UniTalk-ASD数据集深度分析报告
原创

一、 应用场景与落地价值
活跃说话人检测(ASD)任务在许多下游应用中起着至关重要的作用,包括说话人日志(Speaker Diarization)、音视频语音识别(Audiovisual Speech Recognition)以及人机交互(Human-Robot Interaction)。 在实际的商业与生活部署中,UniTalk所针对的场景完美契合了现代真实世界的需求,例如视频会议、社交媒体短视频以及现场直播。在这些场景中,模型必须处理极其复杂的状况,如未被充分代表的小语种、嘈杂的背景音(街道声音、音乐或重叠语音)以及涉及多人、遮挡或动态镜头运动的拥挤画面。

二、 相较于主流AVA数据集的核心优势
AVA数据集长期以来是ASD任务的事实基准,但它几乎完全基于电影(尤其是老电影)构建,存在显著的“领域差距(Domain Gap)”。相比之下,UniTalk具有以下压倒性优势:
- 数据来源与真实性:AVA主要包含干净的电影配音,甚至存在音轨与画面嘴型不匹配(人工覆盖)的问题。而UniTalk的数据全部来源于YouTube上的真实世界视频,如综艺、体育采访、播客等,完全还原了真实的噪声和视觉环境。
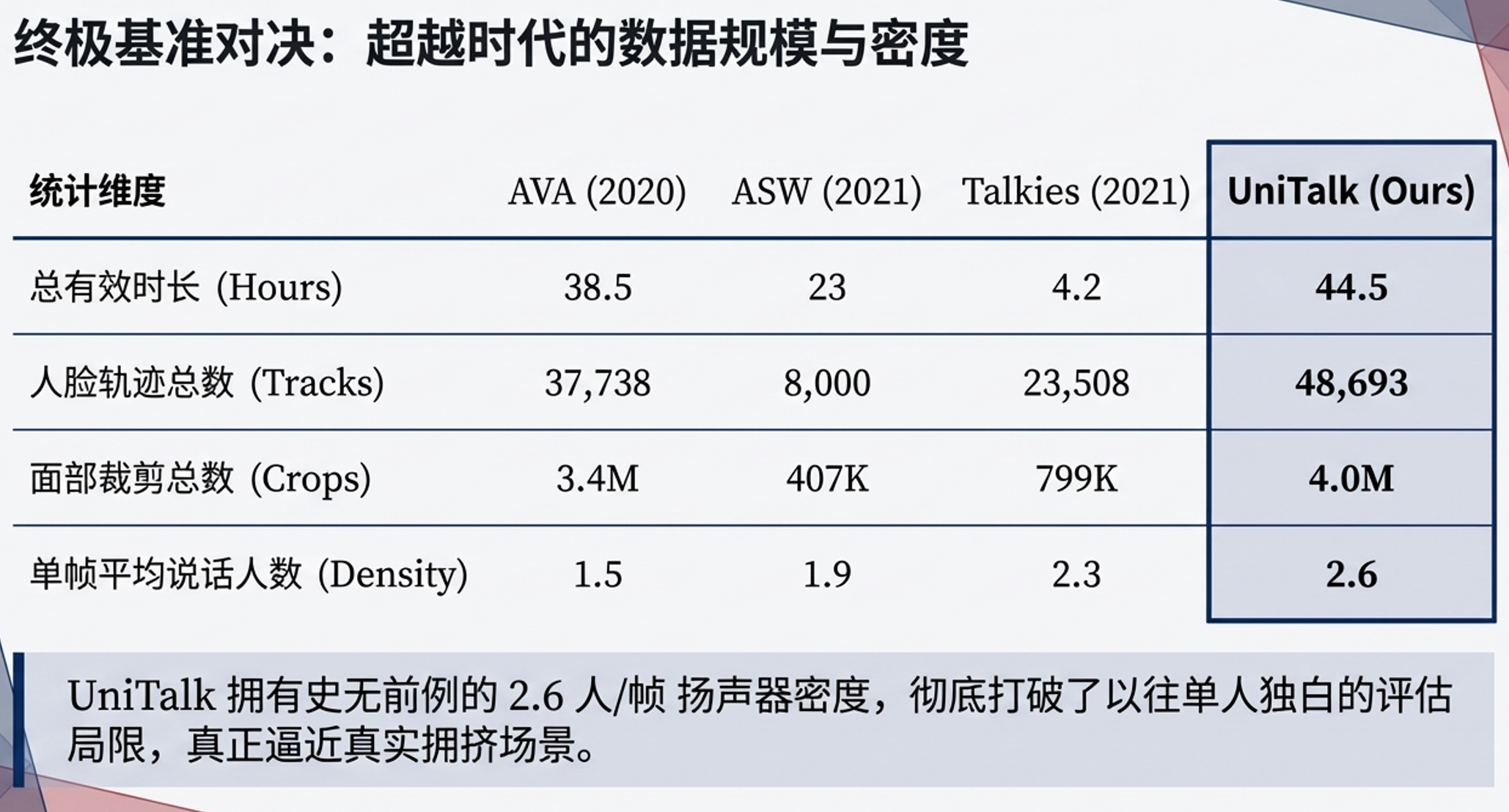
- 视觉复杂度:AVA的平均每帧人脸数仅为1.5人,而UniTalk达到了2.6人,并且有超过55%的帧包含两张或以上的可见人脸,大幅提升了多说话人场景的互动复杂度。
- 语言多样性:AVA主要由印欧语系(如英语、意大利语、俄语)主导,而UniTalk在保持英语为主的同时,大幅增强了东亚语言(如中文、韩语、日语)和越南语、阿拉伯语等语言的覆盖率,为跨文化和多语种场景提供了更稳健的评估基础。
