降本增效与灾难切换

降本增效与灾难切换

SRE运维实践
发布于 2026-03-13 15:56:14
发布于 2026-03-13 15:56:14
序言
容器的流行,让降本增效到了一个新的高度,看看对应的历史的发展,最早的时候是物理机,然后是虚拟机,现在是容器,从而出现了调度集群的k8s,每一步都是为了增高cpu使用率,又要隔离,又要混合部署,流行必然有其原因,也必然有其优势。
降本增效很多情况下和稳定性是冲突的,降本嘛,既要成本,又要质量,左手打右手的区别,俗称左右互搏。就像别人说的,老婆和老妈掉水了,你救谁?每一次的抉择,代表了企业到了个什么程度,如果开始降本增效了,那离倒闭还有多久?
权衡
1 故障切换失败
为了稳定性的目标,我们会有各种双活切换方案,在关键时刻,一键切换,故障恢复。
在某个月黑风高的夜晚,告警系统发出了很多告警,单可用区不可用,业务有损,从而执行切换可用区方案,执行之后,流量掉0,系统扛不住这么高的流量,直接出现雪崩,而且在这关键时刻,底层的CA机制有问题,无法扩容底层机器。
每次因为容量不足的故障之后,就会掀起一阵风,那是扩容的风声,大量系统开始进行扩容,规划的容量要是高峰期业务的流量的两倍。
每几个月,当没有大故障产生的时候,降本增效就开始了,各种缩容,cpu的使用率必须要达到多少。
一个成熟的系统,哪有那么多的容量来进行缩容呢?如果能够缩容,那说明并不是核心系统,而核心系统,也会在成本的压力下,进行大幅度缩容,看看成本把孩子逼成什么样了。
稳定性重要?还是成本更重要?业务高速发展的时候,正经人谁去考虑成本?权衡。。。只有出现大故障的时候,才会考虑到稳定性,否则也就是成本优先。但是每次出故障,成本的人从来不扛锅,只有功,还是挺棒的。
2 k8s集群中的降本方案
在业务上容器方案,也就意味着能混合使用了,从而也就有了降本的可能,云都提供了一个功能,那就是pod的hpa方案,当pod的cpu使用率高于或者低于多少的时候,就开始自动扩容缩容,而对于底层的node,那么方案就是开启CA,集群的自动扩容缩容,再也不用人工去扩容了。
云,在这个场景中,就变成了一个依赖了,依赖公有云的售卖的机器中,有足够的机器能充当CA的池子,别扩容扩容就机器没了,再也买不出新的机器了,而这也是经常出现问题的地方,也就是机型的机器不足,买不出来了,这其实也是产生故障的原因,自动扩缩容,业务高峰,自动加机器,业务低峰,自动退机器,成本最大收益化,从而每个机器的cpu使用率都很足。
如果你开启了CA,你还能规划容量吗,其实也能,保留基础资源的使用,设置最小数量,但是肯定不能满足高峰期的使用,如果是你你如何来解?
3 k8s集群的架构
在使用云的时候,一般都是选择一个数据中心,然后有三个可用区,而这个地方就可以进行设置高可用的集群架构了。
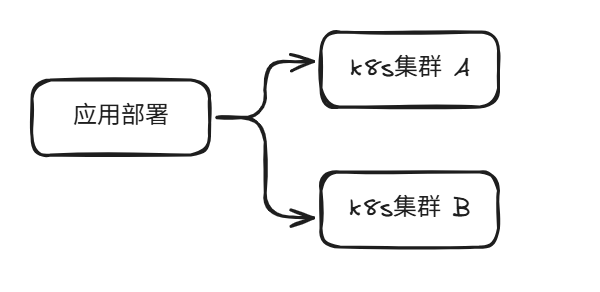
在创建k8s集群的时候,直接进行分可用区创建2个集群,应用部署的时候,同时部署在2个k8s集群中,从而直接使用双活的架构,当出现单可用区故障的时候,可以进行切换可用区,你说怎么切换可用区?要么使用DNS解析来切换入口流量,或者使用LB来切换可用区流量,如果是微服务架构,那么只要在注册中心来区分不同可用区的服务就可以了,但是客户端要支持可用区切换的,注册中心,你值得拥有。
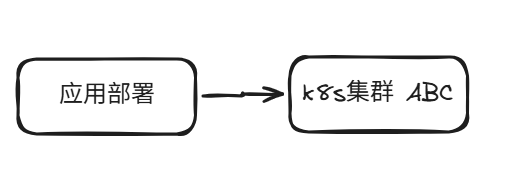
还有一种方案,就是创建k8s集群的时候,只创建一个,但是里面的机器是分布在不同的可用区的,可以有A可用区,也可以有B可用区,也可以有C可用区,这种方案的好处是应用部署只要部署一次即可,当某个可用区有问题之后,pod会自动调度到好的可用区里面去,这种方案运维其实蛮简单的,毕竟只有一个集群需要运维,而且有问题会自动好,基本上也不用切换,但是这种集群的坏处就是,如果这个k8s集群挂了,所有业务全嘎,你完全没有手段进行容灾,灾难发生的时候,只能烧香拜佛了。
