重复测量数据分析及结果详解(之三)——多水平模型

重复测量数据分析及结果详解(之三)——多水平模型

医学和生信笔记
发布于 2026-03-17 18:05:23
发布于 2026-03-17 18:05:23
上一篇文章继续介绍了基于重复测量数据的广义估计方程,对广义估计方程的结果进行了详细解释。本文承接上文,继续介绍医学中重复测量数据的常用方法:多水平模型(multilevel model)。
三、多水平模型

要了解多水平模型,得先了解多水平数据,或者叫多层次数据,简单来说就是具有一定层次结构的数据。比如学校-学生、村-村民、单位-职工,这些都是二层结构,同样,重复测量数据也是一个二层次数据,即:个人-时间点。每个人包含多个时间点,所以是个二层次结构数据。
多水平模型在不同领域有不同叫法,比如随机系数模型、随机效应模型、混合效应模型等等,其实说的都是差不多一回事。它主要是一种处理非独立数据的方法(重复测量数据就是非独立数据,因为每次测量结果可能是相关的,而不是独立的)。
多水平模型应用场景很多,这里只介绍它在重复测量数据中的应用情况。对于重复测量数据,它是将个体与时间点分别看做水平2和水平1两个层次上的数据,水平2包含水平1(即每个人包含多次测量)。
(一)基于重复测量数据的多水平模型思想
对于重复测量数据,传统方法(如一般线性模型)的做法是将数据合并,估计自变量(如组别因素、时间)的效应,这种做法忽略了个体间的变异,因为它假定个体之间是没有差异的。而现实情况是,数据的差异不仅体现在个体内(不同时间点),往往个体之间也是有差异的,因此分析时需要考虑到个体间的差异。
多水平模型正是基于这种思想,将个体间(水平2)的变异分解出来,并估计其大小(通常用方差表示)。然后在此基础上,再估计自变量(如组别)的效应。
(二)多水平模型中的随机效应
多水平模型中,随机效应是一个非常关键的词。多水平模型不同于传统方法的特点就是可以估计随机效应。
在重复测量数据中,随机效应可以理解为个体(水平2)间的随机差异。常见的随机效应有两类:
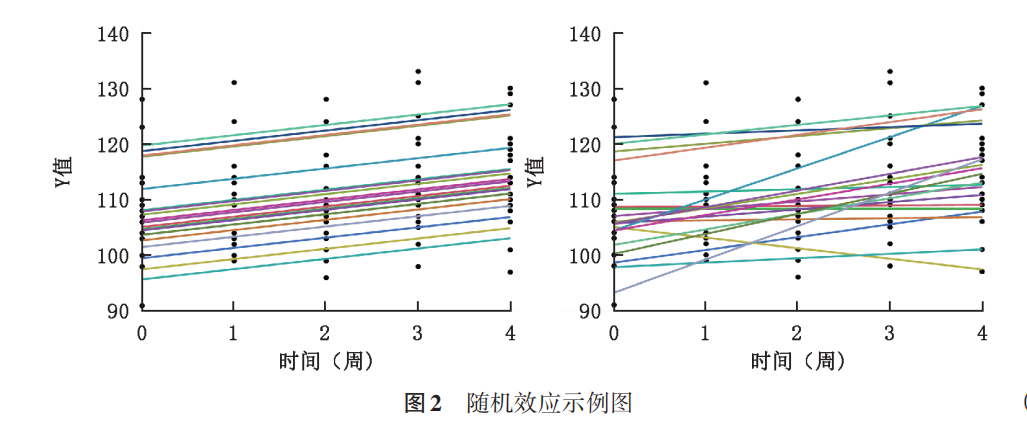
一是个体间只有截距存在差异,斜率相同(图2左,表现为几条平行曲线或直线),即每一个体高低不同,但时间变化趋势相同,这时候如何体现个体间(水平2)的差异呢?只要估计出截距的变异(方差)就行了,所以这种情况下叫做随机截距模型;
二是个体间不仅截距存在差异,斜率也不相同(图2右,表现为几条不平行的曲线或直线),即每一个体不仅高低不同,而且每个人随时间变化的趋势也各不相同。这种情况下,要体现出个体间的差异,仅估计截距的变异是不够,还得估计斜率的变异,即随机系数模型。
