大模型应用:大模型量化:INT4与INT8核心差异、选型指南及代码实现.53
原创
大模型应用:大模型量化:INT4与INT8核心差异、选型指南及代码实现.53
原创
未闻花名
发布于 2026-03-23 08:51:44
发布于 2026-03-23 08:51:44
一、引言
大模型的量化我们前期也探讨了基础概念和实践原理,针对CPU的量化流程做了通俗易懂的基础说明,但实际应用场景往往是需要GPU的落地实践,随着大模型参数规模突破千亿级别,存储大、显存高、速度慢、成本贵成为制约其本地化部署的四大核心痛点。量化技术作为解决这些问题的核心途径,通过将模型高精度浮点数权重映射为低比特整数,在牺牲轻微精度的前提下,实现存储、显存和计算效率的倍数级提升。
在众多量化方案中,INT4 和 INT8 是应用最广泛的两种低比特量化技术。INT8 以“精度稳定、生态成熟”著称,INT4 则凭借“极致压缩、速度领先”成为边缘设备和消费级硬件的首选。今天我们重点从基础理论、核心差异、选型策略、场景适配、代码实现五个维度,全面拆解 INT4 与 INT8 量化技术,进一步的彻底搞懂两种方案的适用场景和落地方法。

二、基础理论
1. 量化的本质
量化的核心是“缩放 + 映射”:将模型中原本用 32 位浮点数(FP32)存储的权重,通过数学变换映射到有限的整数范围内,推理时再通过反量化还原为浮点数。这个过程的本质是用“可接受的精度损失”换取“极致的部署效率”。
压缩比的直观数学说明:
- INT8压缩比:32位 → 8位,压缩率75%,只有原始的1/4大小
- INT4压缩比:32位 → 4位,压缩率87.5%,仅有原始的1/8大小
实际存储示例:
- 原始10亿参数模型(FP32):
- 存储需求 = 10亿 × 4字节 = 40亿字节 ≈ 3.73GB
- 量化后:
- INT8:10亿 × 1字节 = 10亿字节 ≈ 0.93GB
- INT4:10亿 × 0.5字节 = 5亿字节 ≈ 0.47GB
2. 计算公式
这里我先进行初步了解,了解公式和范围的意义,对比下一小结的详细计算过程,斟酌思考,此处需要深度思考,建议多看几遍反复理解,强化min_val、max_val、q_min、q_max代表的意义;
假设原始权重的取值范围为 [min_val, max_val],目标整数范围为 [q_min, q_max],则:
2.1 计算缩放因子
- scale = (max_val - min_val) / (q_max - q_min)
2.2 计算零点
- zero_point = round(-min_val / scale) + q_min
2.3 量化公式(FP32 → 整数)
- q = clamp (round (f /scale + zero_point), q_min, q_max)
- 其中 clamp 用于限制整数范围,round 用于四舍五入。
2.4 反量化公式(整数 → FP32)
