OpenClaw 为什么总“失忆”?双层记忆 + 三层防御,让它真正记住你

OpenClaw 为什么总“失忆”?双层记忆 + 三层防御,让它真正记住你

技术人生黄勇
发布于 2026-03-20 10:59:22
发布于 2026-03-20 10:59:22
很多朋友在使用 OpenClaw 会遇到失忆的问题,询问为什么我的小龙虾记不住我,一件事前天说过,昨天说过,今天还是忘记,但是每次它都信誓旦旦的跟我说:记住了。
这种事不是孤例子,之前有过例子,有人告诉她的 OpenClaw:"检查这个收件箱,提供归档或删除建议。在我发话之前不要做任何事。",在测试收件箱上正常工作了几个星期。
但当她告诉 OpenClaw 去处理真正的收件箱(包含数千条消息)时,小龙虾开始删除电子邮件,并忽略了她的停止命令。
原因就是对话上下文窗口被填满了,Agent 压缩了历史记录,而那个"在我发话之前不要做任何事"的指令——只是在聊天中,从未保存到文件中,从上下文中消失了。
要想了解这个问题的来龙去脉,就得先了解 OpenClaw 设计的双层记忆系统。
然后再听听 OpenClaw 代码库的维护者给出的调整建议,最大限度避免你的小龙虾的“遗忘症”。
二、记忆系统的存储架构
OpenClaw 的记忆系统采用了双层记忆架构设计,将记忆整体分为两类:每日日志(动态记忆)和长期记忆(静态记忆)。
记忆类型 | 存储格式 | 存储路径 | 产生方式 |
|---|---|---|---|
静态记忆 | Markdown | ~/.openclaw/workspace/MEMORY.md 和 memory/*.md | 手动创建 + 自动生成 |
动态记忆 | JSONL | ~/.openclaw/agents/{agentId}/sessions/*.jsonl | 自动记录 |
这种设计架构非常符合人类大脑的记忆机制。
人的记忆也是由一个个重点片段组成的,我们能记住的也只是某个特定的时刻、某件具体的事件。
把这些片段串联起来才形成了人类所谓的记忆,至于每天发生的琐事,终究会随着时间而被淡忘。
图片
因此,此种记忆机制也可以说是实现了工程学的最大程度仿生。
2.1. 对话内容产生动态记忆
每次用户与 Agent 交互时,系统会自动将对话内容追加到 JSONL 格式的会话日志文件中,这是最原始的、未经处理过的记忆。动态记忆的 JSONL 格式示例如下:
{
"type": "message",
"message": {
"role": "user",
"content": "帮我写一个 Python 爬虫"
}
}
{
"type": "message",
"message": {
"role": "assistant",
"content": "好的,我来帮你写..."
}
}2.2. 静态记忆的产生
静态记忆是整个系统的长期记忆,用于存储在长期对话中提炼出来的需要系统重点记住的内容,比如用户的性格、回答偏好、项目的约定等。
静态记忆的产生途径分为以下三种:
- • 途径一:用户手动创建:用户可以直接编辑 MEMORY.md 文件,写入需要 Agent 长期记住的信息,比如:"你要称呼我为老板"、"我喜欢简洁的回复"等。
- • 途径二:session-memory Hook 自动转换:当用户执行 /new 命令重置会话时,系统会触发 session-memory Hook,自动将上一个会话的关键内容转换为 Markdown 文件。大致流程为:
-
- 1. 读取会话日志:从 JSONL 文件中提取最近 N 条(默认 15 条)user/assistant 消息
- 2. 生成语义化文件名:使用 LLM 根据对话内容生成描述性 slug(如 api-design、bug-fix)
- 3. 写入 Markdown 文件:生成 memory/YYYY-MM-DD-{slug}.md 文件
- • 途径三:Memory Flush 自动写入:当会话上下文接近 token 限制时,系统会在压缩(compaction)前触发一个特殊的 Agent 回合,在该回合中,Agent 被明确指示:将需要持久保存的重要信息写入 memory/YYYY-MM-DD.md 文件。
