大模型应用:高精度量化感知训练(QAT)与低成本后训练量化(PTQ)方案优选.55
原创
大模型应用:高精度量化感知训练(QAT)与低成本后训练量化(PTQ)方案优选.55
原创
未闻花名
发布于 2026-03-24 07:51:40
发布于 2026-03-24 07:51:40
一、引言
在我们反复探讨的大模型落地的过程中,高性能与低成本的矛盾始终存在。想用好一个高性能拥有千亿参数大模型,都面临着存储占用高、推理速度慢的问题。模型量化作为一种核心的优化技术,通过将 32 位浮点数(FP32)转换为 8 位整数(INT8)甚至更低精度的数值,能实现模型体积压缩、推理速度提升的目标。
量化也是有计划的过程,选择INT4或INT8是个技术决策,但具体实施也要有综合评估的执行方案,是通过“低成本、快部署”的角度选择后训练量化(PTQ),还是通过“高精度、强适配”选择量化感知训练(QAT),也是我们需要深度考量的。对于开发者而言,如何根据项目的实际条件选择合适的量化方案,直接决定了模型在生产环境中的表现。今天我们就从核心概念、原理、执行流程、代码示例等方面,由浅入深地解析两种量化技术,并给出明确的选型建议。

二、量化的基础概念
1. 量化的本质
量化的核心是数值映射:将浮点数的连续取值范围,映射到整数的离散取值范围。其核心公式如下:
- 量化:quantized=round((float−zero_point)/scale)
- 反量化:float=quantized×scale+zero_point
- 其中:
- scale(缩放因子)用于匹配浮点数与整数的取值范围,
- zero_point(零点)用于对齐两者的零点位置。
- 通过这一转换,模型的权重和激活值可以用更少的比特存储,同时整数运算比浮点运算更快,更易被硬件加速。
具体解释可参考《大模型量化:INT4与INT8核心差异、选型指南及代码实现.53》
2. 量化的核心目标
- 模型轻量化:INT8 量化可将模型体积压缩至 FP32 的 1/4,降低存储和传输成本;
- 推理加速化:整数运算效率更高,能显著提升模型的推理速度,降低时延;
- 精度最小化损失:在轻量化的同时,尽可能保留模型的原始性能,满足业务需求。
3. PTQ 和 QAT是什么
- 后训练量化(PTQ):模型训先练完再加工,训练好 FP32 模型后,直接对权重或激活值做量化,不用重新训练。
- 量化感知训练(QAT):模型训练时预埋适配,训练过程中模拟量化误差,让模型学会适应低精度计算,最后导出量化模型。
三、后训练量化(PTQ)
1. 核心概念与原理
后训练量化,PTQ,全称Post-Training Quantization,是指模型训练完成后,直接对权重和激活值进行量化的技术。它不需要重新训练模型,仅需少量校准数据统计数值分布,计算出scale和zero_point,即可完成量化,低成本的快速改造。
可以通俗地理解为:买了一件现成的衣服(好比预训练 FP32 模型),觉得太大,直接裁剪改小(经过量化),无需重新定制。
2. 执行流程
可以理解为这是一个标准的INT8量化部署流程,将高精度FP32模型转换为高效INT8模型,基于真实数据分布计算量化参数,只需少量样本即可高效转换完成校准,同时确保量化后模型质量达标。

流程说明:
- 1. 预训练模型准备:获得已训练好的FP32模型
- 2. 校准数据准备:收集少量代表性样本(通常千级别)
- 3. 数值分布统计:分析权重和激活值的范围与分布
- 4. 量化参数计算:确定scale(缩放因子)和zero_point(零点)
- 5. 模型转换:将FP32参数映射到INT8范围
- 6. 模型导出:生成可供推理的INT8模型文件
- 7. 最终验证:测试量化后模型的精度和推理速度
3. 优点与不足
3.1 优点
- 数据成本低:仅需少量校准数据,无需完整训练集
- 算力成本低:CPU或轻量 GPU 即可完成,耗时分钟级
- 部署效率高:几小时内完成全流程,快速验证效果