重复测量数据分析中,通常先考虑随机截距模型,如果出于专业需要,或经图形发现每个人的时间变化趋势差别较大,也可以考虑随机系数模型。
(三)多水平模型中的用途
多水平模型用途十分广泛,它可以用于具有层次结构的数据分析,如“学校-学生”“乡镇-村民”“患者-肿瘤部位”“个体-时间”等数据,重复测量数据可以看做是多水平数据的特例。
(四)多水平模型的SAS软件实现
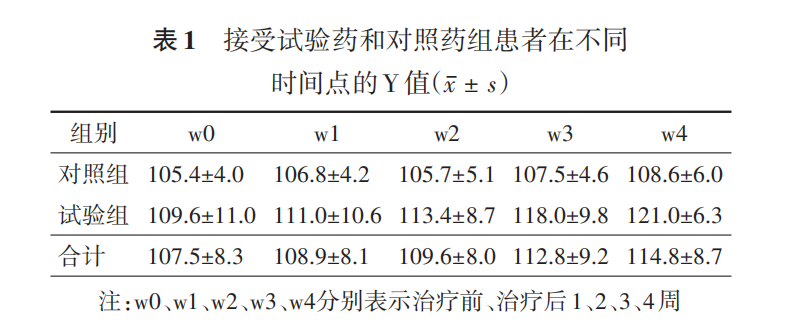
仍以前面文章的例1作为示例。在多水平模型和广义估计方程中,是以模型的形式,主要是明确自变量和因变量。这里组别是自变量(试验组和对照组分别赋值为1和0),因变量用y表示。下面列出数据的图示和每个时间点的均值情况。
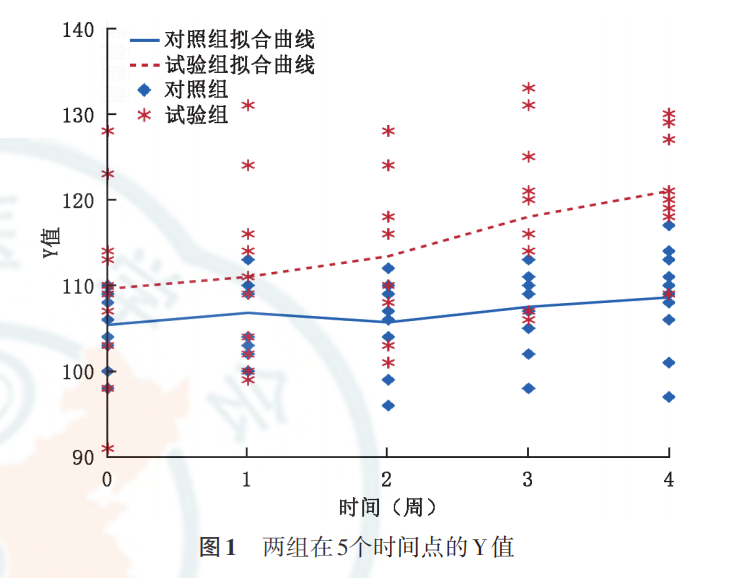
多水平模型的分析通常需要进行一定的初步探索过程,然后才可考虑最终确定的模型。
重复测量数据的多水平模型分析,建议第一步先绘制每一个体随时间的变化趋势图,根据图形为进一步的分析提供参考。例1中20名个体随时间变化的趋势图见图3,可以看出,每个人的Y值高低不同,差异较大,因此至少可以考虑随机截距模型。从时间变化的斜率来看,尽管在某些个体中起伏较大,但总的大都是呈增加趋势,而且可以发现,试验组增加的趋势似乎幅度更大(换句话说,试验组和对照组的变化趋势似乎有差异,当然,有没有的话,需要后面统计分析来确定,但起码可以给我们一些初步提示)。
如果每个人随时间变化趋势基本一致,拟合随机截距模型即可,否则需要考虑随机系数模型。当然图形只是给我们一个初步的主观判断,是否需要采用随机系数模型,可结合统计分析结果来确定。
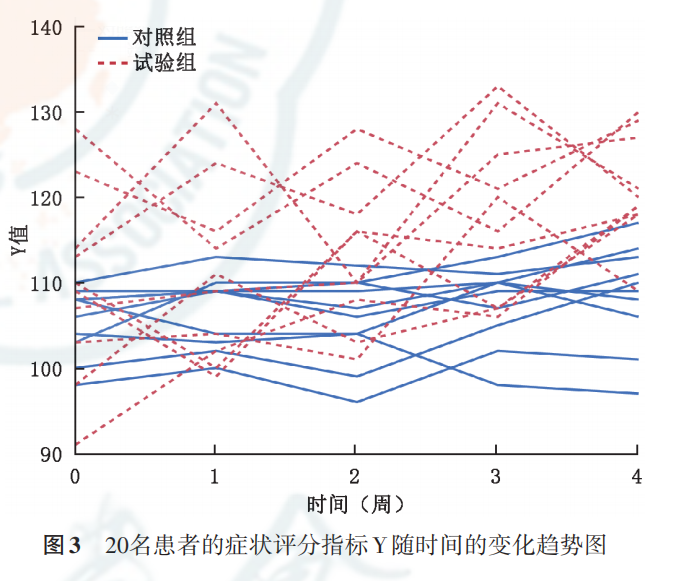
根据图 3提示,我们先考虑拟合随机截距模型,以确定个体间(水平2)是否变异较大。如果变异(方差)较大,那就不能忽视这种变异,需要采用多水平模型将其估计出来;如果变异(方差)较小,那可以忽略,不用多水平模型也没事,直接采用传统的线性模型,把数据合并分析即可。
实际中通常先拟合一个随机截距的空模型(即模型中不包含任何变量),以观察个体间变异情况。SAS程序如下:
data ex2;
input id group time y;
cards;……;
proc mixed covtest data=ex2;
class id;
model y=/solution;
random int/subject=id type=un solution;
/*random指定随机效应,此处指定 int (截距),拟合随机截距模型;
