TrendRadar:重新定义你的信息获取方式——一个开源热点追踪系统的完整指南

TrendRadar:重新定义你的信息获取方式——一个开源热点追踪系统的完整指南

山行AI
发布于 2026-03-13 18:36:05
发布于 2026-03-13 18:36:05
🌐 引言:在信息洪流中找回主动权
每天早晨,当你打开手机,是否曾被几十个未读推送淹没?微博热搜、知乎热榜、抖音热点、财经快讯...我们生活在信息过剩的时代,却常常感到真正有价值的内容正在与我们擦肩而过。算法推荐让我们越来越沉浸于自己感兴趣的“信息茧房”,而主动获取多元化信息的能力却在退化。
这就是 TrendRadar 诞生的背景——一个旨在帮助用户从被动接收转向主动筛选的开源热点追踪系统。它不是一个简单的新闻聚合器,而是一套完整的解决方案,让你能够:
•定制专属信息流:只关注真正关心的领域•掌握热点演变规律:不仅知道“什么在火”,更了解“为什么火”和“如何演变”•跨平台统一管理:告别在十几个App间来回切换的繁琐•智能分析预测:利用AI技术洞察趋势背后的规律
本文将全面解析TrendRadar的设计理念、核心功能、部署方法以及高级应用场景,带你深入了解这个在GitHub上获得大量关注的开源项目。
第一章:TrendRadar是什么?——重新定义热点追踪
1.1 项目定位:不只是新闻聚合器
TrendRadar的官方介绍是“最快30秒部署的热点助手”,但这只是它最表面的特性。深入来看,它是一个高度可定制化的信息过滤与管理系统,核心价值体现在三个层面:
技术层面:基于Python构建的自动化爬虫系统,支持多平台数据采集、智能过滤和实时推送。
用户体验层面:提供从简单到复杂的多种使用模式,满足不同技术背景用户的需求。
信息管理层面:不仅收集信息,更对信息进行结构化处理和趋势分析,提供洞察而不仅仅是数据。
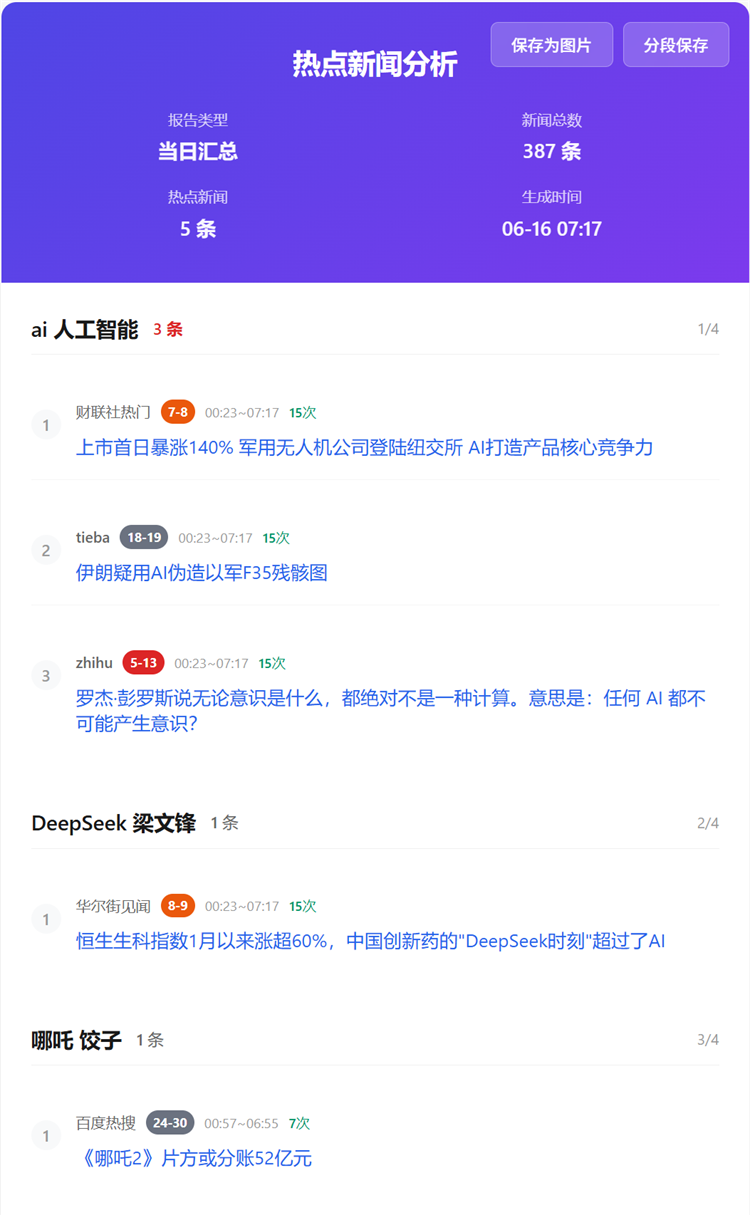
Github Pages效果
1.2 核心设计哲学
TrendRadar的设计遵循几个关键原则:
用户主权原则:用户完全控制接收什么信息、何时接收、以何种方式接收。这与主流社交平台的算法推荐形成鲜明对比。
信息最小化原则:默认情况下,系统会尽可能过滤无关信息,只传递用户明确关心的内容。这与“越多越好”的信息流设计相反。
渐进式复杂度:用户可以从最简单的“一键部署”开始,随着需求增长逐步使用更复杂的功能,学习曲线平缓。
隐私优先:所有配置和数据处理都可以在用户完全控制的环境中进行,无需将敏感信息委托给第三方服务。
第二章:核心功能深度解析
2.1 全网热点聚合:不只是简单的爬虫
TrendRadar目前支持11个主流平台的热点监控:
•社交平台:微博、知乎、抖音、贴吧•视频平台:bilibili热搜•新闻资讯:今日头条、澎湃新闻、凤凰网•财经专业:华尔街见闻、财联社热门•搜索引擎:百度热搜
技术实现特点:
每个平台的采集器都经过专门优化,处理各自的反爬机制和数据格式。系统不是简单抓取网页,而是理解每个平台的数据结构,提取标准化的热点信息(标题、热度值、排名、更新时间等)。
可扩展性:
系统采用模块化设计,新增平台只需实现标准的采集接口。项目已经预留了扩展机制,社区用户也可以贡献新平台的采集模块。
2.2 智能推送策略:三种模式的科学设计
TrendRadar的推送系统是其最精妙的设计之一,提供三种不同哲学的模式:
2.2.1 当日汇总模式(daily)
•适用人群:管理者、研究人员、需要完整记录的用户•工作逻辑:每次推送都会包含当天所有匹配的新闻,无论之前是否已经推送过•使用场景:每天下午6点查看全天热点汇总报告;项目复盘时查看完整时间线•优点:信息完整,不会遗漏任何相关内容•缺点:可能存在重复信息
2.2.2 当前榜单模式(current)
•适用人群:自媒体从业者、市场营销人员、需要实时了解排名的用户•工作逻辑:每次只推送当前时间点榜单上的匹配新闻•使用场景:监控某个话题的实时排名变化;追踪热点话题的生命周期•优点:反映实时状态,适合追踪动态变化•缺点:持续在榜的话题会重复出现
