AI Can Learn Scientific Taste: 让人工智能拥有科学判断能力

AI Can Learn Scientific Taste: 让人工智能拥有科学判断能力

安全风信子
发布于 2026-03-25 08:21:35
发布于 2026-03-25 08:21:35
作者: HOS(安全风信子) 日期: 2026-03-21 主要来源平台: HuggingFace 摘要: AI Can Learn Scientific Taste 提出了一种通过社区反馈强化学习(RLCF)来训练 AI 学习科学品味的方法,将科学品味学习形式化为偏好建模和对齐问题。本文深入分析其核心机制、技术实现和实验结果,探讨其在 AI 科学研究中的应用价值和未来发展方向。
目录:
- 1. 背景动机与当前热点
- 2. 核心更新亮点与全新要素
- 3. 技术深度拆解与实现分析
- 4. 与主流方案深度对比
- 5. 工程实践意义、风险、局限性与缓解策略
- 6. 未来趋势与前瞻预测
1. 背景动机与当前热点
本节核心价值:理解 AI Can Learn Scientific Taste 诞生的背景和解决的核心问题,把握当前 AI 科学研究的关键挑战。
伟大的科学家具有强烈的判断力和远见,这与我们所说的科学品味密切相关。科学品味是指判断和提出具有高潜在影响的研究想法的能力。然而,大多数相关研究都集中在提高 AI 科学家的执行能力,而增强 AI 的科学品味仍然未被充分探索。
在当前的 AI 研究中,存在以下挑战:
- 科学品味的定义和量化:科学品味是一个主观的概念,如何定义和量化它是一个难题。
- 监督信号的获取:如何获取高质量的监督信号来训练 AI 学习科学品味。
- 偏好建模和对齐:如何将科学品味学习形式化为偏好建模和对齐问题。
- 泛化能力:训练出的模型是否能够泛化到未来年份、未见领域和同行评审偏好。
AI Can Learn Scientific Taste 的出现正是为了解决这些核心问题,通过引入社区反馈强化学习(RLCF)范式,利用大规模社区信号作为监督,将科学品味学习形式化为偏好建模和对齐问题。
2. 核心更新亮点与全新要素
本节核心价值:深入了解 AI Can Learn Scientific Taste 的三大核心创新点,及其如何实现 AI 的科学品味学习。
AI Can Learn Scientific Taste 引入了三个关键的全新要素,使其在 AI 科学研究领域脱颖而出:
- 社区反馈强化学习(RLCF):提出了一种新的训练范式,利用大规模社区信号作为监督,而不是传统的人工标注。
- Scientific Judge:训练了一个判断模型,在 70 万对领域和时间匹配的高引用 vs. 低引用论文对上进行训练,用于判断研究想法的潜在影响。
- Scientific Thinker:使用 Scientific Judge 作为奖励模型,训练了一个策略模型,用于提出具有高潜在影响的研究想法。
此外,该研究还创建了 SciJudgeBench 数据集,包含了领域和时间匹配的高引用 vs. 低引用论文对,为科学品味学习提供了高质量的监督信号。
3. 技术深度拆解与实现分析
本节核心价值:深入剖析 AI Can Learn Scientific Taste 的技术实现细节,包括其架构设计、核心组件和工作流程。
3.1 架构设计
AI Can Learn Scientific Taste 的架构设计主要包括以下几个部分:
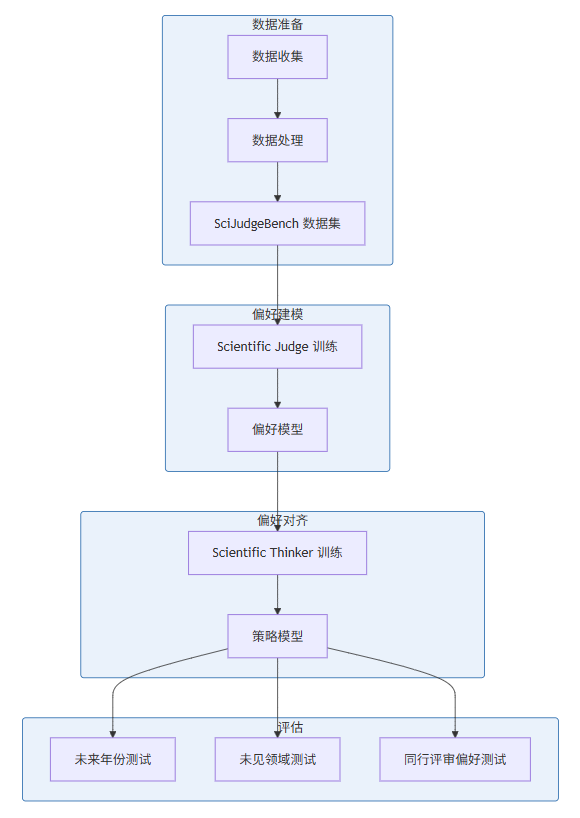
3.2 核心组件详解
3.2.1 社区反馈强化学习(RLCF)
RLCF 是一种新的训练范式,利用大规模社区信号作为监督,具体步骤如下:
- 数据收集:收集大量领域和时间匹配的高引用 vs. 低引用论文对。
- 偏好建模:训练 Scientific Judge 来学习社区的偏好。
- 偏好对齐:使用 Scientific Judge 作为奖励模型,训练 Scientific Thinker 来提出符合社区偏好的研究想法。
3.2.2 Scientific Judge
Scientific Judge 是一个判断模型,用于评估研究想法的潜在影响,主要包括:
- 训练数据:70 万对领域和时间匹配的高引用 vs. 低引用论文对。
- 模型架构:基于大型语言模型,通过对比学习训练。
- 评估能力:能够判断研究想法的潜在影响,泛化到未来年份、未见领域和同行评审偏好。
3.2.3 Scientific Thinker
Scientific Thinker 是一个策略模型,用于提出具有高潜在影响的研究想法,主要包括:
- 训练方法:使用强化学习,以 Scientific Judge 作为奖励模型。
- 生成能力:能够生成具有高潜在影响的研究想法。
- 评估指标:通过 Scientific Judge 和人类评估来评估生成想法的质量。
3.3 代码示例
以下是 AI Can Learn Scientific Taste 的核心实现示例:
# Scientific Judge 训练
class ScientificJudge:
def __init__(self, model):
self.model = model
def train(self, dataset):
"""在 SciJudgeBench 数据集上训练 Scientific Judge"""
