Clawdbot背后的软件工程思维和品味


以下是Clawdbot作者GitHub上做的一连串项目。
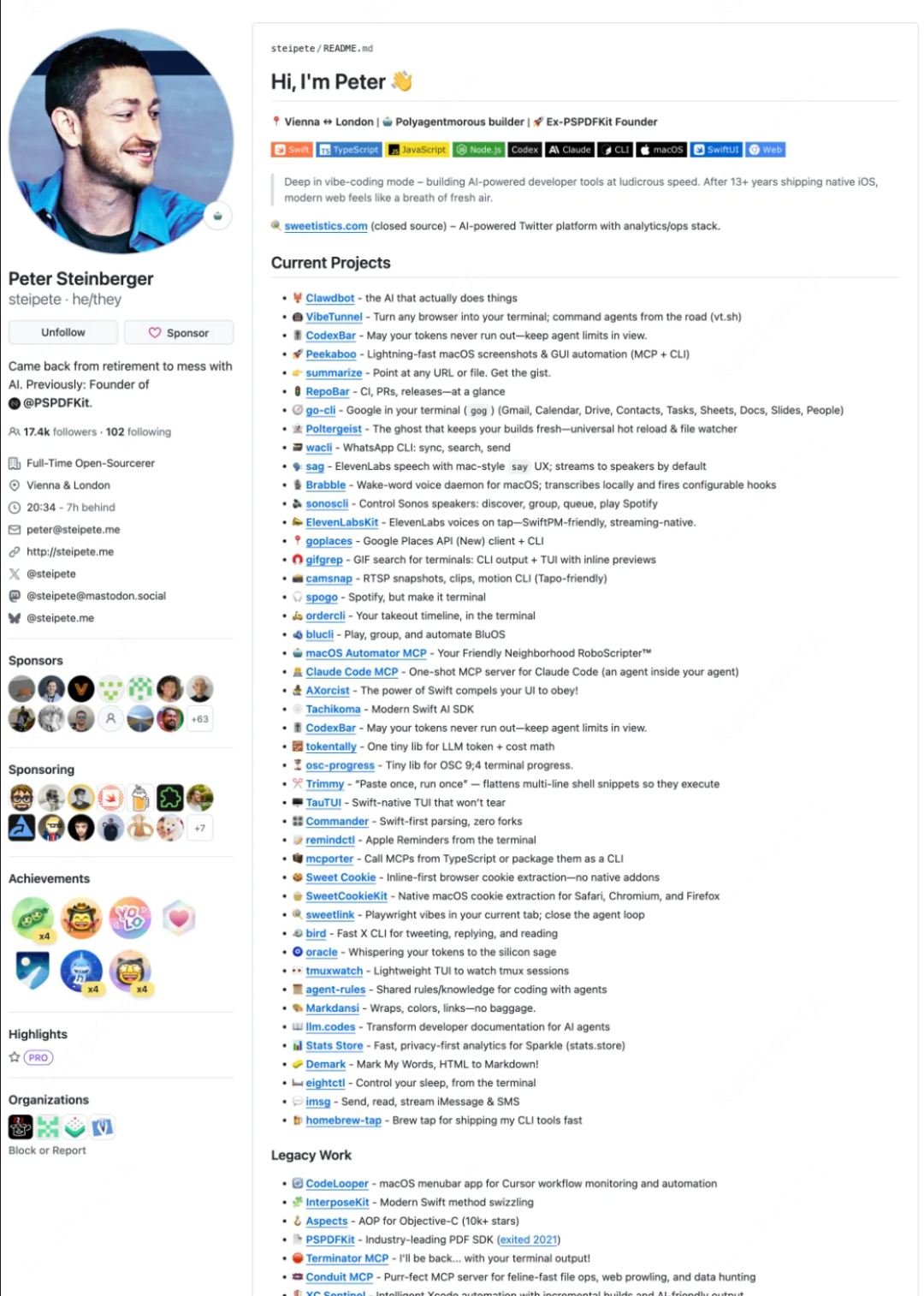
其实这是地基,Clawdbot之所以强,就在于有太多的skill可以用。
没有这套生态,Clawdbot不会像现在一样受欢迎。
Clawdbot不是缝合怪,而是作者一开始就带着目标做这件事情,用一个控制面,把所有服务和数据打通,然后逐步Agent化。
一点点,从一个个散点的服务,聚沙成塔,组成了一个可以被模型调用和执行的Agent。
没有一鸣惊人,都是踏踏实实的做基本功。