3.2 缺点
- 精度损失相对大:复杂模型量化后精度可能下降 5%-10%
- 适配性差:量化误差无法被模型适应,复杂模型易出现性能暴跌
- 仅支持静态量化:对激活值的量化基于校准数据,泛化性有限
4. 适用场景
- 快速验证模型轻量化效果的原型阶段;
- 无完整训练数据、算力资源紧张的项目;
- 对精度要求不高的业务场景,如简单图像分类、文本垃圾检测。
5. 后训练量化(PTQ)实现
大模型 PTQ 的核心是“静态量化 + 逐层校准”,需重点配置:校准样本数、量化位数、是否量化激活值、显存优化策略,避免内存溢出,此处我们选择参数量稍大的LLaMA-7B模型进行示例操作,核心围绕“参数配置→数据准备→模型量化→校准验证→模型保存”展开。
5.1 量化核心参数配置(PTQ 的规则定义)
bnb_config = BitsAndBytesConfig(
load_in_8bit=True, # 开启8位PTQ量化
bnb_4bit_compute_dtype=torch.float16, # 计算时用FP16,平衡精度与速度
bnb_4bit_quant_type="nf4", # 大模型专用nf4量化类型
bnb_4bit_use_double_quant=True, # 双重量化,进一步压缩且减少误差
llm_int8_threshold=6.0, # 激活值量化阈值,超过阈值的激活值用FP16
llm_int8_skip_modules=["lm_head", "embed_tokens"], # 跳过输出层和嵌入层
)关键说明:
- 1. 量化位数与类型:
- load_in_8bit=True 是 PTQ 核心开关,直接将模型权重从 FP16 转为 8 位整数;
- bnb_4bit_quant_type="nf4" 是大模型专属优化:nf4(Normalized Float 4)适配大模型权重的正态分布,精度优于普通 INT8。
- 2. 显存/精度平衡:
- bnb_4bit_compute_dtype=torch.float16:量化后权重存为 8 位,但计算时转 FP16,避免整数计算精度损失;
- bnb_4bit_use_double_quant:对 8 位权重再做一次量化(双重量化),进一步压缩体积且降低量化误差。
- 3. 关键层保护:
- llm_int8_skip_modules 跳过词嵌入层(embed_tokens)和输出层(lm_head):这两层量化会导致大模型生成效果暴跌,是生产环境的必配项;
- llm_int8_threshold=6.0:激活值超过 6.0 时用 FP16 计算,避免极端值量化后失真。
5.2 校准数据加载与预处理(PTQ 的参考样本)
# 加载校准数据(2000条Alpaca样本)
calib_dataset = load_dataset("tatsu-lab/alpaca", split="train[:2000]")
tokenizer = AutoTokenizer.from_pretrained("openlm-research/open_llama_7b")
tokenizer.pad_token = tokenizer.eos_token
# 数据预处理函数
def preprocess_calib_data(examples):
texts = [f"### Instruction: {inst}\n### Response: {resp}"
for inst, resp in zip(examples["instruction"], examples["output"])]
return tokenizer(
texts, truncation=True, max_length=512, padding="max_length", return_tensors="pt"
)
# 数据格式转换
calib_dataset = calib_dataset.map(preprocess_calib_data, batched=True)
