评估指标全景图:准确率、F1、AUC、Silhouette、Calinski-Harabasz、Regret-机器学习算法原子解构系列

评估指标全景图:准确率、F1、AUC、Silhouette、Calinski-Harabasz、Regret-机器学习算法原子解构系列

jack.yang
发布于 2026-03-17 08:29:05
发布于 2026-03-17 08:29:05
核心观点:每一个评估指标背后,都有一段为解决特定问题而诞生的历史;每一次误用,都是对这段历史的遗忘。没有“最好”的指标,只有“最匹配任务目标”的指标。
在机器学习从实验室走向工业部署的过程中,评估指标已从“模型性能的度量工具”,演变为连接算法、业务与伦理的契约语言。然而,当团队盲目追逐 AUC 提升 0.01,却忽视其在不平衡数据中的局限性时,他们实际上是在用 1950 年代的雷达信号检测理论,解决 2020 年代的金融风控问题。比如在 Kaggle 比赛中,AUC 是金标准;在医疗诊断中,召回率关乎生死;在推荐系统中,NDCG 决定收入。然而,许多团队在上线模型后才发现:线上业务指标(如用户留存)与离线评估指标(如准确率)完全脱钩。
本章将从起源 → 定义 → 任务类型 → 指标选择 → 失效信号 → 工程解读四层结构,构建你的评估指标决策树。
1. 历史起源:指标为何而生?
每一个主流评估指标,都诞生于一个具体的工程或科学问题。理解其起源,是避免误用的第一步。

image
💡 关键洞察:指标是特定历史场景的产物。脱离其原始语境使用,极易导致误判。
2. 严格数学定义
以下给出各指标的形式化定义,明确其输入、输出与假设条件,确保跨框架、跨论文的一致性。
(1)分类任务
- 准确率(Accuracy)

image
假设:所有类别同等重要,且训练/测试分布一致(i.i.d.)。
- 精确率(Precision)与召回率(Recall)
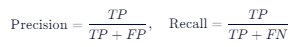
image
- F1 分数(调和平均)

image
注:调和平均对极端值更敏感,优于算术平均。
- AUC(ROC 曲线下面积)
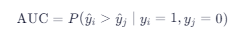
image
即:随机选一个正样本和一个负样本,模型给正样本打分更高的概率。
(2)聚类任务
- Silhouette 系数(样本级) 对样本 (i),设 (a(i)) 为同簇平均距离,(b(i)) 为最近异簇平均距离:
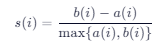
image
整体 Silhouette 为所有 (s(i)) 的均值,取值 ([-1, 1]),越大越好。
- Calinski-Harabasz 指数

image
(3)强化学习
- Regret(T 步累计后悔值)