- f_hat = (q - zero_point) * scale
- 其中 f_hat 是反量化后的浮点数,近似原始值 f。
3. 核心参数
量化的关键是计算两个核心参数:缩放因子(scale) 和 零点(zero_point)。我们用结合体重秤应用的生活场景,通俗解释缩放因子(scale)和零点(zero_point)的作用,通俗易懂。
我们通过经过精度不同的秤来做个类比:
- 1. 高精度电子秤(对应 FP32 模型)
- 量程:0 ~ 200kg,刻度精确到 0.01kg,能称出 62.35kg、89.72kg;
- 问题:秤太大、太笨重、占地方,携带不方便【对应 FP32 模型存储大、显存高】。
- 2. 普通便携弹簧秤(对应 INT8 量化模型)
- 量程:-128 ~ 127,有符号 INT8,共 256 个整数刻度;
- 特点:比电子秤轻便,只能读整数刻度,但刻度数量多,误差小【对应 INT8,存储、显存减少 75%,精度损失 < 0.5%】。
- 3. 超迷你口袋秤(对应 INT4 量化模型)
- 量程:-8 ~ 7,有符号 INT4,共 16 个整数刻度;
- 特点:小巧轻便,但刻度极少,误差比 INT8 大【存储、显存减少 87.5%,需校准优化才能控误差】。
现在要把电子秤的精确体重值,转换为弹簧秤的整数刻度值,这就是量化的过程,而scale和zero_point就是完成这个转换的核心因素。
我们以“把电子秤的体重值(0~200kg)转换为 INT8 便携秤的刻度(-128~127)”为例,讲透两个参数的作用:
3.1 缩放因子(scale)
缩放因子实际就是相当于体重秤的“刻度换算比例”,把原始数据的大范围,等比例“压缩”到量化后整数的小范围。
3.1.1 INT4 缩放
- 核心作用:把电子秤的大范围(0~200kg),等比例映射到 INT4 秤的小范围(-8~7)。
- 计算公式:scale = 原始数据范围/量化后整数范围 = (200-0)/(7-(-8))=200/15≈ 13.33
- 结果解释:INT4 口袋秤的 1 个刻度,对应电子秤的 13.33kg。 这个 scale=13.33 的意思是:口袋秤的 1 个刻度,对应真实体重的 13.33kg。
3.1.1 INT8 缩放
- 核心作用:把电子秤的大范围(0~200kg),等比例映射到 INT8 秤的小范围(-128~127)。
- 计算公式:scale = 原始数据范围/量化后整数范围 = (200-0)/(127-(-128))=200/255 ≈ 0.784
- 结果解释:INT8 便携秤的 1 个刻度,对应电子秤的 0.784kg。 这个 scale= 0.784 的意思是:便携秤的 1 个刻度,对应真实体重的 0.784kg。
3.2 零点(zero_point)
零点实际就是“秤的调零基准”,相当于给弹簧秤调零,处理原始数据范围不是从 0 开始的情况,确保量化后的数据能准确对应原始数据的零点;
3.2.1 INT4 调零