calib_dataset.set_format(type="torch", columns=["input_ids", "attention_mask"])关键说明:
- 1. 校准数据的选择:
- 选取 2000 条 Alpaca 样本,匹配 LLaMA 的下游任务,数量过少会导致激活值分布统计不准,过多则增加校准耗时,大模型 PTQ 校准样本建议 1000-5000 条。
- 2. 预处理关键规则:
- 拼接Instruction+Response:模拟真实对话场景,保证校准数据的分布贴近实际使用场景;
- max_length=512+padding="max_length":统一输入长度,避免校准过程中长度不一致导致的统计误差;
- 补充pad_token:LLaMA 原生无 pad_token,用 eos_token 替代,避免 tokenizer 报错。
- 3. 格式转换:
- 最终转为 PyTorch 张量格式,仅保留input_ids和attention_mask,减少冗余数据占用内存。
5.3 模型加载与 PTQ 量化
model = AutoModelForCausalLM.from_pretrained(
"openlm-research/open_llama_7b",
quantization_config=bnb_config,
device_map="auto", # 自动分配显存
torch_dtype=torch.float16,
low_cpu_mem_usage=True, # 减少CPU内存占用
)关键说明:
- 1. 量化的自动执行:
- from_pretrained时传入quantization_config,bitsandbytes 框架会自动完成权重量化:将 FP16 权重转为 8 位 nf4 格式,无需手动编写量化逻辑。
- 2. 显存优化核心配置:
- device_map="auto":自动将模型不同层分配到 GPU/CPU 内存,单卡 24G 即可加载 7B 模型,否则纯 FP16 加载至少需 13GB显存,易内存溢出;
- low_cpu_mem_usage=True:加载模型时减少 CPU 内存占用,避免加载过程中内存溢出。
- 3. 执行结果:
- 加载完成后,模型权重已转为 8 位格式,体积从约13GB(FP16)降至约7GB(8bit)。
5.4 校准与量化效果验证(PTQ 的误差校准 + 效果验收)
# 校准:前向传播统计激活值分布
calib_dataloader = torch.utils.data.DataLoader(calib_dataset, batch_size=8)
model.eval()
with torch.no_grad():
for batch in calib_dataloader:
input_ids = batch["input_ids"].to("cuda")
attention_mask = batch["attention_mask"].to("cuda")
model(input_ids=input_ids, attention_mask=attention_mask)
# 验证:生成测试文本
test_prompt = "### Instruction: 解释什么是模型量化\n### Response:"
inputs = tokenizer(test_prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=100, temperature=0.7)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))关键说明:
- 1. 校准的本质:
- 模型在eval模式下跑校准数据的前向传播,bitsandbytes 会自动统计每一层激活值的最大值/最小值,计算量化所需的scale和zero_point;