# 数据加载和预处理
train_data = self.preprocess_data(dataset)
# 对比学习训练
for batch in train_data:
high_citation_paper = batch['high_citation']
low_citation_paper = batch['low_citation']
# 计算偏好分数
high_score = self.model.score(high_citation_paper)
low_score = self.model.score(low_citation_paper)
# 计算对比损失
loss = self.contrastive_loss(high_score, low_score)
# 反向传播
loss.backward()
self.optimizer.step()
def judge(self, research_idea):
"""评估研究想法的潜在影响"""
return self.model.score(research_idea)
# Scientific Thinker 训练
class ScientificThinker:
def __init__(self, policy_model, scientific_judge):
self.policy_model = policy_model
self.scientific_judge = scientific_judge
def train(self, training_steps):
"""使用强化学习训练 Scientific Thinker"""
for step in range(training_steps):
# 生成研究想法
research_idea = self.policy_model.generate_idea()
# 评估研究想法
reward = self.scientific_judge.judge(research_idea)
# 计算策略梯度
loss = -reward * self.policy_model.log_prob(research_idea)
# 反向传播
loss.backward()
self.optimizer.step()
def generate_idea(self):
"""生成具有高潜在影响的研究想法"""
return self.policy_model.generate_idea()
# 主流程
def main():
# 准备数据集
dataset = load_scijudge_bench()
# 训练 Scientific Judge
judge_model = load_llm_model()
scientific_judge = ScientificJudge(judge_model)
scientific_judge.train(dataset)
# 训练 Scientific Thinker
policy_model = load_llm_model()
scientific_thinker = ScientificThinker(policy_model, scientific_judge)
scientific_thinker.train(10000)
# 评估
evaluate(scientific_thinker, scientific_judge)3.4 实验结果分析
AI Can Learn Scientific Taste 在多个实验中展示了显著的性能提升:
- Scientific Judge 性能:
- 优于 SOTA LLMs(如 GPT-5.2、Gemini 3 Pro)
- 泛化到未来年份测试、未见领域和同行评审偏好
- Scientific Thinker 性能:
- 提出的研究想法具有比基线更高的潜在影响
- 在多个评估指标上表现优异
- 消融实验:
- 验证了社区反馈强化学习的有效性
- 分析了不同组件对性能的贡献
4. 与主流方案深度对比
本节核心价值:通过多维度对比,清晰展示 AI Can Learn Scientific Taste 与其他 AI 科学研究方案的优势和差异。
方案 | 监督信号 | 偏好建模 | 策略优化 | 泛化能力 | 性能表现 | 可扩展性 |
|---|---|---|---|---|---|---|
AI Can Learn Scientific Taste | 社区反馈 | 对比学习 | 强化学习 | 强 | 优于 SOTA LLMs | 高 |
传统 AI 科学家 | 人工标注 | 无 | 无 | 弱 | 有限 | 低 |
基于引用的方法 | 引用计数 | 简单统计 | 无 | 中 | 中等 | 中 |
专家评审系统 | 专家反馈 | 专家知识 | 无 | 中 | 高但成本高 | 低 |
4.1 对比分析
- 监督信号:AI Can Learn Scientific Taste 使用大规模社区信号作为监督,而传统方案依赖人工标注或简单统计。
- 偏好建模:AI Can Learn Scientific Taste 通过对比学习训练 Scientific Judge,而传统方案要么没有偏好建模,要么依赖专家知识。
- 策略优化:AI Can Learn Scientific Taste 使用强化学习优化 Scientific Thinker,而传统方案通常没有策略优化机制。
