通过"难度预判"机制提升小语言模型的数学推理能力

通过"难度预判"机制提升小语言模型的数学推理能力

CreateAMind
发布于 2026-03-11 19:03:58
发布于 2026-03-11 19:03:58
通过"难度预判"机制提升小语言模型的数学推理能力
Enhancing Math Reasoning in Small-sized LLMs via Preview Difficulty-Aware Intervention
https://www.arxiv.org/pdf/2508.01604

摘要
强化学习扩展增强了大语言模型的推理能力,强化学习作为引出复杂推理的关键技术。然而,最先进的推理LLM的关键技术细节——如OpenAI O系列、Claude 3系列、DeepMind的Gemini 2.5系列和Grok 3系列——仍未公开,这使得研究界难以复现其强化学习训练结果。因此,我们从基于开源GRPO框架的早期预览强化学习(EPRLI)算法开始我们的研究,并结合针对数学问题的难度感知干预。应用于15亿参数的LLM,我们的方法在AIME24上达到50.0%,Math500上达到89.2%,AMC上达到77.1%,Minerva上达到35.3%,OBench上达到51.9%——超越O1-Preview,在标准学校实验室设置下与O1-mini相当。
- 引言 诸如 OpenAI 的 o 系列(OpenAI,2025a;b)、DeepSeek R1(Guo 等,2025)、Claude 3.7(Anthropic,2025)、Grok-3(XAI,2024)和 Gemini 2.5(LLC,2025)等大型语言模型(LLM)在数学与代码生成等复杂推理任务上表现卓越。这些能力通常通过大规模强化学习(RL)获得,并结合了逐步推理(Wei 等,2022)、自我反思(Wang 等,2023)与回溯(Ahmadian 等,2024)等策略。然而,在小型模型中提升推理能力仍然困难。为此,我们提出一种“预览式难度感知干预”强化学习算法,用于提升小型大语言模型的数学推理能力。我们采用该算法早期预览版训练出的 1.5B 模型,在主要数学推理基准(Guo 等,2025;Christiano 等,2017;Everitt 等,2021;Weng,2024)上超越了 OpenAI 的 O1-Preview 与 O1-mini(OpenAI,2024;Jaech 等,2024)。
- 相关研究 2.1 推理型大语言模型 强化学习(RL)已被广泛用于使大语言模型(LLM)与人类偏好对齐(Christiano 等,2017;Ouyang 等,2022;Yuan 等,2024a;Azar 等,2024;Rafailov 等,2023),而开源社区主要依赖模仿学习(Yuan 等,2024b;Yue 等,2023;Guan 等,2025)来提升推理能力。近期,研究趋势转向强化学习:OpenAI 的 o1(Jaech 等,2024)展示了其潜力,后续工作进一步验证了基于结果奖励的 RL 的可扩展性(Guo 等,2025;Qwen Team,2024;XAI,2024)。尽管如此,密集奖励方法仍未被充分探索,PRIME(Cui 等,2025)对此进行了强调;目前大多数 RL 应用仍采用结果奖励模型(ORM)(Rafailov 等,2023;Shao 等,2024;Guo 等,2025)。 表现最佳的模型——OpenAI 的 o 系列(Jaech 等,2024;OpenAI,2024;2025a;b)、DeepSeek R1(Guo 等,2025)、Claude 3.7(Anthropic,2025)、Grok-3(XAI,2024)和 Gemini 2.5(LLC,2025)——在推理任务上表现卓越。然而,针对参数规模较小(0.7B–1.5B)且仅接受有限数学数据训练的大语言模型,如何通过深度强化学习并结合难度感知干预来提升其数学推理能力,尚缺乏深入研究。
- 方法 3.1 带难度感知干预的早期预览版群体相对策略优化(GRPO)(Shao 等,2024)


在本研究中,我们提出了一种学习分层策略的方法,能够高效地适配层次结构中的所有层级,以完成新任务。我们研究的层次策略由高层策略(manager)和底层策略(sub-policy,记作 π_low)组成。高层和底层都直接在环境中执行动作。通常,高层策略的运行频率低于底层策略。
需要指出的是,在我们预览版框架中的层次结构由 L 个离散层级构成,每一层用 l ∈ {0, 1, ..., L-1} 索引。在此配置下,第 l+1 层为高层策略,其对应的第 l 层为低层策略。该结构支持自上而下的协调机制:高层策略引导底层策略的行为与规划策略。