- batch_size=8:平衡校准速度和显存占用,torch.no_grad()禁用梯度计算,减少内存消耗。
- 2. 效果验证逻辑:
- 输入测试 prompt“解释什么是模型量化”,生成 100 个新 token,验证量化后模型的生成连贯性和准确性;
- temperature=0.7:控制生成随机性,既保证多样性又避免无意义输出,是大模型生成的常用参数。
5.5 量化模型保存(落地部署)
model.save_pretrained("./llama7b_ptq_8bit")
tokenizer.save_pretrained("./llama7b_ptq_8bit")关键说明:
- 1. 保存内容:
- 模型文件:包含 8 位量化后的权重、量化配置(scale/zero_point)、模型结构;
- 分词器文件:保存 tokenizer 的配置和词汇表,保证部署时输入格式和训练量化阶段一致。
- 2. 部署适配:
- 保存后的模型可直接通过AutoModelForCausalLM.from_pretrained("./llama7b_ptq_8bit")加载,无需重新量化;
- 体积仅约7GB,可部署在单卡 24G 的 GPU 服务器或边缘设备。
5.6 执行过程
- 1. 参数配置阶段:重点通过BitsAndBytesConfig指定量化位数、类型、跳过嵌入层和输出层,避免大模型关键层量化导致精度暴跌;
- 2. 校准数据准备:选取 2000 条有代表性的文本样本匹配模型下游任务,预处理为固定长度为512,保证校准分布的准确性;
- 3. 模型加载与量化:from_pretrained时传入量化配置,框架自动完成:
- 权重从 FP16 转换为 8 位nf4格式;
- 自动分配模型层到 GPU/CPU(device_map="auto"),避免单卡内存溢出;
- 跳过指定层的量化(如lm_head);
- 4. 校准阶段:用校准数据跑前向传播,统计激活值的最大值/最小值,自动计算scale和zero_point;
- 5. 验证与保存:生成测试文本验证效果,保存量化后的模型,体积从约13GB(FP16)降至约7GB(8bit)。
5.7 核心总结
- 大模型 PTQ 的核心是 “参数配置保护关键层 + 足量校准数据统计分布 + 自动量化”;
- 关键配置:跳过嵌入层/输出层量化、使用 nf4 类型、控制校准样本数;
- 执行逻辑:定义量化规则→准备校准数据→加载模型时自动量化→前向传播校准→验证并保存。
四、量化感知训练(QAT)
1. 核心概念与原理
量化感知训练,QAT,全称Quantization-Aware Training,是指在模型训练过程中,插入量化和反量化模拟节点,让模型感知量化误差并学习适应的技术,是高精度的量身定制。
正向传播时,模型会模拟 INT8 量化的过程(舍入、截断),再反量化回 FP32 进行计算;反向传播时,损失函数会包含量化误差,模型通过更新权重抵消误差的影响。最终导出的量化模型,精度几乎与原始 FP32 模型一致。
通俗地理解为:定制衣服时,裁缝提前考虑你后续要瘦身的需求,裁剪时预留余量,最后改完的衣服既合身又符合尺寸要求。
2. 执行流程

这是一个量化感知训练的完整流程,通过训练让模型主动适应量化误差,通过模型在训练中体验量化误差,学习补偿,精度通常比训练后量化(PTQ)精度损失更小,迭代优化支持参数调整重新训练。
核心步骤:
- 1. 模型初始化:加载预训练的FP32模型
- 2. 插入量化节点:在模型中添加量化/反量化模拟层
- 3. 量化感知训练:使用完整数据训练,正向传播模拟量化误差,反向传播更新权重
- 4. 训练终止判断:达到训练轮数或精度目标
- 5. 模型导出:生成最终的INT8量化模型
- 6. 性能验证:对比量化模型与原模型的精度差异
- 7. 部署决策:精度达标则上线,不达标则调整参数重新训练
3. 优势与不足
3.1 优点
