Triton 开始


Triton,本文指 OpenAI Triton,先看官方介绍,
Triton is a language and compiler for parallel programming. It aims to provide a Python-based programming environment for productively writing custom DNN compute kernels capable of running at maximal throughput on modern GPU hardware.
Triton 是一个用于并行编程的 Python DSL,也是一个将计算映射到并行硬件的编译器框架。
两个视角,
- 算法研究:使用 Python DSL 快速实现高性能算子,无缝接入 PyTorch 生态
- 编译器开发:为自研 AI 芯片提供编译基础设施,可基于 MLIR 构建完整编译栈
它是一座连接高级算法思想与底层硬件并行性的桥梁,兼顾了生产力、性能与可移植性。
本文聚焦于 AI 编译器开发,想的是怎么把 Triton + MLIR 上手玩起来。
不过在此之前,先聊聊我写这篇文章的初衷。
为什么写 Triton?
我也是初次接触 Triton。那为什么想到写它了呢?
因为目前 AI 编译器的主流方向是 Triton + MLIR,正好打算深入学习一下。
但真要写 Triton,现在又有问题了,怎么写呢?如今问一问 AI 不就好了。
所以,文风与内容,打算稍作变化。啥意思,会多点‘废话’,多唠叨几句,不再简要成手册,这就由 AI 来做吧。
我呢,多谈谈自己的想法:一是让大家感觉更像是在和一个人交流;二是分享个人实践的经验,希望能对大家有所裨益。
GoCoding 定位,让大家了解技术上新的东西,或能引导大家进入新的领域。技术深入跟随会议或社区进展就好。
怎么来学 Triton?
- 官方渠道:不用多说,当然从官方渠道开始。不建议看我这样的二手信息。 那我写文的价值呢?一,对我个人最有用;二,让关注我的人能了解新的技术、发现感兴趣的领域,一起学习。
- AI 辅助:与 AI 聊聊我的目标,看看它建议的学习路径。现在可真方便 ✌️
那我们开始吧!
首先,了解一样东西,我不仅仅会了解它是什么、用做什么。就如文章开头对 Triton 的描述。我一般还会去了解背景:它的由来、发展历程。挖掘得细一点,有时还会发现一些有意思的小故事。
其次,就是对比。为什么是它,它的优势在哪,它在往什么方向发展。也就是了解一下它“到哪里去”的问题。更远的,未来的可能性与不确定性,学习并深入时可能会想一想。
之后,才是学习。笨办法,是我用得比较多的。就是,把一本书或官方教程,全部写一遍、跑一遍。当然,现在 AI 开道,免费导师,可以试试聪明办法了。又想起我自己说过的那句:AI:不懂的人用,则是引导者 😊
现在,就按上述思考,开始吧!
Triton 的发展阶段
发展阶段 | 大致时间 | 核心特征与关键事件 | 技术栈与生态 | 主要目标用户 |
|---|---|---|---|---|
初创与原型 | 2018 - 2021 | 在OpenAI内部诞生,核心是为NVIDIA GPU提供比CUDA更友好的编程抽象。发表了开创性的学术论文。 | 独立的编译器,深度集成于PyTorch。后端主要为CUDA/NVVM。 | AI研究人员、需要编写定制CUDA算子的开发者。 |
