主动推理的心智理论:一个多智能体合作框架

主动推理的心智理论:一个多智能体合作框架

CreateAMind
发布于 2026-03-11 18:42:53
发布于 2026-03-11 18:42:53
Theory of Mind Using Active Inference:A Framework for Multi-Agent Cooperation
主动推理的心智理论:一个多智能体合作框架
https://arxiv.org/pdf/2508.00401

摘要
心智理论(Theory of Mind, ToM)——理解他人可能拥有不同知识和目标的能力——使智能体能够在规划自身行动的同时,对他人的信念进行推理。我们提出了一种实现多智能体合作的新颖方法,即将心智理论嵌入主动推理(active inference)框架。不同于以往基于主动推理的多智能体合作方法,我们的方法既不依赖于任务特定的共享生成模型,也不需要显式通信。在我们的框架中,具备心智理论(ToM)的智能体维护着关于自身及他人信念和目标的不同表征。随后,这些 ToM 智能体使用一种经过扩展和改进的、基于复杂推理树(sophisticated inference tree)的规划算法,通过递归推理(recursive reasoning)系统地探索联合策略空间。我们通过碰撞规避和觅食(foraging)模拟对我们的方法进行了评估。结果表明,与不具备心智理论(non-ToM)的智能体相比,ToM 智能体能够通过避免碰撞和减少冗余努力,实现更优的合作效果。关键在于,ToM 智能体仅通过可观察的行为推断他人的信念,并在规划自身行动时考虑这些推断。我们的方法展现了在实现通用(generalisable)和可扩展(scalable)多智能体系统方面的潜力,同时为理解心智理论机制提供了计算层面的洞察。
关键词:心智理论(Theory of Mind),主动推理(Active Inference),多智能体合作(Multi-agent Cooperation),复杂推理(Sophisticated Inference),递归规划(Recursive Planning)
1 引言
心智理论(Theory of Mind, ToM)代表了人类认知最显著的成就之一——理解其他智能体拥有与我们自身可能不同的信念和目标的心智[6]。这种元认知(meta-cognitive)技能使我们能够认识到他人可能持有错误信念,并维持与我们自身不同的观点。例如,当我们观察某人寻找一个我们已知在他们不在场时被移动过的物体时,我们能够基于他们认为物体所在的位置(而非其实际位置)来预测他们的搜寻行为[1,12]。这种现实与信念之间的根本性区分,使得复杂形式的合作、竞争和交流成为可能。心智理论在人类发展中早期出现,并支撑着我们应对复杂多智能体环境的能力[11]。
虽然心智理论(ToM)是人类社会认知的基础,但目前基于主动推理(active inference)的多智能体合作方法却缺乏这一关键能力。以往基于主动推理的多智能体合作模型主要依赖于共享或相同生成模型(generative models)的假设,这限制了它们的通用性(generalisability)和实际应用。我们提出,通过在主动推理的规划阶段(planning stage)实现心智理论(ToM),是进行和建模多智能体合作的一个更优方案。这为多智能体人工智能系统提供了一个更有原则(principled)且通用(generalisable)的解决方案,同时提供了一个计算模型,该模型可作为深化我们对人类如何实现心智理论理解的工具。在提出我们的新颖方法之前,我们首先详细阐述了现有基于主动推理进行合作的方法的局限性。
