ICLR 2026 | MedAgent-Pro:用 Agent 工作流模拟临床医生的循证诊断过程
原创
ICLR 2026 | MedAgent-Pro:用 Agent 工作流模拟临床医生的循证诊断过程
原创
CoovallyAIHub
发布于 2026-03-20 14:42:33
发布于 2026-03-20 14:42:33
导读
多模态大模型(MLLM)在医学影像诊断上有一个根本性矛盾:它们能"看"图像、能"说"结论,但做不好临床诊断中最关键的一步——定量分析。测量杯盘比、计算射血分数、评估组织厚度,这些需要精确数值的操作是 MLLM 的短板。更严重的是,MLLM 在推理过程中容易产生幻觉和不一致,这在临床场景中不可接受。
MedAgent-Pro 的思路是不让 MLLM 直接做诊断,而是让它扮演临床医生的角色——先查指南、制定计划、调用专业工具做定量分析、最后综合证据决策。在青光眼和心脏病两个诊断任务上,MedAgent-Pro 的 MOE 决策模式以 90.4% 和 66.8% 的准确率大幅超越通用 MLLM 和专用模型。
论文信息
- 标题:MedAgent-Pro: Towards Evidence-based Multi-modal Medical Diagnosis via Reasoning Agentic Workflow
- 作者:Ziyue Wang, Junde Wu, Linghan Cai, Chang Han Low, Xihong Yang, Qiaxuan Li, Yueming Jin
- 机构:新加坡国立大学(NUS)、牛津大学(University of Oxford)
- 发表:ICLR 2026(arXiv 2503.18968)
- 代码:https://github.com/jinlab-imvr/MedAgent-Pro
一、MLLM 做医学诊断的瓶颈在哪里
论文首先用实验展示了现有 MLLM 在医学诊断上的表现:
模型 | 青光眼 mACC | 青光眼 F1 | 心脏病 mACC | 心脏病 F1 |
|---|---|---|---|---|
LLaVA-Med | 50.0 | 0.0 | 50.0 | 0.0 |
Janus-Pro-7B | 53.4 | 13.3 | 52.3 | 10.7 |
BioMedClip | 58.1 | 21.3 | 47.0 | 37.8 |
LLaVA-Med 和 Janus-Pro-7B 的 F1 接近 0,说明它们基本在随机猜测。即使是专门针对医学的 BioMedClip,准确率也仅略高于 50%。
核心问题在于:临床诊断不是"看一眼图片给个结论",而是一个多步骤、多指标、循证的推理过程。比如青光眼诊断需要测量杯盘比(vCDR)、评估盘沿厚度(RT)、检查视盘周围萎缩(PPA)和盘沿出血(DH),任何单一视觉特征都不足以做出准确判断。
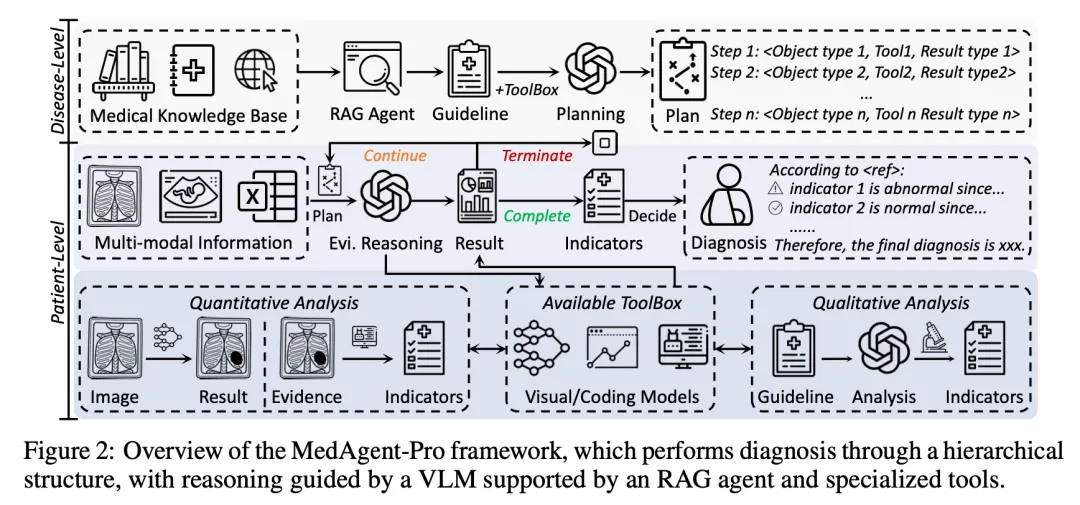