成熟与生态扩张 | 2021 - 2023 | 关键转折:基于MLIR重构。从“编译器”变为“编译器框架”,奠定跨硬件基础。前端DSL稳定,社区采用度激增(如FlashAttention)。 | MLIR成为核心中间层。后端扩展至AMD GPU(ROCM)和Intel GPU(OpenCL/SPIR-V)。 | 高性能计算工程师、框架开发者、其他硬件厂商的编译团队。 |
平台化与工业部署 | 2023 - 至今 | 成为自研AI芯片的“上游编译前端”。其Triton IR(MLIR Dialect) 成为连接算法与多种硬件的关键抽象层。 | 基于MLIR的完整编译栈。出现针对不同自研硬件的定制后端。生态与Torch-MLIR等融合。 | AI芯片公司的编译器团队、构建端到端编译基础设施的架构师。 |
Triton 的核心优势
Triton 核心优势:用 Python 写 GPU 算子,基于 MLIR 轻松跨硬件,已是 PyTorch 高性能算子的事实标准前端。
Triton 与 TVM, XLA 的核心差异:
维度 | Triton | TVM | XLA |
|---|---|---|---|
设计哲学 | 算子优先、Python 原生 | 端到端编译、跨平台 | 静态图优化、框架集成 |
编程体验 | Python DSL,算法思维 | 多层 IR,编译思维 | HLO IR,框架约束 |
硬件适配 | MLIR 方言栈,灵活定制 | Relay/TOPI 多层抽象 | LLVM + 专用后端 |
生态定位 | PyTorch 生态的算子加速器 | 多框架通用编译器 | TensorFlow/JAX 专属编译器 |
Triton + MLIR 跨硬件编译架构
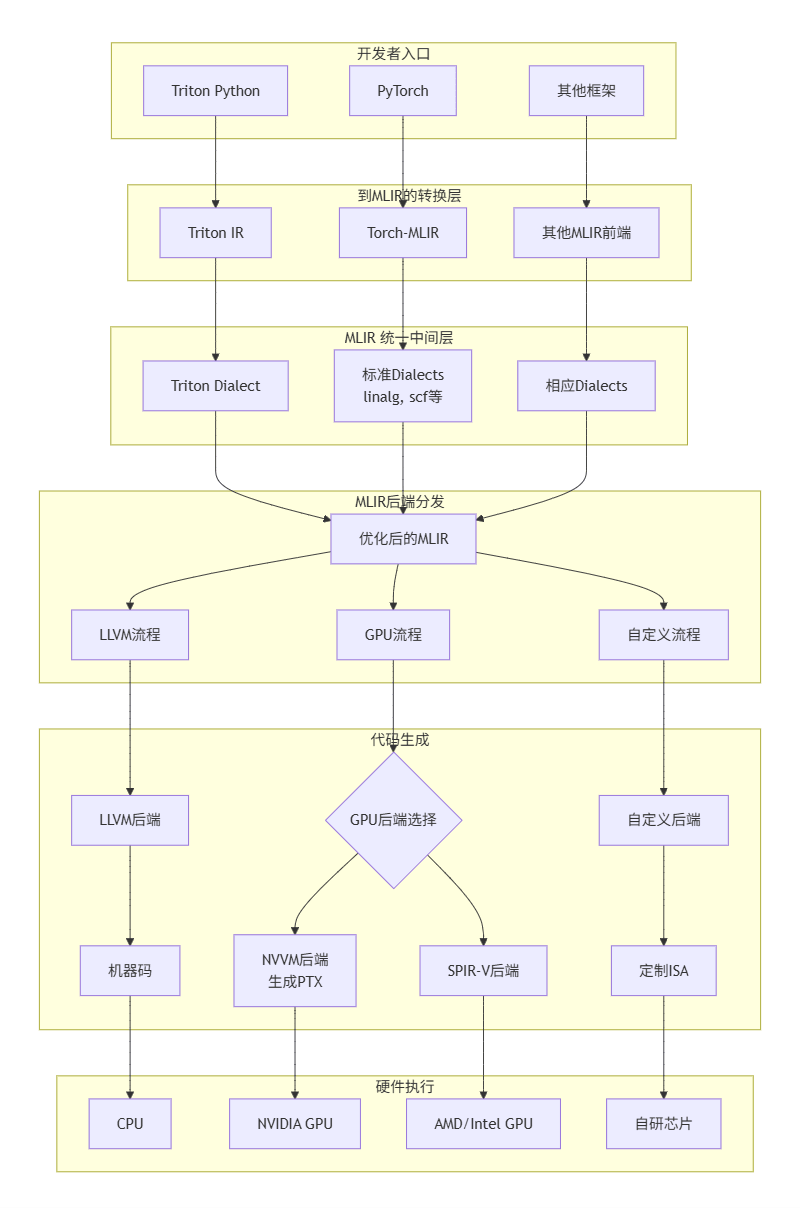
Triton + MLIR 的学习路径
学习路径可以遵循“从用户到开发者,从抽象到具体”的原则,分为四个层次:
层次一:作为算子开发者(用户体验层)
目标:学会使用Triton Python DSL快速实现高性能内核。
- 基础入门
- 阅读Triton官方教程,理解其编程模型(
tl.program_id,tl.arange,tl.load/store)。 - 亲手实现几个经典算子:向量加法、矩阵乘法、Softmax。
- 关键概念:块(Block)、指针运算、掩码(Mask)、原子操作。
- 阅读Triton官方教程,理解其编程模型(
- 进阶掌握
- 学习内存优化技巧:利用
tl.cache,tl.make_block_ptr进行向量化加载/存储,理解不同内存空间(DRAM, L2 Cache, Shared Memory)的差异。 - 学习高级调度:如流水线(Pipeline)和异步复制(
async_copy)。 - 学习如何将Triton内核封装为PyTorch的
torch.autograd.Function,并集成到模型中使用。
- 学习内存优化技巧:利用
- 实践尝试复现或优化一个经典论文中的融合算子(如FlashAttention V1/V2的核心部分)。
层次二:理解编译流程(系统认知层)
目标:理解从Triton Python代码到目标代码的完整编译过程。