- 系统性的困难维度设计:AVA缺乏对困难场景的系统性覆盖,而UniTalk专门针对“代表性不足的语言”、“高背景噪声”和“拥挤场景”这三个维度进行了精心设计和分类。

三、 视频选择逻辑与构建流程
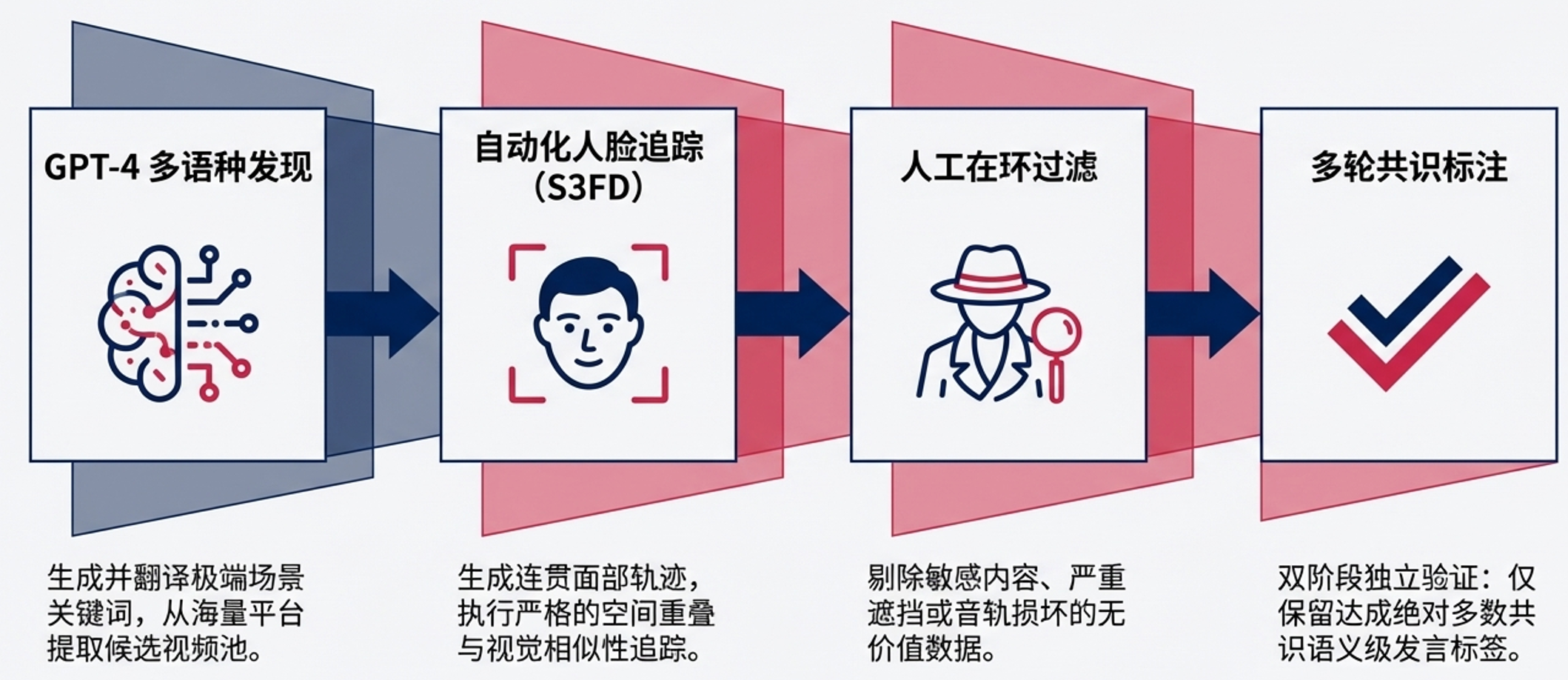
- 搜索与多语言扩展:使用GPT-4生成针对高声学复杂度和高视觉复杂度的搜索关键词(如“游戏节目”、“现场音乐会”、“飞机驾驶舱”),并将其翻译成多语言(如中文、越南语、韩语)以最大化多样性。
- 严格过滤标准:剔除分辨率低于480p、人脸过度遮挡、缺失语音、背景音乐过强或有严重混响的视频,同时排除敏感内容。
- 人脸轨迹生成:通过S3FD检测人脸,使用贪婪算法追踪并进行高斯核平滑。为了保证时间上下文,仅保留长度大于1秒的轨迹,并对小于0.2秒的间隙进行线性插值补洞。最终生成了超过44.5小时、包含48,693个人脸轨迹和400万个人脸裁剪的庞大数据集。