2.2.3 增量监控模式(incremental)
•适用人群:投资者、交易员、讨厌重复信息的用户•工作逻辑:只推送新出现的匹配新闻,之前推送过的绝不会再次出现•使用场景:监控突发新闻;追踪新出现的行业动态;避免信息打扰•优点:零重复,信息密度高•缺点:可能错过持续在榜话题的热度变化
科学的选择建议:
使用场景 | 推荐模式 | 理由 |
|---|---|---|
股市投资监控 | incremental | 只关心新出现的利好/利空消息 |
品牌舆情管理 | current | 需要实时了解品牌话题的排名变化 |
学术研究 | daily | 需要完整的时间序列数据 |
日常生活 | current或daily | 根据对重复信息的容忍度选择 |
2.3 精准内容筛选:从基础到高级的语法系统
TrendRadar的内容筛选系统支持多级语法,用户可以根据需要灵活组合:
基础语法层:
•普通关键词:华为 - 标题包含该词即匹配•必须词(+前缀):+手机 - 必须同时包含该词•过滤词(!前缀):!广告 - 包含该词则排除•数量限制(@数字):@10 - 最多显示10条(v3.2.0新增)
高级配置层:
•排序优先级:可按热度排序或按配置顺序排序•全局数量限制:统一限制所有关键词的显示数量•词组化组织:用空行分隔不同主题的词组
实际配置示例:
# 科技投资组
人工智能
AI
ChatGPT
+技术
!培训
@15
# 新能源汽车组
特斯拉
比亚迪
蔚来
+股价
!传闻
@10
# 政策动态组
证监会
央行
+政策
!解读这个配置表示:
1.监控人工智能领域的技术进展,排除培训广告,最多显示15条2.关注新能源汽车股价变动,排除市场传闻,最多显示10条3.追踪证监会和央行的政策发布,排除第三方解读
2.4 热点趋势分析:超越表面的数据洞察
TrendRadar的热点分析不仅仅是收集数据,更重要的是理解数据背后的模式:
时间维度分析:
•首次出现时间:记录热点首次被发现的时间点•持续时间跨度:热点在榜的总时长•出现频次统计:在监控周期内出现的次数•排名变化轨迹:热点的排名如何随时间变化
跨平台对比: 同一热点在不同平台的表现差异可以揭示重要信息:
•微博热搜第一 + 知乎热榜前十 = 大众关注度高•华尔街见闻热门 + 微博未上榜 = 专业领域关注•所有平台同时出现 = 全民级热点事件
智能标记系统:
•🆕 标记:本轮新出现的热点•🔥 标记:高热度话题(匹配≥10条)•📈 标记:中热度话题(匹配5-9条)•📌 标记:低热度话题(匹配<5条)
2.5 个性化热点算法:重新定义“重要性”
传统的热点榜单往往只考虑单一维度(如搜索量、互动量),TrendRadar采用多维加权算法:
算法公式:
综合得分= rank_weight ×排名分数+ frequency_weight ×频次分数+ hotness_weight ×热度分数默认权重配置:
•排名权重(60%):看重高排名热点•频次权重(30%):看重持续出现的稳定性•热度权重(10%):考虑绝对热度值
可调整场景:
•追热点型:rank_weight=0.8, frequency_weight=0.1, hotness_weight=0.1•深度分析型:rank_weight=0.4, frequency_weight=0.5, hotness_weight=0.1
2.6 多渠道推送:适应不同使用习惯
TrendRadar支持9种推送方式,覆盖几乎所有主流通讯场景:
企业级应用:
•企业微信:适合工作场景,支持富文本格式•飞书:界面友好,交互体验佳•钉钉:国内企业广泛使用•Slack:国际团队协作标准
个人通讯:
•Telegram:技术爱好者首选,推送容量大•个人微信:通过企业微信应用间接推送•邮件:适合归档和深度阅读
轻量级方案:
•ntfy:开源推送服务,支持自托管•Bark:iOS专属,简洁高效