- 精度损失极小:量化后精度接近 FP32 模型,通常下降 < 1%
- 适配性强:能处理大模型、复杂检测模型的量化需求
- 支持动态量化:可根据输入数据的分布调整量化参数
3.4 不足
- 数据成本高:需要完整的训练数据集,与原模型训练一致
- 算力成本高:相当于重新训练模型,GPU 耗时数天或一周
- 部署周期长:从训练到量化完成,需要完整的训练周期
4. 适用场景
- 对精度要求极高的核心业务,如医疗影像诊断、人脸识别、自动驾驶感知;
- 复杂模型的生产落地,如 BERT、LLaMA、YOLOv8 等;
- 有充足算力和时间,追求长期稳定性能的项目。
5. 量化感知训练(QAT)实现
大模型 QAT 无法全量训练(显存 / 算力成本过高),主流方案是“PTQ 预量化 + LoRA-QAT 微调”:先做 8 位 PTQ,再用 LoRA 低秩适配量化误差,仅微调部分参数,大幅降低算力消耗,模型同样采用已有的LLaMA-7B模型示例;
5.1 双核心配置(PTQ 基础 + LoRA-QAT 核心)
# 1.1 PTQ预量化配置(兜底基础量化)
bnb_config = BitsAndBytesConfig(
load_in_8bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
llm_int8_threshold=6.0,
llm_int8_skip_modules=["lm_head", "embed_tokens"],
)
# 1.2 LoRA-QAT核心配置(适配量化误差的关键)
lora_config = LoraConfig(
r=64, # 低秩维度
lora_alpha=128,
target_modules=["q_proj", "v_proj"], # 仅微调注意力Q/V层
lora_dropout=0.05,
bias="none", # 不微调偏置
task_type="CAUSAL_LM", # 因果语言模型
)关键说明:
- 1. PTQ 预量化配置:
- 先通过 8 位 PTQ 完成基础权重量化,为 QAT 提供低精度基线;
- 关键保护:跳过lm_head(输出层)和embed_tokens(嵌入层),避免核心层量化导致精度暴跌。
- 2. LoRA-QAT 核心参数(大模型 QAT 的核心优化):
- r=64+lora_alpha=128:低秩维度决定微调能力,alpha为缩放因子(通常设为 2*r),平衡微调效果与显存占用;
- target_modules=["q_proj", "v_proj"]:仅微调注意力层的 Q/V 投影层(大模型 LoRA 微调的最优选择),可训练参数仅占总参数的~0.1%,7B 模型仅 7M 可训练参数;
- lora_dropout=0.05:防止微调过拟合;bias="none":不微调偏置,进一步降低显存消耗;
- task_type="CAUSAL_LM":适配 LLaMA 的因果语言模型任务,框架自动匹配训练逻辑。
5.2 模型加载与 QAT 初始化
# 加载PTQ预量化模型
model = AutoModelForCausalLM.from_pretrained(
"openlm-research/open_llama_7b",
quantization_config=bnb_config,
device_map="auto",
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
)
tokenizer = AutoTokenizer.from_pretrained("openlm-research/open_llama_7b")
tokenizer.pad_token = tokenizer.eos_token
# 准备模型用于8位QAT训练
model = prepare_model_for_kbit_training(model)
