Anthropic的Skills,有软件工程素养不难想到

Anthropic的Skills,有软件工程素养不难想到

春哥大魔王
发布于 2026-03-11 20:46:06
发布于 2026-03-11 20:46:06
Anthropic最近提出了Skills(智能体技能)概念。
本质是增加了一个Skill.md的文件/文件夹,智能体可以动态的发现和加载这些技能,从而让智能体在特定任务中表现的更好。
很多人把Skill当成单一技能,比如一个Skill负责翻译,另一个负责总结,这样就太浪费了。
Skill应该被视为一个可组合的模块,你可以把多个Skill串联起来,用自然语言描述他们之间的协作关系,也就是说用“自然语言”实现了“工作流编排”。
哈哈哈,你会发现这智能体架构和软件工程越来越近了。
其实我们自己已经这么做了,因为不同领域业务用到的工具肯定是不一样的,所以肯定也是动态加载的。
这和我们做微服务架构里面服务注册与发现的逻辑非常像,不难想到。
像Claude Code和Manus这样的通用智能体,其实用的工具数量非常少,大约只有十几个。
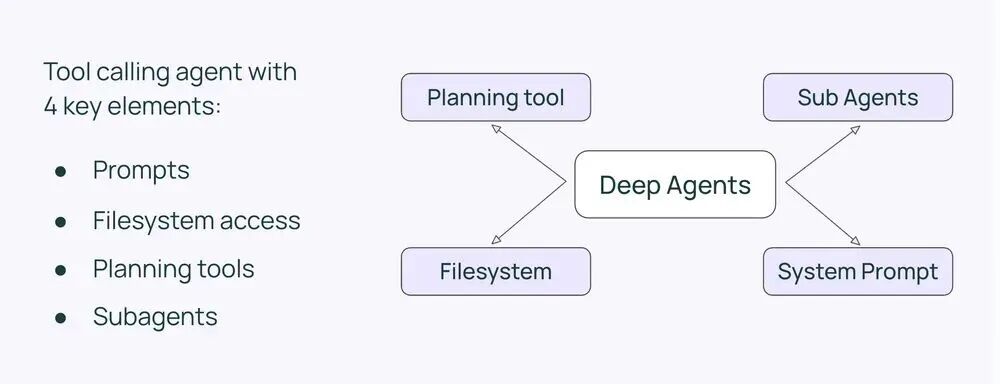
之所以可以用如此少的工具完成任务,关键在于让智能体访问计算机,用计算机的能力。
比如通过bash和文件系统,像人一样操作计算机,而不是为每个任务都提供专门的工具。
用的最多的计算机能力是文件系统和代码执行的能力。
这也是Manus所倡导的一种方法,就是与其提供许多工具,不如给智能体一台计算机,可以操作各种脚本和指令,做很多操作。
Anthropic的Skills采用了同样的模式,将技能视为不同的文件夹,每个文件夹都有一个Skill.md文件,其中包含Yaml和Markdown指令。
结构如下:

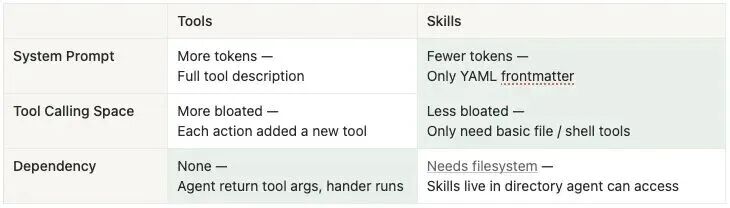
Skills相比传统工具有两个优势:
1、令牌效率高,技能是渐进式披露的,默认只加载Yaml,智能体只有在需要的时候才读取完整的Skill.md文件。
而传统的工具是需要在上下文窗口中加载所有的工具定义,这会导致窗口膨胀。

2、可以减少认知负担,每次智能体只会调用一小组原子工具,而不存在多个工具,避免了上下文混淆。
当你向智能体提出任何技能相关请求时,他会自动读取相关Skill.md文件并执行该技能。
实现一个好的Skill,第一步在于拆分,就像拆分Workflow一样,将任务拆分为多个步骤,这样Workflow中的每个功能节点,都可以对应一个Skill。
第二步是编排,在主Skill中,用自然语言描述整个流程,说清楚就行,其实就是写PE。
比如“先调用xxx智能体分析素材,分析完成之后保存到aaa.md,然后根据分析结果生成2-3个不同风格提纲方案,为每个方案并行调用yyy智能体写草稿”。
条件分支、并行执行逻辑、错误处理都可以用自然语言描述,这样Agent可以理解。
类比下Workflow,最终一个Skill调用另一个Skill,组合为复杂的工作流。
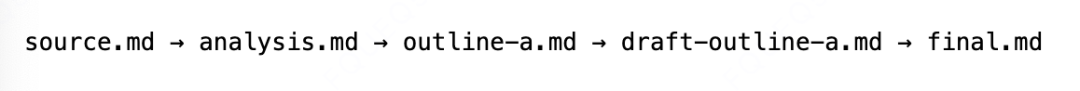
其实我们过去实现ReAct架构,方法也是一样的,用PE描述好任务目标和工作标准。
像Workflow执行一样,所有中间结果都要保存为本地文件。
第一个好处是可追溯,可以看到每一步如何执行的。其次是可崩溃恢复,中间退出了,下次可以从上次断点位置继续执行。还可以引入人工干预,如果不满意中间结果,人工可以接入改动。
当然这里有个小的区别点,就是如何传递不同节点的数据。
有一种方式是通过上下文传递,比如前一个节点的输出作为参数传递给下一个节点。
Skill的方式是传递文件地址,而不是将一大段内容进行传递。
如果传递上下文,模型上下文容易很快填满,而如果传递路径,agent可以自己去读文件,上下文就干净很多。
当然这个也不难想象,见我之前Langgraph的方案,其实上下文信息都是外存储到内存或文件中的,复刻一个java版的Langgraph落地Agent
所以Skill并不难理解,只是换个地方写PE了。
比如以往让Agent调用工具,需要借助Agent完成Json参数填充,完善API描述。但Agent其实并不了解API细节。
参照Skill的思路,完全可以像写API文档的方法,将API文档提供给Agent,Agent像人类一个阅读文档,进而了解API如何调用和使用。
哪怕行业里面没有Skill的概念,相信有很好软件工程素养的你,也会这样做的。
就像我们在没有MCP概念时,我们就用服务注册与发现思想做工具自动识别了。
在没有上下文工程概念时,我们就发现Agent主要解决两个问题,选择一个更智能的模型,通过PE+Tool Call的方式丰富上下文。
模型智力本身是由模型自身控制的,通过上下文工程妄图解决模型智力和成本的问题,听起来长期不靠谱。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号