推送容量对比:
平台 | 单条消息限制 | 分批支持 | 推荐用途 |
|---|---|---|---|
企业微信 | 2048字 | ✅ | 日常工作通知 |
Telegram | 4096字 | ✅ | 技术爱好者首选 |
飞书 | 约1500字 | ✅ | 团队协作 |
钉钉 | 约5000字 | ✅ | 企业环境 |
邮件 | 几乎无限 | ❌ | 完整报告归档 |
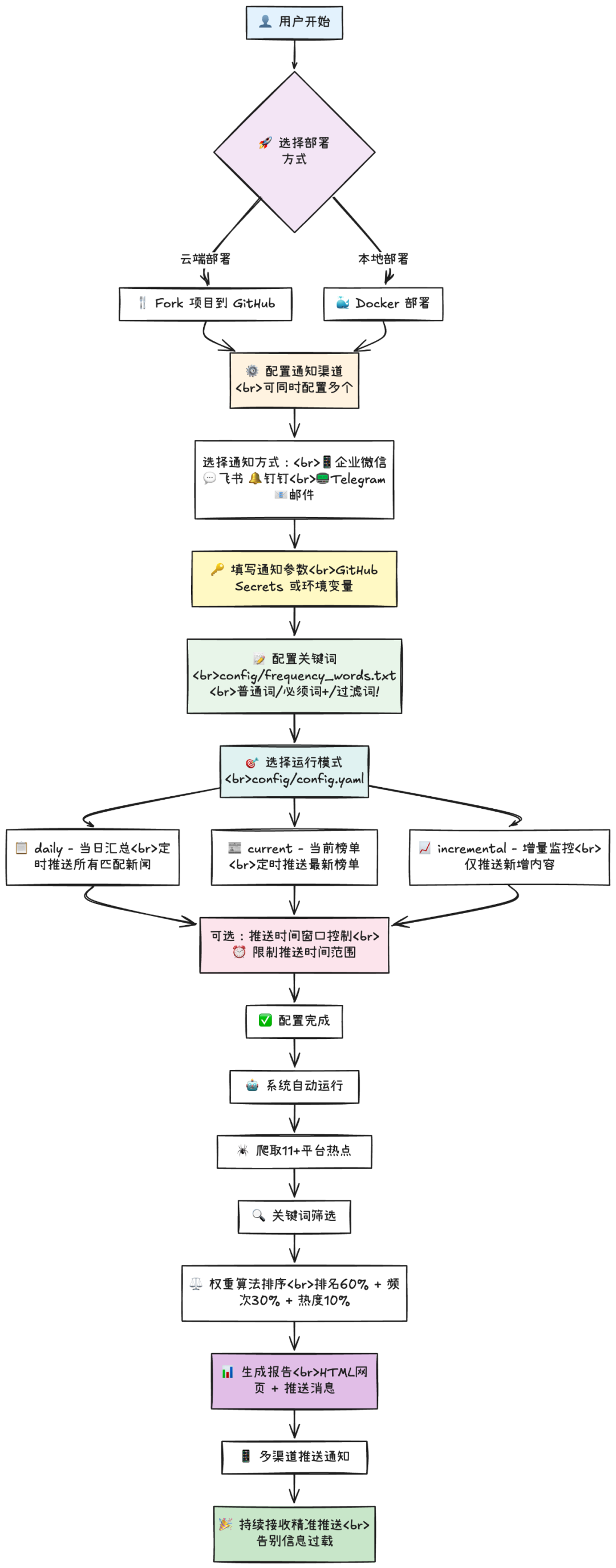
第三章:部署指南——从零到一的完整路径
3.1 最简单的开始:GitHub Fork + Actions
对于大多数用户,这是最推荐的方式:
步骤分解:
1.Fork项目(30秒)•访问 https://github.com/sansan0/TrendRadar•点击右上角“Fork”按钮•等待几秒钟完成复制2.配置推送渠道(2-5分钟)•进入你的Fork仓库 → Settings → Secrets and variables → Actions•点击“New repository secret”•根据选择的平台添加对应配置配置示例(企业微信):•Name: WEWORK_WEBHOOK_URL•Secret: https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=你的密钥3.手动测试(1分钟)•进入Actions页面•找到“Hot News Crawler”工作流•点击“Run workflow”手动触发•等待运行完成,查看手机是否收到测试消息4.调整运行频率(可选)•默认配置为每小时运行一次•可在.github/workflows/crawler.yml中修改cron表达式•建议从低频开始,根据需要调整
技术原理: 这种方式利用GitHub提供的免费计算资源(每月2000分钟)和存储空间,无需自己维护服务器。所有数据都存储在你的仓库中,完全可控。
3.2 Docker部署:完全自主控制
对于有服务器资源或需要完全私有化部署的用户:
环境准备:
# 1. 安装Docker和Docker Compose
# 2. 创建项目目录
mkdir trendradar && cd trendradar
mkdir -p config output配置文件准备:
# 下载配置文件模板
wget https://raw.githubusercontent.com/sansan0/TrendRadar/master/config/config.yaml -P config/
wget https://raw.githubusercontent.com/sansan0/TrendRadar/master/config/frequency_words.txt -P config/
wget https://raw.githubusercontent.com/sansan0/TrendRadar/master/docker/docker-compose.yml
wget https://raw.githubusercontent.com/sansan0/TrendRadar/master/docker/.env.example -O .env环境变量配置(.env文件):
# 基本配置
RUN_MODE=cron
CRON_SCHEDULE=*/30****
IMMEDIATE_RUN=true
# 推送配置(根据实际需要填写)
FEISHU_WEBHOOK_URL=https://open.feishu.cn/open-apis/bot/v2/hook/xxx
WEWORK_WEBHOOK_URL=https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxx
# ... 其他推送配置启动服务:
# 启动容器
docker-compose up -d
# 查看日志
docker-compose logs -f