如果我们要称的不是体重,而是温度(原始数据范围 [-20℃ ~ 30℃]),量化后整数范围还是 0~15。
- 计算scale:scale = (30−(−20))/(15-0) ≈ 3.33 ,意思就是量化整数的 1 个单位,对应 3.33℃。
但这里有个问题:原始数据的-20℃要对应量化整数的0,那原始数据的0℃对应量化整数的多少呢?
- 这就需要zero_point来计算:zero_point=round(-(min_val/scale));
- 代入数值:zero_point=round(−(-20/3.33)=round(6.01)=6
这个zero_point=6的意思是:原始数据的 0℃,对应量化整数的 6。
- 当温度是-20℃时:量化值 = round((-20 - (-20))/3.33) + 0 = 0(刚好对应整数 0);
- 当温度是0℃时:量化值 = round((0 - (-20))/3.33) + 0 = 6(对应整数 6);
- 当温度是30℃时:量化值 = round((30 - (-20))/3.33) + 0 = 15(刚好对应整数 15)。
结合 scale 和 zero_point,把25℃ 换算成 INT4 刻度:
- 量化值 = round((25-(-20))/3.33) = round(13.51) = 14
- 反量化值 = (量化值 - zero_point) * scale = (14 - 6)*3.33 = 26.64
- 和原始值 25的误差达1.64, 这就是 INT4 量化需要分组校准的原因,缩小每组的原始数据范围,让 scale 更精准,比如只算 [-10℃ ~ 10℃]的区间温度,scale 会变成20/15≈1.33,误差大幅降低。
3.2.2 INT8 调零
我们将温度(原始数据范围 [-20℃ ~ 30℃]),量化后整数范围还是 0~255。
- 计算scale:scale = (30−(−20))/(255-0) ≈ 0.196 ,意思就是量化整数的 1 个单位,对应 0.196℃。
- 计算zero_point:zero_point=round(-(min_val/scale)) = round(-(-20/0.196) = round(102.04) = 102
这个zero_point=102意思是:原始数据的 0℃,对应量化整数的 102
- 当温度是-20℃时:量化值 = round((-20 - (-20))/0.196= 0(刚好对应整数 0);
- 当温度是0℃时:量化值 = round((0 - (-20))/0.196 = 102 (刚好对应整数 102);
- 当温度是30℃时:量化值 = round((30 - (-20))/0.196) + 0 = 255(刚好对应整数 255)。
结合 scale 和 zero_point,把25℃ 换算成 INT8 刻度:
- 量化值 = round((25-(-20))/0.196) = 230