作者是个全栈工程师,从移动端到操作系统底层都搞过。
所以他懂得实现一个产品最优雅的软件工程是什么样子的,如果你只懂一样,似乎实现的就不会这么优雅,不会这么严丝合缝。
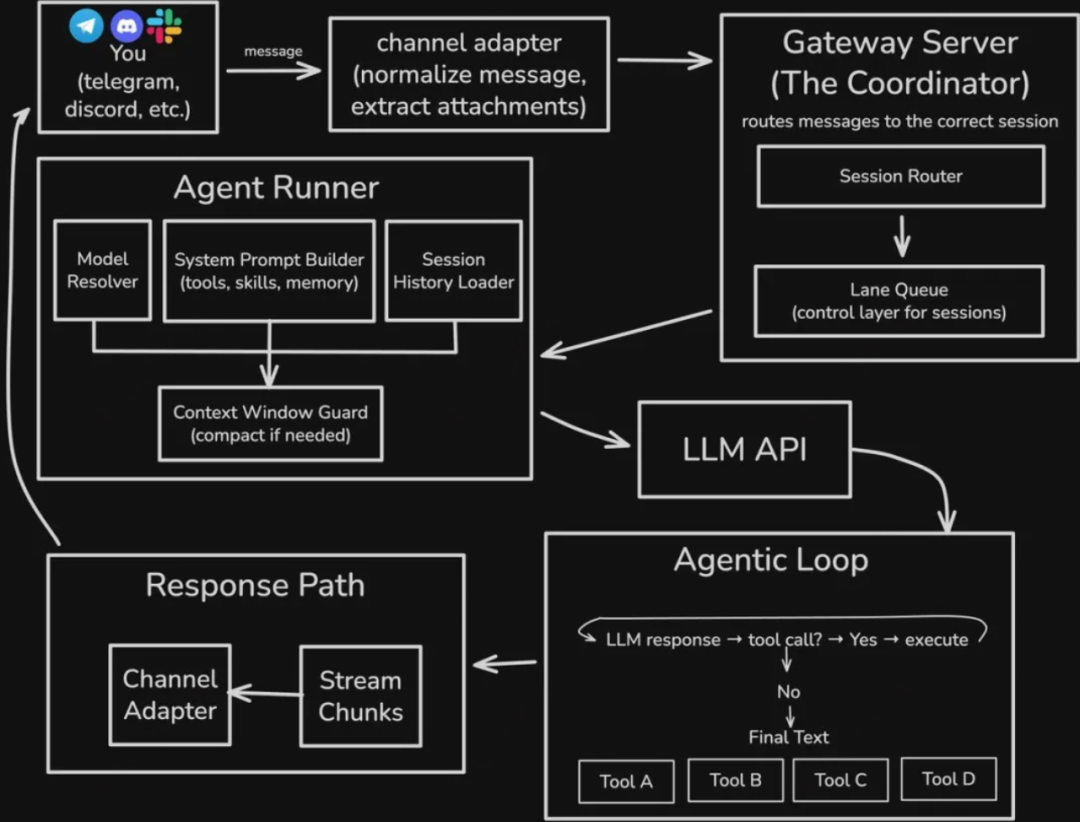