- 追踪编译链使用
torch.compile或Triton的JIT功能运行一个简单内核,并学习如何输出其关键中间表示。- 查看Triton IR了解高级Python操作如何被降低为Triton IR操作。
- 查看MLIR理解Triton IR是如何被转换为MLIR中的
Triton,LLVM,NVVM等Dialect的。这是理解其跨硬件能力的关键。
- 学习MLIR基础概念(无需深入,建立认知即可)
- 什么是Dialect、Operation、Attribute、Type。
- MLIR的核心优势:多层中间表示、可重用的转换和优化基础设施。
- 实践使用
TRITON_DUMP_GRAPH=1等环境变量,导出一个内核的编译流程图,对照官方架构图理解每一步。
层次三:探索编译器开发(贡献者/定制者层)
目标:能够为Triton编译器添加新特性或为其定制新硬件后端。
- 深入Triton编译器代码
- 定位关键目录:
python/(DSL),lib/(核心编译器逻辑,C++)。 - 学习从Python AST到Triton IR的生成过程。
- 学习基于MLIR的Pass是如何对Triton Dialect进行优化的。
- 定位关键目录:
- 学习为MLIR添加Pass
- 编写一个简单的MLIR Pass,对Triton Dialect的IR进行模式匹配和重写。
- 后端开发入门(以连接自研芯片为例)
- 路径一(推荐)将Triton Dialect lowering到已有的、更通用的MLIR Dialect(如
Vector,GPU),然后利用社区或自定义的后端从这些Dialect生成代码。 - 路径二(更深入)定义自己的硬件Dialect,并实现从Triton Dialect到该硬件Dialect的转换规则。
- 这需要对MLIR的方言转换框架(Pattern Rewrite, Dialect Conversion)有扎实理解。
- 路径一(推荐)将Triton Dialect lowering到已有的、更通用的MLIR Dialect(如
层次四:架构与集成(系统架构师层)
目标:设计基于Triton+MLIR的完整编译栈,用于产品化部署。
- 性能调优与自动化
- 研究Triton的自动调优器(Auto-Tuner)原理,学习如何为新的硬件特性添加调优空间。
- 探索基于机器学习的内核自动生成与优化。
- 端到端集成
- 研究如何将Triton与模型级编译器(如Torch-MLIR, IREE)结合,实现从PyTorch模型到混合内核(部分由Triton生成)的无缝编译。
- 设计运行时(Runtime)接口,管理自定义硬件上Triton内核的加载、启动和资源分配。
- 紧跟社区关注Triton和MLIR的RFC、会议(如MLIR Open Design Meetings)、论文,把握技术演进方向。
Triton + MLIR 动手开始
学习路径有了,那就动手开始吧。
我根据个人情况,想法是对四个层次竖着切一刀,每一部分都实践一个简单用例,先对整体建立概念,再继续深入了解我关心的部分。
每个人都可以依据自己的兴趣与实际情况去开始,不必非得按部就班地学。
结语
有兴趣的小伙伴,一起来学吧。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号