CVPR 2026 | VisualAD:去掉文本编码器,纯视觉也能做零样本异常检测
原创
CVPR 2026 | VisualAD:去掉文本编码器,纯视觉也能做零样本异常检测
原创
CoovallyAIHub
修改于 2026-03-17 14:34:18
修改于 2026-03-17 14:34:18
导读
做零样本异常检测,一定要用文本提示吗?VisualAD 给出了一个意外的答案:把 CLIP 的文本编码器整个去掉,只靠两个可学习的视觉 token,参数量砍掉 99%,效果反而更好。在 MVTec AD、VisA 等 13 个基准上取得 SOTA,非 MVTec 数据集上的优势尤为明显(BTAD 超 AnomalyCLIP 6.2 个百分点,KSDD2 超 6.1 个百分点)。
论文标题:VisualAD: Language-Free Zero-Shot Anomaly Detection via Vision Transformer 作者:Yanning Hou, Peiyuan Li, Zirui Liu, Yitong Wang, Yanran Ruan, Jianfeng Qiu, Ke Xu(通讯作者) 机构:安徽大学人工智能学院、安徽大学光电信息获取与防护技术国家重点实验室、国防科技大学智能科学与技术学院 发表:CVPR 2026 代码:https://github.com/7HHHHH/VisualAD
一、文本编码器真的必要吗?一个反直觉的发现
现有零样本异常检测方法(AnomalyCLIP、WinCLIP、AdaCLIP 等)的标准范式是:用 CLIP 的文本编码器生成"正常"和"异常"的语义锚点,然后计算图像特征与这两个锚点的相似度来判断异常。
图片来源于原论文
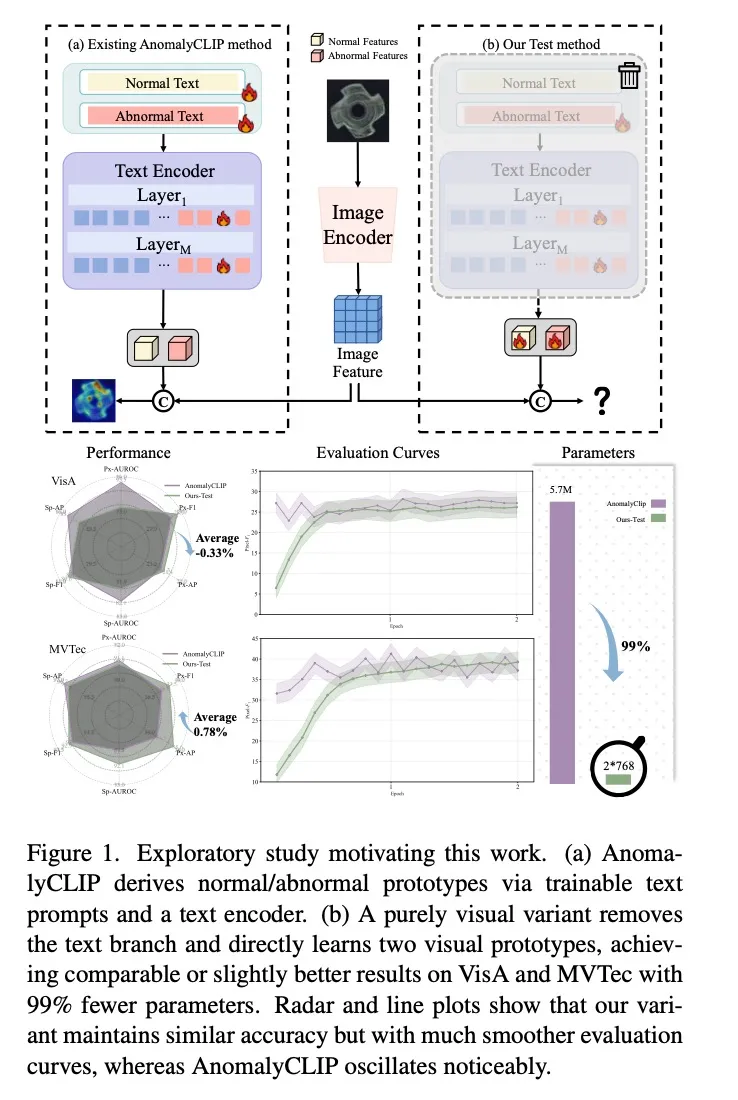
VisualAD 的作者首先做了一个探索性实验:把 AnomalyCLIP 的文本编码器完全去掉,只保留两组可学习的视觉向量(分别代表正常和异常),直接在视觉空间中做对比。结果发现:
- 性能几乎无损
- 可训练参数减少超过 99%
- 训练曲线更平滑,AnomalyCLIP 原版反而有"明显波动"
这个发现引出了核心问题:"如果最终决策只由两组潜在向量——正常和异常——控制,那么语言模态真的不可或缺吗?"