# 管理命令
docker-compose ps # 查看状态
docker-compose restart # 重启
docker-compose down # 停止数据持久化: 所有生成的数据都保存在output目录中:
•news/:原始新闻数据,按日期组织•reports/:生成的HTML报告•logs/:运行日志
3.3 本地Python环境部署:开发者模式
适合需要二次开发或深度定制的用户:
环境准备:
# 克隆项目
git clone https://github.com/sansan0/TrendRadar.git
cd TrendRadar
# 创建虚拟环境
python -m venv venv
source venv/bin/activate # Linux/Mac
# 或 venv\Scripts\activate # Windows
# 安装依赖
pip install -r requirements.txt配置文件调整:
# config/config.yaml 关键配置说明
crawler:
enable_crawler:true# 启用爬虫
request_timeout:30# 请求超时时间
max_retries:3# 最大重试次数
report:
mode:"current"# 报告模式:daily/current/incremental
sort_by_position_first:false# 排序方式
max_news_per_keyword:0# 每个关键词最大新闻数(0=无限制)
notification:
enable_notification:true# 启用通知
push_window:# 推送时间窗口
enabled:false# 是否启用时间窗口
time_range:
start:"09:00"# 开始时间
end:"18:00"# 结束时间运行测试:
# 单次运行测试
python main.py
# 定时运行(Linux/Mac crontab示例)
*/30 * * * * cd /path/to/TrendRadar&&/path/to/venv/bin/python main.py第四章:高级功能与AI集成
4.1 MCP协议与AI智能分析
TrendRadar v3.0.0引入的MCP(Model Context Protocol)支持是项目的重大升级,将简单的数据收集转变为智能数据分析平台。
MCP是什么? MCP是Anthropic提出的标准协议,允许AI模型安全地访问外部工具和数据。TrendRadar实现MCP服务器后,各种AI助手可以直接查询和分析新闻数据。
支持的AI客户端:
•Claude Desktop(官方支持)•Cursor(AI代码编辑器)•Cherry Studio(图形化配置工具)•任何支持MCP协议的客户端
可用的分析工具: TrendRadar MCP服务器提供13种分析工具:
1.基础查询工具:•get_latest_news:获取最新新闻•get_news_by_date:按日期查询新闻•get_trending_topics:获取热门话题2.智能检索工具:•search_news:关键词搜索新闻•search_related_news_history:搜索相关历史新闻3.高级分析工具:•analyze_topic_trend:分析话题趋势•analyze_data_insights:数据洞察分析•analyze_sentiment:情感分析•find_similar_news:查找相似新闻•generate_summary_report:生成摘要报告4.系统管理工具:•get_current_config:获取当前配置•get_system_status:获取系统状态•trigger_crawl:触发爬取任务
实际使用示例:
与AI的自然语言对话:
用户:分析一下最近一周"人工智能"话题的热度趋势