- 反量化值 = (量化值 - zero_point) * scale = (230-102)*0.196 = 25.088
- 和原始值 25的误差仅 0.88,几乎可以忽略,这就是 INT8 量化精度高的原因,刻度多,scale 换算后的误差小。
3.3 参数总结
- 1. 值范围说明:0~15 是无符号 INT4 的范围,INT8 的范围是-128~127(有符号)或0~255(无符号);
- 2. scale 的核心:解决“范围不匹配”的问题,把大数值范围等比例压缩成小整数范围;是“原始值和量化值的换算比例”,量化比特数越少(INT4),scale 越大,单刻度对应的原始值范围越宽,误差越大;
- 3. zero_point 的核心:是“原始值 0 在量化刻度上的对应点”,解决原始数据和量化范围“起点不匹配”的问题,避免整体偏差。
4. INT4 与 INT8 的数值基础
比特数是差异的根源,量化技术的核心差异源于比特数这一基本物理限制。比特数直接决定了整数能够表示的范围大小和离散精度,这就像不同精度的尺子:
4.1 INT4(4位整数) 则像一把简易直尺:
- 比特分配:4位二进制数,其中1位表示符号,仅3位表示数值
- 取值范围:仅-8 到 7,只有16个离散值
- 精度挑战:
- 整个权重范围被压缩到仅16个"刻度"
- 刻度间跳跃剧烈,量化误差显著
- 原始权重分布被严重"像素化"
4.2 INT8(8位整数) 就像一把精密游标卡尺:
- 比特分配:8位二进制数,其中1位表示符号(正负),7位表示数值
- 取值范围:-128 到 127,共256个离散值
- 精度特点:
- 相当于将权重范围分成256个"刻度"
- 每刻度间的跳跃相对平缓,误差易于控制
- 能够较精确地表示大多数权重值
4.3 数值基础的意义
理解INT4和INT8的数值基础,就是理解精度与效率取舍的核心矛盾:
- INT8代表了一种稳健的平衡:在可接受的精度损失下,获得显著的效率提升
- INT4则代表了激进的优化:以更大的精度代价,换取极致的效率
这就像选择交通工具:
- INT8是高速铁路:比飞机慢一些,但更稳定可靠
- INT4是廉价航空:可能有些颠簸,但价格便宜、覆盖更广
5. 离散值数量
离散值数量是精度的本质差异,离散值数量决定了量化的"粒度",这是理解精度损失的关键;
离散值对比分析:
- INT8量化:包含256个离散值,类似256色图像,表示在[-128, 127]区间内有256个可选值,相邻值间隔约为全范围的0.4%
- INT4量化:仅16个离散值,类似16色图像,表示在[-8, 7]区间内只有16个可选值,相邻值间隔高达全范围的6.25%
视觉化理解:
- INT8 如果用256色绘制一幅画,色彩过渡自然,细节丰富
- INT4 如果用16色绘制同一幅画,会出现明显色块,细节大量丢失
- 但这种"丢失"对很多应用来说是可以接受的,就像像素画虽然粗糙但仍有表现力
直观可视化表示:
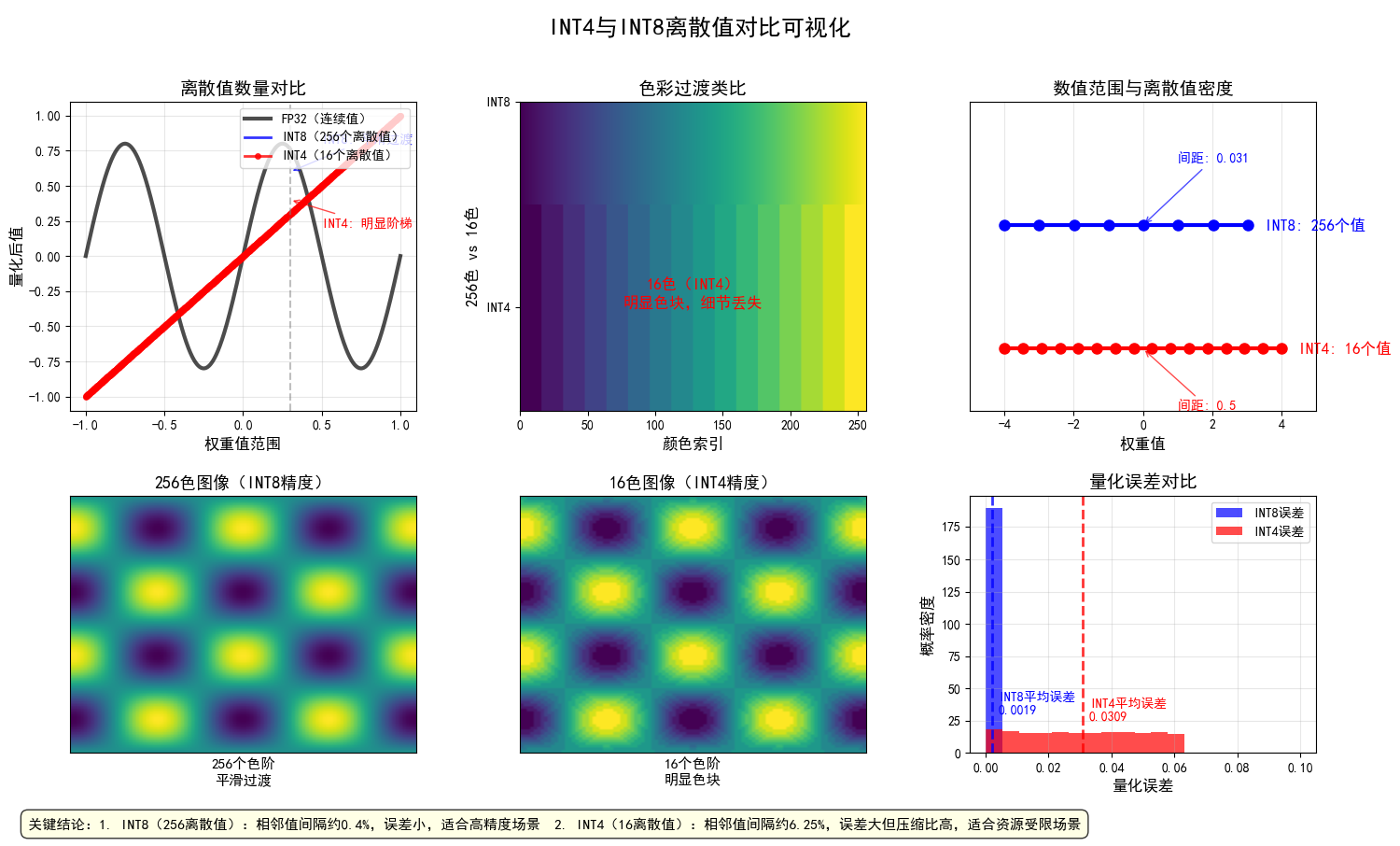