1.1 现有基于主动推理的多智能体合作方法
Maisto 及其同事[9]提出了"交互推理"(interactive inference),其中智能体维护关于共享目标(如两个智能体按下相同或不同的按钮)的概率性信念,并通过观察他人的位置和行动来更新这些信念。他们的智能体选择旨在减少关于联合目标不确定性的认识性策略(epistemic policies)。然而,这种方法假设智能体共享相同的目标,这在多智能体合作任务中并非总是如此。此外,他们的模型依赖于一个为焦点智能体(即进行心智理论推理的智能体)精心设计的生成模型,该模型将其他智能体的位置作为观测输入,而这些观测本身编码了关于共享目标的信息。这些假设限制了该方法在动作本身不直接表明目标,或智能体具有互补而非相同和共享目标的情景下的通用性。
Matsumura 及其同事[10]使用模拟理论(simulation theory)解决了碰撞规避问题(智能体互相通过而不发生碰撞),其中智能体使用自身的内部模型来想象他人的情境。虽然这实现了基本的换位思考(perspective-taking),但他们的实现是领域特定的,仅适用于使用社会力模型的导航任务,因为该模型包含了前进运动和相互排斥的参数。该方法缺乏递归推理(recursive reasoning)能力——即依赖于为不同智能体维护独立信念表征的能力,而这是更复杂协调场景所必需的。
其他研究者提出了通过显式信息交换机制实现多智能体合作的方法[2,5]。这些方法涉及智能体共享似然消息(likelihood messages)——即关于给定状态下观测概率的信息——而非直接共享后验信念。然而,这要求智能体之间的生成模型结构(状态因子和观测模态)完全相同。此外,尽管在数学上具有原则性,但这种方法回避了仅从可观测行为推断他人信念的根本性挑战,而这种能力是人类在多智能体合作中经常展现和利用的。
总体而言,这些方法主要假设所有智能体都在相同的生成模型下运行,对转换动态、观测似然和目标结构具有相同的信念。这种对齐的模型无法捕捉具有不同经验、能力和目标的智能体的现实情况。此外,这些方法通常只涉及单层推理("其他智能体会做什么?"),而非表征心智理论特征的递归信念("我认为其他智能体认为情况如何?")。许多实现也是针对特定任务量身定制的(如导航或相互按钮按压),并未提供跨不同任务的多智能体合作的一般性原则。
为解决这些局限性,我们首次提出了基于复杂主动推理(sophisticated active inference)[3]实现心智理论的通用(generalisable)多智能体合作实现,具有三个关键特征:
- 我们的智能体为自身和他人维护不同的信念和生成模型,使它们能够推理不同观点,同时避免了共享知识和知识结构的假设。
- 我们提出了一种新颖的基于树的规划程序,通过在智能体之间交错策略和观测展开(policy and observation rollouts)来系统地探索联合策略空间。
- 我们的智能体能够通过在自身信念与其他智能体信念之间进行消息传递,推理其他智能体的行动如何影响世界状态,在保持视角分离的同时允许信息整合。