- 泛化能力:AI Can Learn Scientific Taste 能够泛化到未来年份、未见领域和同行评审偏好,而传统方案泛化能力有限。
- 性能表现:实验结果表明,AI Can Learn Scientific Taste 优于 SOTA LLMs,而传统方案性能有限或成本过高。
- 可扩展性:AI Can Learn Scientific Taste 具有良好的可扩展性,能够处理大规模数据,而传统方案可扩展性有限。
5. 工程实践意义、风险、局限性与缓解策略
本节核心价值:探讨 AI Can Learn Scientific Taste 在工程实践中的应用价值、潜在风险和局限性,以及相应的缓解策略。
5.1 工程实践意义
AI Can Learn Scientific Taste 为 AI 科学研究带来了多方面的价值:
- 科学研究加速:通过 AI 辅助提出高潜在影响的研究想法,加速科学研究进程。
- 资源优化:减少无效研究方向的探索,优化研究资源分配。
- 跨领域知识迁移:帮助研究人员发现跨领域的研究机会,促进学科交叉。
- 科学教育:为学生和初级研究人员提供科学品味的指导,培养下一代科学家。
- 决策支持:为科研基金分配、论文评审等提供决策支持。
5.2 风险与局限性
尽管 AI Can Learn Scientific Taste 展现了显著的优势,但也存在一些风险和局限性:
- 引用偏差:引用计数可能反映的不仅仅是研究质量,还包括可见性、合作网络和领域特定的引用文化。
- 新颖性挑战:基于历史数据训练的模型可能倾向于生成主流研究想法,而忽视具有突破性的新颖想法。
- 领域适应性:不同领域的科学品味可能存在差异,模型可能在某些领域表现更好。
- 评估困难:科学品味的评估本身就是一个主观过程,难以完全客观量化。
- 伦理问题:AI 生成的研究想法可能引发知识产权和学术伦理问题。
5.3 缓解策略
针对上述风险和局限性,可以采取以下缓解策略:
- 多维度评估:结合引用计数、同行评审、专家评估等多种指标,综合评估研究想法的质量。
- 新颖性鼓励:在奖励函数中加入新颖性激励,鼓励模型生成具有突破性的研究想法。
- 领域适应:为不同领域开发专门的模型或进行领域适应,提高模型在特定领域的表现。
- 人机协作:将 AI 作为辅助工具,与人类科学家协作,充分发挥两者的优势。
- 伦理规范:制定明确的伦理规范,指导 AI 在科学研究中的应用。
6. 未来趋势与前瞻预测
本节核心价值:展望 AI Can Learn Scientific Taste 技术的未来发展方向,以及其对 AI 科学研究的潜在影响。
6.1 技术演进趋势
AI Can Learn Scientific Taste 代表了 AI 科学研究的一个重要方向,未来可能的演进趋势包括:
- 多模态科学品味:将科学品味学习扩展到多模态领域,包括文本、图像、实验数据等。
- 实时反馈循环:建立实时反馈循环,使模型能够从最新的科学研究中学习。
- 跨学科融合:促进不同学科之间的知识融合,发现跨学科的研究机会。
- 个性化科学助手:根据研究人员的兴趣和专长,提供个性化的研究想法建议。
- 自动化研究规划:不仅生成研究想法,还能制定详细的研究计划和实验设计。
6.2 应用前景
AI Can Learn Scientific Taste 的技术理念和实现方法具有广泛的应用前景:
- 学术研究:辅助研究人员提出高潜在影响的研究想法,加速科学发现。
- 科研管理:为科研基金分配、论文评审等提供决策支持,优化研究资源分配。
- 教育领域:为学生和初级研究人员提供科学品味的指导,培养下一代科学家。
- 产业创新:帮助企业发现具有商业潜力的研究方向,促进技术创新。
- 政策制定:为科技政策制定提供数据支持,引导科学研究方向。
6.3 开放问题
AI Can Learn Scientific Taste 的发展也带来了一些值得深入研究的开放问题:
- 科学品味的定义:如何更准确地定义和量化科学品味?
- 多维度评估:如何综合考虑引用计数、同行评审、专家评估等多种指标?
- 新颖性与可行性平衡:如何平衡研究想法的新颖性和可行性?
- 跨文化差异:不同文化背景下的科学品味是否存在差异?如何处理这些差异?
- 长期影响:AI 辅助科学研究对科学发展的长期影响是什么?
参考链接:
- 主要来源:AI Can Learn Scientific Taste - OpenMOSS 的科学品味学习方案
- 辅助:GitHub 仓库 - AI Can Learn Scientific Taste 的代码实现
附录(Appendix):
- 实验环境:SciJudgeBench 数据集(70 万对领域和时间匹配的高引用 vs. 低引用论文对)
- 模型配置:Scientific Judge 和 Scientific Thinker 的模型架构和训练参数
- 关键超参数:学习率、批量大小、强化学习参数
关键词: AI Can Learn Scientific Taste, 科学品味, 社区反馈强化学习, Scientific Judge, Scientific Thinker, 偏好建模, 科学研究

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-03-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号