则用于更深入地分析模型的概念理解与推理能力。团队基于模板构建了带有符号扰动的选择题生成框架,生成多样化的研究生水平问题,同时通过开放题检验了模型在非约束条件下的推理表现。
团队对多类具有代表性的LLM进行了全面评测,将其分为四组:指令调优模型、高级推理模型、数学增强模型和气候领域专用模型。分析结果揭示了LLM在大气科学中的推理与问题求解能力上的若干有趣洞见。团队相信ATMOSSCI-BENCH将成为推动LLM在气候服务中应用的重要一步,通过提供一个标准化且严格的评测框架,为未来研究奠定基础。
01
研究背景
随着能力的不断提升,大语言模型(LLMs)展现出成为“AI科学家”的潜力,它们不仅能够辅助,还可能自主完成假设生成、实验设计、执行、分析与改进等科研环节。然而,要推动AI在大气科学中的应用,并开发出可靠且高效的LLM气候任务应用,首先必须认识到:LLM本身是这一进程的核心。评估当前LLM是否具备在大气科学中进行推理的能力是一个不可或缺的前提,这需要建立健全而全面的评测框架。
在现有的模型评估体系中,传统的基准多侧重于通用任务(如数学或常识推理),但未能有效覆盖大气科学中的复杂跨学科问题。大气科学问题不仅涉及气候动力学、热力学、流体力学和观测数据等多源知识,还依赖复杂的推理链条,远比常见的数学题或一般知识问答更具挑战性。
针对这一空白,团队提出了AtmosSci-Bench,这是首个系统性集成多学科知识的大气科学评测框架。它为评估LLM 在气候与大气科学中的表现提供了标准化基准,确保模型在这一关键领域的实用性、准确性与稳健性。
02
评估基准建构
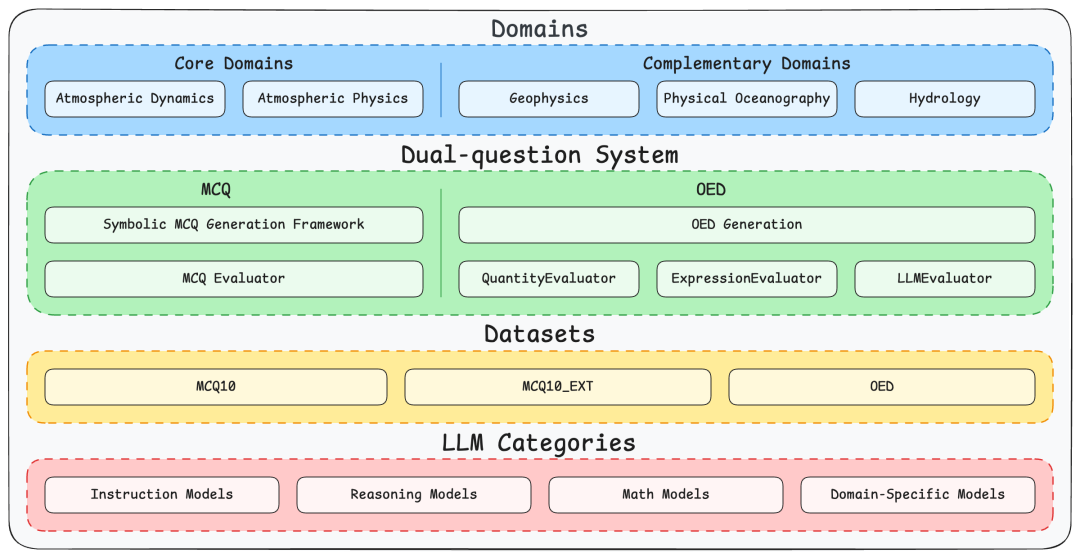
AtmosSci-Bench概览图
01
评估领域
1. Hydrology水文学 涉及降水、径流和水资源管理等关键问题;
2. Atmospheric Dynamics大气动力学 研究大气运动及其对天气和气候的影响;
3. Atmospheric Physics大气物理学 探索云、辐射和能量交换等物理过程;
4. Geophysics地球物理学 分析地球内部和表面的物理特性;