在提出的具有难度感知干预的组相对策略优化(Shao et al., 2024)的早期预览版本中,我们对其底层马尔可夫决策过程(MDP)进行了简化。具体而言,我们假设高层与低层策略共享相同的参数化方式。这种简化导致了以下表达式:

其中,高层和低层策略在共享策略 πθ 下被统一处理。这种统一的参数化不仅降低了模型的复杂度,还促进了分层结构内的高效训练与推理。


4. 实验
为研究所提出的两种早期预览分层GRPO实现方法对大语言模型推理能力的有效性,我们进行了一系列实验。这些实验旨在与不同参数规模的先进推理导向大语言模型进行对比分析,具体包括:拥有15亿参数的DeepSeek-R1-Distill-Qwen-7B(Guo等人,2025)、STILL-3-1.5B-Preview(RUC-AIBOX,2025)、DeepScaler-1.5B-Preview(Luo等人,2025)、FastCuRL-1.5B-Preview(Chen等人,2025);中等参数规模的Qwen3-4B(Yang等人,2025)、DeepSeek-R1-Distill-Qwen-7B(Guo等人,2025)、MIMO-7B(小米LLM-Core团队,2025);大参数规模的Llama 4 Maverick(AI,2025b)、Phi4-Reasoning-14B(Abdin等人,2025)、Qwen 2.5-72B(Team,2024)、Kimi-1.5(Team,2025a)、Llama 4 Behemoth(AI,2025a)、Qwen3-235B(Team,2025b)、DeepSeek-R1(Guo等人,2025);以及闭源推理模型如Claude 3.7 Sonnet(标准版)(Anthropic,2025)、O1、O1-Mini(OpenAI,2024a)和O1-Preview(OpenAI,2024b),从而对所提出的早期预览方法进行全面评估。
4.1. 实验设置
我们选择DeepScaler-1.5B-Preview-16k(Luo等人,2025)作为基础模型,这是一个拥有15亿参数的模型。我们使用AdamW优化器(Loshchilov & Hutter, 2019),恒定学习率设为1×10⁻⁶进行优化。在生成过程中,我们将温度设置为0.6,并为每个提示采样16个响应。在本实验中,我们不使用系统提示,而是在每个问题末尾添加“让我们一步一步地思考,并将最终答案输出在方框内。”
4.2 基准测试
数学推理基准为了更好地评估训练后的模型,我们选取了五个基准来测试其性能:MATH 500(Hendrycks等人,2021)、AIME 2024(AI-MO,2024a)、AMC 2023(AI-MO,2024b)、Minerva Math(Lewkowycz等人,2022)和OlympiadBench(He等人,2024b)。
4.3. 数据集与评估指标
数学推理数据集训练数据集包含 40K 个问题,涵盖两个难度级别。具体而言,数据集由 AIME(美国数学邀请赛)问题(1984-2023)、AMC(美国数学竞赛)问题(2023年之前)、Omni-MATH 数据集和 Still 数据集组成。我们将模型的最大生成长度设置为 32768 个标记,并采用 PASS@1 作为评估指标。具体来说,我们使用采样温度为 0.6、top-p 值为 1.0,为每个问题生成 k 个回答(通常 k = 16)。PASS@1 的计算公式如下:

4.4. 数学推理实验
所提出的分层推理模型与开源和闭源的先进推理模型进行了评估对比,包括 O1-Preview、O1-Mini、O1、Claude 3.7 Sonnet 等。如表 1 所示,我们的 15 亿参数模型取得了令人印象深刻的性能。
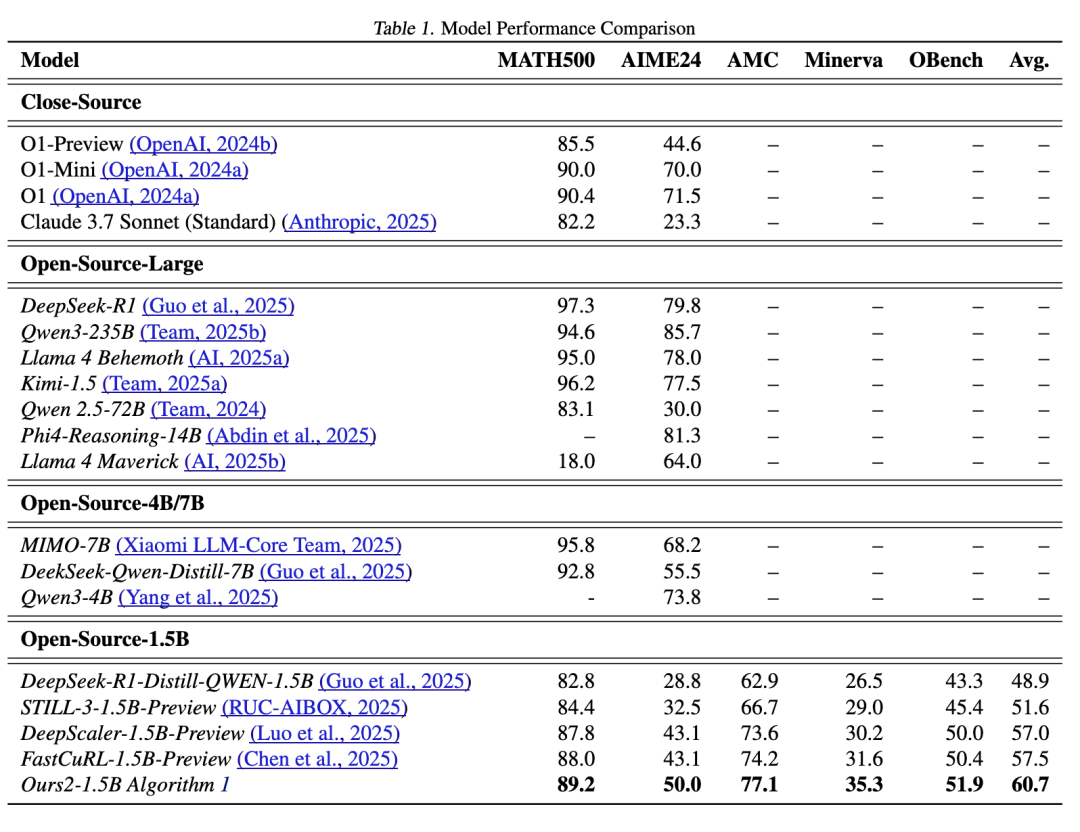
在多个基准测试中表现优异:在 AIME24 上 Pass@1 达到 50.0,在 MATH500 上达到 89.2,在 AMC23 上达到 74.7,在 Minerva 上达到 35.3,在 OlympiadBench 上达到 51.9。这些结果展示了模型在各种数学及竞赛级任务中强大的通用推理能力。
值得注意的是,采用带有预览难度感知干预的强化学习训练策略,使得我们的 15 亿参数模型在 AIME24 上超越了当前性能最佳的 15 亿参数推理模型 6.9 分,在 MATH500 上超越 1.4 分,在 AMC23 上超越 1.1 分,在 Minerva 上超越 4.1 分,在 OlympiadBench 上超越 1.9 分——平均总体提升 3.7 分。此外,它还超越了几个更大参数规模的模型,包括 O1-Preview,并与 O1-2024-12-17(低配版)性能相当。
5. 讨论
我们通过引入一种基于强化学习的、专为数学解题任务设计的预览式难度感知干预策略,启动了对利用强化学习提升大语言模型推理能力的探索。尽管应用于规模相对较小的数学数据集,我们的方法仍显示出推理能力的提升:我们的15亿参数模型不仅超越了OpenAI的O1-Preview,而且接近了性能更强的O1-Mini模型的水平。
我们计划进一步开发该框架,以同时支持中小型模型,其长期目标是开发一个能在数学和编程等多个领域表现出色的统一推理智能体。为促进该领域的透明度并加速进展,我们承诺将进行开源,为研究社区提供工具和基准,以推动资源高效设置下大语言模型推理能力的研究。
原文链接:https://www.arxiv.org/pdf/2508.01604
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号