type 指定水平2变量,重复测量数据中即个体id;type指定协方差结构, 常见为vc和un;solution指定输出随机效应估计结果*/
run;
表 6 显示了随机效应估计结果,其中 id 对应的估计值反映了个体间的变异大小(即水平2的方差),Z值和P值反映了方差与0相比的统计学检验结果,本例分析结果显示,个体间差异较大,且这种变异有统计学意义;residual 则显示了水平1的误差,即个体间变异外的随机误差。

这里需要提醒一点,由于此处估计的是方差,方差不可能小于0,因此此处的P值是单侧P值。有的统计软件给出 的是双侧P值,是有问题的。
通过对空模型的分析,可以看出,个体间的确存在较大的变异,且有统计学意义,因此需要考虑多水平模型。如果个体间变异很小,无统计学意义,也可以不用多水平模型, 直接采用普通的一般线性模型即可。
基于表 6 结果,进一步拟合随机截距模型。此时的分析与广义估计方程类似,如果要考虑组别和时间的主效应, 可先不加入交互项。SAS程序如下:
proc mixed covtest data=ex2;
class id time(ref=first);
model y=time group/solution;
random int/subject=id type=un solution;
run;
结果显示,时间和组别的主效应均有统计学意义 (表 7)。与前面文章的表4的广义估计方程结构相比,两种方法的参数估计值相同,但标准误不同,从而导致不同的统计量和 P值。但总的来说,结论是一致的。二者的解释也相同,这里不再赘述。可参考前面文章中广义估计方程的解释结果,这两种方法都是从模型的角度解释的。
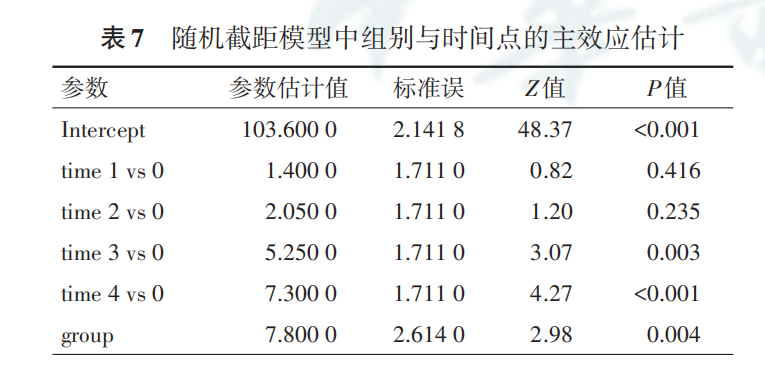
此时拟合的是基于随机截距模型的结果,我们进一步考虑是否有必要采用随机系数模型,即每个人随时间变化的趋势(每个人的斜率)是否有差异。SAS程序如下:
data ex2;
input id group time y;
timec=time;
…… ;
proc mixed covtest data=ex2;
class id time(ref=first);
model y=group time/solution;
random int timec/subject=id type=un solution;
/*random指定int和timec作为随机效应,拟合随机系数 模型 */
run;
