RF-DETR:最近一个月迭代 5 个版本的实时检测+分割模型
原创
RF-DETR:最近一个月迭代 5 个版本的实时检测+分割模型
原创
CoovallyAIHub
发布于 2026-03-17 09:46:15
发布于 2026-03-17 09:46:15
导读
实时目标检测长期由 YOLO 系列主导,Transformer 架构因推理速度劣势一直难以进入实时场景。
Roboflow 推出的 RF-DETR 改变了这个局面:基于 DINOv2 骨干的检测 Transformer,在 COCO 上以 56.5 AP(L 模型,6.8ms) 超越 YOLO11 和 YOLO26 同级别模型,同时原生支持实例分割。项目开源活跃,一个月发了 5 个版本,近期新增了 PyTorch Lightning 迁移、自定义数据增强、GPU 显存监控等实用功能。
论文: RF-DETR: Neural Architecture Search for Real-Time Detection Transformers 作者: Isaac Robinson, Peter Robicheaux, Matvei Popov, Deva Ramanan, Neehar Peri 发表: ICLR 2026(arXiv: 2511.09554) 代码: https://github.com/roboflow/rf-detr Stars: 5.9K(截至 2026.3.15) 协议: Apache 2.0(N/S/M/L),PML 1.0(XL/2XL)
一、为什么是 Transformer 而不是 YOLO?
YOLO 系列在实时检测领域统治多年,核心优势是速度。但 RF-DETR 证明了 Transformer 架构在实时场景下也能做到更好:
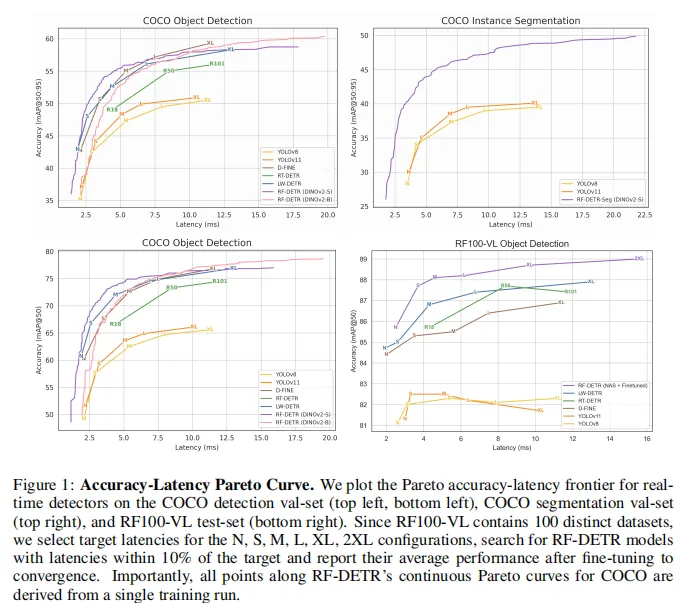
screenshot_2026-03-16_11-39-03.png
图片来源于原论文
模型 | COCO AP₅₀:₉₅ | COCO AP₅₀ | 延迟 (ms) | 参数量 | 分辨率 |
|---|---|---|---|---|---|
RF-DETR-N | 48.4 | 67.6 | 2.3 | 30.5M | 384×384 |
RF-DETR-S | 53.0 | 72.1 | 3.5 | 32.1M | 512×512 |
RF-DETR-M | 54.7 | 73.6 | 4.4 | 33.7M | 576×576 |
RF-DETR-L | 56.5 | 75.1 | 6.8 | 33.9M | 704×704 |
RF-DETR-XL | 58.6 | 77.4 | 11.5 | 126.4M | 700×700 |
RF-DETR-2XL | 60.1 | 78.5 | 17.2 | 126.9M | 880×880 |
延迟在 NVIDIA T4 GPU 上用 TensorRT FP16 测量。
作为参照,YOLO11-S 在 COCO 上的 AP₅₀:₉₅ 为 44.4(3.2ms),YOLO11-M 为 48.6(5.1ms)。RF-DETR-N 以 48.4 AP₅₀:₉₅(2.3ms)超越 YOLO11-S,RF-DETR-S 以 53.0(3.5ms)超越 YOLO11-M——在相近延迟下精度更高。
RF-DETR 使用 DINOv2 作为视觉骨干,结合神经架构搜索(NAS)优化检测头设计,在保持实时推理速度的同时获得了更高的检测精度。
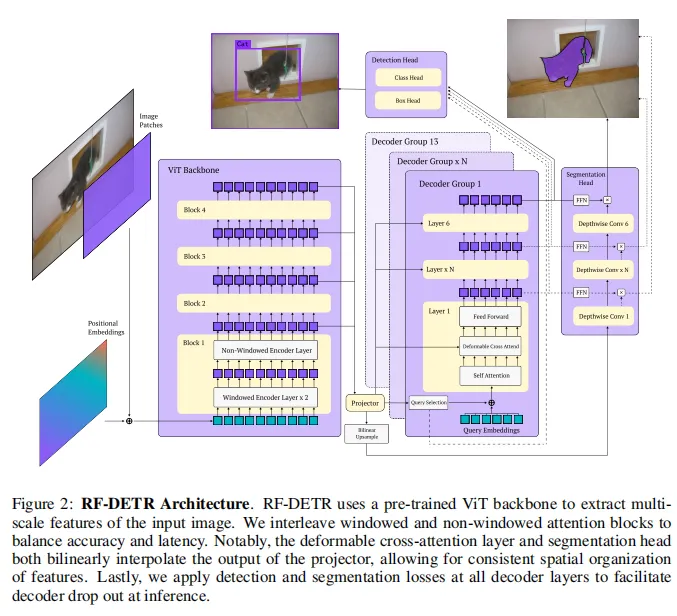
screenshot_2026-03-16_11-43-07.png
图片来源于原论文
二、检测 + 分割,统一 API
自 v1.3.0(2025 年 10 月)起,RF-DETR 新增了实例分割能力,提供统一的 API 接口:
