Java 的 0x7c00 之搞怪的 Java 代码



中秋节过完了,假期也过完了,又回归了工作。
不知道大家在假期里都是怎么度过的,但是肯定都觉得假期过的很快吧!以前听过一句话,从同学那里听来的吧,“年怕中秋,月怕半”。意思是一个月过完一半,剩下的一半感觉就很快了;一年的时间,过完中秋之后,在(感觉/事实)上离下次过年也就不远了。
假期这几天,我们这边一直稀稀拉拉的在下雨,秋天的感觉也很明显了,大家提早穿好秋裤,注意保暖吧~!
本篇文章内容是非正常编码的方式,它是 Java 团队为 Java 语言的跨平台所设计的让 javac 处理的源码的一种特性。它只适合学习和交流,不适合用在项目当中!切记!用来开玩笑也不适合~!!
上面是调侃,下面是正文~!
0x01. 搞怪代码
单刀直入,直接来看代码!
public class Hello
{
public static void main(String[] args)
{
System.out.print("hello"); // \u000A System.out.println(" world");
System.out.print("hello"); // \n System.out.println(" world");
System.out.println();
}
}看下这段代码,想一下它输出的内容,1、2、3……来,给出答案!
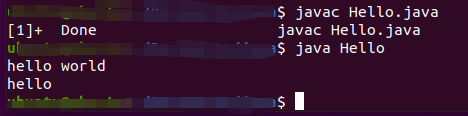
在未看结果之前,不知道是否可以想到答案,至少我是想不出。但是看了答案又感觉原来如此,也不过如此。应该 \u 开头的 Unicode 转义序列被 Java 的编译器处理了。即使在注释中,也被处理了。

上面这段代码的灵感来自于《Java 核心技术》一书。
0x02. 搞怪吗?来看看它的马屁股!
上面的代码感觉奇怪么?注释里的内容不是说好了不处理的吗?javac 怎么给转义了呢?该不会是 javac 的 bug 吧?
其实不是!
根据 Java 语言规范的描述来说,这是 javac 有意为之的。在 Java 语言规范中给出了关于 Unicode 转义序列被 javac 处理时的解释。
- Unicode 转义序列在编译的最早阶段处理
- 处理顺序在注释识别之前
- 目的是确保源代码的跨平台一致性
javac 其执行顺序大致是这样的:
源代码 → Unicode 转义处理 → 词法分析(识别注释、关键字等) → 语法分析
其实这个规范也是跟历史有关系的,早期的开发环境支持的字符集、早期文件的编码格式等,才使得 javac 需要这样的处理顺序(Java 还要跨平台,对可移植性提供了保障)。(这好像又回到了 0x7c00 和 火车宽度是几个马屁股的宽度的问题了,为什么我总是提 0x7c00 呢,因为那篇文章阅读量大呗~!从内存地址 0x7c00 思考程序员的差距)。
从上面代码我们能感觉到这种处理方式是有安全隐患的,但是 Java 团队并没有移除该特性。那么说,这种特性的优点是大过缺点的,哪有十全十美的设计呢?不过是一种平衡上的选择。既然优点大于了缺点,那么就选择了保留。

这里给出 Java 语言规范的地址:
https://docs.oracle.com/javase/specs/jls/se8/html/index.html
想要了解细节 javac 的一些细节,重点阅读 3.2 和 3.3 即可!
0x03.最后
对于这种 Unicode 转义序列,大家还能想到其他的玩法吗?
再举几个例子吧~!
例子一:
public class HiddenLoop {
public static void main(String[] args) {
System.out.println("开始计数:");
int i = 1;
// \u000A while (i <= 3) {
System.out.println("数字: " + i);
i++;
// \u000A }
}
}例子二:
public class ArrayBreak {
public static void main(String[] args) {
int[] numbers = {1, 2, 3\u007D; System.out.println("数组初始化被中断!"); int[] more = {4, 5};
System.out.print("numbers: ");
for (int n : numbers) {
System.out.print(n + " ");
}
System.out.println();
System.out.print("more: ");
for (int n : more) {
System.out.print(n + " ");
}
}
}上面的两个例子是用来进行搞怪的例子,你能猜到它们的输出结果吗?
那么在实际的环境中,它有实际的作用吗?其实还是有的。比如在某些受限的环境中,只能在使用纯粹 ASCII 的环境中编码,那么可以通过这种方式来包含 Unicode 字符;或者需要明确指定不可见字符时,也可以使用该特性。

都看到这里,给点个赞支持一下再走吧~!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号