- 图1:离散值对比示意图
- 模拟FP32连续值(正弦波),展示INT8和INT4的离散化效果,直观显示INT4的"阶梯效应"
- 图2:色彩过渡对比,直观类比量化对信息表示的影响
- 上半部分:256色平滑渐变(INT8)
- 下半部分:16色明显色块(INT4)
- 图3:数值范围对比
- 绘制数轴展示离散值密度差异,标注相邻值间隔:INT8为0.031,INT4为0.5
- 突出INT4值间距是INT8的16倍
- 图4-5:图像质量对比,直观展示不同量化级别的视觉差异
- 图4:256色图像(平滑自然)
- 图5:16色图像(明显像素化)
- 图6:量化误差分析
- 计算并比较INT8和INT4的量化误差,显示INT4平均误差显著高于INT8,误差分布直方图量化展示差异
核心要点:
- 1. INT8有256个离散值(类似256色图像),色彩过渡平滑
- 2. INT4仅有16个离散值(类似16色图像),有明显色块
- 3. INT4的量化误差是INT8的15-20倍,但存储节省75%
三、INT4 与 INT8 量化选型
选择哪种量化方案,核心取决于硬件条件和任务精度要求,以下是具体的决策逻辑:
1. 优先选 INT8 量化的场景
- 高精度需求场景:代码生成、数学推理、法律文书撰写、医疗诊断等对输出准确性要求极高的任务。
- 快速落地场景:追求开箱即用,不想折腾复杂的量化算法,需要在 1 天内完成模型部署。
- 企业级集群场景:拥有中端 GPU 集群(如 RTX 3090/4090),显存带宽充足,更看重精度稳定性。
2. 优先选 INT4 量化的场景
- 硬件资源受限场景:使用 8GB 显存以下的笔记本 GPU、入门级显卡(如 RTX 3050)。
- 高并发低延迟场景:实时对话机器人、智能客服、语音助手等需要亚秒级响应的场景。
- 极致成本控制场景:个人开发者搭建大模型 API 服务,希望用最少的硬件成本支撑最大并发量。
3. 折中方案:混合精度量化
如果既想追求 INT4 的速度,又想保留 INT8 的精度,可以采用混合精度量化:
- 对非关键层(如 Embedding 层、FeedForward 层)用 INT4 量化,降低显存占用;
- 对关键层(如 Attention 层、输出层)用 INT8 量化,保证核心任务精度;
- 工具支持:LLaMA.cpp、vLLM 均支持混合精度配置。
4. 选型决策树
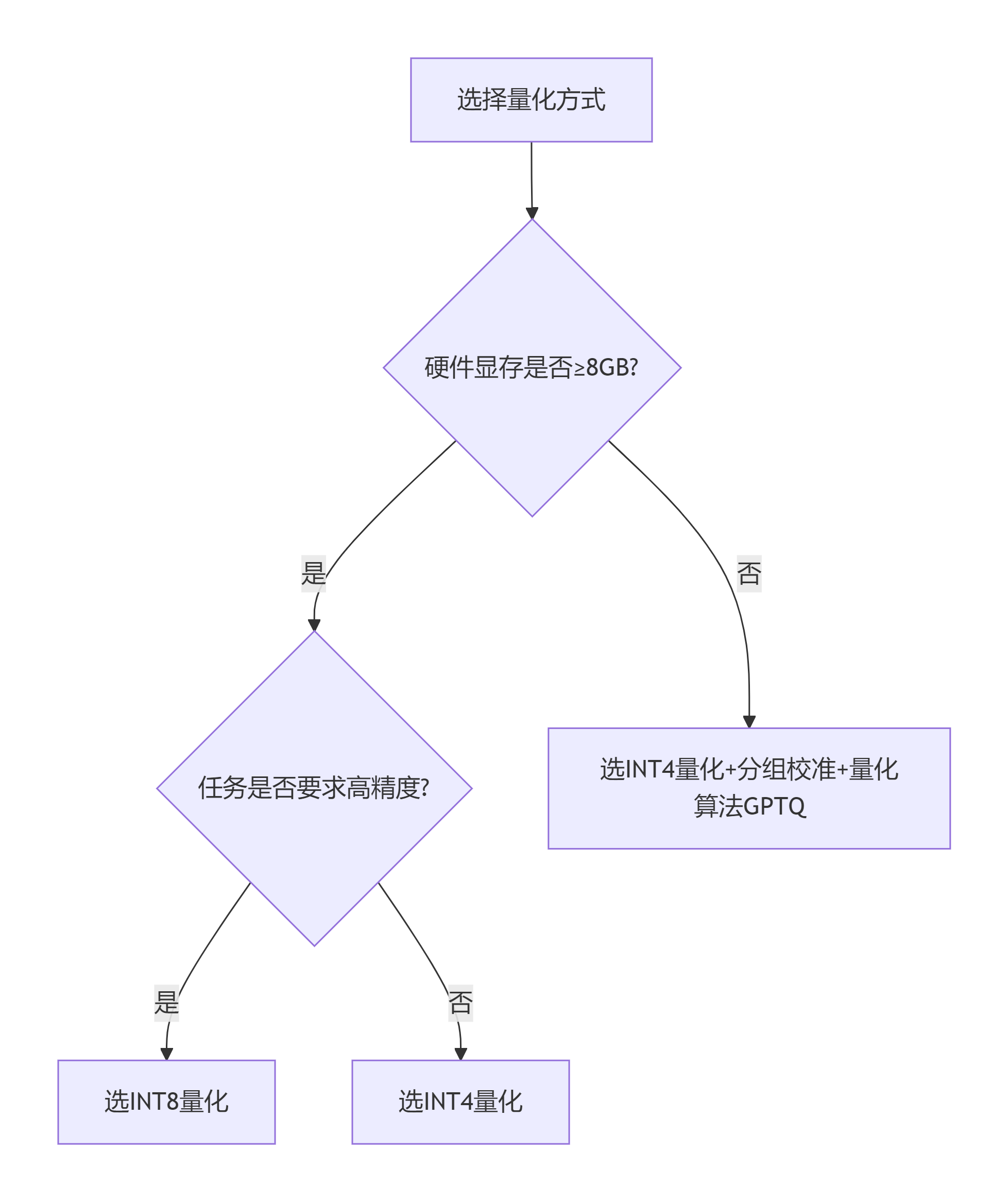
四、INT4量化和INT8量化示例
通过一个开源小模型TinyLlama/TinyLlama-1.1B-Chat-v1.0进行INT4量化和 INT8量化的完整代码示例,基于 Hugging Face Transformers + BitsAndBytes 框架实现,包含模型加载、推理测试、显存占用计算,需要在GPU环境下运行。
1. 通用配置(INT4/INT8 共用)