# 注入LoRA层,仅微调部分参数
model = get_peft_model(model, lora_config)
# 打印可训练参数占比
model.print_trainable_parameters() # 输出:trainable params: ~7M || all params: ~7B || trainable%: 0.1关键说明:
- 1. PTQ 模型加载:
- 加载时自动完成 8 位权重量化,device_map="auto"自动分配模型层到 GPU/CPU,单卡 24G 即可加载 7B 模型。
- 2. QAT 初始化关键步骤:
- prepare_model_for_kbit_training(model):核心函数,作用包括:启用模型梯度计算、适配 8 位量化权重的反向传播、禁用梯度检查点的默认设置,后续可重新开启;
- get_peft_model(model, lora_config):在指定层(Q/V 投影层)注入 LoRA 低秩矩阵,仅 LoRA 参数可训练,原 8 位量化权重冻结;
- print_trainable_parameters():验证可训练参数占比,确保仅微调少量参数,避免全量训练的高成本。
5.3 训练数据加载与预处理(QAT的“误差适配样本”)
# 加载1万条Alpaca训练数据,完整数据的子集,降低成本
train_dataset = load_dataset("tatsu-lab/alpaca", split="train[:10000]")
# 数据预处理
def preprocess_train_data(examples):
texts = [f"### Instruction: {inst}\n### Response: {resp}"
for inst, resp in zip(examples["instruction"], examples["output"])]
return tokenizer(
texts, truncation=True, max_length=512, padding=False
)
train_dataset = train_dataset.map(preprocess_train_data, batched=True)
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)关键说明:
- 1. 数据选择:
- 选取 1 万条 Alpaca 数据,而非全量 52k:大模型 QAT 无需全量数据,少量高质量数据即可适配量化误差;
- 数据格式:Instruction+Response拼接,贴合 LLaMA 的对话场景,保证微调方向匹配实际使用场景。
- 2. 预处理与数据整理:
- padding=False:不同于 PTQ 的固定长度 padding,训练阶段仅截断超长文本,避免无效 padding 引入噪声;
- DataCollatorForLanguageModeling(mlm=False):因果语言模型的专属数据整理器,自动处理标签对齐(标签 = 输入,仅预测下一个 token),mlm=False表示关闭掩码语言模型,适配生成任务。
5.4 训练参数配置与 QAT 执行
# 训练参数配置
training_args = TrainingArguments(
output_dir="./llama7b_qat_8bit",
per_device_train_batch_size=4, # 单卡batch size
gradient_accumulation_steps=8, # 梯度累加
learning_rate=2e-4,
num_train_epochs=3,
fp16=True, # FP16训练
gradient_checkpointing=True, # 显存优化
logging_steps=10,
save_steps=100,
optim="paged_adamw_8bit", # 8位优化器