特性 | MEMORY.md | memory/*.md |
|---|---|---|
用途 | 核心长期记忆 | 按时间组织的会话记忆 |
内容类型 | 用户偏好、重要信息、工作流程等 | 具体会话的摘要和细节 |
更新方式 | 用户手动维护为主 | 系统自动生成为主 |
命名规则 | 固定为 MEMORY.md | YYYY-MM-DD(-{slug}).md |
检索优先级 | 平等,由向量相似度决定 | 平等,由向量相似度决定 |
整个静态记忆系统的设计核心在于途径三,往往"健忘"的问题就出在这一步,即如何进行历史对话信息的压缩。
OpenClaw 的处理方法是使用 LLM 直接对历史对话信息进行处理:
首先,通过 Memory Flush 进行一次记忆筛选,让 Agent 自己判断什么是"durable memories"(持久记忆);
然后,通过 LLM 对历史消息进行有损摘要,默认只要求保留 "decisions, TODOs, open questions, constraints",不保留具体数值、时间点等细节。
这是 OpenClaw 在记忆上的平衡,通过把历史会话记录(JSONL 格式)压缩成记忆(Markdown 格式),来避免上下文溢出的问题,赋予系统记忆的能力。
但与此同时带来的问题也显而易见,在进行压缩时难免会有信息的流失,这在大多数场景下是合理的,但对于"具体几点"这类精确信息确实是弱点。
但这不是 bug,而是在"长期记忆完整性"和"系统效率/成本"之间的设计取舍。
用户如果有重要的精确信息,可以主动要求 Agent 记录到长期记忆中。
这个设计使得LLM是否足够“聪明”变得很重要,在实际使用中 OpenClaw 就不把我认为需要记忆、重要的信息保留下来。
个人觉得这是在目前阶段能找到的最优解决方案了,有一定作用,成本也不至于太高。
三、记忆信息的检索与调用
当产生并保存一个记忆文件(.md)时,后台会自动触发索引构建流程,并在需要时进行检索。
3.1. 索引构建
默认情况下,只有 Markdown 文件会被索引,而 JSONL 会话日志不会被索引。
Markdown 文件首先被分块,而后每个块同时生成向量 Embedding和文本 Token,分别存入 sqlite-vec 和 FTS5 索引。
这两个都是 SQLite 扩展,意味着整个系统只依赖一个轻量级数据库文件,不需要部署 ES 或者 Milvus。
3.2. 记忆搜索
OpenClaw 采用关键词 + 向量的混合加权搜索,结合了两者的优势:
- • 向量搜索:基于语义相似度,通过计算余弦相似度找到意思相近的内容
- • BM25 关键词搜索:基于词频统计,使用 SQLite 内置的 FTS5 全文检索引擎找到包含精确关键词的内容
两个引擎的搜索结果按照 70:30 的权重(权重比例来自经验数据)合并,最终得分 = 0.7 × 向量相似度 + 0.3 × BM25 得分,且只有得分超过 0.35 的结果才会被返回。
3.3. Agent 如何查找记忆
OpenClaw 通过两个核心工具实现与记忆系统的交互:
memory_search:语义搜索
该工具用来调用记忆检索功能,可搜索 MEMORY.md 和 memory/*.md 文件,返回相关度排序的记忆片段,包含路径、行号和得分。
返回格式示例:
{
"results": [
{
"path": "memory/2026-01-10.md",
"startLine": 15,
"endLine": 20,
"score": 0.85,
"snippet": "用户提到喜欢蓝色,特别是天空蓝...",
"source": "memory"
},
{
"path": "MEMORY.md",
"startLine": 5,
"endLine": 8,
"score": 0.72,
"snippet": "颜色偏好:蓝色系...",
"source": "memory"
}
],
"provider": "openai",