首先,将所有的端点统一到一个客管处的gateway,让UI/CLI都围绕同一协议演进。
会话和状态都以本地文件/本次存储为主,模型既支持云端,也支持本地(ollama)。
大量能力通过外部CLI+Skills方式接入,Clawdbot负责能力编排。
作者也是一位很好的产品经理。
他认为真正的个人助理,必须拥有主人全部的生活,这样他才能对主人需求有更深层的理解。
比如财务记录、私人情感状态等,而这些数据是绝不会放到由大型科技公司控制的云端服务器上的,所以技术实现上,体现了“本地优先的强制约束”。
所以Clawdbot被设计为一个持久化运行的进程,而不仅仅是一个无状态的客户端。
它的记忆系统,不再由向量数据库托管,而是采取直接的markdown/sqlite形式存在本地。
每日记忆是追加的,Agent会在一天中随时写入,比如Agent被告知“记住某件事”,就会写入到这里。



Agent经过策划和分析提取的长期记忆会写到memory.md中。

Agent每次会加载agents.md文件,包含如下指令:

每次记忆搜索时,会采用多路召回策略,先是向量语义找到意思相同的内容,同时基于BM25关键词搜索,找到确切的token,之后进行合并。
同时还会对旧的对话总结压缩(触发时机:接近上下文配额限制时触发、手动触发),保留最新消息的完整性。


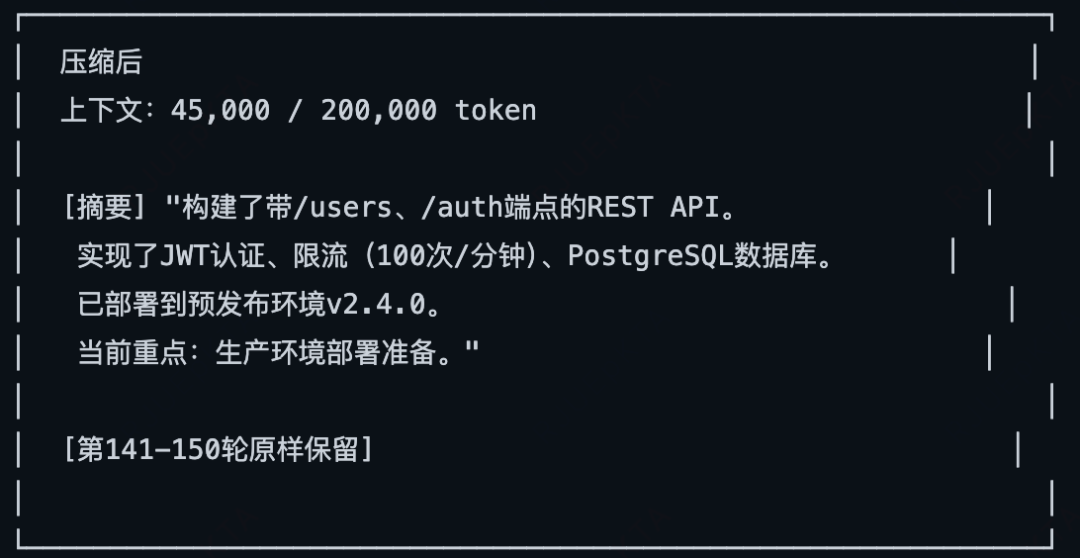
压缩是一个有损的过程,可能导致重要信息丢失,它采用了预压缩记忆刷新。
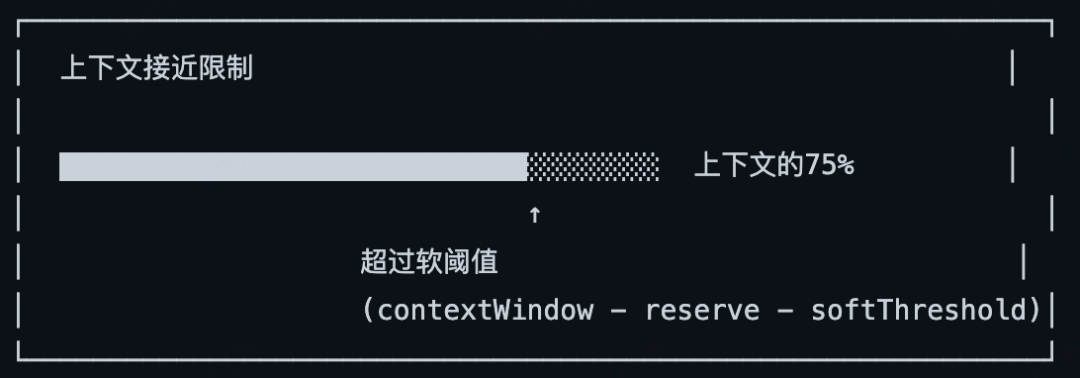