分割模型 | COCO AP₅₀:₉₅ | COCO AP₅₀ | 延迟 (ms) | 参数量 |
|---|---|---|---|---|
RF-DETR-Seg-N | 40.3 | 63.0 | 3.4 | 33.6M |
RF-DETR-Seg-S | 43.1 | 66.2 | 4.4 | 33.7M |
RF-DETR-Seg-M | 45.3 | 68.4 | 5.9 | 35.7M |
RF-DETR-Seg-L | 47.1 | 70.5 | 8.8 | 36.2M |
RF-DETR-Seg-XL | 48.8 | 72.2 | 13.5 | 38.1M |
RF-DETR-Seg-2XL | 49.9 | 73.1 | 21.8 | 38.6M |
用户可以用相同的代码接口切换检测和分割任务,降低了使用门槛。
三、6 种模型规格,覆盖从边缘到云端
RF-DETR 提供从 Nano 到 2XLarge 共 6 个规格:
- Nano/Small(30-32M 参数,2.3-3.5ms):适合边缘设备和实时流处理
- Medium/Large(33-34M 参数,4.4-6.8ms):平衡精度和速度
- XLarge/2XLarge(126M+ 参数,11.5-17.2ms):追求最高精度
N/S/M/L 采用 Apache 2.0 开源协议,可自由商用。XL/2XL 采用 PML 1.0 协议。
四、近期更新:一个月 5 个版本
RF-DETR 的迭代速度很快,2026 年 1-3 月的主要更新:
v1.6.0 rc(3/13)— PyTorch Lightning 迁移
将训练框架迁移到 PyTorch Lightning,为分布式训练、混合精度等高级训练特性提供更好的支持。
v1.5.2(3/4)— GPU 显存监控
训练和评估的进度条现在实时显示 GPU 峰值显存占用(max_mem),无需额外的 profiling 工具即可掌握硬件利用情况。
v1.5.1(2/27)— 嵌套数据增强
支持 Albumentations 的 OneOf 和 Sequential 嵌套容器,增强管线的灵活性。
v1.5.0(2/23)— 自定义数据增强
通过 aug_config 参数完全控制训练增强策略,支持传入 Albumentations 字典、选择内置预设(保守/激进/无增强),或完全禁用增强。边界框和分割掩码会自动跟随变换。
from rfdetr import RFDETRSmall
model = RFDETRSmall()
model.train(dataset_dir=".", aug_config=AUG_AGGRESSIVE)v1.4.2(2/12)— YOLO 格式支持
支持 YOLO 格式数据集直接训练,支持图片 URL 推理,允许无测试集训练。
v1.4.0(1/22)— 新预训练检查点
新增 L/XL/2XL 检测检查点和全系列(N-2XL)分割检查点,性能全面提升。同时放弃 Python 3.9 支持。
五、总结与思考
RF-DETR 的核心价值:
- Transformer 做实时检测的可行性验证:DINOv2 骨干 + NAS 优化的检测头,在 COCO 上超越 YOLO 同级模型
- 检测+分割统一:一套 API 覆盖两种任务
- 迭代速度快:一个月 5 个版本,工程质量扎实(显存监控、增强管线、Lightning 迁移等)
- 对工业场景的适用性:Nano 模型 2.3ms 延迟适合产线实时检测,自定义增强适合特定缺陷场景的微调
值得关注的点:
- XL/2XL 模型的 PML 1.0 协议限制了部分商用场景
- 目前 COCO AP₅₀:₉₅ 对比表中的数据来自 RF-DETR 官方,尚未有第三方独立验证
- 生态还在早期(5.9K stars),相比 Ultralytics YOLO(54K+)的社区规模差距明显
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号