注意程序中新产生了 1个新变量 timec,其值完全等同 于 time,即 0~4。产生的目的主要是因为 random 语句指定的随机效应通常为连续变量而不是分类变量(否则容易导致估计不出结果,在SAS中是如此,不同软件规定不同,不是所有软件都需要这么做),然而固定效应估计中我们期望将其作为 分类变量,这样才能发现每一时间点与参照时间点的差异。因此分析时将time作为分类变量,放在固定效应的估计中, 而timec作为连续变量放在随机效应的估计中。当然,如果固定效应分析本身就将time作为连续变量,就无需这一步。所以,这取决于你把time作为连续变量纳入模型,还是作为分类变量纳入模型,作为连续变量,那就是默认时间变化是直线趋势,如果不能确定这一点,最好作为分类变量纳入。
表 8 给出了随机系数模型的随机效应估计结果,与表 6 相比,尽管只增加了 1个随机斜率,但结果却增加了 2个, 除了时间的随机效应外,还有1个是时间随机效应与截距随机效应的协方差。
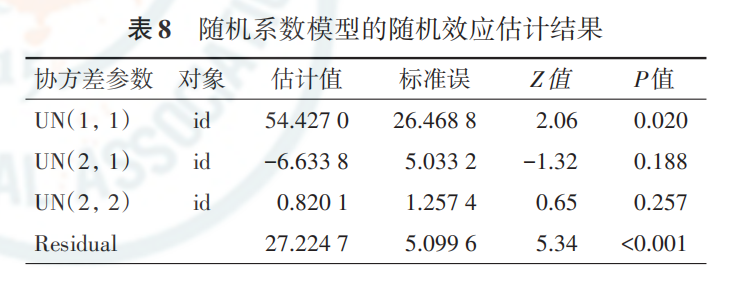
表8结果中,第一行反映的是截距的方差,提示个体间差异较大,且有统计学意义(P=0.020);第三行反映的是(时间变量的)斜率的方差,提示每一个体随时间变化的斜率差异并不大,且无统计学意义(P=0.257);第二行是截距和斜率的协方差,这一结果很有实际意义,它反映了截距与斜率的相 关性,表8结果中,该估计值为负数,提示如果个体初始时间 点的值较大,其斜率较小,反之,如果某个人初始时间点的值 较低,其斜率变化则较大。通俗地说,如果某人一开始Y值很低,那么后期很可能会增长(或降低)很快,而如果一开始Y 值较高,后期增长(或降低)速度会较慢。当然由于该值并无 统计学意义(P=0.188),也可能并无这种关联。
表 8结果提示,time 作为随机效应并无统计学意义,因此实际中考虑随机截距模型即可。
进一步在模型中加入交互项,以考量两组随时间变化的趋势是否相等。SAS程序如下:
proc mixed covtest data=ex2;
class id time(ref=first);
model y=time group time*group/solution;
random int/subject=id type=un solution;
run;
估计结果及其解释仍与广义估计方程类似,结论也是 一致的(表9),此处不再重复解释。读者可参考广义估计方程结果解释。
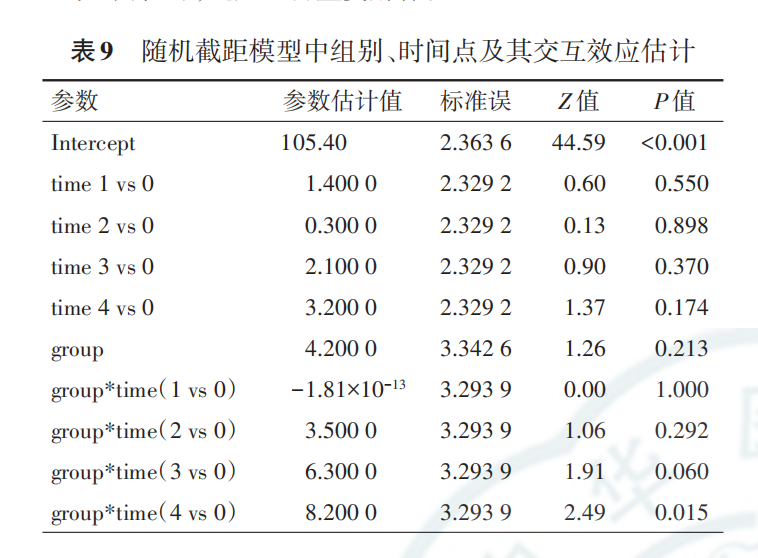
(五)多水平模型分析的注意事项
(1)根据实际趋势选择不同模型
多水平模型分析的关键是如何指定随机效应,不少非统计学专业人员难以理解这一含义。
