babyvm 逆向分析(二)



上篇文章中,我们把 babyvm 的大体结构了解清楚了,本篇文章开始分析 babyvm 的执行。
0x01:上篇文章回顾
上篇文章中把相关函数都已经整理好了。上次分析了它的 handler 函数,以及分发判断的字符。它的 handler 一共就几个,上次也都看过了。
它还有一个大大的 opcode 数组,我们只需要按照它的流程来让它模拟执行 opcode,我们就可以得到它的具体执行流程,从而分析它的算法,得到最后的 flag。
0x02:分析 VmRun 和 DispatchCode 的流程
对于我们来说,初始化已经详细看过了,最后 flag 的判断那是后话。因为,我们需要了解的是它具体的执行流程。而执行流程主要是在 VmRun 和它其中的 DispatchCode 两个函数。这两个函数分别如下。
VmRun 函数的代码:
unsigned __int64 __fastcall VmRun(VM *pVm)
{
unsigned __int64 v2; // [rsp+18h] [rbp-8h]
v2 = __readfsqword(0x28u);
pVm->opcode = &opcode;
while ( *(_BYTE *)pVm->opcode != 0xF4 )
DispatchCode(pVm);
return __readfsqword(0x28u) ^ v2;
}可以看到,VmRun 主要就是一个 while 循环,大多数都是一个 while 循环。当 opcode 当前字节为 0xF4 时结束循环。它的循环体比较简单,就是一个 DispatchCode 函数,代码如下:
unsigned __int64 __fastcall DispatchCode(VM *pVm)
{
int i; // [rsp+14h] [rbp-Ch]
unsigned __int64 v3; // [rsp+18h] [rbp-8h]
v3 = __readfsqword(0x28u);
for ( i = 0; *(_BYTE *)pVm->opcode != *(&pVm->op0 + 16 * i); ++i )
;
(*((void (__fastcall **)(VM *))&pVm->handler0 + 2 * i))(pVm);
return __readfsqword(0x28u) ^ v3;
}上面的代码也比较好理解,for 中相当于查找的 opcode 的当前字节对应的分发值,也就是依次找 op0、op1,这里完全可以使用一个 switch 来代替。使用 switch 更直观,但是这样写代码量少啊!
找到对应的值以后,调用相对应 handler 函数即可。循环体内的 i 和 循环体外的 i 是同样的值。
0x03:编写模拟执行的代码
我们把要用的代码都抄到自己的代码中,然后进行相应的调整即可。
下面是部分调整后的代码,代码如下所示:
// 全局变量
void *pMem = NULL;
DWORD dwLength = 0;
char EncCodeFlag[] = "Fz{aM{aM|}fMt~suM !!";
// 输入函数
void InputAndCheckLength(struct VM *pVm)
{
const char *buf;
buf = (const char *)pMem;
strcpy(pMem, "111111122222223333333");
dwLength = strlen(buf);
if ( dwLength != 21 )
{
puts("WRONG!");
exit(0);
}
++pVm->opcode;
}
// 分发函数
void DispatchCode(struct VM *pVm)
{
printf("%3d: ==> %x ===> ", pVm->opcode - opcode, *(_BYTE *)pVm->opcode);
switch (*(_BYTE *)pVm->opcode)
{
case 0xF1:
Mov(pVm);
break;
case 0xF2:
Xor(pVm);
break;
case 0xF5:
InputAndCheckLength(pVm);
break;
case 0xF4:
Nop(pVm);
break;
case 0xF7:
Mul(pVm);
break;
case 0xF8:
Swap(pVm);
break;
case 0xF6:
Arithmetic(pVm);
break;
}
}
// 初始化函数
void VmInit(struct VM *pVm)
{
pVm->r0 = 0;
pVm->r1 = 18;
pVm->r2 = 0;
pVm->r3 = 0;
pVm->opcode = (char*)opcode;
pMem = malloc(0x512);
memset(pMem, 0, 0x512);
}可以看到,我们的初始化函数短了很多,因为我们的分发函数不再使用函数指针的形式去调用,而是改成了 switch case 的方式去调用了。还带着一些全局的变量。
同样,对于我们来说比较重要的就是 DispatchCode 函数里的这行代码:
printf("%3d: ==> %x ===> ", pVm->opcode - opcode, *(_BYTE *)pVm->opcode);这行代码是我自己添加的,不是复制出来的,它可以帮我们打印出我们想要的偏移和对应的字节码。
0x04:编译运行
到这一步以后,就可以编译运行了,运行结果如下图。

可以看到,在输出的结尾直接输出了 “WRONG!”,说明代码跑完了!开心不开心?因为 flag 的比较在整个 VM 执行的流程之外,因此 VM 根据 opcode 执行中途是不会退出的。
那么接下来,我们还是增加输出代码来观察流程。
0x05:增加流程后的运行
从上面的流程中可以看到,整个流程的运行主要就是针对 0xf1 和 0xf2 的分支运行的。那我们就专门增加这两句的输出。多少有些诡异,这样的算法会不会过于简单呢?
