GWAS功效(Power)分析?一篇讲透

GWAS功效(Power)分析?一篇讲透

邓飞
发布于 2026-03-12 17:24:43
发布于 2026-03-12 17:24:43
大家好,我是邓飞,今天介绍一下GWAS分析中的功效分析。
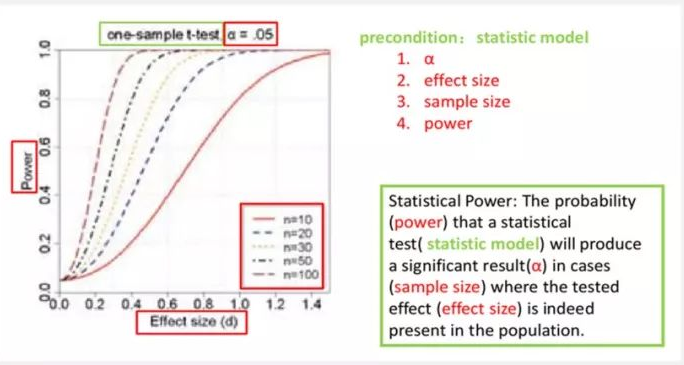
做GWAS的小伙伴谁没踩过这坑:吭哧吭哧测了样本、跑了模型、画了曼哈顿图,结果要么没检出显著位点,要么检出的位点验证不出来——大概率是功效(Power) 没算对!
别再让你的GWAS实验白忙活了,今天就用大白话,把GWAS功效分析的核心逻辑、实操方法、代码模板一次性讲透,从实验前定样本量到实验后筛位点,直接抄作业就行!
先搞懂:GWAS功效,到底是个啥?
简单说,功效就是你的实验能把真实存在的“基因-性状关联”给检测出来的概率。
比如一个位点确实控制着大豆百粒重,你的实验功效80%,就意味着有80%的可能把这个位点揪出来;要是功效只有30%,那基本就是靠运气,没检出才是常态。
要注意,功效分析不是“可选动作”,而是GWAS实验的必修课:实验前算,能帮你定合适的样本量,避免样本太少白花钱;实验后算,能帮你筛真实阳性位点,避免后续验证做无用功。
核心三要素:功效高低,看这仨就够了
所有功效计算的逻辑,都绕不开这3个核心参数,不用背复杂公式,理解关系就行:
- 样本量(N):不用多说,实验中群体大小直接决定检测能力,样本越多,功效越高(当然,也得考虑成本);
- 效应强度(MAF/PVE/beta):QTL效应越明显,越容易被检测。比如MAF适中(0.2-0.5)、PVE(表型方差解释率)高的位点,功效自然高;那些微效QTL,就得靠大样本量凑;
- 显著性水平(α):GWAS的“判定标准”,全基因组分析通用5e-8,候选区域可放宽到1e-5。标准越严,功效越低,这是跷跷板。
一句话总结:样本量不够,就需要效应值足够大;效应值小的微效QTL,必须靠增大样本量提功效!
核心三步法:GWAS功效计算,就这么简单
不管用哪种方法算功效,核心就三步,自由度(df)在GWAS单个SNP检验中固定为1,直接套就行,全程不用懂复杂的统计原理!
第一步:算NCP(非中心参数)
NCP是功效计算的“中间核心值”,把样本量、效应值揉成一个数,NCP越大,功效越高。 给大家整理了最常用的3个NCP计算公式,按需选,不用纠结:
- 用MAF+效应值(beta):
NCP = 2×MAF×(1-MAF)×N×beta²(有SNP效应值结果时用,最贴合GWAS结果) - 用PVE+遗传力(h²):
NCP = N×PVE×h²(作物常用,h²一般取0.8-0.99,根据自己的性状定) - 极简通用版(推荐新手):
NCP = N×PVE/(1-PVE)(只有PVE值时直接用,参考文献验证,准!)