image
📌 所有定义均基于标准符号体系,后续算法章节将沿用此规范。
3. 直观直觉:指标即“业务契约”
- 准确率(Accuracy) → “整体正确率” 适用于类别均衡场景(如手写数字识别)。但在欺诈检测中,99.9% 准确率可能意味着漏掉所有欺诈交易(因欺诈仅占 0.1%)。
- F1 分数 → “精确率与召回率的调和平均” 当你既怕误报(如把正常邮件标为垃圾),又怕漏报(如漏掉重要邮件),F1 是平衡点。
- AUC(ROC 曲线下面积) → “排序能力的度量” 不关心绝对阈值,只问:“正样本是否排在负样本前面?” 适用于需要动态调整阈值的场景(如风控评分卡)。
- Silhouette 系数 → “簇内紧致 vs 簇间分离” 聚类不是分类!Silhouette 告诉你:每个样本是否真的属于当前簇,而非强行分组。
- Calinski-Harabasz 指数 → “类间方差 / 类内方差” 数值越大越好,适合自动选择最优聚类数 K(如肘部法替代方案)。
- Regret(后悔值) → “与最优策略的累积损失差” 强化学习/在线学习的核心指标:不是绝对收益高,而是少走弯路。
💡 关键洞察:评估指标是目标函数的代理(Proxy)。若代理与真实目标错位,优化即灾难。
4. 按任务类型分类:指标选择决策表
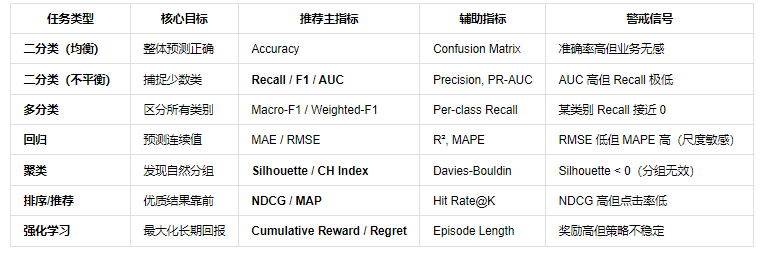
image
📌 注:
- PR-AUC(Precision-Recall AUC)在极度不平衡时比 ROC-AUC 更可靠。
- MAPE(Mean Absolute Percentage Error)对零值敏感,慎用于含零目标的回归。
- R² 可为负值!表示模型比均值预测还差。
5. 工程实现剖析:Scikit-learn 中的关键细节
from sklearn.metrics import (
accuracy_score,
f1_score,
roc_auc_score,
silhouette_score,
calinski_harabasz_score,
mean_absolute_error,
ndcg_score
)
# 二分类:注意 proba vs label
auc = roc_auc_score(y_true, y_proba[:, 1]) # 必须传概率!
# 多分类 F1:macro vs weighted
f1_macro = f1_score(y_true, y_pred, average='macro') # 平等对待每类
f1_weighted = f1_score(y_true, y_pred, average='weighted') # 按样本数加权
# 聚类:Silhouette 计算昂贵(O(n²))
sil = silhouette_score(X, labels, metric='euclidean')
# 推荐:ndcg_score 需要 relevance scores
ndcg = ndcg_score([true_relevance], [predicted_scores])⚠️ 常见陷阱:
- 用
roc_auc_score(y_true, y_pred)(传标签而非概率)→ 结果恒为 0.5! - 在聚类中用 Accuracy → 无意义(标签无语义)
6. 失效场景与陷阱:当指标“说谎”时
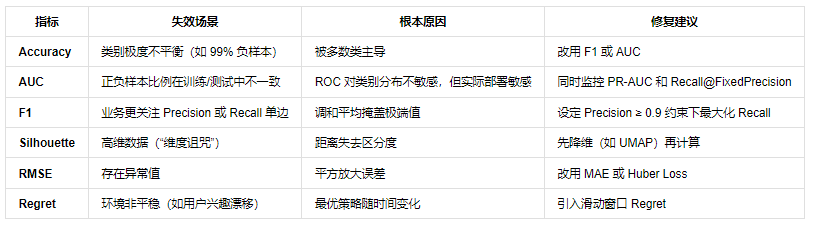
image
🔧 工程经验:永远同时监控 2–3 个互补指标。例如:
- 欺诈检测:Recall@95% Precision + AUC + False Positive Rate
- 推荐系统:NDCG@10 + Coverage + Diversity
7. 工业级指标设计:从离线到在线
离线指标 ≠ 线上效果。顶尖团队的做法:
建立指标映射链
离线 AUC ↑ → 线上点击率 ↑ → 用户停留时长 ↑ → 月活增长 ↑若中间任一环节断裂,需重新设计代理指标。
引入业务约束指标
- 公平性:不同用户群的 Recall 差异 ≤ 5%
- 安全性:高风险操作的 Precision ≥ 99%
- 成本:单次推理 Token 消耗 ≤ 1000
A/B 测试为终极裁判 所有离线指标仅为候选模型筛选器,最终以线上业务指标为准。
8. 本章小结:评估指标使用 checklist
✅ 第一步:明确业务目标 - 是减少漏报?提升用户体验?还是最大化收入?
✅ 第二步:选择主指标 + 辅助指标 + 约束指标 - 主指标驱动优化,辅助指标防偏,约束指标保底线
✅ 第三步:验证指标与业务的相关性 - 历史数据回测:指标提升是否伴随业务提升?
✅ 第四步:监控指标漂移 - 当数据分布变化时,原指标是否仍有效?
记住: “You optimize what you measure.” —— 你优化的,正是你所度量的
延伸资源
- Scikit-learn 官方指标文档:https://scikit-learn.org/stable/modules/model_evaluation.html
- Hanley & McNeil (1982). The meaning and use of the area under a ROC curve.
- Rousseeuw (1987). Silhouettes: a graphical aid to the interpretation and validation of cluster analysis.
- Google ML Crash Course: Classification Metrics
- 交互式工具:ROC Curve Explorer
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-03-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号