这种设计的好处是,零延迟的上下文访问,基本是毫秒级本地读取,无需网络IO等待。
我觉得这一点很容易想到,但我却见到太多人copy社区方案,有模有样的设计所谓的“长期记忆”、“短期记忆”。
但交流下来,似乎他们觉得这样叫只是为了显得自己更专业,更是没有办法从“产品思维”和“哲学视角”给出“记忆”合理的定义。
因为都是本地文件操作,Agent可以方便地通过删除文件,来实现“记忆遗忘”。
针对于语音场景,本地还集成了VAD,这就有点过分了,可以想象到的脏活累活太多了。
但看到上面GitHub的项目list,又可以理解了,生态不就是这么堆起来的吗。
因为大量操作是本地操作,它基本上没有了远端API访问了。
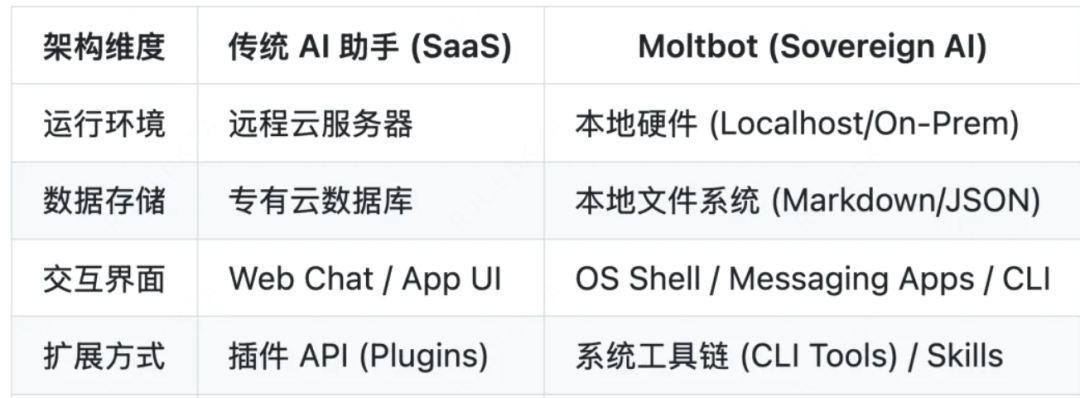
我觉得这些设计都是非常“软件工程”第一性的设计,就像我前面很多文章中提到的一样,Agent设计,先是智力更高的模型,其次就是软件工程。
比如我看很多团队做Agent的意图识别,那些做得好的团队,在于之前搜推工程做得好,所以在意图识别的效率和质量上更高。
反而如果没有搜推工程沉淀的团队,他们做的意图识别只能靠模型推理,这延迟就太高了,哪怕意图识别准确率很高,但哪个用户愿意多等2秒钟?

软件工程认知>Agent认知。

一个好的Agent设计方案,在软件工程架构层面看,一定是具有美感的。
如果你看到一个Agent架构设计缺少美感,大概率这个Agent的效果也不会好的。

我见很多企业落地Agent,老想一口吃个胖子,看的更多是最上层、最光鲜的那一层Agent,似乎只有这个Agent是最值得讲的,值得聊的。
但,我一直认为,Agent无非是数字化时代的新工具。
以往我们数字化建设,用到的工具是大数据、云服务、serverless,如今有了更好用的AI,但无非是数字化的新工具。
从根本上理解了这一点,你就有了方向。



踏踏实实的做好基本功,回到问题原点,而是带着Agent这个垂直到处找钉子。
想清楚业务是啥、有啥问题、需要怎么解决、哪些是合适的方案、哪些可以不用Agent,哪些必须用Agent。
想清楚这些,就不存在所谓的焦虑了。
之所以焦虑,是因为你没理解问题,光想着答案了。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号