第二步:算卡方临界值
把显著性水平(α)代入R语言的卡方分位数函数,一键出结果,公式固定:卡方临界值 = qchisq(p = 1-α, df = 1)比如全基因组α=5e-8,代入就能算出对应的临界值,这是判定SNP是否显著的“卡方门槛”。
第三步:算最终功效值
有了NCP和卡方临界值,最后一步直接算功效,公式也固定,乘以100就是百分比,更直观:功效 = (1 - pchisq(q = 卡方临界值, df = 1, ncp = NCP))×100
加载必备包,导入你的GWAS结果数据(csv/txt格式,包含SNP、MAF/Effect/PVE列):
# 加载包
library(data.table)
library(tidyverse)
# 设置工作路径(替换成你的文件路径)
setwd("D:/GWAS数据路径")
# 导入数据
dd = fread("GWAS结果.csv")
# 查看数据前几行
head(dd)
模板1:有MAF+Effect值,直接算(最贴合GWAS结果)
适合已经跑完GWAS,有每个SNP的MAF和效应值(beta)的情况,样本量、显著性水平按需改:
# 设定参数(根据自己的实验改)
n = 149# 你的实验样本量,比如育体149份材料
h2 = 0.99# 性状遗传力,作物一般0.8-0.99
alpha = 5e-8# 显著性水平,全基因组5e-8,候选区域1e-5
df = 1# 固定为1,不用改
# 第一步:计算NCP
dd = dd %>% mutate(NCP = 2*MAF*(1-MAF)*n*Effect^2)
# 第二步:计算卡方临界值
chi_critical <- qchisq(p = 1 - alpha, df = df)
# 第三步:计算功效(百分比,更直观)
dd = dd %>% mutate(power = (1 - pchisq(q = chi_critical, df = df, ncp = NCP))*100)
# 查看结果,导出带功效值的SNP数据
head(dd)
fwrite(dd, "GWAS结果_带功效值.csv")
模板2:只有PVE值,极简计算(推荐新手)
适合只拿到SNP的PVE值,或者预实验阶段估算功效的情况,操作最简单,闭眼冲:
# 设定参数(按需改)
n = 149# 样本量
alpha = 5e-8# 显著性水平
df = 1# 固定不变
# 第一步:计算NCP(极简通用版)
dd = dd %>% mutate(NCP = n*pve/(1-pve))
# 第二步:卡方临界值
chi_critical <- qchisq(p = 1 - alpha, df = df)
# 第三步:计算功效
dd = dd %>% mutate(power = (1 - pchisq(q = chi_critical, df = df, ncp = NCP))*100)
# 导出结果
fwrite(dd, "GWAS_PVE版_带功效值.csv")
方法3:进阶分析——专用R包/工具,应对特殊情况
如果你的实验需要做基因×环境互作(G×E) 的功效分析,或者想比较不同GWAS模型(GLM/MLM/FarmCPU)的检测功效,用专用工具更专业,做多点试验的小伙伴重点看:
- G×E功效分析:powerGWASinteraction包(CRAN直接安装:
install.packages("powerGWASinteraction")) - 多模型功效比较:GAPIT包(GWAS常用,教程链接:https://github.com/jiabowang/GAPIT/blob/master/tests/gapit_tutorial_script.txt)
避坑指南:这些错误,千万别犯!
结合多年GWAS分析经验,总结了几个高频坑,踩一个就可能让实验白做,大家一定要避开:
- 样本量拍脑袋定:别觉得“别人用100份,我也用100份”,大豆、玉米、水稻等作物的微效QTL多,样本量至少150份以上,效应值小的性状建议200份+,先算功效再定样本量!
- 显著性水平乱改:全基因组分析别随便放宽到1e-6,不然假阳性飙升,后续验证全是坑;候选区域也别太严,不然漏检真实QTL!
- 忽略MAF筛选:低MAF(<0.05)的SNP,检测功效天生低,优先关注MAF>0.05的位点,没必要在低MAF位点上浪费时间;
- 功效值低于70%的位点直接放弃:功效低于70%的位点,就算检出显著,后续验证的成功率也极低,直接筛掉,聚焦功效80%以上的位点!
- 预实验不做功效分析:小范围预实验先算功效,反推正式实验需要的样本量,比直接做大实验省成本、省时间!
实验前:算功效,定样本量
用预实验的MAF/PVE值,代入上面的公式/代码,算出能让功效达到80%以上的样本量,这是GWAS实验的最低标准,避免样本太少导致检测能力不足。
实验后:算功效,筛位点
对GWAS结果中的所有SNP逐个算功效,剔除低功效位点,只保留功效80%以上的显著位点做后续验证(比如KASP分型、近等基因系验证),大大提高候选基因的筛选效率。
资源推荐:
1,快来领取 | 飞哥的GWAS分析教程
2,飞哥汇总 | 入门数据分析资源推荐
3,数量遗传学,分享几本书的电子版
4,R语言学习看最新版的电子书不香嘛?
5,书籍及配套代码领取--统计遗传分析导论
6,飞哥的学习圈子
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号