在评估一种架构方案的时候,要看故障的时候,我们有没有应急手段,手段是否能生效。所谓的狡兔三窟,也是从此可以看到对应的设计。
4 如何解决机器买不出来的问题
在一个k8s集群中,可以划分很多节点池,设置对应label或者是污点,从而能对业务进行精细化的调控,大致架构如下
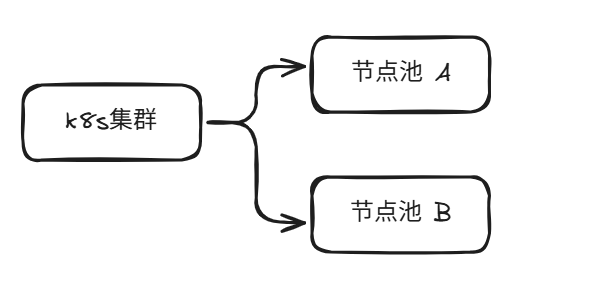
为什么要用不同的节点池呢?所谓的节点池就是相同硬件架构,相同的操作系统,相同的kublet的设置,相同的网络策略,主要的目的其实就是隔离故障,精细化的管理,例如不同的业务需要用不同的安全组,不同的业务的node上面支持不同的pod数量。
节点池为什么能解决机器买不出来的问题,主要在于节点池支持不同的硬件架构,从而可以节点池A是某种机型的机器,节点池B是某种机型的机器,就不信在故障的时候,所有的机器都买不到了,所有的可用区都不可用了,这个概率很低,除非是非常核心的业务,那么就可能需要跨城市的机房了,此种场景略去。
5 演练
演练很多时候都是演戏,因为大家都习惯于在业务低峰期变更,在业务低峰期演练,但是实际上故障发生的时间,可不一定是低峰,基本都是高峰,所以如果规划的容量不足,一旦演起来,那就是有损故障了。
曾几何时,一个哥们进行演练,其实也就是点点页面的按钮,但是某一天,一不小心点错了,在业务高峰进行演练,立刻业务有损,还好及时回滚,要不然就要背上故障了,作为一个运维,背了故障,和背上人命没啥区别,俗称的故障复盘,都是甩锅追责大会。
演戏嘛,尽量真实的,要的就是业务高峰高,要的就是对核心业务进行演练,不出故障的时候,运维都被裁了,出了故障的时候,卧槽。。。运维死哪去了。
6 其他的容灾方案
有没有更多的容灾方案呢?例如采用不同的公有云进行备份,例如线上使用云,备份使用本地机房,都有可能,但是要保障的sla是多少,能花的成本是多少,这个才是需要权衡的。
可用性等级越高,从而花的成本越高。
在容量不足的时候,其实最简单的方式是限流熔断,抛弃一部分业务,而保住核心业务,这样也是节省成本的一种方式。
稳定性与成本之间的博弈。
7 节点池
节点池是个好东西,能隔离故障域,可能一个节点池炸了,但是其他的是好的,只要业务能调度pod,那么总是能慢慢恢复的。
看起来有些东西是强依赖,但是如果方案足够多,也慢慢的可以变成弱依赖。
花很多的成本,解决那万分之一的问题,是否值得?如果你是做成本的,你肯定会说不值得;如果你是做稳定性的,那么就会觉得值得,其实也可以评估一下收益,如果业务在关键时候炸了几分钟,那么能损失多少,如果损失的钱比投入的钱要多,那么说明,这个稳定性的成本是值得的,反而,那么就是不值得的。
很多流程,看起来是也是为了稳定性考虑,但是很多都是形式主义,但是做的人不觉得,他们觉得很棒很优秀,实际上。。。被一群人唾弃。
擦眼看世界,不要局限于自己的思维角度,有的时候,适当看看外面,外面的风景不一定很美,但是可以给你不同的视角。
风言风语
降本,可能更好的方式是从技术上降本,例如优化资源使用,合理设计limit,request,例如智能调度,cpu密集型和内存密集型放一个机器上,这样大家不会有资源争抢。
降本是不是增效,其实这个也无法衡量,大部分都是野生的慢慢摸索,下了决定就去弄,事前其实无法评估损失,因为只有等到了故障爆发,造成了实际的损失,大家才会真正去思考是否应该粗暴的降本。效率其实是肉眼可见的下降,因为大家所有的关注力都在怎么降本,那就是对集群缩容,直接把cpu打上去。
降本只是一种手段,服务器的成本如果没有下降的空间了,那么下一步就是人员成本的下降了,裁员进行时,也是财源进行时。降本也是一种灾难,虽然势不可挡,但是也从侧面反映了核心业务的市场不行了。
上k8s,上容器也不一定省钱,用虚拟机也不一定很贵,使用的场景不同,需要选择不同的方式。很多凑巧的事发生在一起,就形成了故障,降本其实也不是唯一的原因,看问题也不要太片面,只是从中窥探它的趋势。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号