"model": "text-embedding-3-small"
}memory_get:精确读取
此工具用来精准读取记忆文件,可按文件和行范围进行定向读取,返回指定文件片段的完整内容。
返回格式示例:
{
"text": "用户提到喜欢蓝色,特别是天空蓝。\n\n在选择UI时偏好冷色调。\n\n...",
"path": "memory/2026-01-10.md"
}3.4. Agent 什么情况下搜索记忆
Agent 被明确指示必须在特定场景下使用记忆工具:在回答有关过去工作、决策、日期、人物、偏好或待办事项的问题之前,必须先运行 memory_search 搜索 MEMORY.md 和 memory/*.md 文件,然后使用 memory_get 提取所需的行。
3.5. Agent 主动写入记忆
在 OpenClaw 的交互中,Agent 也可以主动写入记忆文件,使用标准的文件操作工具。比如,当 Agent 判断需要记住某些信息时,会使用 exec 或 write 工具写入对应的 memory/YYYY-MM-DD.md 文件。
3.6. 交互的安全边界
为了保证整个系统的安全边界,对 memory_get 制定了严格的路径限制,规定其只能读取到特定位置的文件:
- • MEMORY.md / memory.md
- • memory/*.md
- • 配置的 extraPaths 中的 .md 文件
四、优缺点
通过双层记忆架构,实现了从"无状态工具"到"有记忆伙伴"的进化。
它将记忆从上下文中剥离出来,构建了一个分层的、可搜索的、持久化的知识管理架构,使得 Agent 能够不间断地积累知识、记住用户偏好、延续历史上下文。
这种设计不仅解决了上下文窗口有限的问题,还为 AI 助手提供了更接近人类记忆的工作方式,使得 Agent 能够在长期交互中保持一致性和连续性,真正成为用户的可靠伙伴。
但也还存在很多问题无法解决。
比如:固定开销无法消除(System Prompt)、工具定义每次都要发送、压缩是惰性的、记忆检索是增量成本、工具调用有额外成本。
记忆层的真正价值不是"降低单次成本",而是:使无限长的对话成为可能(没有记忆层,上下文会爆炸),同时保持相关信息的可访问性(压缩后仍可通过搜索找回)。
五、如何最大限度避免
只要在以下三个方面做些调整,你就能领先于 95% 的 OpenClaw 用户:
- 1. 将持久有效的规则放在文件中,而不是在聊天中提供。你的 MEMORY.md 和 AGENTS.md 文件不受压缩操作影响,但在对话中输入的指令无法保证。
- 2. 检查记忆刷新是否启用以及是否有足够的缓冲区触发。OpenClaw 有一个内置的安全网,用于在进行压缩操作之前保存上下文,但大多数人从未检查过它是否在运行或给它足够的空间触发。
- 3. 强制检索记忆。在 AGENTS.md 中添加一条规则:"在行动前搜索记忆"。没有它,Agent就会猜测而不是检查它的记录。
当 Agent "忘记"某件事时,不外乎是发生了以下三件事之一:

三种失效模式——从未存放(最常见)、压实丢失、修剪损坏
原因一:"从未被存储"
- • 原因:指令只存在于对话中,从未被写入文件
- • 结果:当压缩被触发或开启新会话时,它便消失了
- • 典型案例:Meta 对齐总监 Summer Yue 的邮件删除事故
- • 这是最常见的原因
原因二:"压缩操作改变了上下文内容"
- • 原因:长时间会话触发令牌限制,压缩操作对旧消息进行归纳处理
- • 结果:摘要存在信息损耗,丢失细节、一些微妙差别和特定的约束条件
- • 影响:Agent现在根据归纳结果运行,而非你最初提供的指令
原因三:"会话修剪了工具结果"
- • 原因:为优化缓存,会话会修剪旧工具结果
- • 结果:Agent"忘记"了工具之前返回的内容
- • 特点:临时性,磁盘上的记录没有变化,但模型无法看到工具先前响应这个请求的输出
快速判断:
- • 忘记了偏好设置?可能从未写入 MEMORY.md (原因一)
- • 忘记了工具返回的内容?可能是修剪(原因三)