作者的回答是:不需要。异常本质上是纹理、形状、颜色的结构性/统计性偏差,这些信息完全可以在视觉域内捕获,不需要跨模态对齐。
二、两个 token + 两个模块:VisualAD 的极简架构
图片来源于原论文
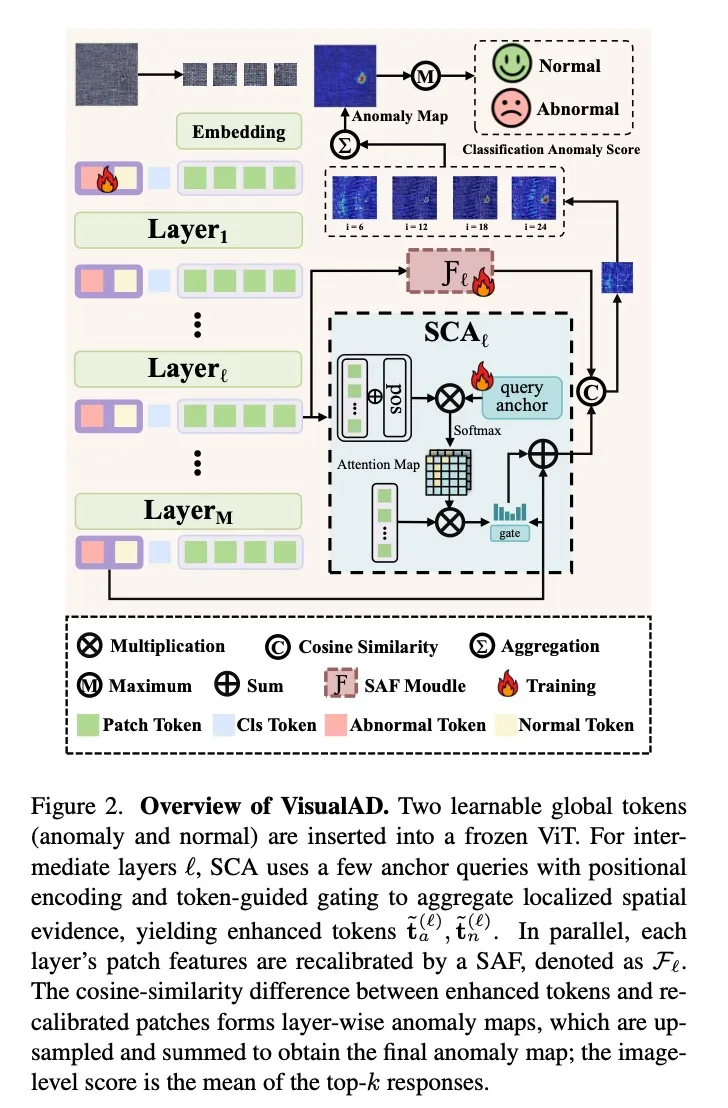
VisualAD 的架构非常简洁:
输入序列:在冻结 ViT 的输入中插入两个可学习 token:
- 异常 token(tₐ):编码"什么是异常"
- 正常 token(tₙ):编码"什么是正常"
这两个 token 与图像 patch token 一起经过 ViT 的多层自注意力,逐步获取高层次的正常/异常语义,同时引导 patch token 凸显异常相关的视觉线索。
但仅靠两个 token 和冻结 ViT 还不够——token 缺乏空间感知能力,patch 特征也没有经过异常检测的适配。因此引入两个轻量模块:
空间感知交叉注意力(SCA)
解决的问题:全局 token 需要"知道"空间信息才能定位异常。
做法:使用 4 个可学习的锚点查询(anchor queries),通过交叉注意力从带位置编码的 patch token 中提取空间信息,再通过 token 引导的门控机制注入到正常/异常 token 中。
消融实验显示,去掉 SCA 后图像级 AUROC 从 84.7% 暴跌至 50.5%(接近随机),说明空间感知是零样本异常检测的关键。
自对齐函数(SAF)
解决的问题:冻结 ViT 的 patch 特征没有为异常检测做过适配。
做法:每层加一个轻量 MLP(单隐层),重新校准 patch 特征。
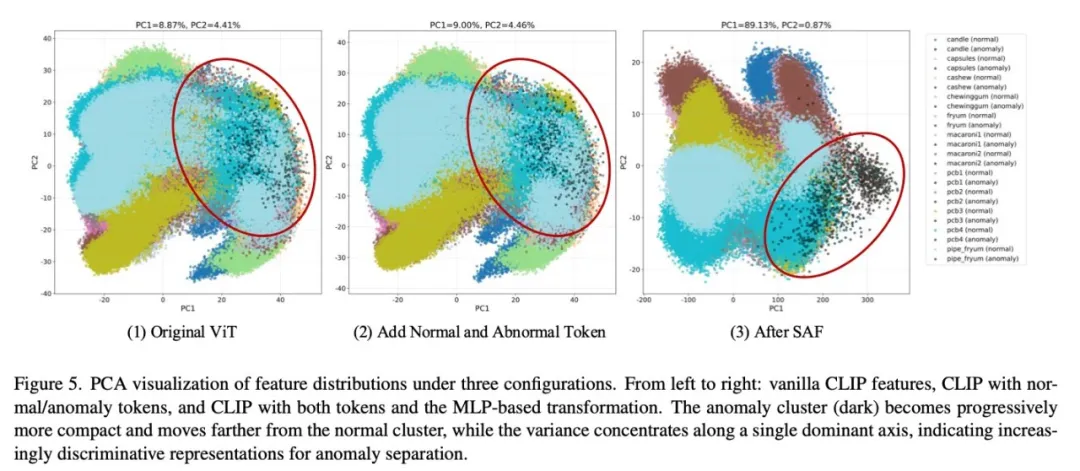
效果很直观:PCA 可视化显示,加 SAF 后第一主成分方差从 9.0% 提升到 89.1%,异常簇变得更紧凑,与正常簇的距离更远。
图片来源于原论文
异常评分
对 SAF 校准后的 patch 特征,计算其与异常 token 和正常 token 的余弦相似度之差作为逐像素异常分数。多层融合(从第 6、12、18、24 层提取),图像级分数取 top 1% 像素的均值。
三、13 个基准 SOTA:工业和医疗全覆盖
工业领域
数据集 | 指标 | VisualAD (CLIP) | AnomalyCLIP | AdaCLIP |
|---|---|---|---|---|
MVTec AD | 图像 AUROC | 92.2 | 91.6 | 92.0 |
MVTec AD | 像素 AUROC | 90.8 | 91.0 | — |
MVTec AD | 像素 F₁-max | 43.9 | 38.9 | — |
VisA | 图像 AUROC | 84.7 | 81.0 | 79.7 |
BTAD | 图像 AUROC | 94.9 | 88.7 | 90.0 |
KSDD2 | 图像 AUROC | 98.0 | 91.9 | 94.9 |
DAGM | 图像 AUROC | 99.5 | 98.0 | 98.3 |
