run.ts 上篇 —— 模型调度、账号轮询与上下文守护机制

run.ts 上篇 —— 模型调度、账号轮询与上下文守护机制

jack.yang
发布于 2026-03-13 08:17:26
发布于 2026-03-13 08:17:26
关键词:LLM 调度|API Key 轮询|上下文压缩|Token 监控|弹性推理
在 OpenClaw 的智能体系中,src/agents/run.ts 是真正的“心脏”——它负责将用户请求转化为一次完整的 AI 推理过程。这个看似简单的函数,实则承载了高可用、自适应、安全可控三大工业级要求。
本文聚焦 run.ts 的三大核心机制:
- 多模型弹性调度(Claude → GPT-4 → Gemini)
- 认证账号健康轮询(API Key 轮询 + 冷却策略)
- 上下文窗口守护(Token 监控 + 自动压缩)
它们共同确保:即使某个模型宕机、某个账号限流、某次对话过长,系统仍能优雅降级并完成任务。
一、入口:runAgentInference() 函数
run.ts 的主函数签名如下:
async function runAgentInference(
session: PiSession,
request: AgentRunRequest,
options: RunOptions
): Promise<AgentRunResult>session:当前会话上下文(含历史消息)request:用户输入 + 工具调用历史options:超时、重试次数、允许的模型列表等
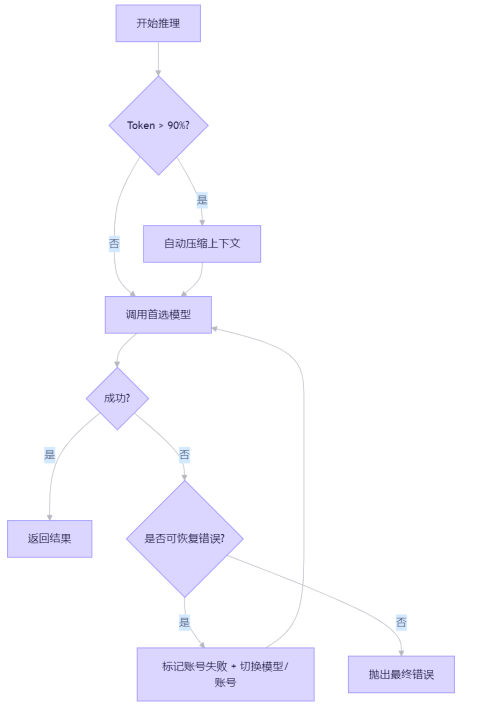
该函数不直接调用 LLM,而是进入一个多阶段调度循环。
二、第一层防御:模型调度与优先级降级
OpenClaw 允许为每个智能体配置多个候选模型,按优先级排序:
# agents/dev-assistant/config.yaml
models:
- id: "claude-3-5-sonnet"
provider: "anthropic"
- id: "gpt-4o"
provider: "openai"
- id: "gemini-1.5-pro"
provider: "google"调度流程
- 尝试首选模型(如 Claude)
- 若返回可恢复错误(如限流、超时),标记该账号失败,切换至下一模型
- 若所有模型失败,抛出最终错误
这使得用户无感知地享受“模型冗余”带来的高可用性。
错误分类决定是否降级
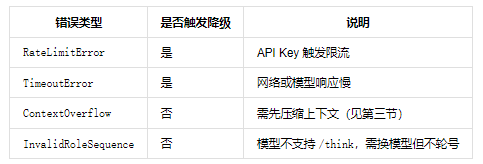
image
三、第二层防御:API Key 轮询与健康状态管理
一个模型可能绑定多个 API Key(例如多个 OpenAI 组织账号)。OpenClaw 通过 认证档案(Auth Profile)管理这些凭证。
账号轮询策略
- 每次调用前,从健康账号池中选择一个
- 若调用失败,调用
markAuthProfileFailure(profileId)- 将该账号加入冷却队列(默认 60 秒)
- 下次调度自动跳过
- 若调用成功,调用
markAuthProfileGood(profileId)- 提升该账号信用分,增加被选中概率
数据结构示例
const authProfiles = {
"openai-team-a": { key: "...", cooldownUntil: 0, successCount: 12 },
"openai-team-b": { key: "...", cooldownUntil: 1710234567, successCount: 3 }
}轮询不是随机,而是基于健康状态的智能选择。
四、第三层防御:上下文窗口守护(Context Window Guardian)
LLM 的上下文长度有限(如 Claude 200K,GPT-4o 128K)。当会话过长,必须主动干预。
Token 使用监控
在每次调用前,估算当前会话的 Token 数:
const tokenUsage = estimateTokens(session.messages)若超过 HARD_MIN_THRESHOLD(如 90% 上下文),触发自动压缩
自动压缩策略:compactEmbeddedPiSessionDirect()
保留关键信息:
- 用户原始指令
- 最近 3 轮对话
- 所有工具调用结果摘要
丢弃中间思考过程(如 /think ... 块)
生成压缩摘要:
[系统摘要] 此前对话已压缩。用户要求部署服务,AI 已执行:1) 拉取代码 2) 构建镜像 3) 推送仓库。配置控制
maxContextTokens: 120000
hardMinThreshold: 0.9 # 超过 90% 触发压缩压缩不是截断,而是语义提炼——确保 AI 仍能理解任务上下文。
五、协同工作:三层防御如何联动?
考虑以下场景:
用户连续发送 50 条消息,Claude 返回 “context length exceeded”
处理流程:
run.ts检测到ContextOverflow错误- 不降级模型,而是调用
compactEmbeddedPiSessionDirect() - 用压缩后的会话重试同一模型
- 若仍失败(罕见),才降级到 GPT-4o
- 若 GPT-4o 的 Key 限流,则轮询下一个 OpenAI 账号
image
层层递进,最大限度保留原始意图。
六、工程价值:为什么这很重要?
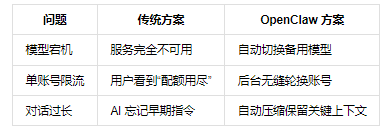
image
这些机制让 OpenClaw 从“能用”走向“可靠”,真正满足企业级 SLA 要求。
结语:智能体的“韧性”来自细节
run.ts 的设计哲学是:不要相信任何外部依赖。模型可能慢,账号可能封,上下文可能溢出——但系统必须继续工作。
这种“防御性编程”思维,正是工业级 AI 系统与玩具项目的本质区别。
在下一篇中,我们将继续深入
run.ts的下半部分:故障转移策略、重试逻辑与结果封装机制。
下一篇预告:
第 6 篇:run.ts 下篇 —— 故障转移、重试策略与结果封装
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-03-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号