我们通过模拟两个多智能体场景来实证验证我们的方法:一个是碰撞规避任务(智能体必须互相通过而不占据相同位置),另一个是苹果觅食任务(需要对资源进行高效搜索和消耗)。这些场景在一个简单的 3×3 网格环境中实现,以提供一个清晰且可解释的概念验证,未来工作旨在将该方法扩展到更大更复杂的环境中。
我们的结果表明,具备心智理论(ToM)的智能体比不具备心智理论的智能体能更有效地进行多智能体合作。ToM 智能体能够成功避免碰撞并减少冗余努力,因为它们能够主动而非被动地与其他智能体互动。
2 我们的方法:主动推理中的心智理论
2.1 复杂推理
我们的方法建立在复杂推理(sophisticated inference)[3]之上,该方法将标准主动推理扩展到考虑预期自由能(Expected Free Energy, EFE)的递归形式。在标准主动推理中,智能体通过考虑"如果我那样做会发生什么?"来评估策略。而复杂推理则将其深化为"如果我那样做,我会对发生的事情持有什么信念?"这种区分对于心智理论(ToM)至关重要。当推理其他智能体时,我们不仅需要考虑它们会做什么,还需要考虑它们对自身行动后果的信念。这种对其他智能体的递归推理需要维护一个独立的其他智能体模型。
2.2 具备心智理论(ToM)的智能体对多个智能体的信念结构
在我们的 ToM 框架中,焦点智能体(focal agent)为其自身及环境中每个其他智能体分别维护独立的状态信念(s)。在双智能体情景下,这产生
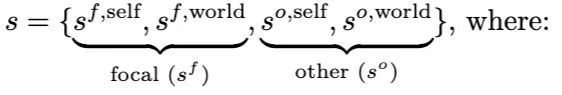
其中:
- sᶠ,ˢᵉˡᶠ 是焦点智能体关于其自身状态的信念(例如,焦点智能体自身的所在位置);
- sᶠ,ʷᵒʳˡᵈ 是焦点智能体关于世界状态的信念(例如,其他智能体的位置或当前位置的物品);
- sᵒ,ˢᵉˡᶠ 是焦点智能体关于其他智能体自身状态的信念(例如,其他智能体的位置);
- sᵒ,ʷᵒʳˡᵈ 是焦点智能体关于其他智能体对世界状态所持信念的信念(例如,其他智能体认为焦点智能体的位置或当前位置的物品)。
这种结构使焦点智能体能够保持自身视角的独立性,同时模拟他人可能如何看待事物的不同方式。具体而言,信念组件可以灵活组合,以捕捉不同的推理情境。例如,焦点智能体可将 sᵒ,ˢᵉˡᶠ 与 sᶠ,ʷᵒʳˡᵈ 配对,以预测在基于自身对环境信念的前提下,其他智能体会观察到什么。焦点智能体亦可将 sᵒ,ˢᵉˡᶠ 与 sᵒ,ʷᵒʳˡᵈ 配对,以预测其他智能体基于其自身(可能错误的)世界观会认为自己将观察到什么。这种跨视角推理能力,使焦点智能体能够区分:(a) 它认为其他智能体将感知到什么;与 (b) 它认为其他智能体相信自己会感知到什么。由于焦点智能体自身的世界信念(sᶠ,ʷᵒʳˡᵈ)可能与其关于其他智能体的世界信念(sᵒ,ʷᵒʳˡᵈ)不同,因此它可以表征知识不对称的情形——例如,当焦点智能体知道而其他智能体不知道某些信息时。
通过维护这些独立的表征,我们的框架不假设智能体之间存在共享的知识结构。焦点智能体可根据可观测行为,构建并持续更新其对其他智能体的模型,而实际的其他智能体则可能基于一个完全不同的生成模型运行。这种能力使得我们的智能体即使在拥有不同先验知识、能力或目标的情况下,也能有效协作——这是现实且实用的多智能体系统的基本要求。
2.3 基于心智理论的递归规划