编译运行后的输出如下图所示。
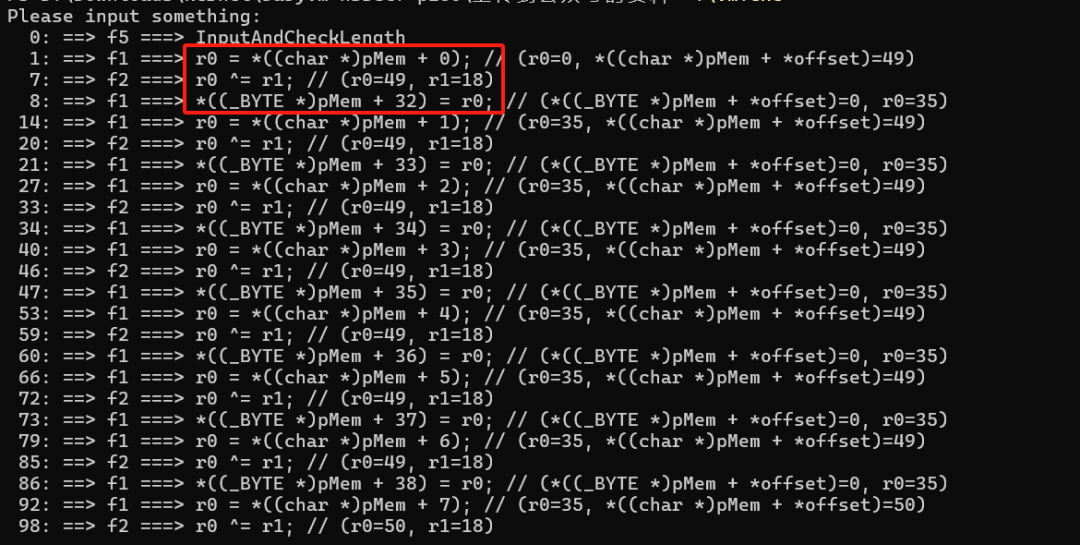
这么多行代码,流程都出奇的一样,从我们的输入中依次读取,然后取出与 18 进行异或,异或后写入 pMem 偏移 32 的位置处。18 是初始化时的赋值。
知道了算法,就好解决了。
0x06:修改代码
既然就是一个异或运算,那就用最后比对的字符串和 18 进行异或,然后直接打印 pMem + 32 的偏移就是我们要的结果了。修改代码如下:
void InputAndCheckLength(struct VM *pVm)
{
printf("InputAndCheckLength \r\n");
const char *buf;
buf = (const char *)pMem;
// strcpy(pMem, "111111122222223333333");
strcpy(pMem, EncCodeFlag);
dwLength = strlen(buf);
/*
if ( dwLength != 21 )
{
puts("WRONG!");
exit(0);
}
*/
++pVm->opcode;
}
void CheckFlag()
{
int i;
// 增加的代码
printf("%s\r\n", pMem + 32);
for ( i = 0; dwLength - 1 > i; ++i )
{
if ( *((_BYTE *)pMem + i + 32) != EncCodeFlag[i] )
{
puts("WRONG!");
exit(0);
}
}
puts("Congratulation?");
puts("tips: input is the start");
}编译运行,看输出结果:
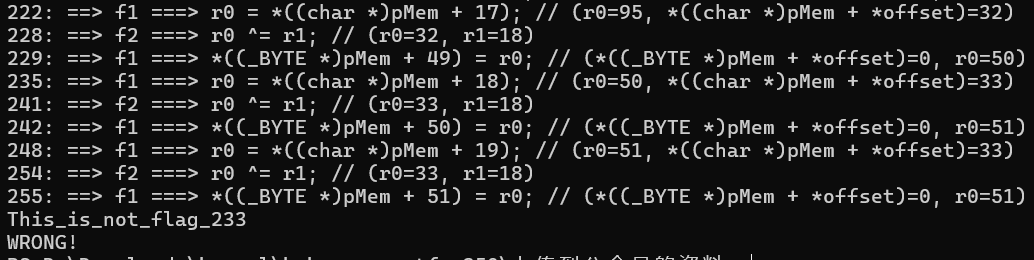
可以看到,输出的值是 This_is_not_flag_233,很奇怪的值啊。
用得到的 flag 继续进行测试,修改代码测试:
void InputAndCheckLength(struct VM *pVm)
{
printf("InputAndCheckLength \r\n");
const char *buf;
buf = (const char *)pMem;
// strcpy(pMem, "111111122222223333333");
// strcpy(pMem, EncCodeFlag);
strcpy(pMem, "This_is_not_flag_233");
dwLength = strlen(buf);
/*
if ( dwLength != 21 )