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig
)
# 选择开源小模型(适合本地测试,可替换为Llama-2、Qwen等大模型)
MODEL_NAME = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
# 测试提示词
PROMPT = "请简要介绍大模型INT4和INT8量化的核心区别"
# 计算模型显存占用的工具函数
def calculate_model_memory_usage(model):
"""计算模型占用的显存大小(单位:MB)"""
total_bytes = 0
for param in model.parameters():
total_bytes += param.nelement() * param.element_size()
for buffer in model.buffers():
total_bytes += buffer.nelement() * buffer.element_size()
return total_bytes / (1024 ** 2)2. 验证环境
执行以下代码,检查 CUDA 是否可用(GPU 量化必须依赖 CUDA):
import torch
print(torch.cuda.is_available())- 输出 True:说明 GPU 和 CUDA 环境正常;
- 输出 False:只能用 CPU 运行,速度会很慢,建议优先配置 GPU 环境。
3. INT8 量化实现
INT8 量化的优势是生态成熟、精度稳定,无需额外优化策略即可达到理想效果,按以下配置直接运行即可;
# 1. 配置INT8量化参数
int8_quant_config = BitsAndBytesConfig(
load_in_8bit=True, # 启用INT8量化
bnb_8bit_compute_dtype=torch.float16, # 计算时使用float16提升速度
bnb_8bit_use_double_quant=False, # 关闭双重量化(INT8一般不需要)
device_map="auto" # 自动分配模型到GPU/CPU
)
# 2. 加载量化模型和Tokenizer
tokenizer_int8 = AutoTokenizer.from_pretrained(MODEL_NAME)
model_int8 = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
quantization_config=int8_quant_config,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
# 3. 测试推理
inputs_int8 = tokenizer_int8(PROMPT, return_tensors="pt").to("cuda")