AI:调用 analyze_topic_trend("人工智能", days=7)
用户:对比知乎和微博对"新能源汽车"的关注度差异
AI:调用 analyze_data_insights("新能源汽车", platforms=["zhihu","weibo"])
用户:生成昨天热点新闻的摘要报告
AI:调用 generate_summary_report(date="2025-01-15")4.2 数据持久化与历史分析
TrendRadar不仅关注实时数据,更重视历史数据的积累和分析:
数据结构设计:
output/
├── news/# 原始新闻数据
│├──2025-01/
││├──2025-01-15.json
││└──2025-01-16.json
│└──2025-02/
├── reports/# 生成报告
│├── html/
││├──2025-01-15.html
││└──2025-01-16.html
│└── txt/
└── logs/# 运行日志历史数据分析价值:
1.趋势预测:基于历史模式预测热点生命周期2.事件回溯:重大事件发生时的舆论反应分析3.季节性规律:某些话题的季节性变化规律4.平台差异研究:不同平台用户的关注偏好差异
4.3 自定义扩展与二次开发
TrendRadar采用模块化设计,方便用户进行自定义扩展:
新增平台支持:
# 在适当位置添加新的平台采集器
classNewPlatformCollector:
def fetch_hotspots(self):
# 实现数据采集逻辑
pass
def parse_content(self, raw_data):
# 实现数据解析逻辑
pass自定义处理管道: 系统处理流程清晰,可以在任意环节插入自定义逻辑:
数据采集→数据清洗→关键词匹配→权重计算→报告生成→通知推送
↑↑↑↑↑
可插入可插入可插入可插入可插入
自定义清洗自定义匹配自定义算法自定义格式自定义渠道API接口: 对于开发者,还可以将TrendRadar作为后端服务,通过API提供数据:
from flask importFlask, jsonify
from trendradar.core importNewsAnalyzer
app =Flask(__name__)
analyzer =NewsAnalyzer()
@app.route('/api/hotspots/<date>')
def get_hotspots(date):
data = analyzer.get_hotspots_by_date(date)
return jsonify(data)第五章:应用场景与实践案例
5.1 个人用户:信息过载的解决方案
典型用户画像:
•张先生,35岁,金融从业者•每天需要关注股市动态、行业政策、宏观经济•之前需要在10+个App间切换,花费大量时间
TrendRadar配置方案:
# frequency_words.txt 配置
证监会政策
央行公告
美联储
+利率
!分析报告
A股
港股
美股
+大盘
!个股分析
人工智能
新能源
芯片半导体
+产业政策使用效果:
•每天接收3-4次推送,每次阅读时间5分钟•重要政策发布后10分钟内收到通知•周末和晚间自动静默,不被信息打扰•月度自动生成热点报告,用于投资复盘
5.2 企业应用:品牌舆情监控
典型场景:
•某科技公司市场部需要监控品牌声量•关注产品发布后的市场反馈•及时发现并处理负面舆情
企业级部署方案:
# Docker集群部署
version:'3.8'
services:
trendradar:
image: wantcat/trendradar:latest
deploy:
replicas:3
environment:
- MODE=incremental
- KEYWORDS=公司名,产品名,CEO名+负面
volumes:
-./data:/app/output
# 添加告警集成
alert-manager:
image: prometheus/alertmanager
# 配置告警规则,当负面舆情超过阈值时触发工作流集成:
1.TrendRadar发现负面舆情2.自动生成告警,发送到企业微信危机处理群3.触发CRM系统创建客户服务工单4.同步到舆情分析平台进行深度分析
5.3 媒体与内容创作:热点发现与追踪
自媒体运营者需求:
•及时发现热点话题•追踪话题演变过程•分析受众关注点变化
创作支持功能:
1.热点预警系统:话题热度快速上升时提前预警2.角度发现工具:分析同一话题的不同讨论角度3.时效性评估:判断话题是否还有创作价值4.竞品分析:监控同类账号的内容表现
实际工作流:
上午9:00:接收当日热点简报
上午10:00:发现"人工智能教育"话题快速升温
上午10:30:分析各平台讨论角度差异
上午11:00:确定创作角度"AI如何个性化教育"
下午2:00:完成内容创作并发布
下午4:00:监控内容传播效果第六章:技术架构与设计理念
6.1 系统架构设计
┌─────────────────────────────────────────────────────┐
│用户界面层│
├─────────────────────────────────────────────────────┤
│Web界面移动推送邮件报告 API接口命令行│
└─────────────────────────────────────────────────────┘
│
┌─────────────────────────────────────────────────────┐
│业务逻辑层│
├─────────────────────────────────────────────────────┤
│热点采集│内容过滤│趋势分析│报告生成│
└─────────────────────────────────────────────────────┘
│
┌─────────────────────────────────────────────────────┐
│数据处理层│
├─────────────────────────────────────────────────────┤
│数据清洗│关键词匹配│权重计算│持久化│
└─────────────────────────────────────────────────────┘
│
┌─────────────────────────────────────────────────────┐
│数据源层│
├─────────────────────────────────────────────────────┤
│微博API 知乎爬虫头条接口...自定义源│
└─────────────────────────────────────────────────────┘6.2 关键技术创新
1. 智能重试机制:
classSmartRetry:
def __init__(self, max_retries=3, backoff_factor=1.5):
self.max_retries = max_retries
self.backoff_factor = backoff_factor
def fetch_with_retry(self, url):
for attempt in range(self.max_retries):
try:
response =self._fetch(url)
returnself._parse(response)
exceptExceptionas e:
if attempt ==self.max_retries -1:
raise
wait_time =self.backoff_factor ** attempt
time.sleep(wait_time)2. 增量识别算法: 系统使用哈希算法识别内容相似度,避免重复推送:
def is_new_content(content, history_set):
# 生成内容指纹
fingerprint = generate_fingerprint(content)
# 检查是否已存在
if fingerprint in history_set:
returnFalse
# 添加到历史记录
history_set.add(fingerprint)
returnTrue3. 自适应推送策略: 根据用户反馈动态调整推送策略:
classAdaptivePushStrategy:
def adjust_frequency(self, user_feedback):
# 分析用户打开率、阅读时长等指标
engagement_rate =self.calculate_engagement()
if engagement_rate <0.3:# 参与度低
returnself.decrease_frequency()
elif engagement_rate >0.7:# 参与度高
returnself.increase_frequency()
else:
returnself.maintain_frequency()6.3 性能优化策略
1. 缓存机制:
•热点数据缓存:减少对数据源的频繁请求•配置缓存:避免每次读取配置文件•模板缓存:加速报告生成过程
2. 异步处理:
import asyncio
from concurrent.futures importThreadPoolExecutor
async def fetch_all_platforms(platforms):
async withThreadPoolExecutor(max_workers=5)as executor:
tasks =[]
for platform in platforms:
task = asyncio.create_task(
fetch_platform_data(platform)
)
tasks.append(task)
results = await asyncio.gather(*tasks)
return results3. 内存管理:
•分批处理大数据集•及时释放不需要的资源•使用生成器减少内存占用
第七章:社区生态与未来发展
7.1 开源社区贡献
TrendRadar采用GPL-3.0开源协议,鼓励社区参与:
贡献方式:
1.代码贡献:修复bug、增加新功能、优化性能2.文档贡献:完善使用文档、翻译多语言版本3.平台扩展:增加新的数据源支持4.问题反馈:提交Issue报告问题或建议功能
社区成果:
•73位贡献者进入致谢名单•收集了数百个问题反馈和改进建议•社区用户贡献了多个平台采集器•形成了活跃的用户交流群
7.2 项目路线图
短期计划(未来3个月):
1.增加更多国际平台支持(Twitter、Reddit等)2.优化移动端使用体验3.增加数据可视化仪表板4.完善API文档和开发者指南
中期计划(未来6-12个月):
1.引入机器学习模型进行热点预测2.开发浏览器插件版本3.建立热点知识图谱4.支持多用户协作功能
长期愿景:
1.构建去中心化的热点数据网络2.开发基于区块链的数据验证机制3.创建热点分析的标准协议4.培养数据素养的教育工具
7.3 商业化可能性
虽然TrendRadar是完全开源免费的,但围绕它可以构建多种商业模式:
企业版服务:
•私有化部署支持•定制化功能开发•专业技术支持•数据归档与审计
数据服务:
•历史热点数据API•行业分析报告•舆情监控服务•趋势预测模型
生态合作:
•与媒体机构合作内容发现•与学术机构合作研究项目•与投资机构合作数据服务•与教育机构合作课程开发
第八章:使用建议与最佳实践
8.1 新手上路指南
第一周:简单开始
1.使用GitHub Fork方式部署2.只配置1-2个最关心的关键词3.选择一种推送方式(推荐企业微信)4.使用默认配置,每小时接收一次
第二周:逐步优化