四、 数据表达与严格的标注标准
- 张量输入:模型输入被规范化为视觉张量 V∈R T×H×W 和梅尔频谱图音频张量 A∈R 4T×M 。
- 逐帧二元标注:采用 Y∈{0,1} T 的帧级二元标注。标注标准极其严格:仅当发出带有语义内容的口头信号(包括正常说话、喊叫、唱歌)时才标记为“说话”;而咳嗽、笑声、打喷嚏等非言语发声,即使嘴部动作明显,也被明确排除在外。
五、 难度空间设计与子集划分
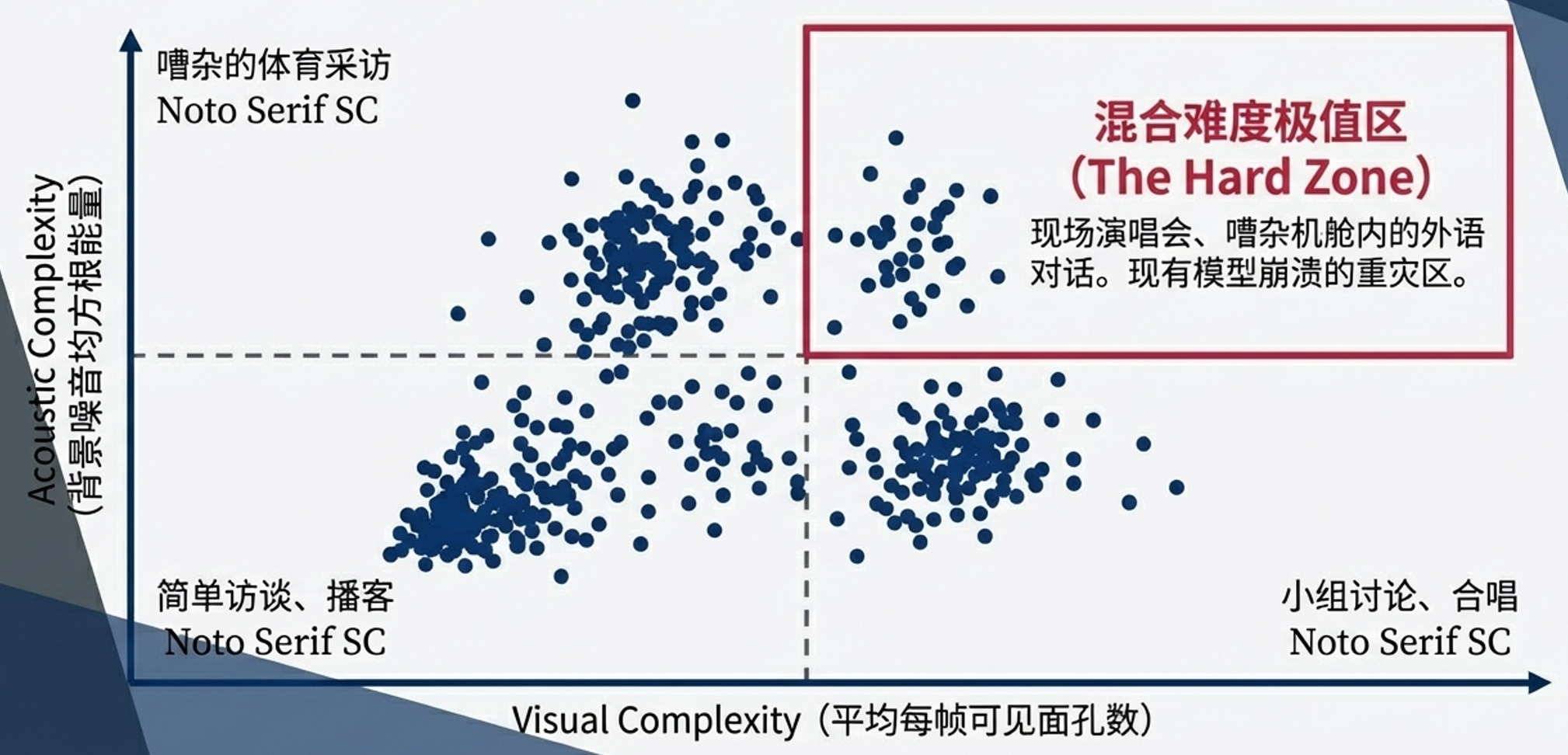
UniTalk将测试集细分为四个专门设计的“压力测试”子集:
- 代表性不足的语言(28.0%):非英语、音频干净、场景简单。
- 嘈杂背景(16.1%):强环境噪声,但语言为主流语言且画面不拥挤。