{
puts("WRONG!");
exit(0);
}
*/
++pVm->opcode;
}再次编译运行输出,如下图:

看图,虽然好像是成功了,但是却好像这个值是个假的。
0x07:重新出发
再次看上面的图,我们的 opcode 执行到偏移 255 的位置,但是我们的 opcode 远不止 255 个,一共有 500 多个吧,如下图:
看上面的提示,"input is the start"。
然后,我们重点看一下我们的 opcode,opcode 是以 0xF5 是的,以 0xF4 结束的。在整个 opcode 中,有两个 0xF5,和两个 0xF4。且第二个 0xF5 不在第一个 0xF5 和 0xF4 之间。猜测应该是两段 opcode,可能正确的是第二段吧。
那么,我们调整 opcode 的数组,只保留第二个 0xF5 和 0xF4 之间的数据。然后编译运行,结果如下图:
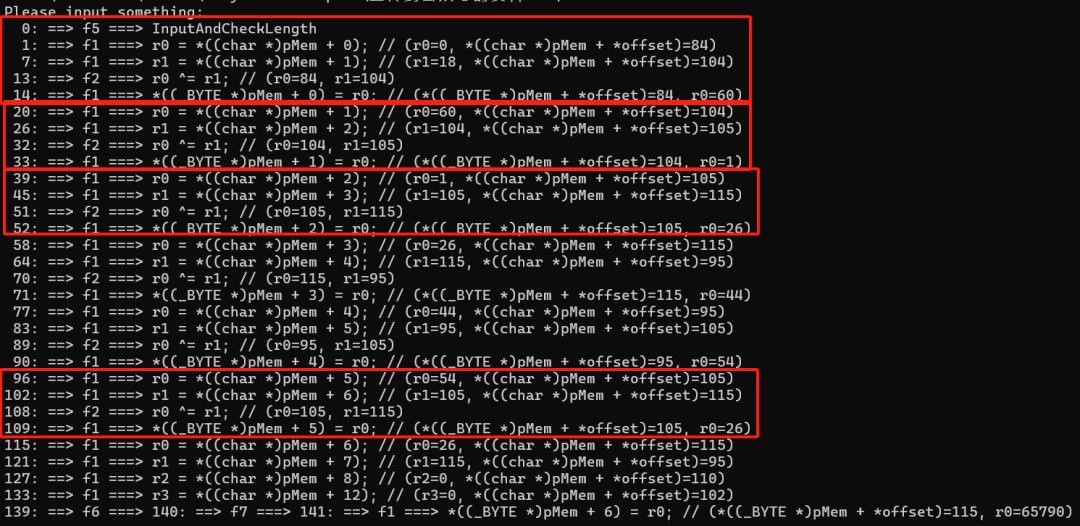
可以看到,算法不太一样了,这次算法的总结如下:
pMem[0] = pMem[0] ^ pMem[1];
pMem[1] = pMem[1] ^ pMem[2];
pMem[2] = pMem[2] ^ pMem[3];
pMem[3] = pMem[3] ^ pMem[4];
pMem[4] = pMem[4] ^ pMem[5];
pMem[5] = pMem[5] ^ pMem[6];之后的算法还有没有输出的,继续增加输出,编译运行。上图,我们看到了偏移 109 的位置,这次我们从偏移 109 之后开始看起,运行结果如下:
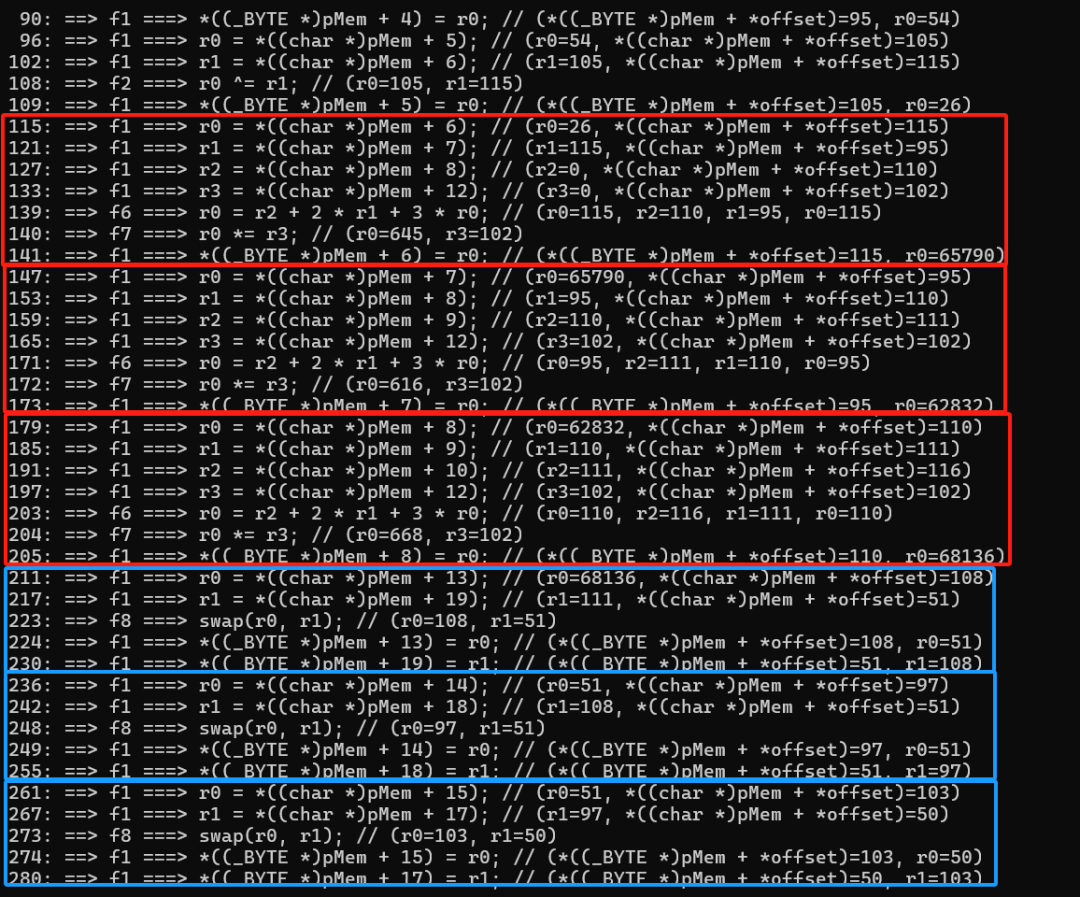
图中我用两种颜色框住了代码,红色是一种算法,蓝色是另外一种算法。总结上面的算法,先看红色部分:
115: ==> f1 ===> r0 = *((char *)pMem + 6);
121: ==> f1 ===> r1 = *((char *)pMem + 7);
127: ==> f1 ===> r2 = *((char *)pMem + 8);
133: ==> f1 ===> r3 = *((char *)pMem + 12);
139: ==> f6 ===> r0 = r2 + 2 * r1 + 3 * r0;
140: ==> f7 ===> r0 *= r3;
141: ==> f1 ===> *((_BYTE *)pMem + 6) = r0;上面复制出一组红色框的代码,每个红色框的算法是一致的,只是数据不同,整理算法如下:
pMem[6] = (pMem[8] + 2 * pMem[7] + 3 * pMem[6]) * pMem[12];