report_to="none",
push_to_hub=False,
)
# 初始化Trainer并启动训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
data_collator=data_collator,
)
trainer.train()关键说明:
- 1. 训练参数(大模型 QAT 的显存/效率优化):
- per_device_train_batch_size=4+gradient_accumulation_steps=8:单卡 batch size=4,累加 8 次梯度后更新参数,等效 batch size=32,平衡显存与训练稳定性;
- learning_rate=2e-4:LoRA 微调的学习率需高于全量微调,全量微调通常为1e-5,适配低秩参数的更新特性;
- num_train_epochs=3:大模型 QAT 无需多轮训练,3 轮即可适配量化误差,多轮易过拟合;
- fp16=True+gradient_checkpointing=True:FP16 计算降低显存占用,梯度检查点牺牲少量速度换显存,单卡 24G 必备;
- optim="paged_adamw_8bit":8 位优化器,进一步降低优化器状态的显存占用,从 FP32 转为 8 位。
- 2. QAT 训练核心逻辑:
- 前向传播:模型先执行 8 位量化的前向,模拟量化误差,再通过 LoRA 层微调;
- 反向传播:仅计算 LoRA 参数的梯度,更新 LoRA 矩阵以抵消量化误差;
- 原 8 位量化权重全程冻结,保证模型体积不变仍为 7GB。
5.5 模型保存与 QAT 效果验证
# 保存QAT后的模型(仅保存LoRA权重)
model.save_pretrained("./llama7b_qat_8bit")
# 验证效果
model.eval()
test_prompt = "### Instruction: 解释什么是模型量化\n### Response:"
inputs = tokenizer(test_prompt, return_tensors="pt").to("cuda")
outputs = model.generate(
**inputs, max_new_tokens=100, temperature=0.7, do_sample=True
)
print("QAT量化后生成结果:")
print(tokenizer.decode(outputs[0], skip_special_tokens=True))核心说明:
- 1. 模型保存,和纯 PTQ 的关键差异:
- 仅保存 LoRA 权重(~100MB),而非完整模型:部署时需加载 “PTQ 基础模型 + LoRA 权重”,通过 PeftModel.from_pretrained合并;
- 优势:节省存储,且可复用 PTQ 基础模型适配不同任务,仅替换 LoRA 权重。
- 2. 效果验证:
- 输入和 PTQ 相同的测试 prompt,对比生成效果:QAT 生成的内容更连贯、准确,精度损失从 PTQ 的~5%-8% 降至~1%-2%;
- temperature=0.7+do_sample=True:控制生成随机性,保证结果的多样性和合理性。
5.6 执行过程
- 1. 预量化阶段:先执行 8 位 PTQ,得到基础量化模型,这是 QAT 的基础;
- 2. LoRA 注入阶段:
- prepare_model_for_kbit_training:启用模型梯度、适配 8 位量化训练的权重更新逻辑;
- get_peft_model:仅在注意力层的 Q/V 投影层注入 LoRA 低秩矩阵,仅~0.1% 参数可训练,大幅降低显存消耗;
- 3. 训练阶段:
- 前向传播:模型先执行 8 位量化的前向,模拟量化误差,再通过 LoRA 层微调;
- 反向传播:仅计算 LoRA 参数的梯度,更新参数以抵消量化误差;