1.根据实际需求调整推送频率2.细化关键词配置3.尝试不同的推送模式4.探索网页报告功能
第三周:深度使用
1.配置多个关键词组2.使用高级语法进行精准过滤3.尝试AI分析功能4.探索历史数据分析
8.2 常见问题解决
问题1:收不到推送
•检查GitHub Actions是否运行成功•验证Webhook配置是否正确•查看运行日志寻找错误信息•确保关键词配置不为空
问题2:推送内容太多
•增加过滤词排除无关内容•使用@数字限制单次推送数量•切换到incremental模式减少重复•减少监控平台数量
问题3:推送内容太少
•检查关键词是否过于具体•增加相关关键词的变体•增加监控平台数量•检查平台是否正常获取数据
问题4:数据更新延迟
•检查cron表达式是否正确•查看网络连接是否正常•确认数据源API是否稳定•考虑增加采集频率
8.3 高级配置技巧
1. 智能时间窗口配置:
notification:
push_window:
enabled:true
time_range:
start:"09:00"
end:"18:00"
only_once_per_day:false# 窗口内可多次推送
weekday_only:true# 仅工作日推送2. 多环境配置管理:
# 开发环境配置
cp config/config.yaml config/config.dev.yaml
# 生产环境配置
cp config/config.yaml config/config.prod.yaml
# 根据环境选择配置
export TRENDRADAR_ENV=prod
python main.py --config config/config.${TRENDRADAR_ENV}.yaml3. 自动化测试配置:
# tests/test_config.py
def test_keyword_matching():
config = load_config("config/test_config.yaml")
analyzer =NewsAnalyzer(config)
# 测试关键词匹配
test_news =["苹果发布新手机","水果苹果很新鲜"]
results = analyzer.filter_by_keywords(test_news)
assert len(results)==1# 只应该匹配第一条
assert"苹果发布新手机"in results结语:重新掌控你的信息世界
在信息爆炸的时代,我们面临着两个极端:一方面是信息过载带来的焦虑和低效,另一方面是信息茧房带来的狭隘和偏见。TrendRadar试图在这两个极端之间找到平衡点——既不让你被无关信息淹没,也不让你局限于单一视角。
这个项目的真正价值不在于技术本身有多复杂,而在于它将信息选择的权力交还给用户。通过TrendRadar,你可以:
1.定义自己的信息优先级:而不是被平台的算法定义2.建立系统的信息收集习惯:而不是碎片化的随机浏览3.培养数据驱动的决策能力:而不是凭感觉或随大流4.保持对世界的开放认知:同时避免被无效信息消耗
TrendRadar仍然在快速发展中,每个版本都在增加新功能、优化用户体验、扩展应用场景。无论你是普通用户、内容创作者、企业管理者还是技术开发者,都能在这个项目中找到适合自己的价值点。
最重要的是,它是一个开源项目——这意味着你可以完全控制自己的数据,根据自己的需求进行定制,甚至参与改进让它变得更好。在这个数据日益被巨头垄断的时代,能够拥有对自己信息的完全控制权,本身就是一种珍贵的能力。
开始使用TrendRadar,不仅仅是用了一个新工具,更是开启了一种新的信息生活方式。
完整流程:
免责声明
TrendRadar是一个开源项目,使用者需遵守各数据源平台的Robots协议和相关法律法规。项目开发者不对因使用本项目产生的任何直接或间接损失负责。请合理使用,尊重数据来源,勿进行过度频繁的请求。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号