我们方法的核心创新在于规划算法,该算法使智能体能够对联合策略空间进行递归推理。它系统地探索焦点智能体关于其他智能体信念的信念如何影响其自身的规划决策。预期自由能(EFE)的递归形式被扩展至心智理论(ToM)场景中(见附录 A),从而产生一种深度树搜索算法,该算法在焦点智能体与其他智能体的策略和观测之间交替进行。在每个规划时间范围(planning horizon)内,树搜索通过以下五个主要阶段展开,具体细节如下并如图 1 所示。
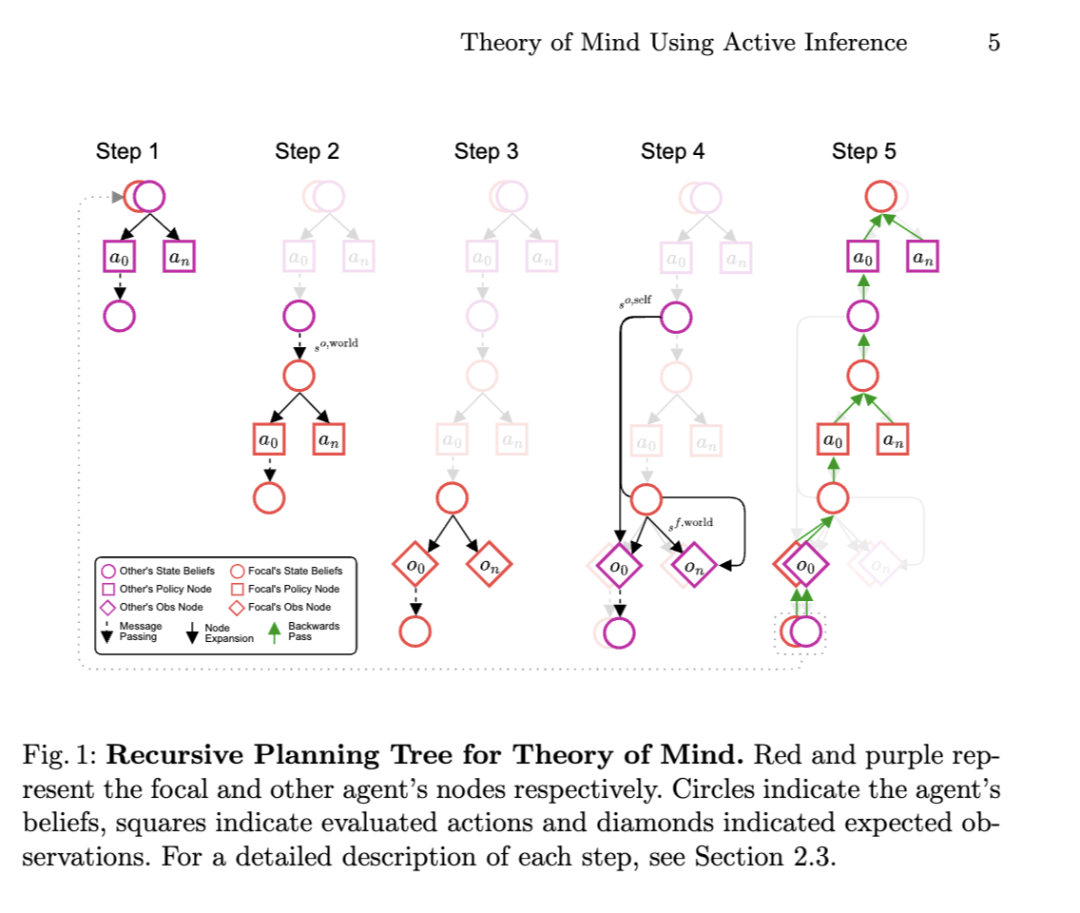
步骤 1:其他智能体策略扩展。如第 2.2 节所述,我们从焦点智能体的信念开始,该信念包含其自身及环境中其他智能体的独立信念(s = {sᶠ, sᵒ})。焦点智能体首先考虑其他智能体可能选择哪些策略。这在图 1 的步骤 1 中可视化,其中每个策略节点代表其他智能体可能执行的一个特定动作(a₀;紫色方块)。潜在动作是根据焦点智能体关于其他智能体信念(sᵒ;紫色方块上方的紫色圆圈)的信念进行评估的。本质上,焦点智能体提出问题:“基于我对其他智能体信念和目标的看法,它会选择做什么?” 随后,焦点智能体计算如果其他智能体执行该动作,其信念将如何更新(sᵒ;紫色方块下方的紫色圆圈)。
步骤 2:焦点智能体策略扩展。对于所考虑的其他智能体的每一个动作,焦点智能体评估自身的策略选项。关键的是,在此之前,焦点智能体需根据对其他智能体行动后果的预期,利用似然消息传递来更新其世界信念。在此处,焦点智能体使用其对“如果其他智能体执行一个动作,其关于世界的信念(sᵒ,ʷᵒʳˡᵈ;红色圆圈上方的紫色圆圈)将如何变化”的计算。然后,创建一个似然消息,捕捉从其他智能体预期行动中获得的信息——以其他智能体更新后的信念与其先验信念之间的差异形式呈现。该机制使焦点智能体能够将有关“世界状态(sᶠ,ʷᵒʳˡᵈ;红色方块上方的红色圆圈)将因其他智能体行动而如何变化”的信息整合到自身的信念中。接着,焦点智能体利用这些更新后的信念,通过标准 EFE 计算评估其自身的策略选项(a₀;红色方块),从而为焦点智能体与其他智能体之间的每一种可能联合策略组合创建树结构中的分支。随后,焦点智能体计算若在给定其他智能体行动的情况下执行某个动作,其自身信念将如何更新(sᶠ;红色方块下方的红色圆圈)。
步骤 3:焦点智能体观测扩展。然后,在给定联合策略的前提下,焦点智能体考虑其可能接收到的观测及其产生的后验信念。
这一过程在图 1 的步骤 3 中进行了说明,其中焦点智能体的观测节点(o₀;红色菱形)代表焦点智能体在考虑双方行动执行(sᶠ;红色菱形前的红色圆圈)的前提下,预期会遇到的各种观测。这导致了焦点智能体后验信念(sᶠ;红色菱形后的红色圆圈)的计算。
步骤 4:其他智能体观测扩展。在此,焦点智能体考虑在给定联合策略和预期世界状态变化的前提下,其他智能体可能接收到的观测(o₀;紫色菱形)。观测概率是根据焦点智能体关于其他智能体自身状态(sᵒ,ˢᵉˡᶠ;来自早期扩展的紫色圆圈)的信念,以及焦点智能体自身关于世界状态的更新信念(sᶠ,ʷᵒʳˡᵈ;紫色菱形前的红色圆圈)计算得出的。随后,焦点智能体更新其对其他智能体后验信念(sᵒ;紫色菱形后的紫色圆圈)的表征。
步骤 5:树向后传播与策略选择。最后,在为当前规划范围展开树之后,一次向后传播计算焦点智能体的策略选择概率。向后传播在图 1 的步骤 5 中可视化,绿色向上箭头表明 EFE 值从叶观测节点回传至每个策略分支,以告知根节点的最终策略选择。为了规划下一个时间步,步骤 5 中观测节点的叶子将成为步骤 1 的根节点(灰色虚线箭头)。