在 VisA 上超 AnomalyCLIP 3.7 个百分点,BTAD 上超 6.2 个百分点,KSDD2 上超 6.1 个百分点——越是非 MVTec 的数据集,VisualAD 的优势越明显,说明纯视觉方法的泛化能力更强。
医疗领域
数据集 | 指标 | VisualAD (CLIP) | VisualAD (DINOv2) | AnomalyCLIP |
|---|---|---|---|---|
OCT17 | 图像 AUROC | 88.9 | 91.2 | 63.7 |
BrainMRI | 图像 AUROC | 96.7 | 93.8 | 96.4 |
OCT17 上 VisualAD (DINOv2) 超 AnomalyCLIP 27.5 个百分点,差距非常显著。
骨干网络灵活性
VisualAD 可以适配不同的视觉骨干:
- CLIP ViT-L/14@336px:图像级精度更强
- DINOv2 ViT-g/14:像素级定位更强(F₁-max 更高)
这意味着用户可以根据场景需求选择骨干——需要判断"有没有缺陷"用 CLIP,需要定位"缺陷在哪里"用 DINOv2。
四、消融实验:空间感知为什么是零样本异常检测的关键?
核心组件消融(VisA 数据集)
配置 | 图像 AUROC | 图像 AP |
|---|---|---|
完整 VisualAD | 84.7 | 87.6 |
去掉 SCA | 50.5 | 58.9 |
去掉 SAF | 82.3 | 85.4 |
两个都去掉 | 48.0 | 56.1 |
SCA 是命脉(去掉后接近随机),SAF 提供稳定的性能增益(+2.4 AUROC)。
锚点查询数量
锚点数 | 像素 F₁-max | 图像 AUROC |
|---|---|---|
1 | 33.3 | 84.7 |
4 | 34.6 | 84.7 |
16 | 33.5 | 84.9 |
32 | 32.4 | 84.5 |
4 个锚点是最佳平衡点,更多反而引入冗余。
层选择
层 | 像素 AUROC | 图像 AUROC |
|---|---|---|
{18} 单层 | 95.2 | 82.4 |
{6,12,18,24} 四层 | 95.8 | 84.7 |
多层融合捕获互补尺度的信息,四层组合效果最好。
五、总结与个人点评
VisualAD 的核心贡献:
- 范式转变:证明了零样本异常检测不需要文本编码器,纯视觉方法可以做到同等甚至更好的效果,且参数量减少 99%+
- 极简有效的架构:两个可学习 token + SCA + SAF,设计简洁,冻结骨干无需微调
- 跨域跨骨干通用性:在 13 个工业+医疗基准上 SOTA,支持 CLIP 和 DINOv2 两种骨干
- 实用指导:需要图像级判断选 CLIP 骨干,需要像素级定位选 DINOv2 骨干
值得关注的局限性:
- 方法仍需在一个工业数据集上做辅助训练(学习两个 token 和轻量模块),并非完全的"零训练"
- 作者提到未来方向包括自适应层选择、更细粒度的结构化 token、以及轻量不确定性估计来增强领域迁移的鲁棒性
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号