- • 忘记了整个对话?压缩或会话重置(原因二)
5.1. 压缩与修剪
大多数用户都混淆了压缩和修剪,它们是完全不同的系统:

压缩操作会重写历史记录(有损、永久性),而修剪操作只会修剪工具处理结果(无损、临时性)。
压缩
- • 将整个对话历史总结为一段紧凑的摘要,改变了模型未来会看到的内容
- • 当上下文窗口被填满时触发
- • 影响一切:用户消息、助手消息、工具调用
- • 反应性的,当溢出即将发生时触发,而不是提前
- • 有损的,永久性的
修剪
- • 仅在内存中修剪旧工具结果,仅针对单个请求
- • 磁盘上的会话历史记录未受影响
- • 只影响 toolResult 消息;用户和助手消息不会被修改
- • 不会触及工具结果中的图像
- • 无损的,临时性的
修剪是朋友,它能减少膨胀,而且不会破坏对话上下文。
压缩是危险的,因为它会改变模型看到的内容。
建议启用 cache-ttl 模式:每5分钟从上下文中删除旧的或不再需要的信息,以保持上下文的简洁和相关性。
{
"agents": {
"defaults": {
"contextPruning": {
"mode": "cache-ttl",
"ttl": "5m"
}
}
}
}5.2. 核查你的Agent的上下文包含了什么
在做配置的改动之前,建议在 OpenClaw 会话中运行 /context list。
用于查看 OpenClaw 当前会话的上下文信息,即模型"看到"的内容。
🧠 Context breakdown
Workspace: /path/to/workspace
Bootstrap max/file: 20,000 chars
Sandbox: mode=non-main sandboxed=false
System prompt (run): 38,412 chars (~9,603 tok) (Project Context 23,901 chars (~5,976 tok))
Injected workspace files:
- AGENTS.md: OK | raw 1,742 chars (~436 tok) | injected 1,742 chars (~436 tok)
- TOOLS.md: TRUNCATED | raw 54,210 chars (~13,553 tok) | injected 20,962 chars (~5,241 tok)
Skills list (system prompt text): 2,184 chars (~546 tok) (12 skills)
Skills: frontend-design, oracle, …
Tools: read, edit, write, exec, process, browser, …
Tool list (system prompt text): 1,032 chars (~258 tok)
Tool schemas (JSON): 31,988 chars (~7,997 tok)
Session tokens (cached): 14,250 total / ctx=32,000需要检查的内容:
- • MEMORY.md 是否加载? 如果显示"缺失"或未列出,就表示该文件不在上下文中
- • 是否有什么东西被截断? 超过 2 万个字符的文件会按文件截断。所有引导文件的总字符数最多为 15 万个字符
- • 注入的字符是否和原始字符一样? 如果不是,说明内容被截断
如果文件被截断,则调整配置中的字符数限制。
每个文件的字符数限制为 bootstrapMaxChars(默认 20000)。总字符数限制为 bootstrapTotalMaxChars(默认 150000)。
5.3. 压缩实际做了什么
压缩生命周期
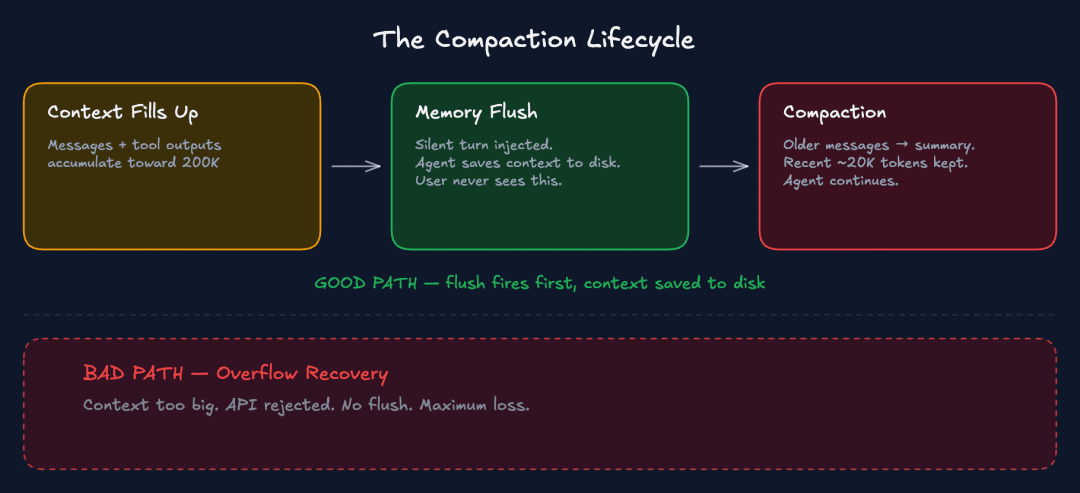
压缩生命周期图,展示了良好路径(首先执行冲洗操作)与不良路径(溢出恢复,最大损失)的对比。
随着上下文信息不断增加,工具输出也越来越多,最终接近阈值。接下来会发生什么呢?