针对每个联合策略组合,递归计算 EFE 值,并根据观测概率进行加权。其他智能体的策略概率在策略选择时被边缘化处理。最终的概率分布平衡了目标导向行为与信息寻求行为,同时考虑了对其他智能体行动的不确定性。
我们的实现通过两种机制实现了计算效率,这两种机制在复杂主动推理中已有实践[3]。策略剪枝通过消除不太可能的策略节点来减少树的扩展,这些节点不会进一步分叉。观测剪枝同样聚焦于可能的结果,减少了组合爆炸。
3 实验验证
我们在两个需要不同合作形式的多智能体场景中对我们的 ToM 框架进行了实证验证。所有模拟均在一个 3×3 网格环境中进行(参考网格布局见附录 B),具有确定性动态和对智能体位置的完美可观察性。实验设计为每个任务包含两种条件:基线条件(两个智能体都使用不具备心智理论能力的复杂主动推理),以及 ToM 条件(其中一个智能体(红色)配备我们的心智理论框架,而另一个(紫色)保持非 ToM 状态)。所有模拟均使用基于 JAX 的 Python 包 pymdp 进行,该包为构建此类模型提供了高效灵活的工具[7]。
3.1 碰撞规避任务
任务描述。碰撞规避任务提出了一个基本的合作挑战:两个智能体从网格的对角位置开始,目标是交换位置,同时避免碰撞。两个智能体的最短路径都涉及穿越会导致碰撞的中心格子。我们使用三个主要指标评估性能:任务完成成功率(智能体是否到达各自目标)、碰撞发生情况和路径效率(完成任务的总时间步)。该任务需要主动合作,因为被动策略会导致僵局。
生成模型。每个智能体的生成模型包含两个状态因子:自身位置(9 个离散位置状态加上一个边界违规的空状态,如[8])和其他智能体位置(也是 10 个状态,与焦点智能体的位置状态类似)。观测模型通过身份似然映射提供了对两个位置的完美感知访问,消除了感官不确定性。
动作空间包含九个选项:方向移动(上、下、左、右、四个对角线)加上无操作。关于智能体自身位置的转换动态反映了完全可控性,遵循标准网格世界物理,其中试图占据同一格子的智能体会永久卡住。无效移动通过空状态指定(具有严重的负效用)。例如,如果智能体试图从位置 1(左上角)向上移动,它将进入严重不受欢迎的空状态,从而驱使其远离无效移动。由于其他智能体的位置不可控制,其他智能体位置的转换动态反映了其他智能体可采取有效动作之间的均匀概率分布。例如,从位置 1(左上角)移动到中心、向下、向右或无操作的概率均为 1/4。
偏好设定:编码了目标导向行为——到达目标位置获得高正效用,而遭遇空观测则受到严重惩罚。关键的是,未包含任何显式的碰撞规避偏好——协调必须通过心智理论(ToM)推理自然涌现,而非硬编码的行为。
规划时间范围对 ToM 和非 ToM 智能体均设为 3 个时间步,这足以通过替代路径到达目标,同时需要足够的前瞻规划来识别协调机会。
结果。关于此任务结果的示意图,请参见图 2a。在非 ToM 条件下,两个智能体可预见地选择了各自最优的策略,直接经由中心向目标移动。这导致了碰撞和永久僵局,双方均未能实现其目标。这是一个明显的合作失败案例,尽管个体规划复杂且能观察到对方位置,但缺乏将其整合进规划过程的能力。