pMem[7] = (pMem[9] + 2 * pMem[8] + 3 * pMem[7]) * pMem[12];
pMem[8] = (pMem[10] + 2 * pMem[9] + 3 * pMem[8]) * pMem[12];再来看蓝色的部分,代码如下:
211: ==> f1 ===> r0 = *((char *)pMem + 13);
217: ==> f1 ===> r1 = *((char *)pMem + 19);
223: ==> f8 ===> swap(r0, r1);
224: ==> f1 ===> *((_BYTE *)pMem + 13) = r0;
230: ==> f1 ===> *((_BYTE *)pMem + 19) = r1;这个就更简单了,算法如下:
swap(pMem[13], pMem[19]);
swap(pMem[14], pMem[18]);
swap(pMem[15], pMem[17]);把上面的算法都整合到一起如下:
pMem[0] = pMem[0] ^ pMem[1];
pMem[1] = pMem[1] ^ pMem[2];
pMem[2] = pMem[2] ^ pMem[3];
pMem[3] = pMem[3] ^ pMem[4];
pMem[4] = pMem[4] ^ pMem[5];
pMem[5] = pMem[5] ^ pMem[6];
pMem[6] = (pMem[8] + 2 * pMem[7] + 3 * pMem[6]) * pMem[12];
pMem[7] = (pMem[9] + 2 * pMem[8] + 3 * pMem[7]) * pMem[12];
pMem[8] = (pMem[10] + 2 * pMem[9] + 3 * pMem[8]) * pMem[12];
swap(pMem[13], pMem[19]);
swap(pMem[14], pMem[18]);
swap(pMem[15], pMem[17]);这下整个算法就明确了。
0x08:CheckFlag 的问题与解决
上面得到了算法,但是 CheckFlag 就有问题了,看一下 CheckFlag 的代码,代码如下:
void CheckFlag()
{
int i;
printf("%s\r\n", pMem + 32);
for ( i = 0; dwLength - 1 > i; ++i )
{
if ( *((_BYTE *)pMem + i + 32) != EncCodeFlag[i] )
{
puts("WRONG!");