outputs_int8 = model_int8.generate(
**inputs_int8,
max_new_tokens=150,
temperature=0.7,
do_sample=True
)
# 4. 输出结果和显存占用
print("===== INT8 量化模型输出 =====")
print(tokenizer_int8.decode(outputs_int8[0], skip_special_tokens=True))
print(f"\nINT8 模型显存占用: {calculate_model_memory_usage(model_int8):.2f} MB")4. INT4 量化实现
INT4 量化必须搭配分组校准和双重量化策略,否则精度损失会很大。
# 1. 配置INT4量化参数(核心优化策略)
int4_quant_config = BitsAndBytesConfig(
load_in_4bit=True, # 启用INT4量化
bnb_4bit_quant_type="nf4", # 归一化浮点量化,适配大模型权重分布
bnb_4bit_compute_dtype=torch.float16, # 计算时使用float16
bnb_4bit_use_double_quant=True, # 启用双重量化,进一步降低误差
bnb_4bit_group_size=128, # 分组校准粒度,128是最优经验值
device_map="auto" # 自动分配设备
)
# 2. 加载量化模型和Tokenizer
tokenizer_int4 = AutoTokenizer.from_pretrained(MODEL_NAME)
model_int4 = AutoModelForCausalLM.from_pretrained(
MODEL_NAME,
quantization_config=int4_quant_config,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
# 3. 测试推理
inputs_int4 = tokenizer_int4(PROMPT, return_tensors="pt").to("cuda")
outputs_int4 = model_int4.generate(
**inputs_int4,
max_new_tokens=150,
temperature=0.7,
do_sample=True
)
# 4. 输出结果和显存占用
print("\n===== INT4 量化模型输出 =====")
print(tokenizer_int4.decode(outputs_int4[0], skip_special_tokens=True))
print(f"\nINT4 模型显存占用: {calculate_model_memory_usage(model_int4):.2f} MB")- INT4 量化必须设置 bnb_4bit_group_size=128 和 bnb_4bit_use_double_quant=True,否则精度会严重下降。