- 拥挤场景(21.5%):多人、遮挡或快速镜头运动,但音频干净。
- 困难/混合样本(34.4%):同时叠加至少两种上述困难因素(如飞机驾驶舱中的中文对话)。
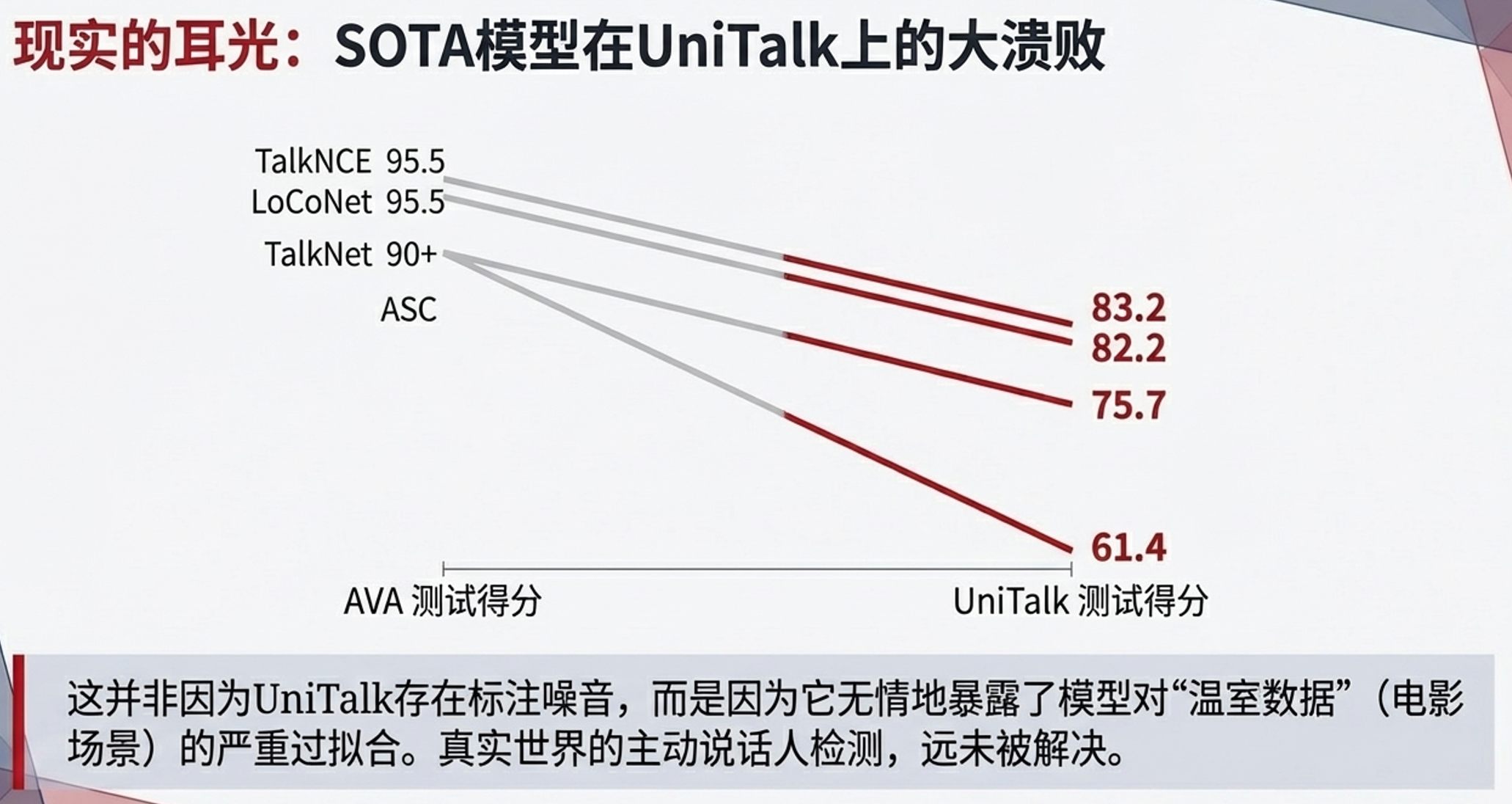
六、 模型挑战与真实失败案例
- 指标暴跌:现有的SOTA模型(如TalkNCE、LoCoNet)在AVA上能取得超过95%的mAP,但在UniTalk上均未能达到饱和。以TalkNCE为例,其在UniTalk上的整体得分为83.2 mAP,在“小语种”下降至86.7,而在包含多重挑战的“困难样本(Hard)”上更是暴跌至77.9 mAP。
- 典型失败案例:附录中展示了一个终极困难的测试视频(越南语室外演唱):画面存在多张相互遮挡的小脸(视觉拥挤),伴随强烈的乐器和环境底噪(高声学噪音),且语言为越南语(代表性不足语言)。面对这种真实场景,所有SOTA模型均出现了严重的帧级预测错误(误判或漏判)。