5. Physical Oceanography物理海洋学 研究海洋的物理特性及其与气候系统的相互作用。
02
数据建构
ATMOSSCI-BENCH的题库来源于大学课程资料,确保内容的学术性和挑战性。
- 选择题(MCQ):团队构建了MCQ自动生成框架,先由专家将问题转化为模板,再引入符号扰动机制和物理约束,自动生成大规模以及变体丰富的题目。这样能检验模型是否真正理解,而不是依赖模式匹配。
- 开放题(OEQ):OEQ负责考察LLM在无约束的条件下,是否能进行更加深入的思考。问题需要模型进行数值计算、符号推导或文字解释,考察其深度推理与表达能力。为保证公平评估,团队设计了三重评测体系:数值评估器、符号表达评估器和 LLM评估器。
最终,ATMOSSCI-BENCH包含超过1000道题目,全面覆盖大气科学五大领域,并且对于数据污染有高度抗性。
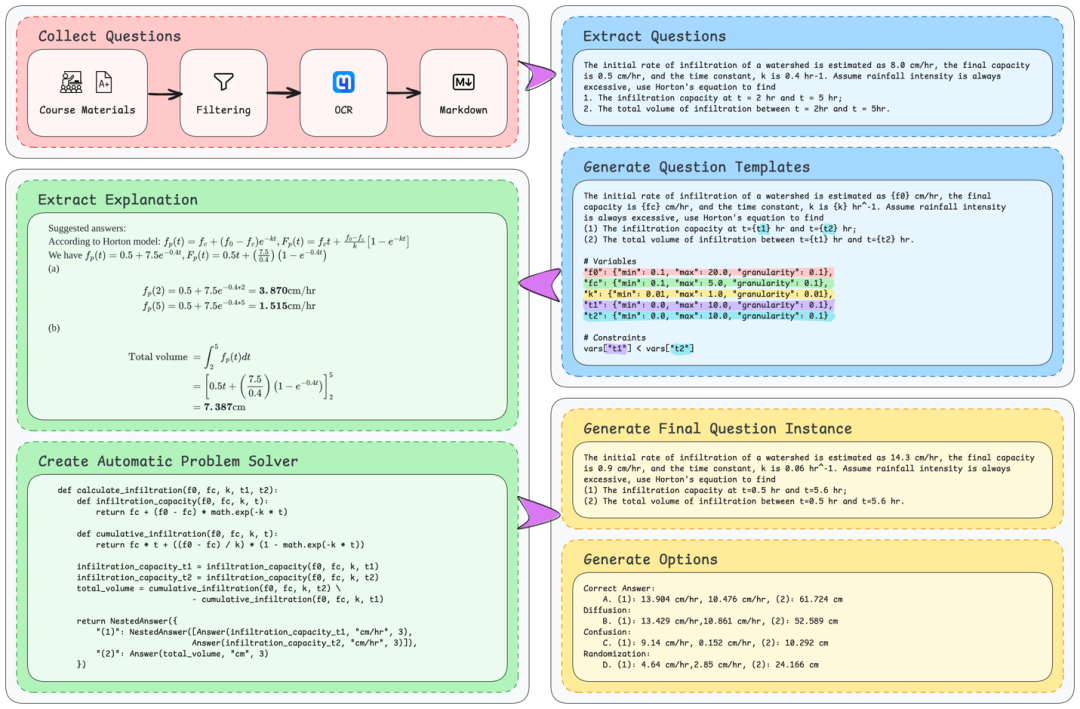
MCQ自动生成框架 - 团队基于模板的问题生成框架的构建流程图。红色模块表示题目的收集过程,蓝色模块表示题目的生成过程(变量用不同颜色标记),绿色模块表示自动求解器,它会根据给定变量推导出答案,黄色模块则展示了一个生成问题及其对应选项的示例。
03
评估成果
01
四类大语言模型的全面评估
根据AtmosSci-Bench的评测结果,研究团队对四类大语言模型进行了全面的比较:指令调优模型、高级推理模型、数学增强模型、领域气候模型。结果显示,各类模型在处理大气科学问题时表现出显著差异。
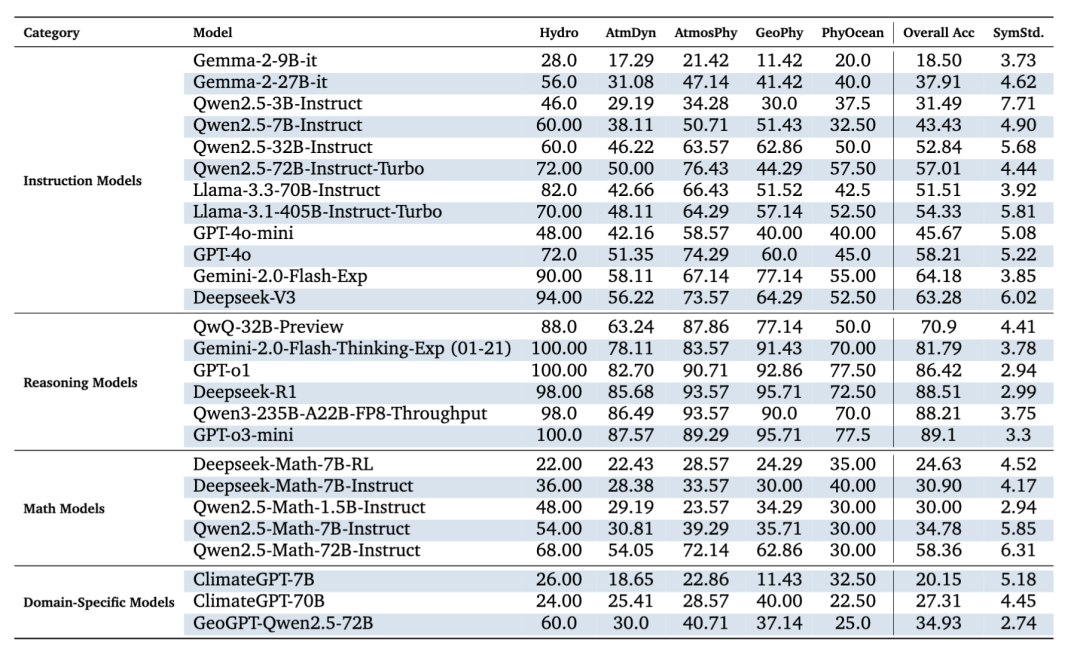
表1. 水文学 (Hydro)、大气动力学 (AtmDyn)、大气物理学 (AtmosPhy)、地球物理学 (GeoPhy) 和物理海洋学 (PhyOcean) 五个领域的四个 LLMs 类别在在 MCQ10 数据集上的准确率(%)和符号标准偏差方面的性能比较。
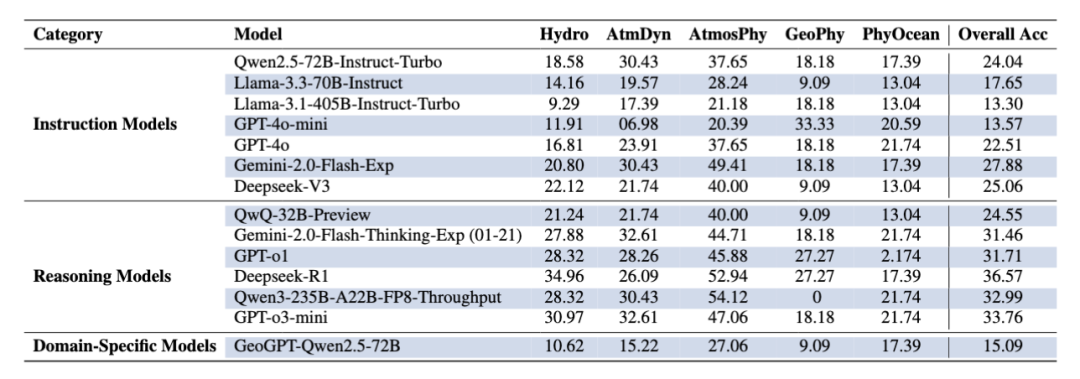