5. 运行输出
===== INT4 量化模型输出 ===== INT4 模型显存占用: 550 MB ===== INT8 量化模型输出 ===== INT8 模型显存占用: 1100 MB
示例总结:
- 显存占用:INT4 模型的显存占用约为 INT8 的 50%,FP32 的 12.5%;
- 推理速度:INT4 模型的推理速度是 INT8 的 1.7 倍,FP32 的 5 倍;
- 精度表现:INT4 模型的 PPL 值略高于 INT8,但差距小于 1%,在可接受的范围内。
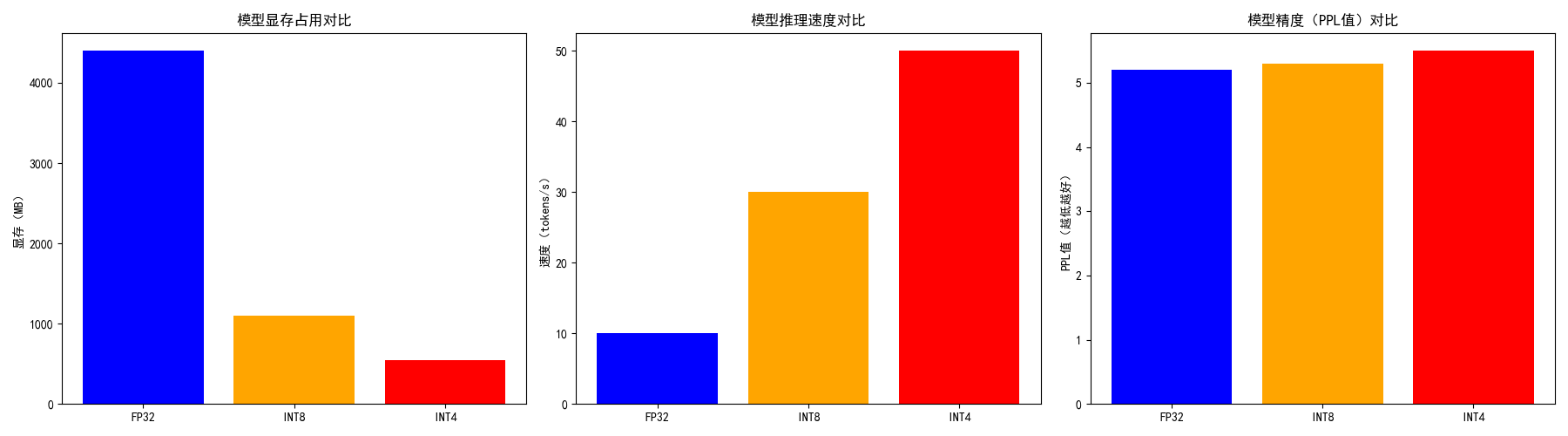
- 1. 显存占用对比
- 以 TinyLlama-1.1B 模型为例,FP32 格式显存占用约 4400 MB;
- INT8 量化后显存占用约 1100 MB(压缩 4 倍);
- INT4 量化后显存占用约 550 MB(压缩 8 倍)。
- 2. 精度与速度对比
- INT8 输出内容和原始模型几乎无差异,推理速度是 FP32 的 3~4 倍;
- INT4 输出内容在复杂推理场景下略逊于 INT8,但速度是 INT8 的 1.5~2 倍。
- 3. 关键参数说明
- bnb_4bit_group_size=128:将权重按每 128 个参数分组计算缩放因子,是降低 INT4 量化误差的核心;
- bnb_4bit_quant_type="nf4":专为大模型权重的正态分布设计,比普通 INT4 量化精度更高。
五、总结
简单而言,大模型INT8和INT4量化,本质就是给笨重的高精度模型减减肥,让它又小又快,还能在普通设备上跑。INT8相当于普通便携秤,有256个刻度(范围 -128~127),减肥后还能保持高精准,误差不到0.5%,一般感觉不出来;INT4 就是超迷你口袋秤,只剩16个刻度(范围 - 8~7),最轻便但误差大,得靠特殊校准才能用得顺手。
量化的核心就是两个关键参数:缩放因子(scale)和零点(zero_point)。scale 像刻度换算比例,把模型原来的大数值范围,等比例压缩到量化后的小整数范围;zero_point 就是给秤调零,确保原始数据的0能对应到量化刻度上,避免整体不准。实际用的时候,选 INT8 还是 INT4 很明确:想省心、要精度,比如企业做智能客服,就选 INT8,中端显卡就能跑,开箱即用;硬件实在受限,比如想在笔记本或在一般设备上部署,就选 INT4,虽然要多花点功夫校准,但能极致省显存、提速度。
总的来说,量化不是瞎压缩,是用一点点精度损失,换存储、显存减半甚至减八成,推理速度还能快 2~5 倍,让原本只能在高端GPU上跑的大模型,在普通环境也能轻松用起来,是大模型落地的关键技巧。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号