二、MedAgent-Pro 的两层 Agent 架构
MedAgent-Pro 将诊断过程分为任务层和案例层两个层级。
图片
图片来源于原论文
任务层:基于知识的诊断计划生成
对于每种疾病,任务层执行以下流程:
- RAG Agent:从 MedlinePlus 等医学指南库检索该疾病的临床诊断标准
- Planner Agent(GPT-4o):根据检索到的临床标准,生成结构化的诊断计划
诊断计划输出为一组三元组:(对象, 工具, 操作)。例如青光眼的计划可能包括:
- (视盘/视杯, 分割工具, 测量杯盘比)
- (视盘边缘, 分割工具, 评估盘沿厚度)
- (视盘周围区域, VQA 工具, 检查萎缩征象)
- (眼底图像, 分类工具, 检测盘沿出血)
这一层的关键价值是:诊断计划来自临床指南,而非模型自己编造。
案例层:针对单个患者的循证执行
对每个具体患者的影像,案例层按计划逐步执行:
- Orchestrator Agent:分析患者数据,选择诊断计划中的相关步骤
- Tool Agents:调用专业医学工具(分割、定位、VQA 模型)处理影像
- Coding Agent:将工具输出转化为定量指标(如杯盘比的具体数值)
- Summary Agent:汇总各项指标的分析结果
- Decider Agent:综合证据做出最终诊断
在代码实现中,工具接口统一为 Function(image_path, save_dir, save_name),方便接入不同的医学影像分析工具。
三、两种决策模式:LLM vs MOE
MedAgent-Pro 提供两种最终决策方式:
LLM Decider:由 GPT-4o 直接综合各项指标做出诊断判断。
MOE(Mixture-of-Experts)Decider:用加权评分公式做决策:
其中 取值为 1(异常)、0.5(不确定)或 0(正常),为各指标权重。当 时判定为患病。
实验结果表明 MOE Decider 在两个任务上大幅优于 LLM Decider:
决策模式 | 青光眼 mACC | 青光眼 F1 | 心脏病 mACC | 心脏病 F1 |
|---|---|---|---|---|
MedAgent-Pro (LLM) | 75.9 | 44.8 | 63.8 | 44.1 |
MedAgent-Pro (MOE) | 90.4 | 76.4 | 66.8 | 52.6 |
MOE 在青光眼上比 LLM 高 14.5% mACC,说明结构化的加权决策比让 LLM 自由推理更可靠——LLM 在综合多指标时容易受干扰或产生不一致的推理。
四、与专用模型的对比
在青光眼诊断上,MedAgent-Pro 不仅超越了通用 MLLM,还超越了专门的任务特定模型:
方法 | AUC | mACC | F1 |
|---|---|---|---|
VUNO EYE TEAM(REFUGE2 排名第 1) | 88.3 | — | — |
MIG(排名第 2) | 87.6 | — | — |