七、 作为预训练基准的巨大价值
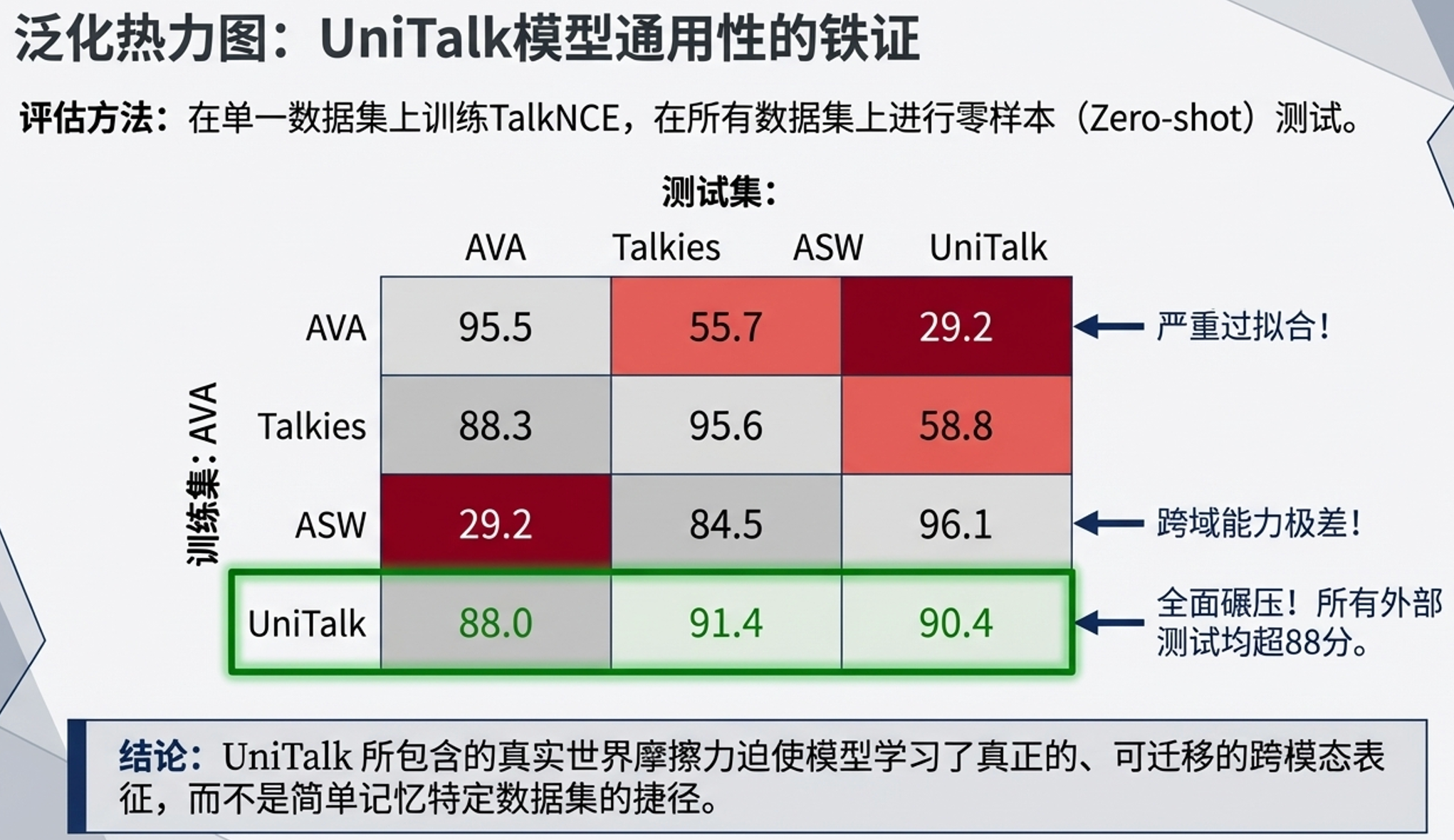
虽然UniTalk极具挑战性,但它提供了极其优质的泛化特征。实验表明,在UniTalk上训练的模型在未见过的真实数据集(如Talkies和ASW)上展现出了极强的零样本迁移能力(得分均在90 mAP以上)。此外,将UniTalk预训练的模型在AVA上进行微调,仅需3小时的AVA数据即可迅速达到92.4 mAP,使用全量数据可达95.7 mAP,同时还能保持在UniTalk本域上的优异表现。这证明了UniTalk不仅是一个严苛的测试场,更是通向通用ASD模型的优秀“预训练教练”。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号