最佳方案:维护性压缩。上下文即将达到极限。
压缩前的内存刷新首先生效。Agent程序会在压缩开始前自动将重要的上下文保存到磁盘,用户不会察觉到这一过程。
然后,压缩程序会汇总较早的对话历史记录。Agent程序会继续处理汇总后的内容,包括最近的消息以及磁盘上的所有内容。
错误发生:溢出恢复。上下文过大,API 拒绝了请求。
现在 OpenClaw 正在进行补救措施。它一次性压缩所有内容,只是为了恢复工作。
没有进行内存刷新,也没有先将重要数据保存到磁盘。导致上下文丢失最大。
5.4. 压缩破坏了什么
不会在压缩操作中保留的内容:
- • 嵌入在对话中的指令(头号杀手)
- • 在会话中给出的偏好、更正和决策
- • 压缩操作前共享的所有图像
- • 工具结果和它们的上下文
- • 原指令的一些细微之处和特异性(摘要存在信息损耗)
会在压缩操作中保留的内容:
- • 所有工作区文件:SOUL.md、AGENTS.md、USER.md、MEMORY.md、TOOLS.md
- • 每日记忆日志(通过搜索按需获取,不重新注入)
- • Agent在压缩操作发生前写入磁盘的任何内容
关于 OpenClaw 的记忆,最重要的原则是:
如果没有写入文件,就不存在。
六、三层防御机制
单靠任何一种机制都不够,你需要三者协同运作:
第一层:压缩前记忆刷新
这是你可以做出的最有用的配置更改。OpenClaw 内置了压缩前记忆刷新功能,在压缩前会触发一个静默的"Agent轮次",提醒模型将任何重要的内容写入磁盘。
推荐配置:
{
"agents": {
"defaults": {
"compaction": {
"reserveTokensFloor": 40000,
"memoryFlush": {
"enabled":true,
"softThresholdTokens": 4000,
"systemPrompt": "Session nearing compaction. Store durable memories now.",
"prompt": "Write any lasting notes to memory/YYYY-MM-DD.md; reply with NO_REPLY if nothing to store."
}
}
}
}
}- • reserveTokensFloor: 40000:为记忆刷新轮次和压缩摘要保留足够的空间
- • memoryFlush.enabled: true:确保刷新功能已启用
- • softThresholdTokens: 4000:距离预留底限多远时触发刷新
第二层:手动记忆管理
虽然有自动刷新机制,但经验丰富的 OpenClaw 用户会通过手动保存来补充这一机制。
在切换任务、给出复杂新指令或做出重要决定时,告诉Agent:
将此保存到 MEMORY.md或:
将今天的关键决定写入记忆文件/compact 命令:从上面介绍看下来,大多数人会认为压缩应该避免,其实不然,它可以按你的需求进行。

/compact 指令的计时技巧——先进行压缩,然后再添加新指令以获得最大运行时间,而不是反过来。
掌握这个命令的诀窍在于:
- 1. 告诉Agent将当前上下文保存到记忆文件
- 2. 发送
/compact手动触发压缩 - 3. 然后给出新指令
新指令会进入压缩后的全新上下文,从而拥有最长的生命周期。它们不会在下次压缩时首先被删除。
为什么需要手动和自动两种方式?