表2. 在 OEQ 数据集上四类 LLM 的准确率(%)对比。
实验结果:在MCQ10数据集上,推理模型表现最优,平均准确率接近90%,远高于其他模型。指令模型在50%左右,数学模型并未展现出明显优势。而气候专用模型反而表现最差(20%~35%),说明仅靠气候语料训练不足以解决复杂推理任务。在OED数据集上,四种大模型呈现出跟MCQ10数据集相似的结果,推理模型利用它们的推理能力取得最优表现。
结论:在大气科学任务中,推理模型显著优于指令模型、数学模型和领域专用模型,展现出更强的高级推理适应性;而领域专用模型尽管接受过专门训练,仍表现不佳。这表明 LLM 在该领域的核心瓶颈在于推理能力,其重要性远高于单纯的领域知识。
02
推理链长度(Inference Time Scaling)
团队选取了典型推理模型(如GPT-o3-mini、QwQ-32B)进行对比,逐步增加其推理token长度(从4K到40K)。
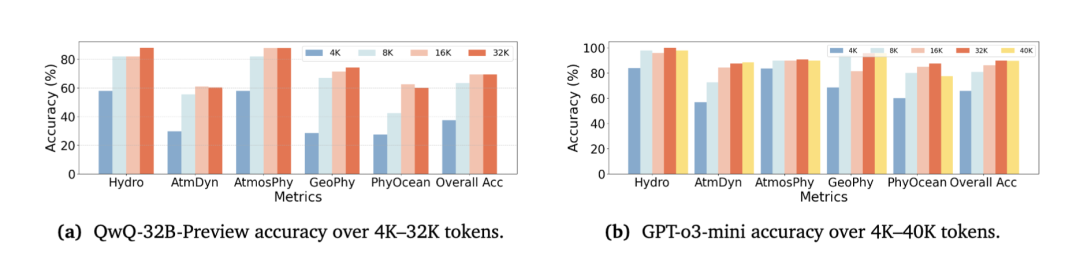
推理步骤研究,不同模型在输入长度增加下的准确率(%)。
实验结果:准确率随推理长度增加而提升。在16K~32K tokens达到最佳,之后增幅趋于平缓。说明模型并非“越想越好”,而是存在一个最优推理时长阈值。
结论:适度延长推理链能提高科学任务表现,但需要平衡效率与收益。
03
符号扰动的鲁棒性测试
团队构建了MCQ30数据集,在同一题目模板中系统改变变量值,测试模型在“数值扰动”下的稳定性。
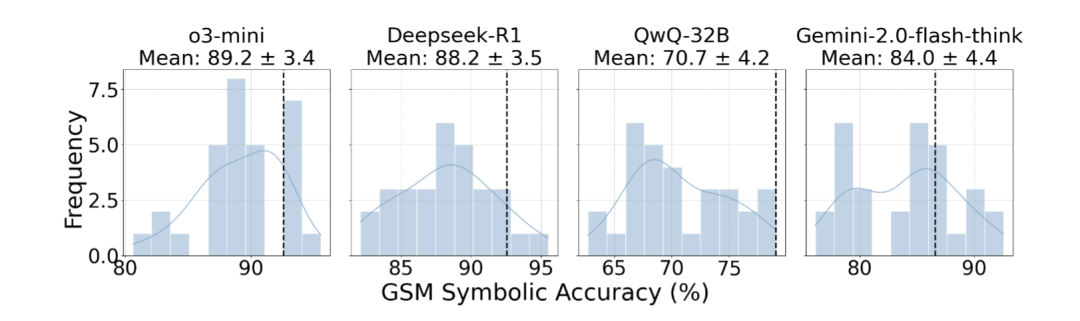
推理类LLM在MCQ30上的性能分布。纵轴表示符号化测试集在横轴所示准确率下出现的频次,黑色竖虚线表示原始题集的准确率。
实验结果:多数推理模型在扰动下准确率出现明显下降,部分问题的正确率下降接近一个标准差。
表现说明:模型可能依赖“模式匹配”,而非真正的逻辑推理。
结论:即便是先进推理模型,在应对变量变化时依然存在脆弱性,需要更强的逻辑泛化能力。
结语
