英伟达的AI帝国野心:Nemotron 3如何改写游戏规则



>一个能记住整座图书馆的AI代理,正在从科幻走进现实。
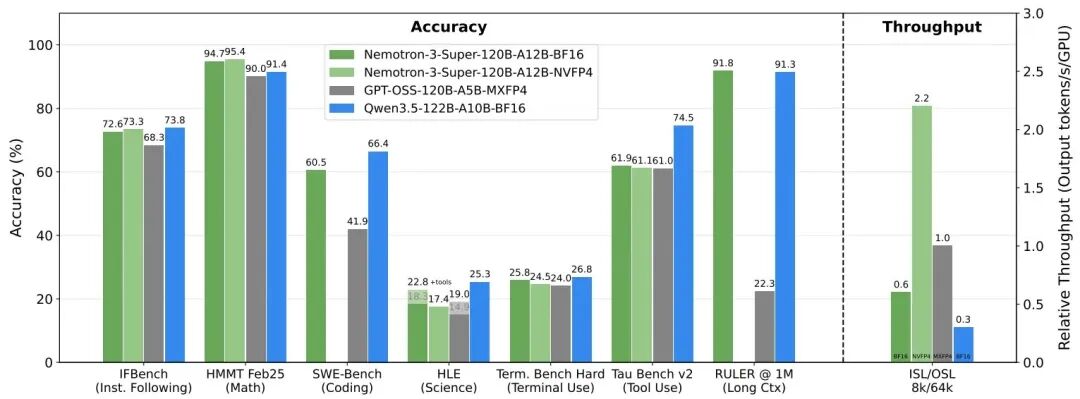
英伟达扔下了一颗重磅炸弹——Nemotron 3系列开源模型正式亮相。其为一款 1,200 亿参数开放模型,拥有 120 亿个活跃参数,旨在大规模运行复杂的代理式 AI 系统。
Nemotron 3 Nano,一款小型的 30-billion-parameter 模型,每次激活最多 30 亿参数,适用于针对性强、高度高效的任务。
Nemotron 3 Super,一款高准确性的推理模型,拥有约 1000 亿参数,每个 token 最多激活 100 亿参数,适用于多智能体应用。
Nemotron 3 Ultra 是一款拥有约 5000 亿参数和每 token 最多 500 亿活跃参数的大型推理引擎,适用于复杂的 AI 应用。其中最抢眼的Nemotron 3 Super,Nemotron 3 Super 采用了混合 MoE (mixture‑of‑experts) 架构,结合了三项主要创新,与之前的 Nemotron Super 模型相比,实现了高达 5 倍的吞吐量提升和高达 2 倍的准确率提升。
还直接把上下文窗口拉到了惊人的100万token,允许智能体在显存中保留完整的工作流状态,并防止目标偏离。。在PinchBench测试中拿下85.6%的高分,让它毫无悬念地坐上了全球开源推理模型的第一把交椅。
Nemotron 3 Super背后是英伟达未来五年260亿美元的生态投入计划。别被“开源”两个字骗了,这其实是它从GPU霸主向AI全栈控制者跃迁的关键一步。
为什么Agent系统一直卡在瓶颈?
过去几年,AI代理(Agent)听起来很酷,但实际用起来总差点意思。最常见的问题就是“健忘”——聊着聊着忘了你最初的要求,或者在多轮任务中突然断片儿。这不是模型笨,而是上下文长度不够用。
比如你想让一个Agent帮你分析三份财报并做横向对比,传统模型处理到第二份时可能就已经开始丢信息了。这就是所谓的“上下文漂移”。再加上多个Agent之间通信开销大、推理成本高,企业级部署迟迟难以落地。
Nemotron 3的出现,某种程度上就是来终结这些问题的。它的混合架构有点像“双核处理器”:一边是Mamba处理长序列数据如流水般顺畅,另一边是Transformer负责精细理解与推理,中间通过MoE路由动态分配任务。这种设计既保证了效率,又没牺牲精度
整套组合拳很多人只盯着Super版本看,但真正厉害的是整个产品矩阵的布局。英伟达这次玩的是阶梯式覆盖,从边缘设备到超算中心全都不放过。
目前Nemotron 3 Nano已经开放下载,300亿参数跑在移动端也绰绰有余,适合做轻量级客服机器人或个人助手。而接下来要推出的Super和Ultra,则会引入更激进的技术:
- ●Latent MoE
- :不再固定激活哪些专家网络,而是根据输入内容动态选择路径;
- ●多token预测(MTP):一次生成好几个token,响应速度直接起飞;
- ●NVFP4训练格式:基于Blackwell架构优化的4位浮点方案,内存占用砍掉一大半。
这种“先放小鱼,再钓大鲸”的策略很聪明——开发者现在就能上手试用Nano,等业务跑起来了,自然会被更高性能的版本吸引升级。
硬件+软件的闭环玩法
光有模型还不够。英伟达最狠的地方在于,它手里握着从芯片到框架的完整链条。
Nemotron 3是为Blackwell GPU架构量身定制的。配合新的NVFP4预训练格式,在
实测数据显示,Nemotron 3 Nano相比前代模型,每token生成成本最多降低了60%,吞吐量提升了整整4倍。对于企业来说,这不只是性能提升,而是商业模式的重构——原来只能服务几千用户的系统,现在能轻松撑起万级甚至更高嘞并发。
一位做AI基础设施的朋友说:“我们折腾了一年才把推理成本压下来30%,人家换个模型+新硬件,直接给你干掉60%。”
开源背后的生态野心
很多人以为开源就是“免费送”,但在英伟达这儿,开源更像是播种机。
这次一起放出的还有:
- ●一个3万亿token的数据集,涵盖网页、代码、论文、对话记录;
- ●Nemo Gym,标准化的Agent训练环境;
- ●Nemo RL,强化学习微调工具包。
所有这些都托管在GitHub和Hugging Face上,连部署都能通过NVIDIA NIM微服务一键完成。你现在不需要买任何硬件,就能在AWS Bedrock或者BaseTen上调用高性能推理服务。
这套“模型+数据+工具+平台”的组合拳,明显是在复制CUDA当年的成功路径。只不过这一次的目标不再是训练市场,而是未来的Agent应用生态。
谁才是真正的大玩家?
十年前,英伟达靠CUDA锁死了AI训练时代的开发者。今天,它想用Nemotron+Blackwell+NIM再演一遍历史。
它的战略很清晰:
- 1拿出真金白银——推自己的标准成为事实标准——让Nemotron逐步替代Llama、Mixtral这些第三方模型;
- 2打造“开源+闭源”混合推理模式——简单任务走低成本开源模型,核心逻辑仍由专有系统处理。
说白了,它不想再只卖“铲子”了,而是要当淘金热里的土地开发商。
业内有人评价:“英伟达早就不是显卡公司了,它正在变成AI世界的操作系统。” 这话听着夸张,但看看现在的布局,还真不是瞎吹。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号