自动刷新会在达到令牌阈值时触发,它是基于时间而非相关性的。
而手动保存则是基于相关性的:你知道何时发生了重要事件。
两者结合起来可以满足这两种需求。
你也可以告诉 Agent 压缩时的优先考虑事项:
/compact 关注决策与开放性问题 第三层:文件架构
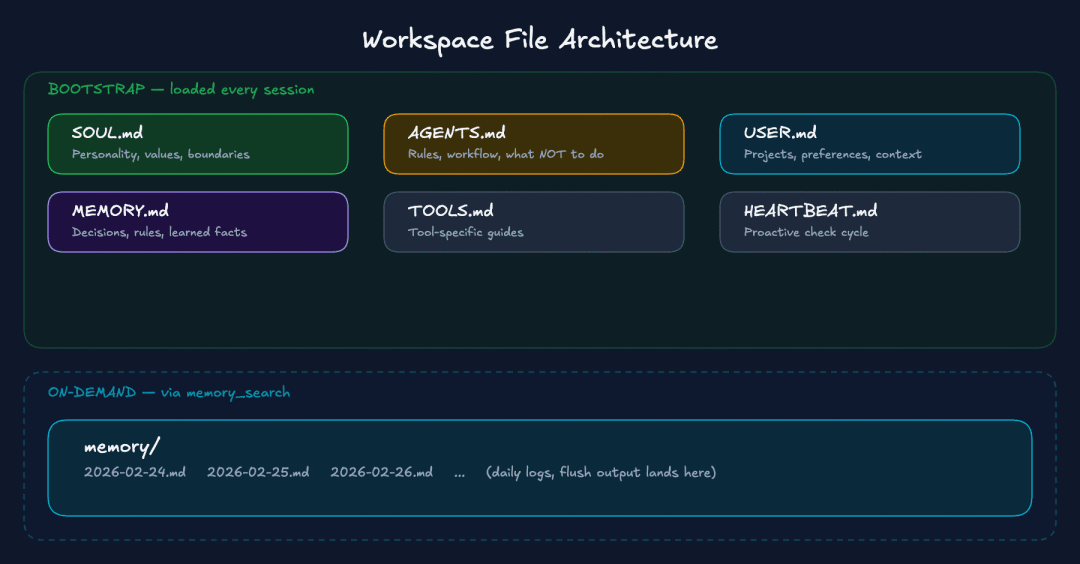
工作区文件架构——引导文件在每个会话中加载,按需内存文件通过 memory_search 访问。
工作区分为两类:
引导文件
(SOUL.md, AGENTS.md, USER.md, IDENTITY.md, TOOLS.md, MEMORY.md, HEARTBEAT.md, BOOTSTRAP.md)在每个会话开始时加载到上下文中。压缩对它们没有影响,因为它们在每个轮次中都从磁盘重新加载。
记忆目录
包含每日日志(memory/YYYY-MM-DD.md)。这些文件并非是通过引导程序注入的,而是通过 memory_search/memory_get 按需调用。
各文件的作用:
- • SOUL.md:说明Agent是谁(沟通语气、个性、情感风格,道德界限以及Agent与你的关系)
- • AGENTS.md:说明Agent如何操作(工作流规则和决策框架、工具使用约定以及响应长度指南)
- • USER.md:你是谁(你的项目、客户、当前优先事项、沟通偏好、关键人物和关系、技术环境细节)
- • MEMORY.md:在每次会话中都应保持不变的内容(你做出的决策及依据、Agent学到的偏好、从过去错误中学到的规则)
- • 每日日志(memory/YYYY-MM-DD.md):你每天工作的上下文(今天发生了什么、对话中做出的决策、活跃任务及其状态)
将以下记忆协议添加到你的 AGENTS.md 中:
## 记忆协议
- 在回答有关过去工作的问题之前:先搜索记忆
- 在开始任何新任务之前:检查今天的记忆以获取活跃上下文
- 当你学到重要的东西时:立即将其写入相应的文件
- 当你纠正一个错误时:将更正作为规则添加到 MEMORY.md
- 当会话结束或上下文很大时:总结并写入 memory/YYYY-MM-DD.md七、检索
如果Agent无法在记忆文件中找到需要的信息,那么记忆文件就毫无用处。
两个记忆访问工具
- • memory_search:在记忆文件中搜索,包括 MEMORY.md、每日日志、记忆目录中的所有内容。默认情况下,它使用关键词和基于语义的匹配。
- • memory_get:按文件和行范围进行定向读取。如果文件不存在,则优雅地返回空文本。
将这个检索协议添加到你的 AGENTS.md 文件中:
## 检索协议
在进行重要的工作之前:
1. memory_search 项目/主题/用户偏好
2. 如果需要,用 memory_get 获取引用的文件块
3. 然后继续执行任务搜索路径的选择
方案一:内置搜索
默认设置,最简单。内置系统自动索引 MEMORY.md 文件和记忆目录中的所有内容,使用混合搜索(关键词 + 语义)。
方案一增强 路径:extraPaths
内置搜索支持索引工作区之外的其他 Markdown 文件,无需额外安装。
{
"agents": {
"defaults": {
"memorySearch": {
"enabled":true,