在 ToM 条件下,红色(具备 ToM)智能体推断出另一智能体最有可能移向中心位置以走最短路径到达其目标,因此它选择不移动至该位置以避免碰撞,即使这是对其自身而言最优的策略。相反,该智能体绕行中心,选择了通向其目标的次优替代路线。ToM 智能体选择了一条更长但无碰撞的路径。有关 ToM 与非 ToM 智能体在时间步 0 的详细规划树,请参见附录 B。
3.2 苹果觅食任务
任务描述。苹果觅食任务考察了在部分可观测情境下的资源获取合作。3×3 网格中设有果园位置(顶部和底部行),苹果可能在此处生成;以及荒地(中间行),不含任何资源。两个智能体从相同的先验知识开始:确信右下角存在一个苹果,而对其他果园位置是否存在苹果则完全不确定。智能体的初始位置与已知苹果的距离相等(见图 2b)。苹果消耗具有排他性——仅有一个智能体可以消耗每个苹果,若两个智能体同时到达同一苹果,则随机决定由谁消耗。合作挑战在于平衡对已知资源的利用与对不确定位置的探索,同时避免对相同资源的冗余竞争。

生成模型。生成模型包含三类状态因子:智能体位置、奖励反馈(二元:收到/未收到,取决于是否吃到了苹果)以及环境物品(荒地、苹果或空果园)。智能体可观察自身位置、其他智能体位置、当前位置的物品以及自身的奖励反馈。
环境是部分可观测的,智能体只能评估其当前位置的苹果可用性,从而对整体资源分布产生不确定性。苹果以概率方式在果园位置生成(每时间步 25%),并在被消耗前一直存在于该位置。动作集包括移动(上、下、左、右)、进食和无操作。偏好设定仅简单偏向于获取奖励,未设置明确的合作激励。规划时间范围设为 3 个时间步,足以到达网格环境的对侧并消耗苹果。
结果。关于此任务结果的示意图,请参见图 2b。有关 ToM 与非 ToM 智能体在时间步 0 的详细规划树,请参见附录 C。
在非 ToM 条件下,两个智能体都汇聚到已知的苹果位置(右下角),导致资源竞争。只有一个智能体成功消耗了苹果(随机决定),另一个智能体浪费了努力,显示出低效的合作。
在 ToM 条件下,红色(具备 ToM)智能体推断出另一智能体很可能会前往已知苹果位置,因此它选择探索另一个它不确定是否有苹果的位置。这导致了冗余努力的避免和更有效的合作,避免了资源竞争。该策略被证明是成功的,因为两个智能体都发现并消耗了苹果。
4 讨论
我们的实验结果表明,为基于主动推理的智能体配备心智理论(ToM)能力从根本上改变了它们完成任务和进行多智能体合作的方式。具备 ToM 的智能体成功应对了碰撞规避和资源竞争场景,与不具备 ToM 的智能体相比实现了更好的合作。重要的是,这种性能提升的实现无需依赖显式通信协议、智能体之间的共享生成模型或预设策略。
我们 ToM 智能体的成功源于其推理他人信念和预测他人行为的能力。在碰撞规避任务中,ToM 智能体认识到两个智能体都遵循各自的最优路径将导致碰撞。通过推理另一智能体可能的轨迹,ToM 智能体主动选择了次优替代路线,展示了相比仅被动响应碰撞的合作行为。同样,在苹果觅食任务中,ToM 智能体预见了资源竞争并战略性地探索了不确定的位置,导致了两个智能体之间更高效的资源分配。
我们的框架解决了以往多智能体主动推理实现中的基本局限性。最重要的是,我们消除了占主导地位的先验工作中对共享或相同生成模型的限制性假设[9,10,2,5]。这限制了它们在更复杂或现实世界场景中的通用性和适用性,因为在这些场景中智能体拥有不同的经验、能力和目标。相比之下,我们的 ToM 框架允许异质多智能体生成模型。ToM 智能体为其环境中的每个智能体维护独立的信念表征,使其能够在不假设他人共享其自身知识、目标甚至生成模型结构的情况下推理他人。