exit(0);
}
}
puts("Congratulation?");
puts("tips: input is the start");
}CheckFlag 函数在比较 Flag 的时候是从 pMem 偏移 32 的位置开始比较的,但是我们拿到的新的算法都会将结果写到从 pMem 开始位置处依次后移。
思考……我在 Functions 窗口中发现了新的函数,这个函数是没有被处理过的函数,如下图:
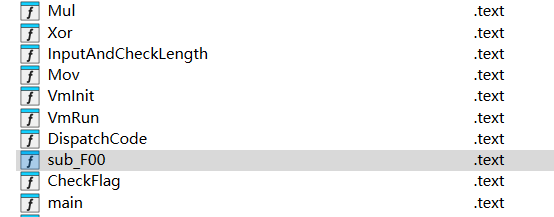
定位到该函数,代码如下:
unsigned __int64 sub_F00()
{
int i; // [rsp+Ch] [rbp-14h]
unsigned __int64 v2; // [rsp+18h] [rbp-8h]
v2 = __readfsqword(0x28u);
for ( i = 0; dwLength - 1 > i; ++i )
{
if ( *((_BYTE *)pMem + i) != byte_202020[i] )
exit(0);
}
return __readfsqword(0x28u) ^ v2;
}这个函数的结构和 CheckFlag 函数的结构是一样的,但是这个函数是没有任何交叉引用的。该函数中,有一个全局变量 dwLength,这个我们是知道的,还有一个 byte_202020 的全局变量,我们去看一下,如下:
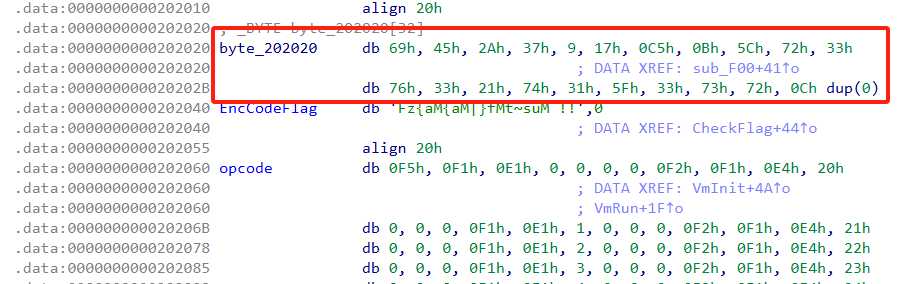
这个全局变量在 假值 和 opcode 上面定义的。
把它们抄到代码中!代码如下:
char EncCodeFlagNew[] = {
0x69, 0x45, 0x2A, 0x37, 0x9, 0x17, 0x0C5, 0x0B, 0x5C, 0x72, 0x33,
0x76, 0x33, 0x21, 0x74, 0x31, 0x5F, 0x33, 0x73, 0x72, 0x0, 0x0, 0x0,
0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0
};
void CheckFlagNew()
{
int i;
for ( i = 0; dwLength - 1 > i; ++i )
{
if ( *((_BYTE *)pMem + i) != EncCodeFlagNew[i] )
exit(0);
}
}到这里,看来我们该收集的内容已经收集全了,接下来就是考虑怎么还原的问题了。
未完待续!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号