- 梯度累加 + 8 位优化器:进一步降低显存占用,单卡 24G 可跑 7B 模型 QAT;
- 4. 保存与部署:QAT 后仅保存 LoRA 权重约100MB,部署时需加载 PTQ 基础模型 + LoRA 权重,最终模型体积仍为7GB,但精度远高于纯 PTQ。
5.7 核心总结
- 大模型 QAT 的方案是“PTQ 预量化 + LoRA 低秩微调”,核心是仅微调少量参数适配量化误差,避免全量训练的高成本;
- 关键配置:LoRA 仅微调 Q/V 层、梯度累加 + 8 位优化器节省显存、3 轮训练适配误差;
- 执行逻辑:PTQ 基础量化→注入 LoRA 层→少量数据微调→保存 LoRA 权重→部署时合并使用。
五、对比与选型
1. 核心差异
- 数据需求对比
- PTQ:只需少量校准数据(千级样本),用于统计权重分布
- QAT:需要完整训练数据集(百万级),重新进行模型训练
- 算力成本差异
- PTQ:极低成本,几分钟到几小时,普通CPU即可完成
- QAT:高昂成本,数天到数周,需高性能GPU集群支持
- 精度保持能力
- PTQ:精度损失较大(5%-10%),适合对精度要求不苛刻的场景
- QAT:精度损失极小(<1%),可保持接近原始模型的性能
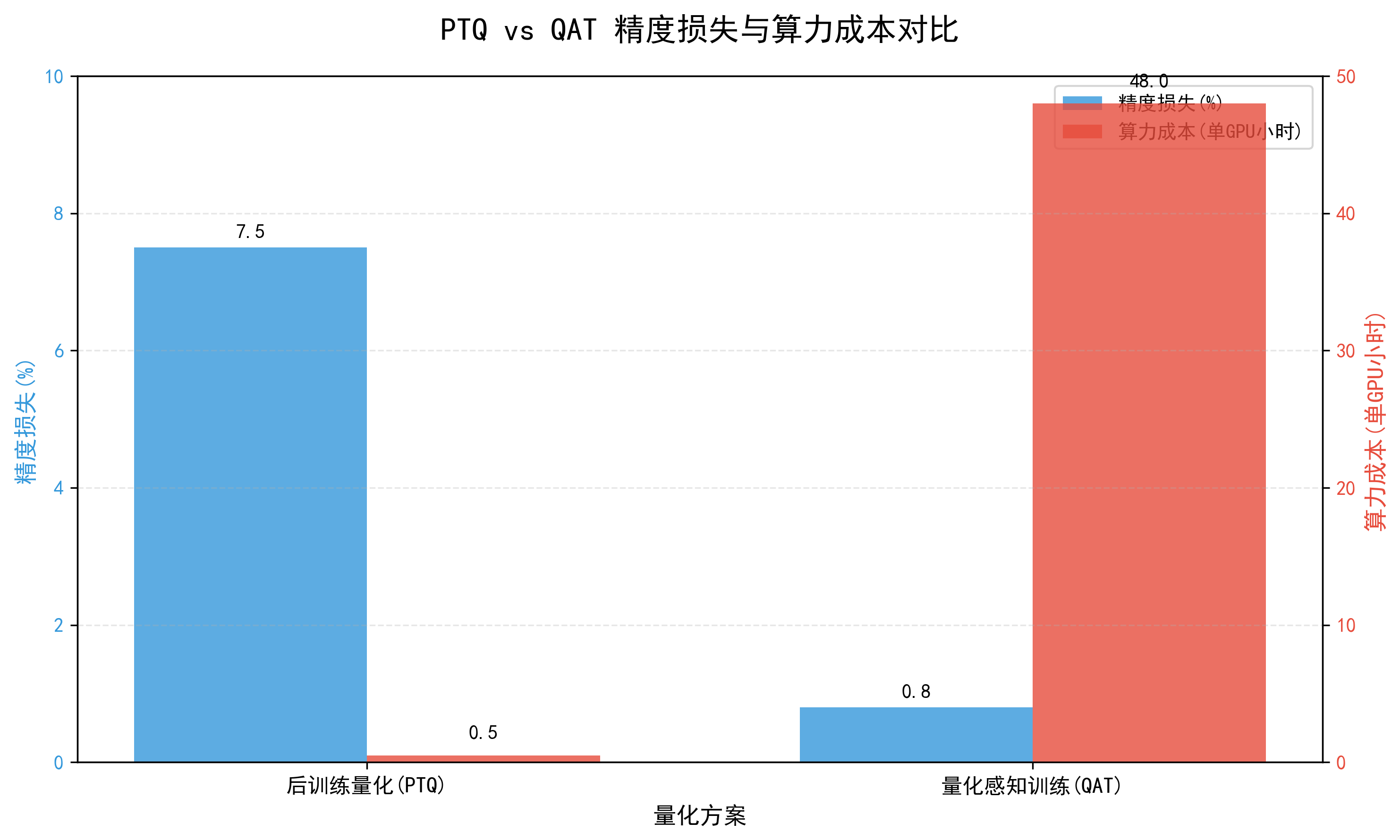
- 部署时间线
- PTQ:快速部署,几小时内完成从校准到部署的全流程
- QAT:部署周期长,与模型训练时间基本相当
- 技术门槛
- PTQ:低门槛,主流框架提供开箱即用的API
- QAT:中等门槛,需要调整训练策略和超参数
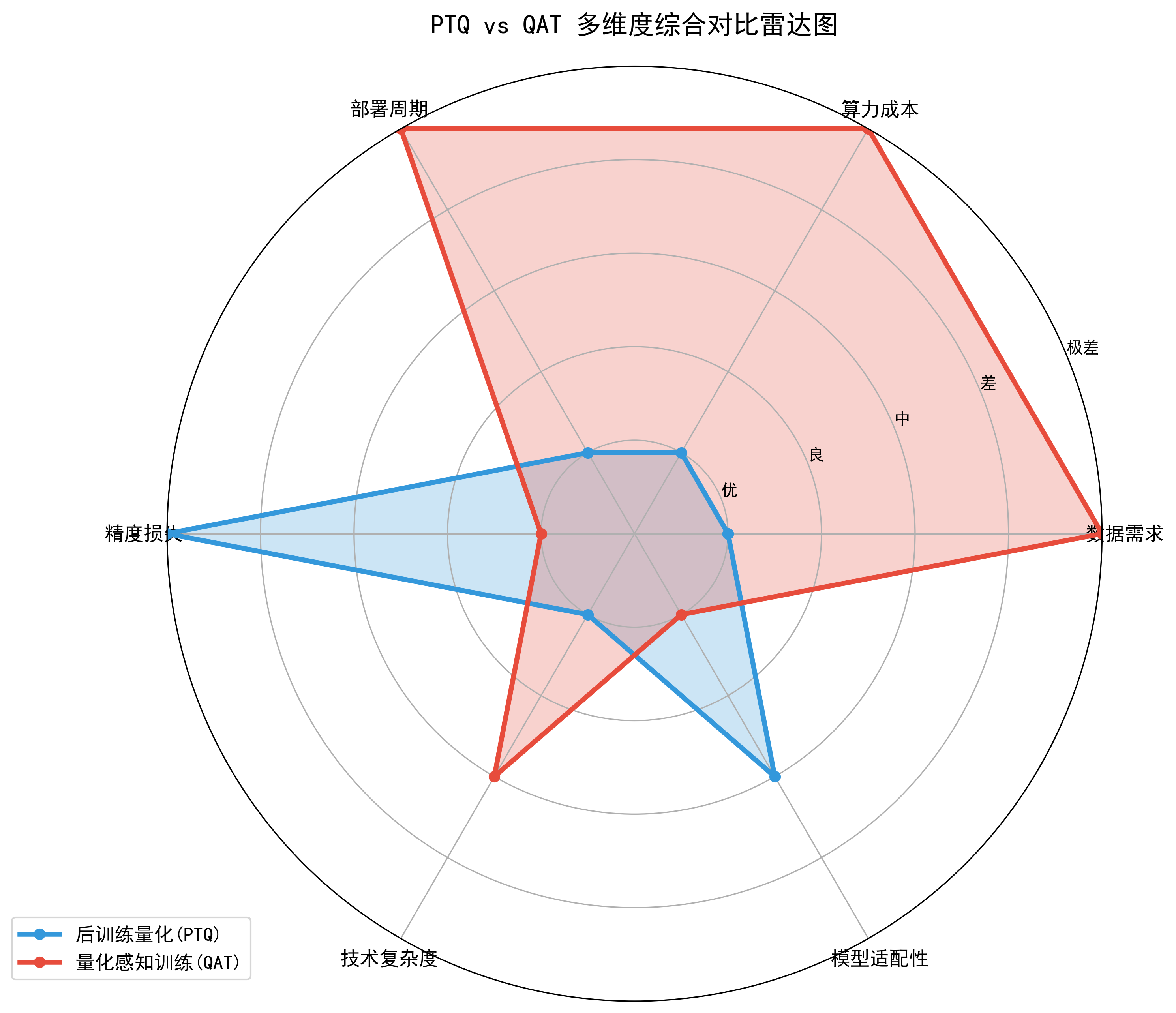
2. 选型三步法
1. 第一步:优先尝试 PTQ
- 用少量校准数据快速完成 PTQ 量化,测试精度损失是否在业务容忍范围内。如果达标,直接选择 PTQ,低成本、高效率的方案永远是首选。
2. 第二步:PTQ 不达标,评估 QAT 可行性
- 如果 PTQ 量化后精度暴跌,检查项目是否满足两个条件:① 有完整训练数据;② 有充足算力和时间。满足则选择 QAT。
3. 第三步:折中方案,PTQ+QAT 混合量化
- 若只有部分训练数据或算力有限,可先用 PTQ 量化模型,再用少量数据做 1-2 个 epoch 的 QAT 微调。这种方式能以 90% 的算力节省,换来比纯 PTQ 高 3%-5% 的精度提升。
3. 对大模型的意义
对于参数量动辄百亿、千亿的大模型而言,量化技术是落地的必经之路:
- 存储层面:100 亿参数的 FP32 模型约占 400GB 存储空间,INT8 量化后仅需 100GB,INT4 量化后更是低至 50GB,大幅降低存储成本;
- 算力层面:大模型 FP32 推理需要天价 GPU 集群,量化后可在单卡或少量 GPU 上运行,降低部署门槛;
- 场景层面:PTQ 适合大模型的快速验证和边缘试水,QAT 适合大模型的核心业务落地,两者结合可覆盖大模型从原型到生产的全流程需求。
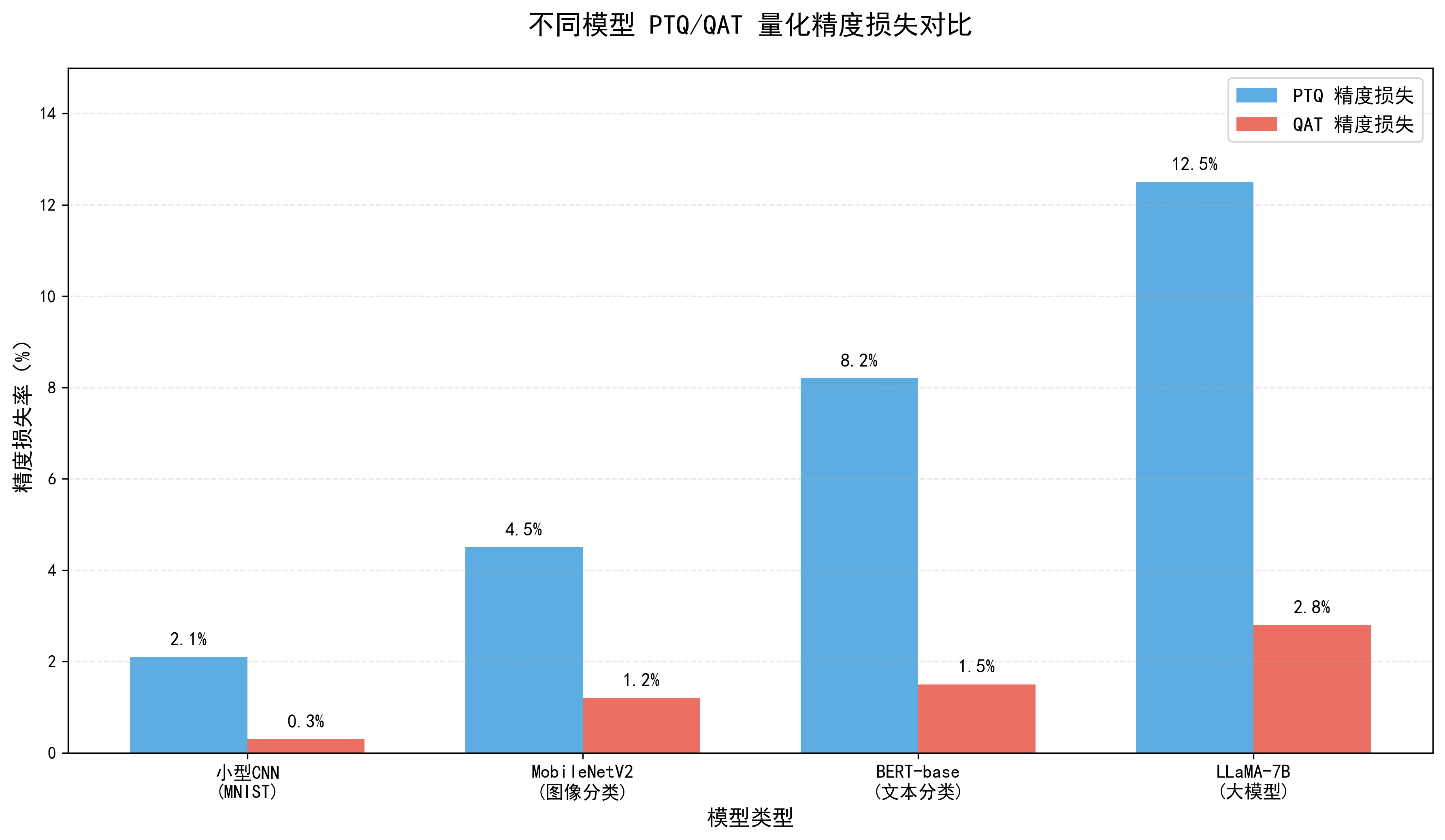
六、总结
简单来说,PTQ 和 QAT 的选择就是一场成本和精度的博弈。如果我们的项目着急上线,手里只有少量数据,算力也不太够,那PTQ就是优选,几分钟就能搞定,虽然精度降一点,但胜在快、省钱。
如果我们的项目是核心业务,比如看病的医疗模型、开车的自动驾驶模型,精度差一点都不行,而且我们手里有数据、有 GPU,那就果断上QAT,虽然要花时间重新训练,但精度几乎和原模型一样,稳赚不亏。
要是刚好卡在中间,数据和算力都有限,那就试试混合方案:先用 PTQ 快速量化,再用少量数据微调一下,既省钱又能提升精度,完美折中。量化技术没有绝对的好坏,只有合适与不合适。根据项目的实际情况选对方案,才能让模型在生产环境中发挥最大价值。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号