4.1 未来方向
虽然本文通过在主动推理中实现 ToM 提供了关于计算性多智能体合作的宝贵见解,但未来研究有几个方向可以建立在我们的发现之上。
我们当前的实现假设能够观测到其他智能体的位置,并置于一个简单的 3×3 网格环境中。虽然这些简化使得核心 ToM 原理能够清晰展示,但我们自然需要在更复杂和现实世界的场景中检验它,这些场景可能涉及更嘈杂的感官信息以及复杂的任务需求和动态。未来的工作还应包括使用跨随机种子的聚合性能指标和与非 ToM 基线的统计比较进行系统的定量评估,以更严格地评估我们方法的鲁棒性。
报告的模拟中另一个简化是,我们的 ToM 智能体假设了解他人的目标,并使用对其他智能体的固定生成模型运行。未来的实现应包含在线学习机制,可能使用狄利克雷计数(Dirichlet counts)[4],以持续学习和更新关于其他智能体模型、偏好和能力的信念。这种自适应学习将显著增强框架的通用性,使其能够与特征最初未知或不断演变的智能体进行有效合作。
此外,虽然我们当前的实现专注于二元互动(dyadic interactions),但其基本原理自然扩展到更大的多智能体场景。每个智能体将为所有其他智能体维护独立的信念表征,规划算法将在任意大小的联合策略空间上展开。然而,计算复杂度随智能体数量呈指数增长,这带来了可扩展性挑战,需要仔细考虑,是进一步研究的方向。
此外,我们的实现专注于一阶心智理论推理("其他智能体相信什么?"),而非更高阶的递归推理("我认为其他智能体认为我相信什么?")。虽然一阶心智理论对于我们的测试合作场景已足够,但更复杂的社会情境可能需要更深层次的递归推理。这可以在存在多个 ToM 智能体的场景中进行检验,研究具备心智理论能力的智能体之间的递归推理如何影响合作动态和计算需求。
另外,我们的框架仅在智能体目标在某种程度上互补的合作场景中得到了验证。未来研究应调查竞争场景,其中智能体的目标直接冲突,以评估规划算法是否仍然有效,以及生成模型应如何构建以处理对抗性互动。
5 结论
我们提出了在主动推理框架内用于多智能体合作的首个通用性心智理论(ToM)实现。我们的方法通过消除所有智能体必须在共享或相同生成模型和目标结构下运行的限制性假设,代表了对现有方法的重要进步。
我们框架的核心创新在于使智能体能够在递归推理他人信念如何影响其行为的同时,为自身和他人维护独立的信念。通过我们新颖的基于树的规划算法,具备 ToM 的智能体通过考虑他人相信什么以及这些信念如何影响他们对行动的考量和决策,系统地探索联合策略空间。这种递归推理能力使得复杂的在线合作成为可能,而无需显式通信或预设合作协议。
我们通过两个任务验证了我们的框架:碰撞规避和资源觅食任务。ToM 智能体在两种场景中都成功合作,避免了冲突并实现了比非 ToM 智能体更高效的结果。重要的是,这些合作能力在遇到任务挑战时立即显现,无需长时间训练或领域特定学习。
我们开发的框架连接了计算科学与认知科学,既为增强人工智能系统提供了实用工具,也为理解复杂社会推理如何从关于他人心智的原则性概率推理中涌现提供了计算基础。
原文链接:https://arxiv.org/pdf/2508.00401
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号