"provider": "local",
"extraPaths": [
"~/Documents/Obsidian/ProjectNotes/**/*.md",
"~/Documents/specs/**/*.md"
]
}
}
}
}当您需要搜索大型存储库(数千个文件)、过去的会议记录或多个独立集合时,请升级到方案二。
方案二:QMD
QMD(查询 Markdown 文档)是一个实验性的记忆后端,可以取代内置的索引器,用于搜索工作区之外的内容,例如 Obsidian 库、项目文档、会议记录、过去的会话记录。
{
"memory": {
"backend": "qmd",
"qmd": {
"searchMode": "search",
"includeDefaultMemory":true,
"sessions": {
"enabled":true
},
"paths": [
{ "name": "obsidian", "path": "~/Documents/Obsidian", "pattern": "**/*.md" }
]
}
}
}八、故障排除
"我的Agent不记得我的偏好"
偏好是否写入了 MEMORY.md 文件?如果它只存在于对话中,就不是持久的。运行 /context list 看看 MEMORY.md 是否真的加载了?
"memory_search 无返回或似乎被禁用"
运行 /context list 并检查你的记忆文件实际是否存在。如果文件不存在,则意味着没有东西可供搜索。
"它不记得浏览器或工具说了什么"
那是会话修剪,不是压缩。工具结果在缓存 TTL 后被清除。将重要的工具输出写入记忆文件,或重新运行工具。
"压缩发生得太晚,我收到了溢出错误"
不要等到溢出。在事情变得严重之前主动使用 /compact 进行压缩。如果卡在溢出死锁中,使用 /new 重置,或通过 openclaw sessions CLI 恢复。
"压缩前内存刷新没有运行"
如果一个轮次导致 Token 数据大幅越过软阈值,就会绕过刷新。检查你的配置,看看该功能是否启用。
"我的Agent在长时间会话后忘记了它的工具"
已知问题,尤其是长时间运行的 Discord / 飞书会话。使用 /new 重置会话,Agent可以从中断处继续进行。
"我的Agent一夜之间忘记了一切"
会话在每日重置时获得新的会话 ID(默认为当地时间凌晨 4:00)。这本质上是一个新的会话,只有引导文件和可搜索的记忆会延续。
完整配置
方案一:内置记忆搜索
无需额外安装,使用 embeddinggemma 模型的本地混合搜索:
{
"agents": {
"defaults": {
"compaction": {
"reserveTokensFloor": 40000,
"memoryFlush": {
"enabled":true,
"softThresholdTokens": 4000,
"systemPrompt": "Session nearing compaction. Store durable memories now.",
"prompt": "Write any lasting notes to memory/YYYY-MM-DD.md; reply with NO_REPLY if nothing to store."