AtmosSci-Bench不仅是一个评估工具,更是推动LLMs在气候服务中应用的关键一步。作为这次评测的标准框架,研究团队采用了科学且严谨的评判体系,全面考察了大气科学领域中各大语言模型在推理、精度计算、多学科整合等方面的能力。研究团队希望激发更多关于LLMs在大气科学中的潜力研究,推动AI技术在大气科学等专业领域的深入应用,并最终为气候变化应对和气候服务提供更强大的技术支持。
作者信息
第一作者:
李辰悦 香港科技大学计算机科学与工程学系博士生。研究兴趣:AI for Science(AI4S),大语言模型,数据库,分布式系统,网络安全以及全栈开发等方向。
共同作者:
邓雯 香港科技大学土木与环境工程系、潘乐陶气候变化和可持续发展研究中心硕士生。研究兴趣:AI for Science;利用机器学习和深度学习方法,提升对高影响天气事件的预测技巧。
陆萌茜 香港科技大学土木与环境工程系、金融系及海洋科学系副教授,博士生导师,潘乐陶气候变化与可持续发展研究中心主任。研究领域包括气象水文科学与人工智能分析结合研究,主要包括大气河、水循环、东亚季风、极端天气和水资源管理等。课题组长期招聘硕士生,博士生,博士后研究员。有意向的申请人请将申请材料直接发送至陆老师邮箱(cemlu@ust.hk)。
通讯作者:
袁彬航 香港科技大学计算机科学与工程学系助理教授。研究兴趣包括数据管理、数据驱动的机器学习、数据库系统、分布式系统以及分布式计算等领域。
文章信息
GitHub 开源项目:
https://github.com/Relaxed-System-Lab/AtmosSci-Bench
文章地址:
https://arxiv.org/abs/2502.01159
#SEPRESS #联合国科学十年无缝预测服务 #人工智能 #大语言模型 #AIforScience #基准测试 #气候与大气科学
END
声明:欢迎转载、转发。气象学家公众号转载信息旨在传播交流,其内容由作者负责,不代表本号观点。文中部分图片来源于网络,如涉及内容、版权和其他问题,请联系小编处理。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号