MAI(排名第 3) | 86.1 | — | — |
RetiZero | — | 50.8 | 18.4 |
VisionUnite | — | 85.8 | 73.1 |
MedAgent-Pro (MOE) | 95.1 | 90.4 | 76.4 |
MedAgent-Pro 的 AUC 达到 95.1,超越 REFUGE2 挑战赛排名第一的方案(88.3)6.8 个点。
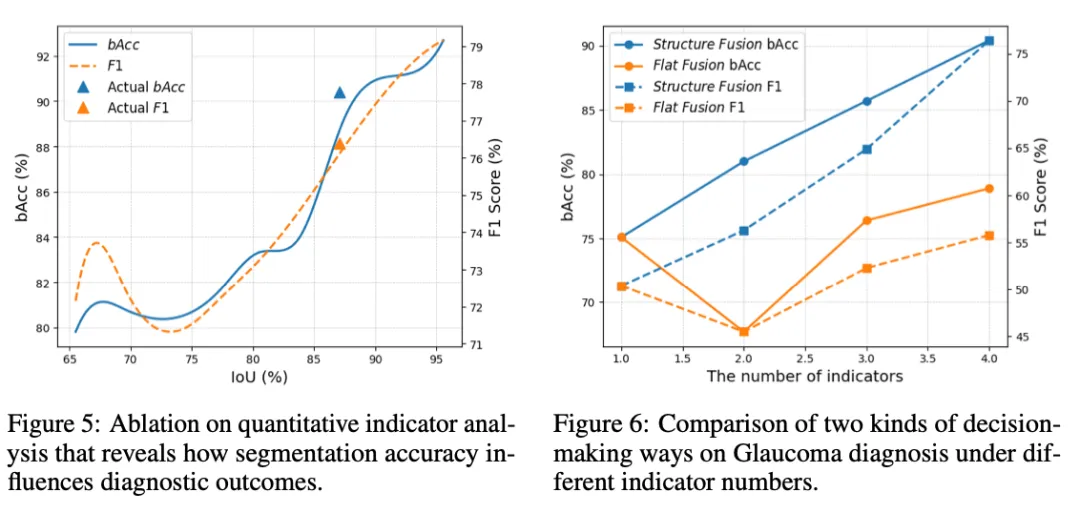
五、消融实验:指标组合与补偿效应
青光眼诊断中 4 个指标的单独表现:
指标 | mACC | F1 |
|---|---|---|
vCDR(杯盘比) | 81.7 | 65.9 |
RT(盘沿厚度) | 70.8 | 31.3 |
PPA(视盘周围萎缩) | 81.0 | 74.6 |
DH(盘沿出血) | 66.8 | 29.6 |
多指标组合(MOE Decider):
指标组合 | mACC | F1 |
|---|---|---|
vCDR + RT | 87.0 | 55.0 |
vCDR + PPA | 93.8 | 78.7 |
vCDR + RT + PPA | 90.1 | 81.5 |
四项全用 | 90.4 | 76.4 |
值得注意的是,vCDR + PPA 的组合(93.8%)甚至略高于四项全用(90.4%),说明增加更多指标不一定带来提升——指标间的权重平衡很重要。
另一个关键发现:当 LLM Decider 缺少 vCDR 这个核心指标时(用 RT + PPA),F1 骤降至 14.3%。这说明 LLM 在关键指标缺失时的鲁棒性较弱,而 MOE 的加权机制能更好地处理指标间的补偿关系。
图片
图片来源于原论文
六、总结与思考
MedAgent-Pro 的核心价值不在于某个模块的性能,而在于将临床诊断的循证流程工程化为 Agent 工作流:查指南 → 制计划 → 用工具 → 出数据 → 做决策。这种设计使得诊断过程可解释、可审计、可扩展到新的疾病类型(只需新增工具和指南)。
值得关注的设计选择:
- MOE Decider 优于 LLM Decider,说明在需要精确综合多指标的场景下,结构化的决策规则比端到端 LLM 推理更可靠
- 诊断计划来自 RAG 检索的临床指南,而非模型自己生成,降低了幻觉风险
- 工具接口标准化(统一输入输出格式),方便扩展新工具
当前局限:
- 仅验证了青光眼(2D 眼底图像)和心脏病(3D 超声心动图)两个疾病,更多疾病类型的泛化能力有待验证
- 心脏病任务的准确率(66.8%)相比青光眼(90.4%)低不少,3D 影像分析仍有挑战
- 依赖 GPT-4o 作为 Planner 和 LLM Decider,本地部署受限
- 代码仓库规模较小(123 stars),社区生态处于早期
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号