}
},
"memorySearch": {
"enabled":true,
"provider": "local",
"local": {
"modelPath": "hf:ggml-org/embeddinggemma-300m-qat-q8_0-GGUF/embeddinggemma-300m-qat-Q8_0.gguf"
},
"query": {
"hybrid": {
"enabled":true,
"vectorWeight": 0.7,
"textWeight": 0.3
}
},
"cache": {
"enabled":true
}
},
"contextPruning": {
"mode": "cache-ttl",
"ttl": "5m"
}
}
}
}方案二:QMD 后端
相同的压缩和修剪配置,但将内置搜索替换为 QMD:
{
"agents": {
"defaults": {
"compaction": {
"reserveTokensFloor": 40000,
"memoryFlush": {
"enabled":true,
"softThresholdTokens": 4000,
"systemPrompt": "Session nearing compaction. Store durable memories now.",
"prompt": "Write any lasting notes to memory/YYYY-MM-DD.md; reply with NO_REPLY if nothing to store."
}
},
"contextPruning": {
"mode": "cache-ttl",
"ttl": "5m"
}
}
},
"memory": {
"backend": "qmd",
"qmd": {
"searchMode": "search",
"includeDefaultMemory":true,
"sessions": {
"enabled":true
},
"paths": [
{ "name": "obsidian", "path": "~/Documents/Obsidian", "pattern": "**/*.md" }
]
}
}
}记忆问题概述
层级 | 功能 | 启用方法 |
|---|---|---|
工作区文件 | 不受压缩影响的身份和指令 | 结构化 SOUL.md、AGENTS.md、USER.md、MEMORY.md |
压缩前刷新 | 压缩前的自动安全网 | 验证 memoryFlush.enabled: true + 调整 reserveTokensFloor |
手动记忆保存 | 基于相关性的重要决策保存 | 习惯:任务切换前"保存到记忆" |
策略性 /compact | 重要新指令前清理空间 | /compact 在新上下文前,而不是溢出后 |
会话修剪 | 修剪工具膨胀以延迟压缩 + 节省缓存 | contextPruning.mode: "cache-ttl" |
混合搜索 | 即使措辞不同也能找到记忆 | memorySearch 中 query.hybrid.enabled: true |
额外路径(方案一+) | 无需切换后端即可索引外部文档 | memorySearch.extraPaths 用于小型文档集 |
QMD(方案二) | 搜索整个知识库 | memory.backend: "qmd" |
Git 备份 | 所有记忆文件的完整历史、差异、回滚 | 在工作区中 git init,自动提交 cron |
记忆卫生 | 防止引导膨胀和上下文浪费 | 每周:将每日日志提炼到 MEMORY.md |
命令参考
命令 | 功能 | 使用时机 |
|---|---|---|
/context list | 显示加载的工作区文件、大小、截断状态 | 调试任何记忆问题时首先检查 |
/context detail | 特定文件注入的深度分析 | 怀疑文件被截断或缺失时 |
/compact [指令] | 手动触发压缩,可选焦点指导 | 添加重要新指令前(不是溢出后) |
/status | 显示模型、提供商、会话信息 | 验证哪个模型处于活动状态 |
/new 或 /reset | 全新会话,干净上下文 | 陷入溢出死锁或开始新工作时 |
/verbose | 切换工具调用详细信息的详细模式 | 验证记忆搜索是否实际触发并返回结果 |
如果你用过一段时间 OpenClaw,大概率都会经历一个阶段:
你开始不是在用 AI,而是在“反复教它认识你”。
记忆,不是能力,而是系统工程。
欢迎朋友们在评论区留言:
👉 你是怎么“让 AI 记住你”的? 👉 你踩过哪些记忆相关的坑?
-END-
参考:
从架构到代码:深入理解 OpenClaw 的双源记忆系统
https://velvetshark.com/openclaw-memory-masterclass
推荐阅读:
从生成到分享:我把 OpenClaw + 腾讯文档技能跑通了
"数字员工" OpenClaw 能值多少钱?百万美元级别的评测告诉你
给 OpenClaw 装了一套“学习系统”:Self-Improving + AutoSkill,Agent 开始自己进化了
让 OpenClaw 替你打工(三):我不止给它装了 30+ Skills 还创建了技能
让OpenClaw替你打工:每日摘要、获取社交网站信息、量化模拟回测(实战教程&踩坑)
让你的OpenClaw替你打工:从0到1跑通小红书运营全流程(实战教程)
给 OpenClaw 接入10000+工具和数据,为你盯盘,给出独家策略
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号