从实际分析的角度来看,建议一定要先绘制每一个体随时间变化的折线图,根据图形大致观察每一个体是否高低不同或变化趋势不同。
如果只是高低不同,但每一折线的趋势基本类似(如都呈上升趋势),此时可考虑随机截距模型;
如果不仅高低不同,而且每一折线的趋势也不同(如有的呈上升趋势,有的呈下降趋势),此时可考虑随机系数模型。
从软件分析的角度来讲, 随机截距模型即在软件中指定截距为随机效应,随机系数模型即在软件中指定截距和时间变量作为随机效应,作为随机效应的时间变量建议为连续变量。
(2)解读多水平模型结果的固定效应和随机效应
多水平模型的固定效应分析与一般线性模型相同,在重复测量数据中,可根据实际需要指定组别变量、时间变量、组别与时间的交互项,其结果解释与传统的一般线性模型也都相同。
随机效应的估计结果与固定效应不同,它反映的是变异大小,如果只有截距是随机效应,给出的是个体间截距的变异大小;如果截距和时间变量均作为随机效应,给出的是个体间截距的变异大小和个体间(随时间变化)斜率的变异大小。
(3)时间的尺度需要仔细把握
在广义估计方程和多水平模型中,时间变量以何种形式纳入模型是一个较为关键的问题。
在本例的分析中,一直是将时间变量作为分类变量,并以虚拟变量的形式纳入模型,即指定治疗前为参照,其余时间点与治疗前进行比较。这种纳入形式是最为稳妥的方式,不管结局随时间变化趋势是何种形式,均可较好地展示出变化规律。但从实际角度来看,并不是所有分析都需要采用这种方式。
如果从图形中大致能够判断出曲线的变化趋势(如大致为直线上升),可以直接将时间作为连续变量纳入模型。与分类变量相比,作为连续变量纳入可以减少需要估计的参数个数,这在样本例数较少时尤为重要。如本文的分析 案例中,从图 1来看,大致呈直线上升趋势,因此也可以考虑直接作为连续变量纳入,估计结果差别并不大。但如果不确定是否直线,稳妥起见,还是作为分类变量更合适。
多水平模型中,如果要估计时间点对结局影响的随机效应(即假定每个人随时间变化趋势不同,需要估计个体间 斜率的变异),此时建议将时间作为连续变量而不是分类变量,否则容易导致无法估计(SAS软件中是如此,其它软件参考各自软件规则)。如果固定效应仍需要将时间作为分类变量,此时可指定一个新变量,其值等同于原来的 time变量,但将其作为分类变量纳入固定效应分析。
如果重复观测时间点较多,如重复观察 10 多次,此时也不建议将时间变量作为分类变量,而是将其作为连续变量纳入,并根据图形大致形状,指定相应的多项式来拟合变化趋势。如果作为虚拟变量,拟合结果太细,反而容易忽略了真正的变化规律。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号